Mixture of Experts LLM: Advanced Techniques Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What is the Mixture of Experts in LLMs?
- How Mixture of Experts LLM Works
- Advantages and Disadvantages of Mixture of Experts LLM
- Training Techniques for Mixture of Experts LLM
- Inference Strategies and Optimization in Mixture of Experts LLM
- When to Use Mixture of Experts LLM
- About Label Your Data
- FAQ

TL;DR
- Mixture of Experts is an ML technique that assigns tasks to specialized sub-models for optimized efficiency and performance.
- A gating network dynamically routes inputs to the most relevant experts based on patterns.
- Experts focus on specific tasks, improving accuracy and reducing computation.
- MoE models excel in scalability but require high memory and complex training coordination.
- Training techniques include auxiliary loss, load balancing, and task-specific fine-tuning.
- Inference efficiency is achieved by activating only necessary experts dynamically.
- Applications include multilingual NLP, image recognition, multi-modal AI, and low-resource languages.
- MoE enables flexible and modular architectures for diverse and complex AI challenges.
What is the Mixture of Experts in LLMs?
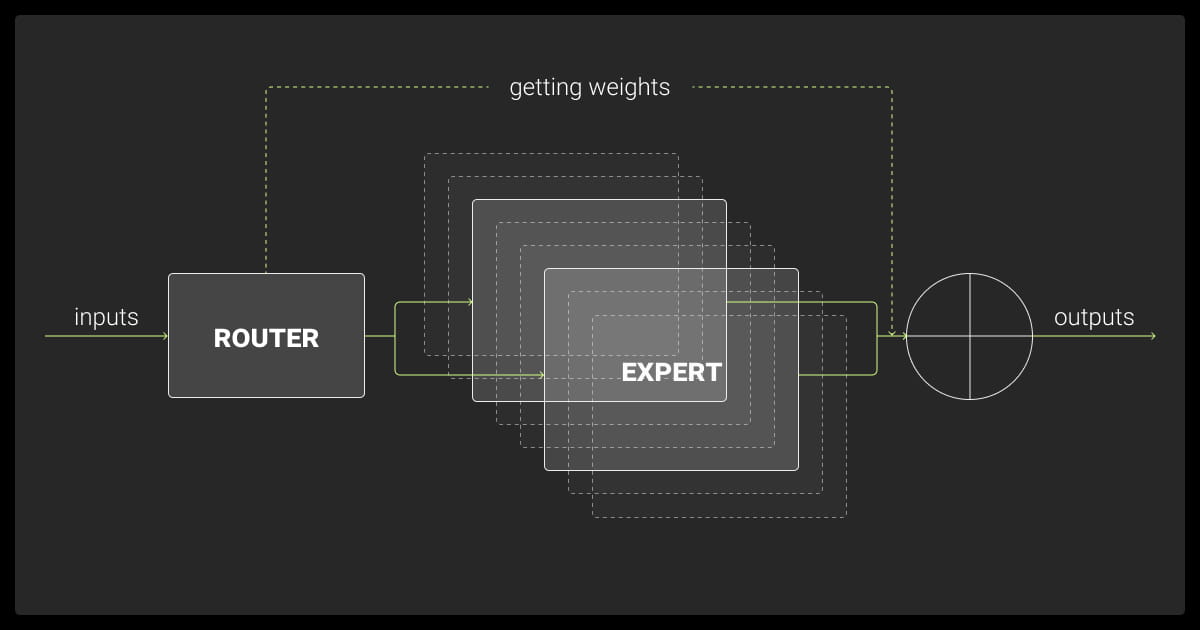
Mixture of Experts is a machine learning technique that assigns tasks to specialized sub-models for optimized efficiency and performance.
Large Language Models (LLMs) are powerful, but they demand significant computational resources. Mixture of Experts LLM (MoE) supported by the work of a reliable data annotation company, offers a way to scale LLMs while optimizing resource use. An LLM mixture of experts splits complex tasks into smaller ones, assigning them to specialized networks called experts.
In Mixture of Experts, tasks are split among specialized networks called experts. Each expert handles specific subtasks like syntax or semantics. By using only the necessary parts of the model, MoE can scale to massive sizes without proportional increases in computation or memory costs.
How Mixture of Experts LLM Works
The mixture of experts model LLM operates through two main phases: training and inference. Both are designed to ensure efficiency while leveraging the specialization of the experts.
Training Phase
Training an LLM mixture of experts model is different from traditional dense models. Instead of training one large network, MoE trains experts and the gating network collaboratively.
Expert Training
Each expert focuses on specific tasks or subsets of data, often relying on high-quality data annotation to refine their specialization. For example, in a language model, one expert might specialize in syntax, while another focuses on semantics. This targeted approach allows experts to perform well on distinct parts of the problem.
Gating Network Training
The gating network learns to assign tasks to the most suitable experts. It does this by creating a probability distribution over all experts and selecting the top ones based on input data.
Joint Training
Experts and the gating network are trained together, optimizing their interaction. A combined loss function ensures the experts and gating network work in harmony, balancing performance and task assignment.
Inference Phase
During inference, MoE minimizes computational overhead while maintaining accuracy.
Input Routing
The gating network evaluates incoming data and decides which experts should handle it. For instance, in a translation task, complex sentences might be routed to experts skilled in linguistic structures.
Expert Selection
Only the most relevant experts are activated for each input, reducing resource usage. Typically, just one or two experts are engaged at a time, optimizing efficiency.
Output Combination
The outputs from the selected experts are merged into a unified result. Techniques like weighted averaging or learned combinations are used to ensure accurate predictions.
Routing Algorithms
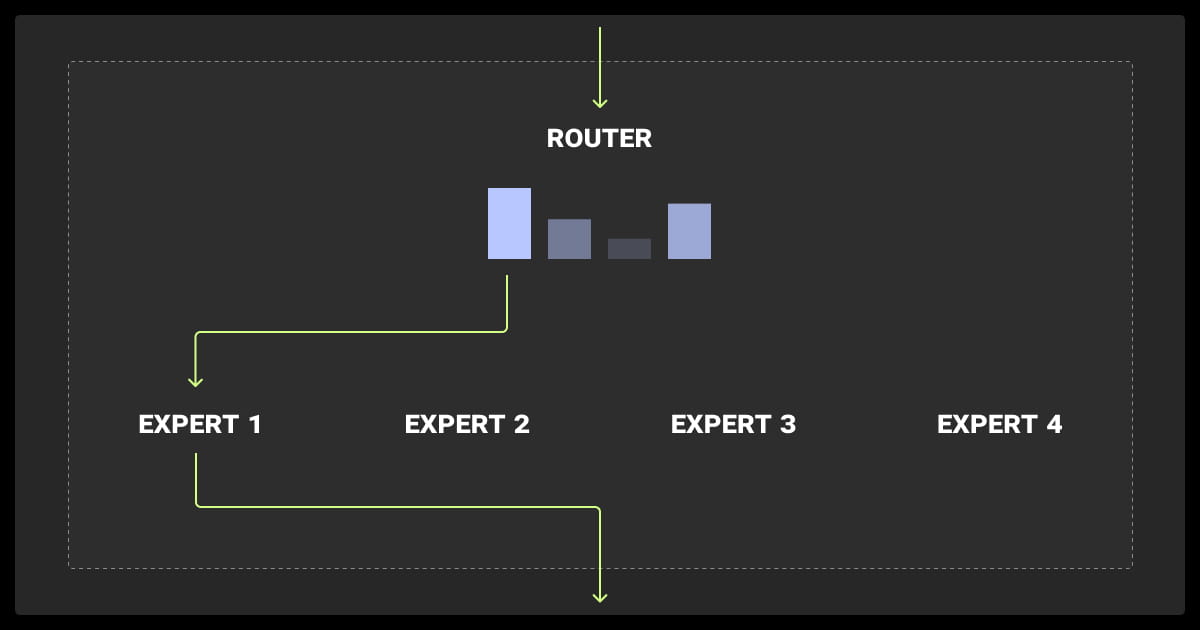
Efficient routing is crucial for MoE’s success. Common methods include:
- Top-K Routing: Activates the top K experts with the highest scores for a given input.
- Sparse Routing: Limits the number of experts activated, reducing computational costs.
- Expert Choice Routing: Allows experts to choose the inputs they are best suited to process, enhancing load balancing.
This architecture ensures that each task is handled by the best-suited experts, optimizing both performance and resource use.
Advantages and Disadvantages of Mixture of Experts LLM
The MoE LLM approach offers a range of benefits but also comes with challenges.
The mixture of experts approach makes large language models more efficient by dividing complex, domain-specific tasks among specialized sub-models or 'experts.' This ensures responses are accurate, context-aware, and scalable, boosting both performance and adaptability.

 Co-Founder & HR Director, Click Intelligence
Co-Founder & HR Director, Click Intelligence
The table below highlights the key advantages and disadvantages:
| Aspect | Advantages | Disadvantages |
| Efficiency | Activates only relevant experts, saving computation and speeding up processing. | Gating network introduces additional computation during inference. |
| Scalability | Scales to trillions of parameters without proportional increases in compute costs. | Requires high memory to store all experts, even if only a few are active. |
| Flexibility | Experts can be added, modified, or fine-tuned for new tasks without rebuilding the entire model. | Parallelism and resource management make deployment more complex. |
| Specialization | Experts focus on specific subtasks, improving accuracy for diverse challenges. | Coordinating expert specialization during training is challenging. |
| Fault Tolerance | Modular design minimizes the impact of any single expert’s failure on overall performance. | Balancing expert utilization requires auxiliary loss and careful routing optimization. |
Training Techniques for Mixture of Experts LLM
Training mixture of experts (MoE) models requires balancing efficiency, stability, and expert utilization. Fine-tuning MoEs introduces additional complexities. Examples include overfitting and specialized adjustments, but the right strategies ensure these models perform optimally.
Efficient Pretraining
Sparse activation reduces computation by ensuring only relevant experts are engaged. Auxiliary loss plays a key role in preventing over-reliance on specific experts, promoting balanced activation. For instance, activating only two experts out of eight in a layer reduces FLOPs while maintaining high scalability.
By dynamically routing tasks to a specialized subset of experts instead of a monolithic model, we improve both efficiency and scalability. This selective activation cuts down computation time, allowing us to generate results faster and more resource-efficiently.
 Founder, Omnitrain
Founder, Omnitrain
Load Balancing
Balancing expert utilization is critical for stable training. Techniques like KeepTopK (selecting the top K experts for each input) and Router Z-Loss (penalizing extreme logit values in the gating network) ensure that all experts contribute meaningfully without bottlenecks.
Expert Capacity and Token Overflow
Each expert has a set token capacity, defined by the capacity factor, limiting the number of tokens it can process. When limits are exceeded, tokens are routed to the next expert or overflowed to another layer. Properly setting the capacity factor prevents overloading and ensures smooth operations.
Fine-Tuning Strategies
Fine-tuning MoEs involves adapting the process to specific tasks. Higher dropout rates for sparse layers reduce overfitting. Smaller batch sizes and faster learning rates improve sparse model performance.
Adjusting auxiliary loss helps balance expert usage or enhance specialization for specific tasks. LLM fine tuning can also dynamically adjust the number of active experts. It engages more of them for complex inputs and fewer for simpler ones. This ensures both speed and accuracy.
Stabilizing Training
To manage instability in training:
- Dropout: Apply dropout selectively to sparse layers. This step deactivates random connections during training, helping to reduce overfitting and enhance model robustness.
- Selective Precision: Use mixed precision, such as bfloat16, for expert computations. This technique lowers memory requirements without compromising model accuracy, making training more resource-efficient.
Combining these methods during both pretraining and fine-tuning allows MoE models to tackle diverse tasks effectively. These strategies ensure better efficiency and adaptability. At the same time, they maintain model stability throughout the training process.
Inference Strategies and Optimization in Mixture of Experts LLM
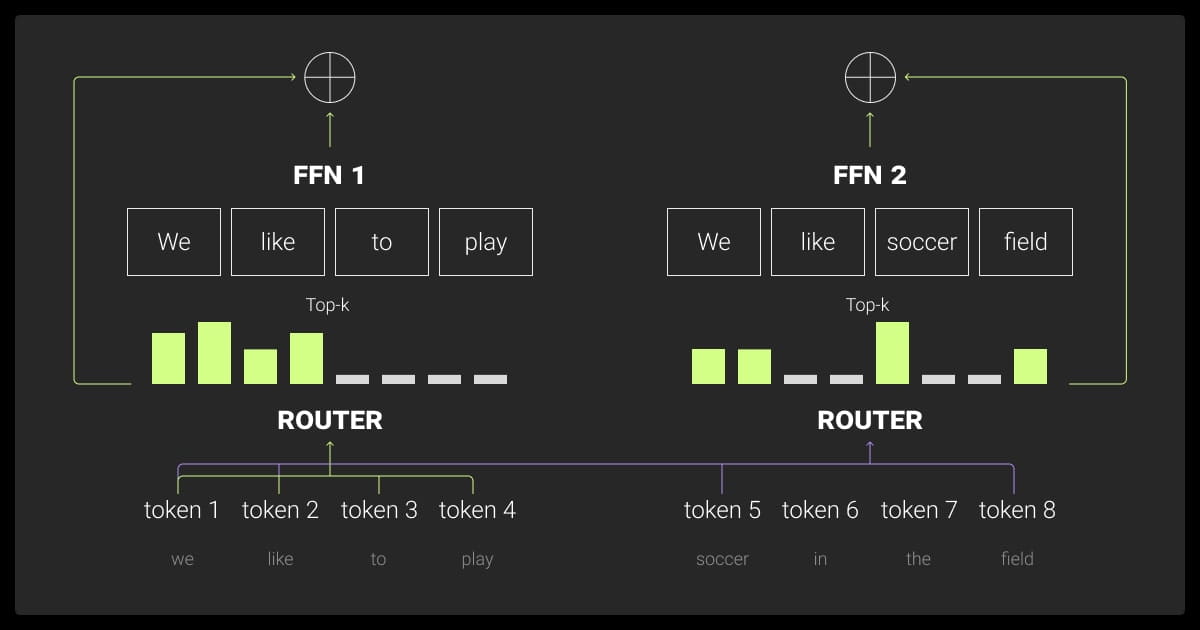
Inference in mixture of experts (MoE) models is designed to balance efficiency and performance. By activating only the necessary experts, MoE reduces computation while maintaining accuracy.
Efficiency in Inference
During inference, only a subset of experts is activated for each input. This selective activation ensures that fewer parameters are used compared to dense models. For example, in a model with eight experts, activating just two minimizes computational costs without sacrificing accuracy. However, high VRAM is still required to store all experts in memory, even if only a few are used.
Task-Specific Routing
The gating network optimizes routing for specific tasks or domains.
- In multilingual models, inputs can be routed to experts specializing in different languages.
- For tasks like retrieval-augmented generation (RAG), the router prioritizes experts trained on retrieval tasks, reducing response times.
This targeted routing enhances performance and efficiency in domain-specific applications.
Output Combination
After experts process the input, their outputs must be merged into a single result. Methods such as weighted averaging (based on gating confidence scores) or learned combinations are used to produce accurate predictions tailored to the task at hand.
Distillation to Dense Models
For resource-constrained environments, MoE models can be distilled into smaller dense models. Distillation retains much of the sparse model’s performance benefits while significantly reducing memory and compute requirements.
Dynamic Expert Allocation
Dynamic expert allocation optimizes inference efficiency by tailoring the number of active experts to the complexity of the task:
- Fewer experts are activated for simple inputs, speeding up processing and conserving resources.
- More experts are engaged for complex tasks, ensuring high accuracy and thorough handling of intricate data.
This strategy strikes a balance between speed and precision, adapting seamlessly to diverse task requirements.
When to Use Mixture of Experts LLM
Mixture of experts (MoE) has become a cornerstone for solving complex problems across various fields. Its efficiency, scalability, and specialization make it ideal for tasks in NLP, computer vision, and beyond.
Natural Language Processing (NLP)
Natural Language Processing (NLP) benefits significantly from the mixture of experts architecture. By leveraging specialized experts, MoE enhances efficiency and accuracy across complex linguistic tasks, ranging from multilingual translations to in-depth text comprehension.
The mixture of experts method promotes specialization. Different experts can focus on distinct areas or types of language understanding. This specialization leads to improved performance on specific tasks while maintaining the overall robustness required for diverse applications.
 Founder & CEO, Vortex Ranker
Founder & CEO, Vortex Ranker
Large-Scale Multilingual Models
MoEs power models like Microsoft Z-code, enabling efficient translations across dozens of languages. By selectively activating language-specific experts, these models deliver exceptional scalability without excessive computational costs.
Text Summarization and Question-Answering
Routing inputs to task-specific experts improves accuracy. For example, an expert specializing in syntax may handle sentence structure, while another expert focuses on semantics for deeper understanding.
Computer Vision
The mixture of experts (MoE) architecture has made significant strides in the field of computer vision. By introducing specialized experts into Vision Transformers, MoE enhances the efficiency and accuracy of image processing tasks, adapting dynamically to the complexity of the input
Vision Transformers (ViTs)
Google’s V-MoEs integrate MoE with Vision Transformers to process images dynamically. This approach enhances tasks like image recognition, as critical image patches are routed to specialized experts, improving both speed and accuracy while optimizing resource use.
Dynamic Scaling
In V-MoEs, the number of active experts adjusts based on the complexity of the image. This ensures faster processing for simple inputs while maintaining accuracy for more detailed images.
Emerging Use Cases
The flexibility and specialization of MoE architecture enable innovative applications across diverse domains. It offers task-specific expertise to tackle complex AI challenges effectively. MoEs are also being explored in personalized medicine, where experts analyze patient data for tailored treatments. Another example includes autonomous vehicles, enabling real-time decision-making.
Multi-Modal AI
MoEs are increasingly used in tasks combining text, images, and video. They also hold potential in automatic speech recognition, where experts in linguistic patterns can improve transcription accuracy and scalability. Experts specializing in each modality collaborate to create unified models for multi-modal challenges. Examples include AI-driven video analysis, interactive systems, or enhancing data annotation services for complex datasets.
Low-Resource Languages
MoEs excel at handling low-resource languages by fine-tuning experts on underrepresented datasets. They are also increasingly being applied to geospatial annotation tasks, where specialized experts can process and analyze location-based data efficiently. This inclusivity improves AI’s accessibility across diverse populations.
Expanding Potential
As AI applications grow in complexity, MoE continues to offer a modular, scalable solution. Its ability to adapt to new tasks and domains ensures that MoE remains at the forefront of modern machine learning.
About Label Your Data
If you need help with LLM fine-tuning task, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is a mixture of experts in LLM?
What is mixture of experts LLM? It is an architecture that divides tasks among specialized sub-models, called experts, with a gating network assigning inputs to the most relevant ones. This approach improves efficiency, scalability, and task-specific performance.
What is the efficient mixture of experts?
An efficient MoE activates only the most relevant experts for each input, minimizing computation while maintaining accuracy. This sparsity allows models to scale without significantly increasing resource requirements.
How does a mixture of expert work?
MoE operates by routing inputs through a gating network, which selects the best experts for processing. The experts' outputs are then combined to produce the final prediction, ensuring task-specific specialization and computational efficiency.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.