LLM Inference: Techniques for Optimized Deployment

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is LLM Inference?
- Challenges of LLM Inference
- Understanding the Phases of LLM Inference
- LLM Inference Performance Metrics
- Techniques for Optimizing LLM Inference
- Advanced Techniques for LLM Inference Optimization
- Best Practices for LLM Inference for Optimizing Performance
- Tools and Frameworks for Efficient LLM Inference
- About Label Your Data
- FAQ

TL;DR
- LLM inference applies trained models to generate outputs for real-world tasks.
- Common challenges include high computational costs, latency, memory demands, and scaling issues.
- Optimize using techniques like model compression, distributed computing, and dynamic batching.
- Use tools like PyTorch, TensorFlow, ONNX Runtime, NVIDIA TensorRT, and cloud platforms.
- Follow best practices by aligning models with tasks, testing regularly, monitoring performance, and updating systems.
What Is LLM Inference?
LLM inference is the process where a trained large language model (LLM) generates outputs based on your input. It applies patterns learned during training to make predictions or respond to prompts. For example, when you ask a chatbot a question, the model uses inference to generate its reply.
Inference is how a model performs tasks after training. Some common tasks include:
- Predicting text completions.
- Classifying text or other data.
- Generating new content, such as summaries or translations.
It’s the stage where the model transitions from being developed to being useful for practical applications.
How Inference Differs From Training
Take a look at the table below to understand the key differences between LLM inference vs training.
| Aspect | Training | Inference |
| Goal | Teach the model using data. | Apply learned patterns to inputs. |
| Data | Large datasets with labels. | Real-world inputs from users. |
| Resource Use | High (computing and storage). | Moderate but can still be costly. |
| Output | Updated model parameters. | Predictions or responses. |
Training is computationally heavy and resource-intensive, while inference focuses on applying the trained model effectively. Here, data annotation is the cornerstone of training accurate and reliable LLMs.
Besides, choosing the right data annotation company can make all the difference in ensuring your LLM is trained on accurate, high-quality data.
Why You Should Care About LLM Inference Efficiency
Efficient LLM inference is important for several reasons:
- Speed: Faster inference improves response times for applications like chatbots or search systems.
- Cost: It reduces computing expenses, especially in large-scale deployments.
- Scalability: Optimizing inference lets you handle more users without delays or bottlenecks.
LLM inference is also integral to fields like automatic speech recognition, where quick and accurate responses are crucial. For industries like GIS, integrating geospatial annotation can significantly enhance model accuracy when processing location-based data. LLM inference has also shown promise in applications like image recognition , where rapid processing is necessary for real-time analysis.
Challenges of LLM Inference
LLM inference is resource-heavy, and making it efficient isn’t always straightforward. You need to balance performance, cost, and scalability while addressing common obstacles.
Here’s what often stands in the way:
Computational Costs
Running large models like GPT-4 requires significant processing power. This translates to:
- Hardware expenses: High-end GPUs, TPUs, or specialized chips are essential but expensive.
- Energy consumption: Operating these models at scale increases electricity usage, which can add up quickly.
- Ongoing costs: Unlike training, inference runs continuously in live applications, increasing long-term spending.
Latency and Scalability Issues
Inference speed directly impacts user experience, especially in real-time applications. Problems include:
- Slow response times: Models with billions of parameters take time to process inputs.
- Scaling limitations: Handling multiple users simultaneously requires additional resources, which can strain infrastructure.
- Network delays: In cloud-based setups, data transfer times can also contribute to latency.
Memory Requirements
Large models consume significant memory to store parameters, intermediate results, and outputs:
- Models like GPT-4 require tens to hundreds of gigabytes of RAM.
- Memory bottlenecks can occur when infrastructure isn’t optimized for serving these models.
These challenges underscore the need for optimization strategies to reduce LLM inference cost, improve speed, and ensure reliable performance.
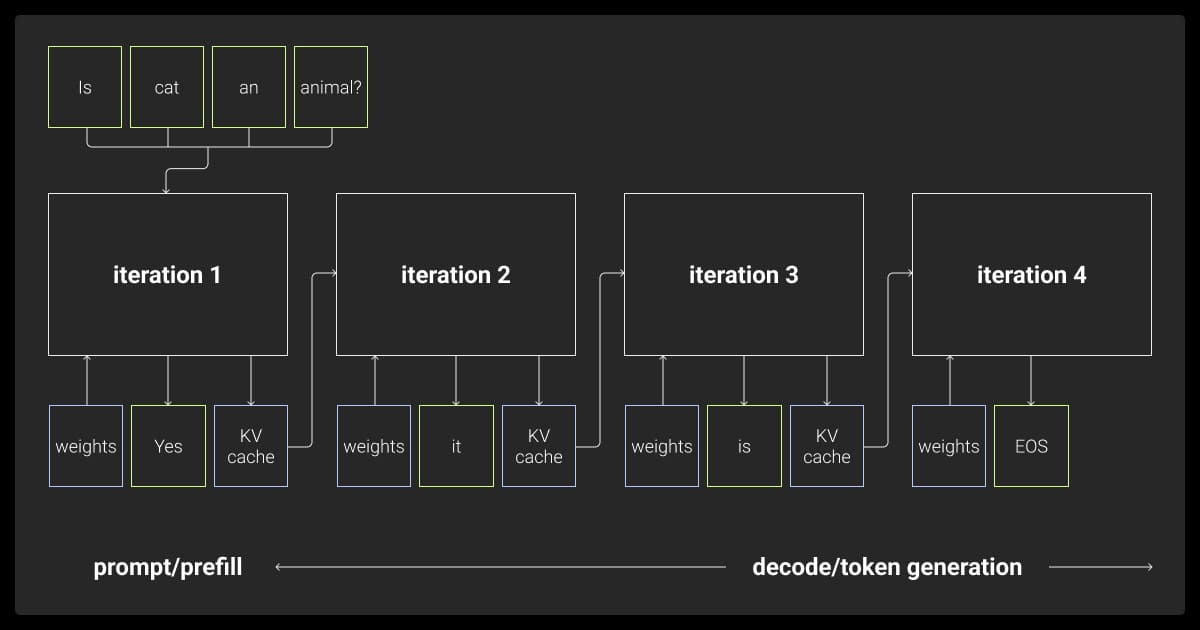
Understanding the Phases of LLM Inference
LLM model inference works in two primary phases, each crucial for generating accurate and context-aware responses:
Prefill Phase
During this phase, the input is converted into tokens. These tokens represent words or parts of words, which the model can understand and process efficiently.
Decode Phase
In this phase, the model generates a response by predicting the next token based on the context of the input and prior knowledge. The model repeats this process until the response is complete.
Understanding how does LLM inference work helps in fine-tuning the inference process and improving response generation.
LLM Inference Performance Metrics
Understanding the performance of LLM inference is crucial for optimizing deployment. Key metrics include:
Latency
Measures how long it takes for the model to respond after receiving an input prompt. Lower latency is essential for real-time applications such as chatbots and language translation.
Throughput
Refers to the number of requests or tokens processed per second. This helps evaluate the scalability of the model when handling multiple users or queries simultaneously.
These metrics allow you to measure and improve the efficiency of LLM inference, ensuring better performance in production environments.
Up next, let’s explore proven techniques to make LLM inference more efficient.
Techniques for Optimizing LLM Inference

LLM inference optimization helps you reduce costs, improve performance, and scale your applications effectively. Below are proven techniques to make your model run faster and more efficiently.
Model Compression
Compressing your model reduces its size without significantly affecting performance. Common methods include:
- Quantization: Converts model weights to lower precision (e.g., from 32-bit to 8-bit) to decrease memory usage and speed up computations.
- Pruning: Removes unnecessary parameters, focusing only on those most critical for inference tasks.
- Weight Sharing: Reuses parameters across layers to reduce redundancy.
Distributed Computing and Parallelization
Splitting inference workloads across multiple devices ensures faster processing:
- Use GPUs or TPUs for parallel processing.
- Distribute computations across servers to handle large-scale requests.
- Optimize communication between devices to reduce bottlenecks.
Efficient Serving Architectures
Choosing the right architecture for model deployment can make a significant difference:
- Use ONNX Runtime or TensorRT to speed up inference.
- Consider specialized solutions like NVIDIA Triton for scalable, multi-model serving.
- Implement serverless architectures for handling sporadic workloads cost-effectively.
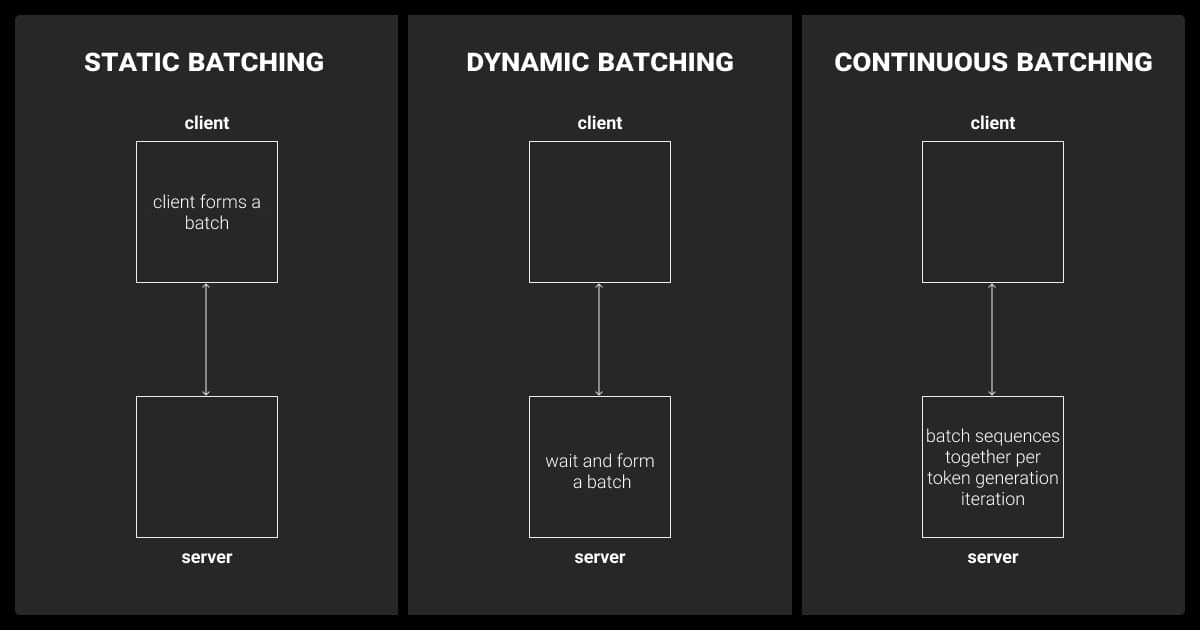
Dynamic Batching
LLM batch inference groups multiple requests together for more efficient processing:
- Combine smaller requests to improve resource utilization.
- Adjust batch size dynamically based on incoming traffic to reduce latency.
Knowledge Distillation
Deploy smaller, distilled versions of your model for specific tasks:
- Train a smaller model (student) to mimic the performance of a larger model (teacher).
- Use the distilled model for use cases where lower precision is acceptable.
Configuration Options
Configuring key parameters during LLM model inference can optimize your model’s performance for specific tasks. Some configuration options include:
- Max tokens sets the total number of tokens (input + output) the model processes.
- Temperature controls output randomness.
- Top-k sampling limits the number of tokens considered, speeding up processing.
Optimization via Quantization
Quantization reduces the bit-width of model weights and activations, making the model more efficient for inference:
- Convert weights from floating-point precision (32-bit) to lower-bit versions (e.g., 8-bit or 4-bit) to cut memory usage.
- This reduces computational requirements, allowing models to run faster, especially on resource-constrained devices like mobile phones.
Quantization has been a game-changer for us. By reducing the precision of our model weights, we were able to cut our inference costs almost in half while maintaining 95% of the original performance. This allowed us to run more efficient, cost-effective models without sacrificing accuracy, and it made deploying at scale much more feasible for our team.

 Developer, TROYPOINT
Developer, TROYPOINT
These techniques improve speed, reduce resource use, and ensure scalability. Next, we’ll discuss the tools and frameworks that can simplify the LLM inference optimization process.
Advanced Techniques for LLM Inference Optimization
While the techniques mentioned earlier are effective for improving LLM inference, certain advanced techniques are used in large-scale or resource-heavy deployments. These methods provide additional speed, scalability, and performance improvements.
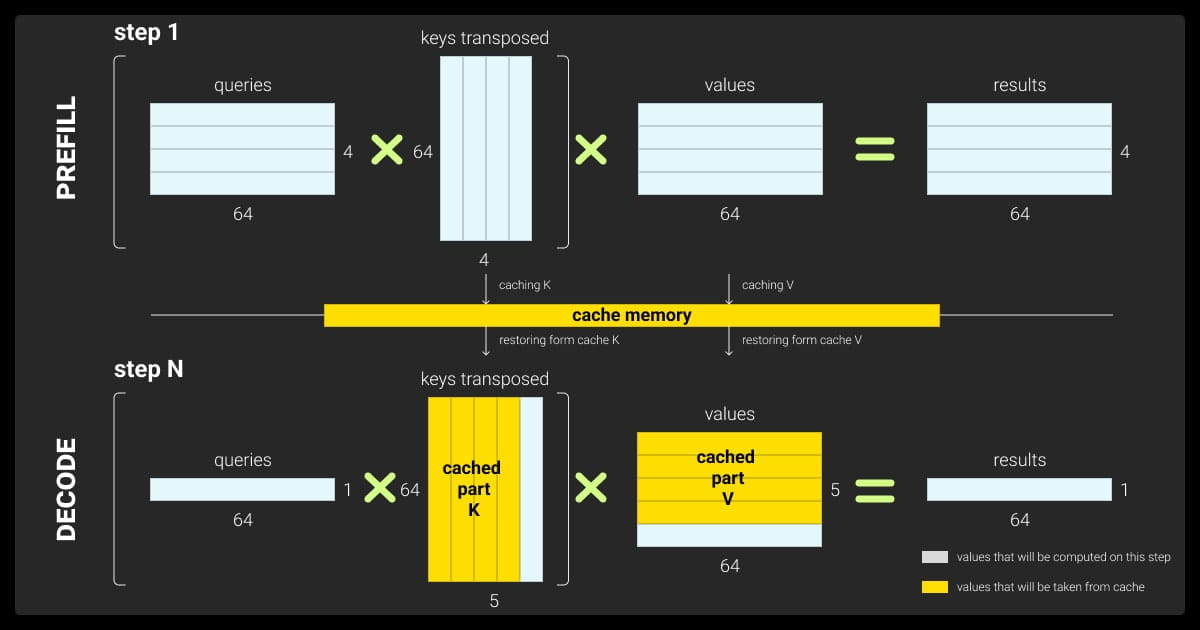
KV Caching
Key-value (KV) caching optimizes the generation process by storing key-value pairs from previous tokens, reducing the need for recomputation as the model generates new tokens.
In-Flight Batching
In-flight batching improves throughput by dynamically processing incoming requests, evicting finished sequences, and allowing new requests to be processed in parallel without significantly increasing latency.
Speculative Inference
Speculative inference uses a smaller, draft model to predict tokens quickly. If the predictions align with the primary model’s output, they are accepted; otherwise, they are discarded. This accelerates token generation without sacrificing accuracy.
Yet, for better accuracy and task-specific performance, LLM fine tuning is often required to tailor models to particular use cases.
Techniques such as prompt engineering and caching can also improve performance. The way queries are framed can have a big influence on response time and quality. Additionally, caching frequently requested data or intermediate results helps avoid redundant computations, speeding up inference and reducing the load on the system.
 Sr. Technical Consultant, WPWeb Infotech
Sr. Technical Consultant, WPWeb Infotech
Best Practices for LLM Inference for Optimizing Performance

To achieve reliable, efficient performance during LLM inference, you need a thoughtful approach to deployment and optimization. Below are key practices to follow.
On-Device Inference
On-device inference is a powerful approach for optimizing LLM for applications with real-time requirements. It offers significant benefits:
- Reduce latency by processing data locally to cut network delays and speed up responses.
- Enhance privacy by keeping sensitive data on-device for better security.
- Lower LLM inference cost by minimizing cloud reliance to reduce infrastructure and bandwidth expenses.
- Use lightweight models like Gemma-2 2B or StableLM 3B for efficient on-device performance.
Align Model Complexity With Your Use Case
- Choose models based on task requirements. Avoid deploying unnecessarily large models for simple tasks.
- Use fine-tuned versions of pre-trained models for domain-specific needs.
- Consider lightweight models for scenarios where speed is more important than precision.
Testing and Benchmarking
Regular testing helps identify inefficiencies and bottlenecks:
- Test latency, throughput, and memory usage under different loads.
- Use benchmarking tools like ONNX Benchmark or Hugging Face’s inference metrics.
- Compare inference times across different hardware configurations to find the best setup.
Continuous Monitoring
Monitoring your inference system in production is critical:
- Track metrics like response times, error rates, and resource usage.
- Implement alerts to detect unusual behavior or performance drops.
- Use tools like Prometheus or Grafana for real-time analytics.
Optimize Hardware Utilization
- Match hardware to your workload. For example, use TPUs for batch processing and GPUs for real-time requests.
- Configure hardware to maximize utilization while avoiding overprovisioning.
- Experiment with instance types if deploying in the cloud to balance cost and performance.
Regularly Update Models and Infrastructure
- Keep your models updated to benefit from the latest optimizations and features.
- Upgrade frameworks and tools to their latest stable versions.
- Reassess infrastructure requirements periodically as workloads evolve.
By following these practices, you can maintain consistent performance, reduce LLM inference cost, and ensure a smooth user experience.
To ensure the best performance, high-quality data annotation services are essential for training and fine-tuning large language models.
With my experience at AI Insider Tips, I've found that batch processing and model quantization are game-changers for handling large-scale LLM applications efficiently. Just last month, we reduced our inference costs by 40% by implementing dynamic batching and using smaller, fine-tuned models for specific tasks instead of always defaulting to the largest models.
 Co-Founder, AI Insider Tips
Co-Founder, AI Insider Tips
Tools and Frameworks for Efficient LLM Inference

Optimizing LLM inference often requires the right tools and frameworks. These solutions help you streamline deployment, reduce latency, and manage resource consumption effectively.
Popular Frameworks for Inference
Several machine learning frameworks are widely used for LLM inference:
- PyTorch: Known for flexibility, it’s commonly used for both research and production inference.
- TensorFlow: Offers robust deployment options, especially when combined with TensorFlow Serving.
- Hugging Face Transformers: Simplifies the use of pre-trained LLMs and supports efficient inference with libraries like transformers and accelerate.
Specialized Tools for Optimization
Specialized LLM inference optimization tools focus on speed and scalability:
- ONNX Runtime: Converts models to a universal format for faster inference across platforms.
- NVIDIA TensorRT: Optimizes LLMs for deployment on NVIDIA GPUs, offering significant speed improvements.
- DeepSpeed: Developed by Microsoft, this tool provides optimization features like mixed precision and ZeRO-Inference for scaling.
Cloud-Based Solutions
Cloud platforms provide managed services tailored for inference:
- AWS Inferentia: Offers cost-effective, hardware-optimized inference for large models.
- Google TPU: Designed for high-speed, large-scale inference tasks.
- Azure Machine Learning: Includes features like autoscaling and support for multiple inference frameworks.
Comparing LLM Inference Tools
| Tool/Framework | Key Features | Best For |
| PyTorch | Flexible, developer-friendly. | Custom inference pipelines. |
| TensorFlow | Scalable, production-ready serving. | Enterprise-grade deployments. |
| Hugging Face | Pre-trained models, user-friendly APIs. | Quick setup for popular LLMs. |
| ONNX Runtime | Universal model format, fast execution. | Cross-platform deployment. |
| TensorRT | GPU optimization, reduced latency. | GPU-intensive applications. |
| AWS Inferentia | Cost-efficient hardware acceleration. | Budget-conscious cloud inference. |
These tools and LLM inference frameworks simplify the process of deploying optimized LLMs. In the next section, we’ll dive into best practices to ensure consistent and reliable performance.
If you’re looking to take your LLM performance even further, our LLM fine-tuning services can help optimize your model for your specific needs.
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is LLM inference?
LLM inference is the process of using a trained large language model to generate outputs, such as predictions or responses, based on new input data.
What is the difference between LLM training and inference?
Training teaches the model to recognize patterns using large datasets, while inference applies those learned patterns to make predictions or generate outputs in real-world scenarios.
What are the stages of LLM inference?
- Input preprocessing: Formatting the input data for the model.
- Model execution: Running the input through the model to generate results.
- Output post-processing: Formatting the results for the end user or application.
How to improve LLM inference?
- Use techniques like model compression, distributed computing, and dynamic batching.
- Optimize infrastructure with tools like ONNX Runtime or TensorRT.
- Monitor performance and scale hardware resources appropriately.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.