Text Annotation: Techniques to Label Data for NLP Projects

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Text Annotation Quality Defines NLP Model Performance
- Core Text Annotation Types (By Structure)
- Adapting Text Data Annotation to Common NLP Tasks
- Text Annotation and LLMs: Both Sides of the Pipeline
- Designing a Schema That Makes Text Annotation Work
- Text Annotation Tools to Manage at Scale
- Managing Text Annotation Velocity Without Losing Quality
- Preventing Label Drift in Long-Term NLP Projects
- Privacy, Compliance, and Secure Text Annotation Environments
- When In-House Annotation Hits a Wall
- About Label Your Data
- FAQ

TL;DR
- Bad annotation leads to bad models—it’s that simple.
- Different NLP tasks require different annotation techniques.
- High-quality annotation depends on clear schemas, training, and tool support.
- LLMs both need rich annotation and can help generate it.
- At scale, tools, QA loops, and reviewer feedback become critical.
Why Text Annotation Quality Defines NLP Model Performance

You’re pressed for time and you need your LLM to finish its training as soon as possible. What’s the harm in letting a few labels in your machine learning dataset slip? You may finish training sooner, but you’ll have to pull your model back to retrain the machine learning algorithm.
Without solid text annotation, AI can’t function properly and data annotation pricing increases significantly.
The Real Cost of Bad Labels
Here we need to take a step back and ask, “What is text annotation?” Or, more importantly, why is text data annotation so important?
Here, the garbage-in-garbage-out principle applies. Poor data annotation injects unnecessary noise into your training data. This confuses your model during downstream NLP tasks like entity recognition or text classification, which can lead to unpredictable inferences.
Say, for example, that your intent classification labels are inconsistent. Maybe you use “Cancel subscription” in one instance and “End membership” in another. The annotation of text means the same thing, but your model won’t know that. It’ll then focus on needless differentiations instead of the things that matter.
Another example is where your NER labels include overlapping spans that don’t make sense to the model. This could cause it to hallucinate relationships or entities. If you’re using technology like the Sora model, this could lead to very strange text-to-video conversions.
Worse yet, ambiguous ChatGPT data annotation often causes models to misfire in production. This can cause:
- Chatbot hallucinations and incorrect image recognition
- Poor ranking in a search engine
- Safety red flags in a content filter
- Unstructured text in data mining
Fixing these issues later is expensive, both in terms of re-labeling costs and eroding user trust. And how important is that trust? Did you know that 54% of Americans are worried about the use of AI in healthcare because they’re worried about false diagnoses? If your model malfunctions, it’s dead in the water.
What High-Quality Text Annotation Looks Like
It’s actually surprisingly easy to get the annotation text for natural language processing techniques right if you plan well. You need to make sure that it’s:
- Consistent across annotators
- Adheres to a well-defined schema
- Aligns with the model’s task domain
You need your reviewers to agree on the labels and document schema edge cases with plenty of examples. It’s also important to consider the domain context. Medical sentiment isn’t the same as retail sentiment.
High-quality annotation also respects the structure of the input. Nested entities? Captured cleanly. Ambiguous intent? Flagged and resolved. You should see minimal disagreement during QA and high model performance during testing.
You should always start with the best quality data you can. If you can’t source it yourself, data collection services may be helpful.
Core Text Annotation Types (By Structure)
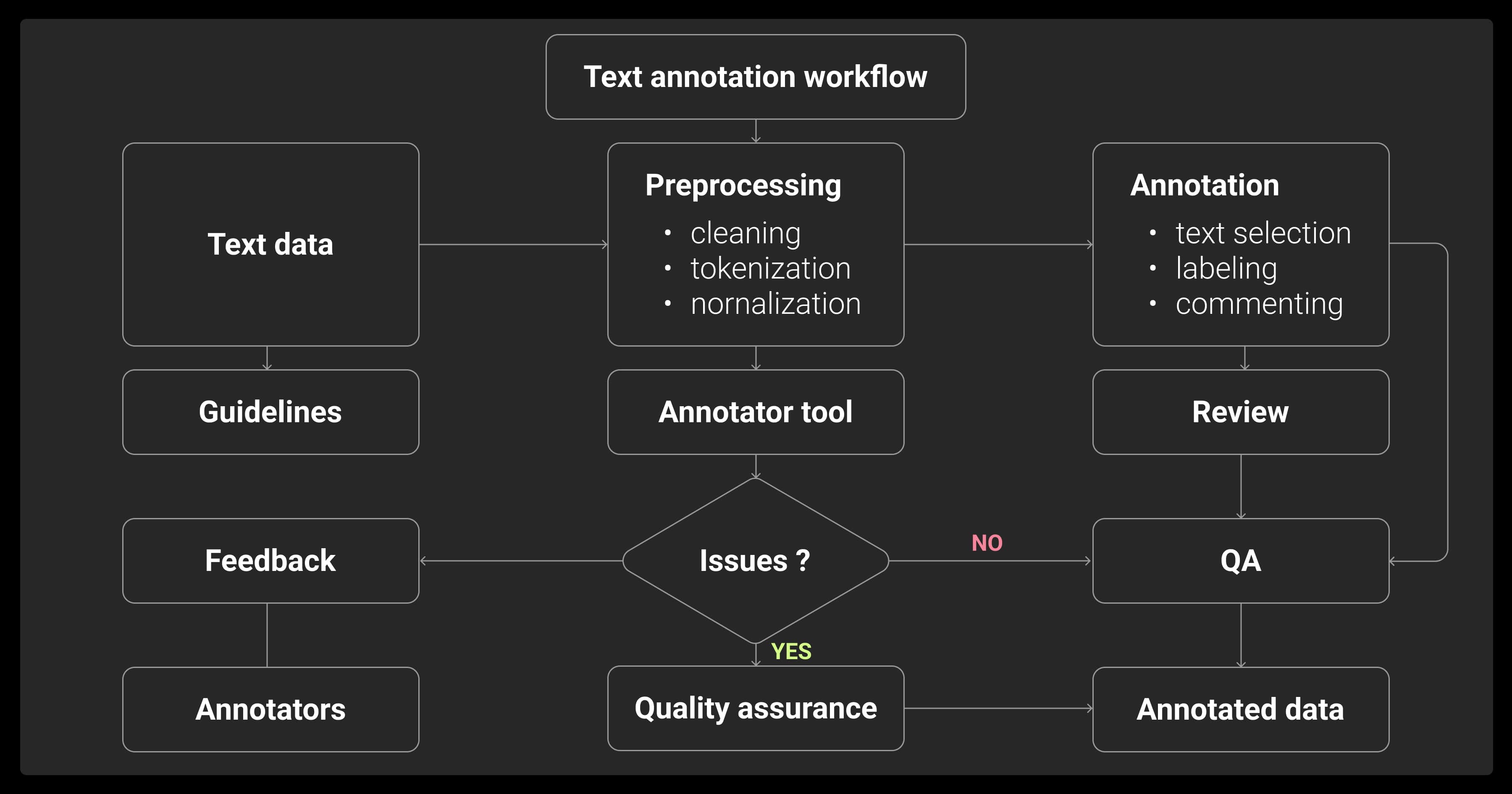
There’s no generic solution for text annotation. You need different types of labels for different tasks. Knowing which structure to use from the beginning makes your pipeline smoother and your models more accurate.
Sequence Labeling
This is essential for tasks like Named Entity Recognition (NER) or Part-of-Speech (POS) tagging. You’ll have to make sure to label each token, often using Begin-Inside-Outside (BIO) schemes.
Working with subword models like BERT? You’ll have to be careful with tokenizer alignment. If you miss a token split, your labels will drift.
Text annotation services for NLP in machine learning are careful to define potential edge cases that the machine might battle with. Take dates, for example, like April 15, 2024. April can be either a month or a name. You’ll need to decide how to deal with these edge cases upfront and stick with it.
Span Annotation
With this technique, you’ll tag free-form spans of text. We use this in entity linking, relation extraction, and nested entity work. Spans can overlap or nest inside each other, which adds complexity.
You need to find tools that support overlapping spans. Your annotators will need to highlight and tag quickly without toggling layers or breaking flow.
Classification Labels
These labels cover the big picture, and work at the sentence or document level. You’ll use this for things like spam detection, topic modeling, or sentiment analysis. The tasks may be:
- Binary, where you answer yes or no
- Multi-class where you choose one
- Multi-label where you choose all that apply
The UI is important here. If the interface is too cluttered, your team is bound to miss labels. The tooling should clearly separate single vs. multi-label setups.
Relationship Annotation
Here, you tag how two entities relate to one another. For example,“Person works_at Company” or QA-style links between questions and answers. You’ll often apply these annotations after you label each entity, which means your schema and tool must support chaining tasks.
In this case, you must make sure your annotators understand the logic. Are they labeling symmetric relations or directional ones? Do relationships cross sentence boundaries? Is it all becoming too complex to handle? You might want to outsource text annotation services.
Instruction, Ranking, and Preference Labels
This type is essential for LLMs. Here, text annotation services:
- Select the best response
- Rank multiple outputs
- Score the prompt quality
You can reduce the bias in such cases by hiring multiple annotators. You can also use pairwise comparisons for simpler decision-making, and gather multiple judgments to extract preference trends.
Adapting Text Data Annotation to Common NLP Tasks

You should always connect your annotation types to real-world NLP use cases. The way you annotate should reflect the task’s complexity, user expectations, and model goals.
Sentiment and Emotion Analysis
Sentiment is messy when it comes to text annotation machine learning. Take the phrase, “This is the best service I’ve ever had.” You might see something as sarcasm, whereas someone else views it as enthusiasm. That’s why you have to create clear guidelines.
You’ll have to define the scales clearly. You can do this with:
- Aspect-based reasoning
- Binary scales, as in positive or negative
- 5-point, as in very negative through to very positive
When you’re labeling for emotion, there’s bound to be overlap. Someone who’s frustrated is also likely to be angry. You’ll need to allow for multi-label options and give your team examples of the borderline cases.
Intent Detection and Text Classification
You need to design tradeoffs between coarse and fine labels to avoid inconsistencies when it comes to borderline cases. For example, if you group “Cancel subscription” and “End trial,” you have to label them the same.
You’ll need to be careful not to use too many fine-grained labels with text annotation for machine learning. It sounds like a clever solution, but can backfire in production. You should start with broad classes, then refine them once your model’s stable.
Named Entity Recognition (NER)
Named entity recognition is deceptively complex. Are dates entities? What about nested terms like “New York City Mayor Eric Adams”? What if two entities share a token? There are plenty of edge cases, label overlap, and cross-domain headaches.
You can deal with this by thoroughly training your annotators on edge cases. Decide how to handle overlap or ambiguity—especially in cross-domain corpora (legal vs. medical vs. e-commerce) upfront so you have a consistent response to it.
Dialogue and Multi-Turn Annotation
Are you training a conversational AI app? You’ll need to deal with speaker turns, user intent changes, emotional tone, or confusion. You’ll need:
- Timestamps
- Speaker roles
- Turn-level sentiment on occasion
You have to segment the conversations correctly. You have to take care not to mix up topics across turns, and track the flow of intent and responses across multiple messages. Not sure if you can manage? You should think of hiring a text annotation service.
Text Annotation and LLMs: Both Sides of the Pipeline
LLMs need strong annotation, but the good news is they can assist you much like a text annotation tool. Before you rush in, though, you need to understand the limits on both sides.
Text Annotation for LLMs
Training large language models with human feedback (RLHF) or fine-tuning them with safety checks requires careful labeling. You’ll need to schedule tasks like:
- Rating completions
- Identifying hallucinations
- Reviewing factuality or helpfulness
You’ll need annotators familiar with the model’s domain—especially for legal, medical, or code-related prompts. Use multiple reviewers to reduce subjectivity in rankings.
Using LLMs for Text Annotation Assistance
You can use GPT or similar models to pre-label data, suggest categories, or filter noise. But beware—LLMs hallucinate. They might generate wrong labels, especially in low-data domains, with great confidence.
You can set your LLMs the following tasks:
- Zero-shot or multi-shot labeling
- Auto-suggestion
- Auto-categorization
The way around this is to let the LLM pre-label the data, but let your human team review it. You shouldn’t fully automate unless you’ve benchmarked the model’s accuracy with a holdout test set.
One more word of warning, you have to choose the right LLM. In 2023, Claude 3 Opus was the most popular model, accounting for an average of 84.83%.
Designing a Schema That Makes Text Annotation Work
Schema design is the hidden engine of high-quality annotation. Aim to get it right from the start, or it’ll cost a fortune to fix later.
Start Simple
It’s always better to start off simply with three to five categories. If you use too many classes at once, you’ll confuse your annotators, which will slow your project. You can always add more categories later.
Add Edge Cases and Examples
You need to include actual text samples in your annotation guide. Be sure to choose some tricky ones and edge cases. Show your team what a borderline positive looks like and clarify ambiguous intent. Your team will learn best from examples, not vague theoretical notes.
Multi-Label vs. Multi-Class
The choice you make depends on the task design. You might use a multi-class option for sentiment and switch to a multi-label one for emotion detection. What you shouldn’t do is to make everything multi-label. It’ll slow down annotation and complicate the modeling. Rather, choose what matches the real-world use best.
Avoid making everything multi-label—it slows down annotation and complicates modeling. Choose what matches real-world use.
Text Annotation Tools to Manage at Scale
The right tools don’t just speed things up—they make your data cleaner and your team more productive.
What to Look for in a Text Annotation Platform
You should look for useful features like:
- Span support
- Reviewer modes (to compare labels)
- Schema control
- Versioning
- Export options like JSON or CSV
You should also make sure your platform supports entity linking and overlapping spans, if necessary.
Wondering which of the NLP text annotation tools is the best for you? Read a comparison of text annotation tools here.
Assisted Labeling and Model-in-the-Loop Workflows
Is pre-labeling a bad idea with a weak model? It doesn’t need to if you manage things properly. You can speed things up but should always let your human team review the results. They must be able to override suggestions.
Don’t want to check every speck of data? Use confidence thresholds to flag uncertain predictions. If you’re working with a large dataset, you should set up a review queue so you spot check data to catch systemic issues before they grow.
We use spaCy to do initial markup, then have our annotators review and refine it, which cut our inconsistency rate by half. The key is to start small with a test set of 100 items, measure agreement rates, and gradually expand.

 CEO, PlayAbly.AI
CEO, PlayAbly.AI
Managing Text Annotation Velocity Without Losing Quality
You can balance speed and quality with careful tracking.
Throughput Benchmarks by Task Type
You need to be realistic about how many examples your model can process per hour. Here are some guidelines about how many samples the typical LLM can process in an hour:
- NER: 100-200
- Sentiment: 300-500
- Relation Extraction: 50-100
These figures change depending on the domain and its complexity.
Monitoring Fatigue and Quality Drop
How do you know your team is battling? You’ll notice signs like:
- Increased label time
- Rising disagreement
- Slower review rates
- Higher rejection rates
These signs either mean that your annotators are confused about the schema or are starting to burn out. You can prevent this by rotating tasks, setting daily caps, and using breaks to keep the quality consistent.
Metrics That Actually Reflect Annotation Health
You need to keep track of the metrics that indicate how healthy your model is. These include:
- Disagreement rates
- Reviewer rejection rates
- Time-per-sample
- Label entropy
These are more useful than a plain volume measurement because they show accuracy.
Divergence heatmaps visualize annotation discrepancies across different annotators or sessions… This helps in identifying patterns in annotation discrepancies and addressing them efficiently, thereby improving the overall quality and consistency of text annotations.
 Founder, Deep AI
Founder, Deep AI
Preventing Label Drift in Long-Term NLP Projects
As your team grows or guidelines evolve, annotation quality can drift. You need to stay ahead of this.
Schema and Guidelines Need Versioning
You must track schema versions and explain the reason for updates. If you change a guideline, you must log why. This will help your reviewers adjust and prevent confusion when it comes to older labels.
Use Disagreements to Improve Guidelines
Don’t just reject labels—ask your annotators what confused them. Their feedback helps tighten your schema and avoid future mistakes.
Privacy, Compliance, and Secure Text Annotation Environments
Text data often contains sensitive information. Treat it accordingly.
How to Handle PII in Text Data
Redaction vs. masking vs. anonymization—what works for NLP?
Choose your redaction approach:
- Replace names with [PERSON]?
- Mask with hashes? Fully anonymized?
What you choose depends on downstream use.
For NLP modeling, partial redaction (e.g., masking user IDs but keeping sentence structure) often works best.
Secure Labeling Options for Sensitive Domains
In healthcare, finance, or government NLP projects, you’ll need secure workflows: air-gapped networks, vendor NDAs, and access controls for annotators. Don’t cut corners here.
When In-House Annotation Hits a Wall
How do you know when it’s time to call in a data annotation company? At some point, your team will hit capacity or expertise limits.
Here are some warning signs that you need to think about hiring data annotation services:
- Review backlogs growing
- Label throughput stalling
- Annotator disagreement
- Accuracy plateaus
What’s changed? Are you overloading your team, or are you asking them to annotate unfamiliar content? If it’s the former, you may need to consider hiring text labeling services. If it’s the latter, you’ll need to clarify your guidelines.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is a text annotation example?
Highlighting “Apple Inc.” as an `ORG` is a typical example of named entity annotation. It teaches the model to recognize organization names within a sentence, using span-based or token-level labeling.
What are 3 ways to annotate a text?
You can choose between token labeling (NER), span highlighting (entity linking), and document classification (topic labels.)
What is text data annotation?
It’s the process of labeling text data so that machine learning models understand what they’re reading. You’ll do this by adding tags, classes, spans, or other metadata.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.