Semantic Segmentation: Enriching Image Data

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Semantic Segmentation Approach: What Does It Mean?
- Key Algorithms and Techniques in Semantic Segmentation
- CNN-Based Semantic Segmentation Methods
- The Role of Data Annotation in Semantic Segmentation
- Data Augmentation for Semantic Segmentation
- Real-World Applications of Semantic Segmentation
- About Label Your Data
- FAQ

TL;DR
- Semantic segmentation provides pixel-level labeling for precise object identification.
- Traditional methods use image features like color and texture to ensure accuracy.
- CNN models such as U-Net and DeepLab enable detailed, pixel-level segmentation.
- Accurate data annotation is an inevitable step in building semantic segmentation models.
- Data augmentation techniques like geometric transformations improve model robustness.
- Applications include autonomous driving, agriculture, medical imaging, and satellite analysis.
Semantic Segmentation Approach: What Does It Mean?
Semantic segmentation takes image labeling to the next level by focusing on each pixel individually. Unlike object detection or image classification, which categorize entire images or place bounding boxes around objects, semantic segmentation offers granular labels for every pixel.
This technique is crucial in fields like medical imaging, where distinguishing tissue types or identifying tumors at the pixel level can be life-saving. It’s not just about detecting objects; it’s about understanding their precise structure and location within the image.
Key Algorithms and Techniques in Semantic Segmentation
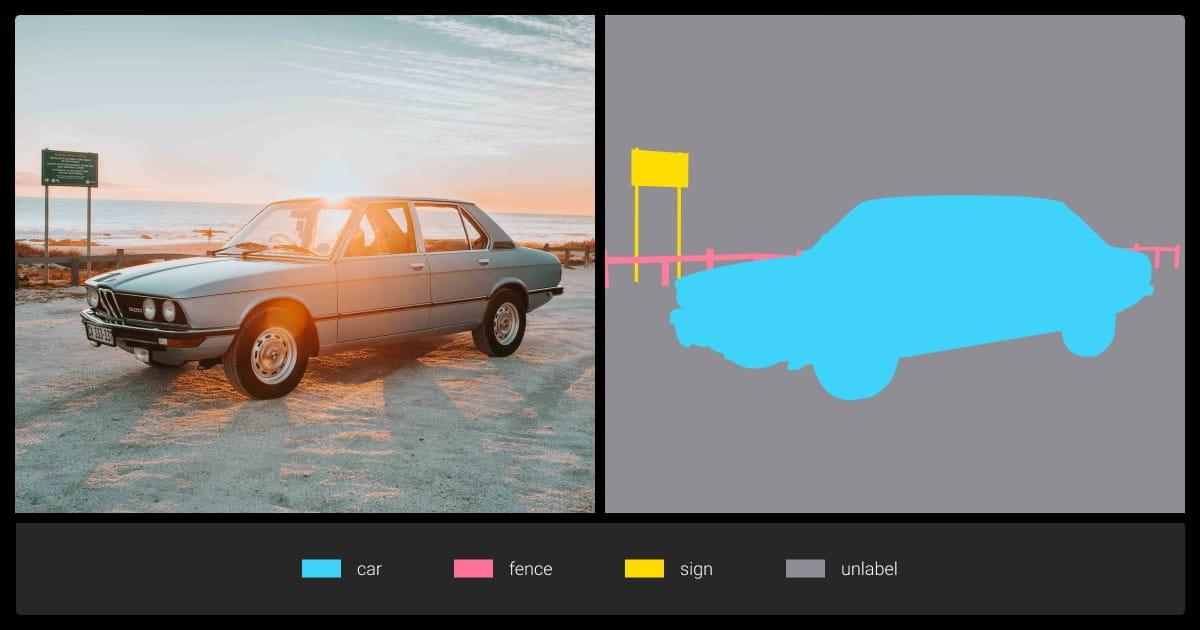
With semantic segmentation, computer vision achieves higher accuracy through detailed, pixel-level labels, providing a more granular understanding of images.
The foundation of traditional semantic segmentation algorithms lies in image features such as color, texture, and boundaries. These models often rely on manually crafted features, statistical analysis, and mathematical transformations to distinguish between different parts of an image.
I've found that weighted sampling during batch formation makes a huge difference—we saw a 23% improvement in minor class detection by ensuring each batch had balanced representation.

 CEO, PlayAbly.AI
CEO, PlayAbly.AI
Image Color and Texture Features
One of the traditional approaches to image segmentation is to use information about the color and texture of the image. This can be particularly effective for distinguishing objects with clear color differences or textural variations.
- Color Histograms: Analyze the distribution of colors in an image to help identify and differentiate objects. These methods are powerful when working with images where colors are distinct.
- K-Means Clustering: This method groups pixels into clusters, analyzing common color characteristics. It reduces the number of colors while maintaining visual integrity, allowing for efficient segmentation.
| Method | Application | Advantages |
| Color Histograms | Image retrieval, object identification | Simple, effective in distinct color scenes |
| K-Means Clustering | General image segmentation | Reduces data complexity for large images |
Boundary Features
With this segmentation technique, it is possible to refine changes in brightness and edge points. These algorithms outline the object edges within an image.
- Canny Edge Detection: A gradient-based method that identifies strong edges in an image while being robust against noise. It’s particularly useful in medical imaging for detecting tissue boundaries.
- Sobel Operator and Laplacian Operator: These operators compute pixel gradients to detect object boundaries based on intensity changes.
| Edge Detection Technique | Advantages |
| Canny Edge Detection | Robust against noise, strong edge detection |
| Sobel Operator | Simple and effective for gradient detection |
| Laplacian Operator | Identifies intensity changes and smooths image noise |
Region-Based Methods
Region-based segmentation refers to particular areas, or segments on the image, that can be combined in terms of texture, color, or brightness. Two commonly used methods are:
- Watershed Algorithm: Simulates water flowing into the local minima of an image, making it useful for medical imaging to delineate boundaries between organs or tissues. However, it can be sensitive to noise.
- Graph Cuts: Treats pixels as nodes in a graph. It indicates the most optimal way to segment the image, while minimizing the cost of cutting the graph into disjoint regions.
While the Watershed algorithm usually refers to medical image segmentation, Graph Cuts relates to general object segmentation in complex scenes.
CNN-Based Semantic Segmentation Methods
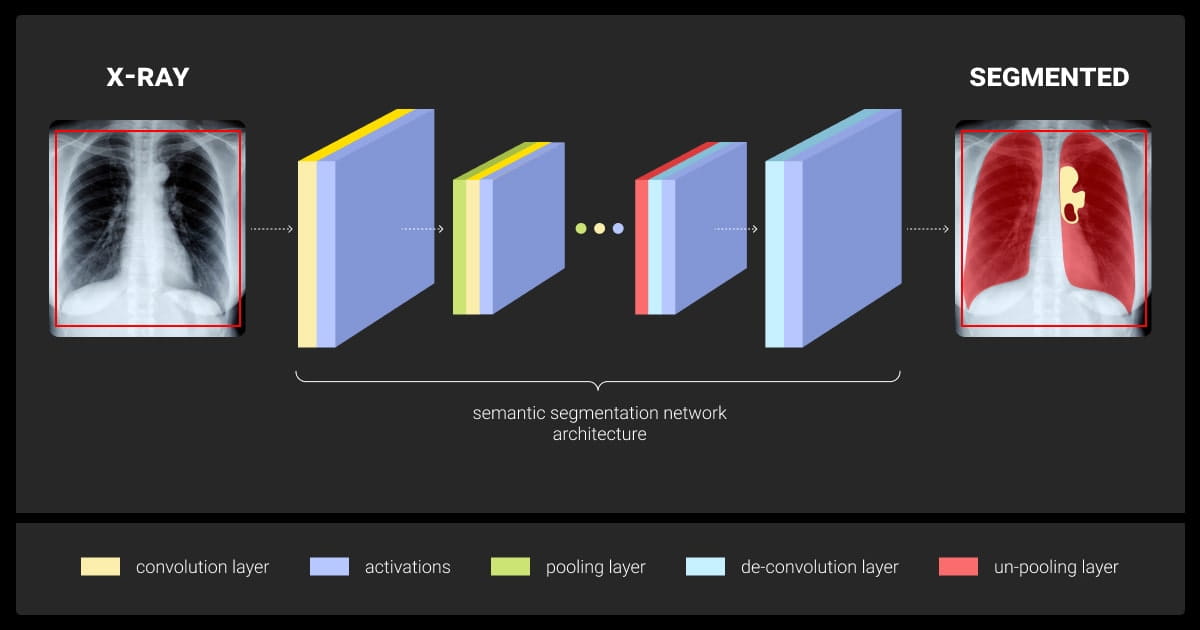
As deep learning has advanced, convolutional neural networks (CNNs) have emerged as the leading method for semantic segmentation. Their ability to capture and interpret hierarchical image features makes CNNs highly efficient for tasks requiring pixel-level precision in labeling. Several popular CNN-based architectures include:
Fully Convolutional Networks (FCNs)
As this study states, FCNs are the foundation of CNN-based segmentation. If compared with traditional CNNs that use connected layers for classification, FCNs replace these layers with convolutional layers. This allows for pixel-level predictions. The semantic segmentation model performs dense, spatial predictions without losing image resolution. FCNs' main feature is connecting layers to convolutional layers to preserve spatial dimensions.
U-Net
As an advanced architecture, U-Net features an encoder-decoder structure. With skip connections, it's possible to recover fine-grained details in the image. Initially, U-Net was developed for biomedical image segmentation and has since become one of the most widely used architectures for pixel-level tasks. We mostly use U-Net architecture for tasks requiring precise boundary delineation.
SegNet
SegNet is another encoder-decoder architecture used for semantic segmentation. It uses convolutional layers for encoding and then decodes using upsampling layers. Compared to U-Net, SegNet does not rely on skip connections. This makes it more lightweight, but potentially less precise in recovering fine details. We would likely use it for segmentation tasks in a resource-constrained environment, such as segmenting crops in agriculture or land features from aerial images.
DeepLab
DeepLab leverages atrous (or dilated) convolutions to expand the field of view without adding extra computational overhead. This approach allows it to capture a broader context in images while preserving high-resolution details. This makes it particularly effective for applications like satellite image analysis, where both large-scale context and fine detail are critical. This approach also ensures that the model can handle complex scenes with varying object sizes efficiently.
| CNN-Based Method | Key Feature | Use Case |
| Fully Convolutional Networks (FCNs) | Replace fully connected layers with convolutional ones | Autonomous driving, road segmentation |
| U-Net | Skip connections between encoder and decoder | Medical image segmentation, fine boundary detection |
| SegNet | Lightweight encoder-decoder without skip connections | Resource-constrained environments |
| DeepLab | Atrous convolution for multi-scale context | Satellite imagery, urban scene segmentation |
The Role of Data Annotation in Semantic Segmentation
Data annotation is an inevitable step in building reliable semantic segmentation models. Accurately labeling data ensures that the model learns to recognize objects with precision.
Why opt for scrupulous image annotation?
- Consistency: Inconsistent labeling across images can confuse the model, leading to reduced accuracy.
- Accuracy: Fine boundary annotations are essential, especially in sensitive applications such as tumor detection in medical images.
- Class Granularity: Detailed distinctions between classes help models perform better, especially in domains like autonomous driving, where differentiating between road types is crucial.
| Annotation Attribute | Feature | Example |
| Consistency | Prevents model confusion | Consistent labeling of objects across all images |
| Accuracy | Ensures correct boundaries | Correctly annotating tumor boundaries in medical scans |
| Class Granularity | Improves detailed segmentation | Differentiating road types in autonomous driving |
Looking to improve your model training accuracy? Jump on the annotation journey with our free pilot!
Annotation Methods
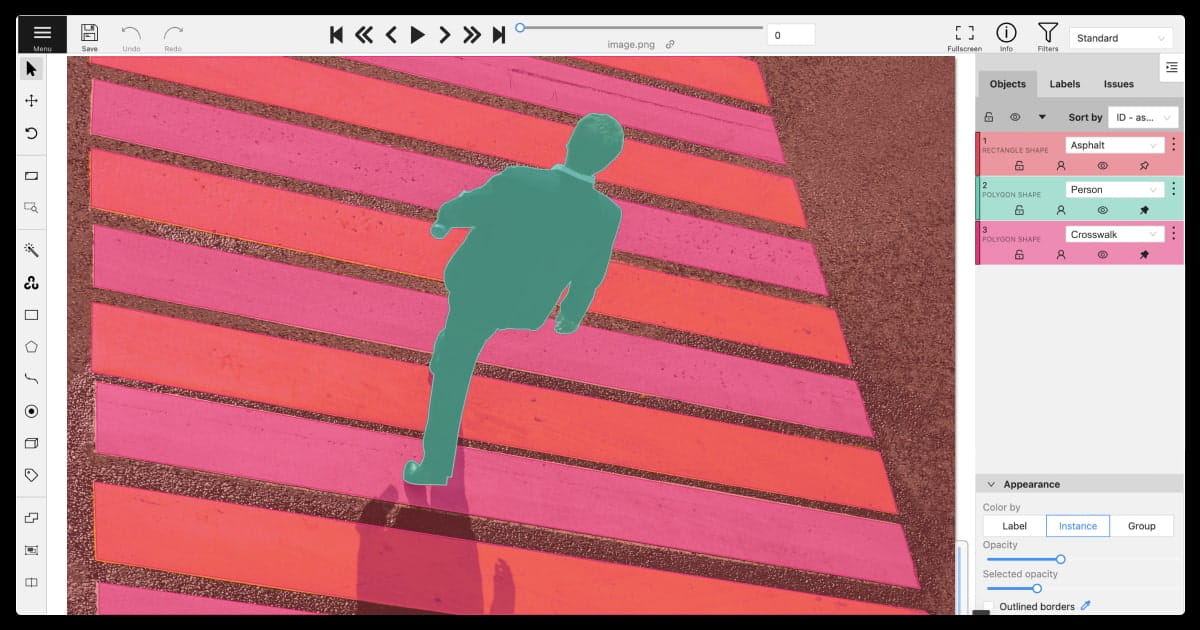
Selecting the appropriate annotation method depends on the project's scale, complexity, and available resources. Manual annotation is best suited for small datasets requiring high precision, such as medical imaging, where accuracy is paramount. Semi-automated annotation works well for larger datasets, as models assist annotators, reducing the workload.
Fully automated annotation is the most suitable choice when it comes to extremely large datasets or when time is a critical factor. However, it often requires manual review for ensuring the accuracy of complex or nuanced data.
| Annotation Technique | Advantages | Drawbacks |
| Manual Annotation | High accuracy | Time-consuming, expensive |
| Semi-Automated Annotation | Faster annotation process | Requires some manual correction |
| Fully Automated | Efficient for large datasets | Lower initial accuracy, needs human review |
Data Augmentation for Semantic Segmentation
Data augmentation enhances training datasets by introducing variations, which improves model robustness and generalization. Through the application of transformations to existing images, the diversity of the data is increased, allowing models to handle a wider range of scenarios effectively.
Geometric Transformations
Geometric transformations are among the most common and straightforward data augmentation techniques used to improve the robustness of segmentation models. By applying simple modifications like rotations, translations, scaling, and flips, the model learns to recognize objects regardless of orientation or positioning. They help increase data diversity without changing the semantic meaning of the image. This ensures that the model becomes robust to variations in orientation.
Noise Injection and Blur
Real-world data is often noisy, particularly in medical imaging or satellite surveillance, where image quality may suffer from external factors like equipment limitations or environmental conditions. Adding noise or blurring to training images helps models learn to recognize patterns in imperfect conditions, making them more resilient to real-world variability. Models handle noisy or imperfect data, such as low-quality medical images or satellite imagery.
Synthetic Data Generation
When real-world data is scarce or expensive to gather, synthetic data generation becomes an invaluable tool. By using techniques like Generative Adversarial Networks (GANs), it's possible to generate artificial images that resemble real-world scenarios. This method is particularly useful for semantic segmentation tasks, where collecting and manually annotating massive datasets is both time-consuming and costly.
When we focus augmentation on areas of an image where minority classes appear, we make the model better at picking up those classes in real-time, without crowding the data with artificial samples.
 Co-Founder, Webineering
Co-Founder, Webineering
Real-World Applications of Semantic Segmentation
By accurately labeling each pixel in an image, segmentation helps machines understand their surroundings, make informed decisions, and deliver critical insights. Here are some key examples of how semantic segmentation is applied in various fields.
Autonomous Driving
It's thanks to the segmentation approach and data annotation for autonomous driving that autonomous vehicles understand their environment in real-time. They are able to identify roads, pedestrians, and other vehicles. CNN-based methods such as DeepLab and U-Net are commonly used, as they provide high accuracy in segmenting complex scenes.
Medical Imaging
In medical imaging, semantic segmentation dataset helps differentiate between organs, tissues, and pathological regions. Traditional techniques like active contour models and modern CNN-based architectures like U-Net excel in this field, offering high accuracy for critical tasks of artificial intelligence in healthcare, like tumor detection.
Satellite Imagery and Land Use Analysis
Satellite vs. drone imagery often require geospatial annotation to segment vast landscapes into categories such as vegetation, water bodies, and urban areas. CNN models like DeepLab are used for large-scale segmentation, while non-deep learning methods like the Watershed Algorithm can be effective for specific tasks, especially when computational resources are limited.
Agriculture and Crop Monitoring
With computer vision in agriculture, we can monitor crop health and analyze soil conditions. Techniques such as texture-based segmentation and color feature extraction allow for the identification of healthy crops, soil types, and the detection of diseases.
| Application Area | Technique | Usage |
| Autonomous Driving | CNN-based models (U-Net, DeepLab) | Efficient for real-time segmentation in complex scenes |
| Medical Imaging | U-Net, Active contour models | Accurate segmentation of tissues and abnormalities |
| Satellite Imagery | CNN-based and non-deep learning methods | Large-scale land use analysis |
| Agriculture and Crop Monitoring | Texture-based segmentation, CNN methods | Detect crop health and soil conditions efficiently |
By leveraging high-quality data annotation, using a combination of augmentation techniques, and optimizing model training, both deep and non-deep learning methods can achieve competitive performance across a wide range of applications. Combining traditional techniques with modern CNN-based models ensures that semantic segmentation remains a powerful tool in various fields.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How to label images for semantic segmentation?
To label images for semantic segmentation, each pixel in the image is manually or automatically assigned to a specific class (e.g., road, sky, vehicle). This can be done through manual annotation tools, semi-automated methods, or fully automated systems using pre-trained models.
When to use semantic segmentation?
Use semantic segmentation when precise, pixel-level understanding of an image is required, such as in autonomous driving, medical imaging, or satellite analysis. It's ideal for tasks that demand detailed object delineation and classification within complex scenes.
Can CNN be used for semantic segmentation?
Yes, CNNs are commonly used for semantic segmentation. They are highly effective in learning hierarchical image features, allowing for precise pixel-level labeling in tasks like object detection and scene understanding.
What are the methods for semantic segmentation?
Semantic segmentation methods include traditional techniques like color/texture-based segmentation, boundary detection, and region-based approaches. Modern methods primarily use CNN-based architectures such as FCNs, U-Net, SegNet, and DeepLab for more accurate pixel-level labeling.
Which neural network is best for semantic segmentation?
The usage of the neural network for semantic segmentation will depend on the specific use case. U-Net and DeepLab models are usually used the most. Both models offer high accuracy and flexibility for different tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.