Sora Model: Text-to-Video AI Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Sora generates high-quality videos from text, images, or videos using transfer learning.
- Uses diffusion transformers and patch-based processing for consistent results.
- Suitable for marketing, education, entertainment, and AI training.
- Offers high-resolution output and advanced editing tools.
- Faces challenges with physics, high costs, and short video lengths.
- Competes with Meta’s Make-A-Video and Google’s Lumiere.
What Is the Sora Model?
Sora is an AI system from OpenAI that turns text into short videos. It uses transfer learning, a method where it builds on what other AI models have already learned. Sora takes ideas from image models like DALL·E and applies them to videos, which are more complex.
Here’s what this text-to-video model can do:
- Create videos from text: You write a description, and Sora generates a video.
- Multimodal Inputs: Edit or extend using text, images, or videos.
- Keep videos consistent: Details stay smooth and realistic across frames.
- Produce high-quality clips: Videos are up to 1080p and 20 seconds long.
OpenAI’s text-to-video model Sora uses transfer learning to work better and faster. Instead of learning everything from scratch, it uses knowledge from other AI models, like language and image systems, and adapts it for videos.
Here’s how it helps:
- Saves time: It reuses parts of older models, so it trains faster.
- Flexible: The system can handle new text-to-video tasks without starting over.
- More accurate: It learns from related tasks to perform better with videos.
How Sora Improves on Earlier Models
Sora model builds upon earlier models like Meta’s Make-A-Video by solving issues with object consistency and motion realism. It also supports video editing and animating still images, making it more versatile.
In fact, its multimodal capabilities position Sora as a leading text to video AI — a system that not only turns text prompts into video but also refines and extends existing footage with quality and coherence.
See how Sora stacks up to other text-to-video AI models:
| Feature | Meta’s Make-A-Video | Google’s Lumiere | Sora Model |
| Input Types | Text and images | Text | Text, images, and videos |
| Video Quality | Low resolution | Medium quality | High resolution (1080p) |
| Learning Method | Paired datasets | Paired datasets | Transfer learning on diverse data |
Sora makes video creation simpler. With transfer learning, it’s faster, more flexible, and easier to use. If you’re creating content or working on simulations, it might save you time and effort.
Sora's biggest advantage lies in how it transforms workflows by acting as both an efficiency booster and a creative collaborator. It doesn’t just generate content; it refines ideas, improves tone, and suggests engaging angles.

 Founder Backlink Monitor
Founder Backlink Monitor
How Sora Architecture Works
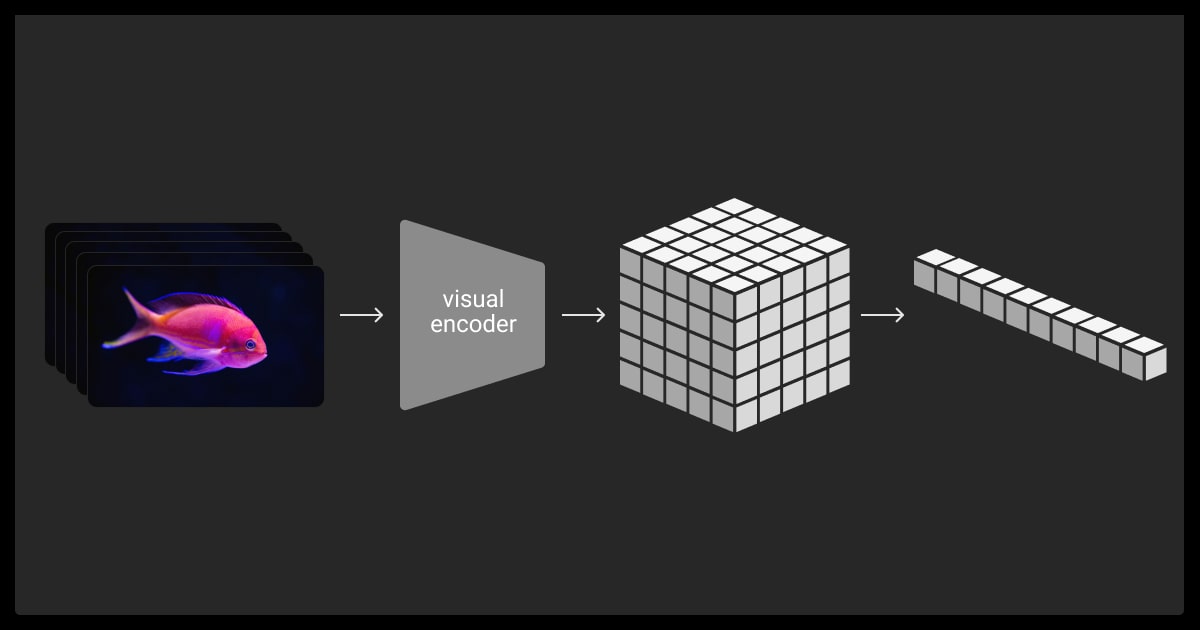
The Sora model architecture uses advanced AI techniques to create videos from text, images, or existing clips. It produces high-quality, smooth, and realistic videos, effectively addressing the challenges of video generation.
Here’s how Sora works:
Diffusion Transformers
Text to video Sora starts with random noise and refines it step by step into a video. It processes the entire video at once instead of handling individual frames, ensuring consistency in objects and motion.
Patch-Based Representations
Videos are broken into smaller “patches” for processing. This reduces computational requirements and improves scalability compared to working on full frames.
Latent Space Compression
Raw video data is converted into compressed, simplified forms for processing. This saves time and computing power while maintaining high-quality outputs.
Training of Text-to-Video Models
Sora’s ability to generate high-quality videos from text can enhance datasets used in machine learning, whether they consist of labeled or unlabeled data.
- Large Dataset: Sora is trained on diverse data, including real-world videos, animations, and video game footage.
- Smart Captioning: AI-generated captions help the model understand text-video relationships.
- Scaling: Sora improves its accuracy by using large datasets and high-performance hardware.
By leveraging transfer learning, Sora can adapt its functionality to align with various types of LLMs, showcasing its versatility with different input data formats.
Sora architecture solves complex problems in image recognition and video generation. Its efficient design allows it to process video data quickly while producing high-quality results. This makes Sora one of the leading text-to-video models.
Applications of the Sora Model
By turning text into high-quality videos, Sora AI model opens up new possibilities for content creation, simulations, and beyond.
For example, Sora’s multimodal input capabilities could complement LLM data labeling workflows by producing visually enriched datasets tailored to specific language models.
Here’s how to use Sora AI model:
Creative and Commercial Use Cases
Content Marketing
Create engaging videos for ads, blogs, and social media without needing a full production team.
Simulation and Training
Simulate real-world environments for training AI in robotics or autonomous vehicles.
Storytelling and Animation
Bring ideas to life with animated sequences or extend existing video content.
The best way to integrate Sora is by incorporating it into business workflows that require rapid and high-quality video content production. Your marketing team can use the AI to create short, engaging video content based on campaign briefs.
 CEO and CTO HasData
CEO and CTO HasData
Key Features for Video Creation
Sora (text-to-video model) has several tools that make it flexible for different tasks:
- Video Extension: Extend clips seamlessly forward or backward.
- Editing: Modify videos with text prompts, like changing colors or adding elements.
- Looping: Create videos that play continuously without noticeable starts or stops.
- Combining Clips: Merge multiple AI-generated videos into one coherent sequence.
Industry Applications of Sora
Sora refines object motion and consistency across frames, tackling challenges commonly found in object detection, ensuring smoother and more realistic video generation.
Different sectors are already finding ways to use Sora:
| Industry | Example Use | Benefit |
| Marketing | Quick ad creation | Saves time and cost |
| Education | Visualizing lessons or concepts | Engages learners |
| Film and Media | Generating animations or special effects | Lowers production effort |
| Gaming | Creating realistic game cutscenes or trailers | Adds creative flexibility |
| AI Training | Simulating environments for machine learning | Produces varied datasets |
| Data annotation | Generates realistic videos to reduce labeling time. | Improves workflows and lowers data annotation pricing |
Sora’s ability to create high-quality text-to-video generative AI videos from simple inputs makes it a powerful tool for businesses and creators.
Take data annotation services, for example. The realistic and consistent videos generated by Sora streamline annotation workflows by providing high-quality visual datasets for training AI models.
Sora’s ability to generate high-quality videos from text can enhance datasets used in machine learning. It streamlines annotation workflows by providing visually enriched datasets tailored to specific language models.

Challenges of the Text-to-Video Model Sora
While the Sora model is impressive, it isn’t perfect. Like all text-to-video models, it faces challenges that limit its applications in certain areas.
Technical Shortcomings
Sora struggles with object consistency, realistic motion, and interpreting detailed prompts, leading to visual inconsistencies and errors.
Safety and Ethical Considerations
The model faces risks like deepfake misuse, biases from training data, and relies on safeguards to prevent harmful content generation.
Real-World Challenges
High computational costs, lack of real-time editing, and a 20-second video limit restrict Sora's broader usability.
One of Sora’s challenges is also ensuring object consistency in videos, a problem similar to what machine learning models face in image classification vs. object detection tasks.
Sora is a major step forward, but it still has room for growth. Addressing these limitations could make it more reliable, efficient, and accessible for a wider range of users.
While object consistency and motion realism have improved, AI-generated videos still struggle with detailed interactions. Sora’s outputs work best in controlled environments but require further refinement for complex physical scenarios.
 Demand Generation Team Leader Netguru
Demand Generation Team Leader Netguru
Sora Model vs. Alternatives
Sora isn’t the only text-to-video model out there. Other systems also aim to simplify video generation:
| Feature | Sora | Meta’s Make-A-Video | Google’s Lumiere |
| Input Types | Text, images, and videos | Text and images | Text and images |
| Output Quality | High resolution (1080p) | Low resolution | Medium resolution |
| Consistency in Motion | Strong, but not perfect | Weak | Moderate |
| Editing Capabilities | Extensive (e.g., loops, extensions) | Basic | Limited |
| Training Approach | Transfer learning on diverse data | Paired datasets | Paired datasets |
Sora outperforms in areas like resolution and editing tools, but its competitors offer simpler setups for less demanding use cases.
Strengths of Sora
- Advanced Inputs: Sora works with text, images, and existing videos, making it flexible for creators.
- Higher Output Quality: Sora videos are sharper and more detailed compared to other models.
- Comprehensive Editing Tools: Features like video extension, looping, and combining clips provide more creative options.
Weaknesses of Sora
- Resource Demands: Sora needs high computational power, limiting access for smaller projects.
- Limited Duration: Videos are capped at 20 seconds, which might not suit all needs.
- Physics and Realism: While improved, it still struggles with realistic motion in complex scenes, such as action sequences or intricate physical interactions.
When to Choose Sora
AI model Sora is a better option if you need high-resolution videos with smooth transitions. It works well for creative or technical projects that require advanced editing. It’s also a strong choice if your project involves a mix of text, images, and video inputs.
As a data annotation company, we recognize the potential of Sora’s high-quality video outputs in enhancing the efficiency of AI training workflows by providing accurate and consistent datasets
When to Consider Other Models
Alternative text-to-video models like Meta’s Make-A-Video or Google’s Lumiere might work better if your project doesn’t require high resolution or extensive editing. These models are also a good option if you’re looking for a simpler tool with lower computational costs.
Future Implications of Sora
Sora’s capabilities point to a growing role for AI in text-to-video generation. By combining advanced text-to-video technology with transfer learning, it’s reshaping how videos are made, edited, and used.
AI-driven video tools like Sora are set to impact several industries:
- Marketing: Faster production of ad content tailored to specific audiences.
- Education: Simplified creation of engaging visual lessons.
- Entertainment: Cost-effective animation and visual effects for films or games.
- AI Development: Generating diverse training data for machine learning models.
Key benefits include:
- Cuts Costs and Time: Generates videos quickly without equipment or teams.
- Boosts Accessibility: Enables high-quality video creation for all users.
- Advances Simulations: Creates scenarios for AI training, like traffic tests.
AI-driven video tools like Sora are set to impact marketing, education, and AI development. By automating content creation, businesses can save costs and increase efficiency, but proper safeguards must be in place.
 Business Development Director TradingFXVPS
Business Development Director TradingFXVPS
Predictions for AI in Text-to-Video Generation
| Trend | Impact |
| More Accessible Hardware | Lowering compute costs could make tools like Sora easier to use. |
| Better Safety Mechanisms | Improved systems to prevent misuse, like stricter content controls. |
| Higher Customization | Models may allow fine-tuned editing for greater control over results. |
Sora demonstrates the transformation of generative AI text-to-video creation. As the technology advances, you can expect more accessible tools, improved realism, and a wider range of applications. These changes could redefine industries that rely on video content.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What model does Sora use?
Sora uses a diffusion model combined with transformer architecture. It starts with random noise and refines it step by step to generate videos. This process ensures consistent and detailed outputs while handling motion and object permanence effectively.
Is Sora AI available to the public?
Yes, Sora is available to ChatGPT Plus and Pro users. ChatGPT Plus users can create limited watermarked videos, while Pro users have access to higher resolution, unwatermarked outputs with longer durations.
How does the Sora model work?
Sora processes videos using a combination of diffusion transformers and patch-based representation. It breaks video frames into smaller sections (patches) and works on these compressed parts. This design helps maintain consistency in motion and reduces computational demands.
What is the model structure of Sora?
The Sora model structure includes three key components:
- Diffusion Transformers: For step-by-step video refinement.
- Patch-Based Processing: Breaks frames into manageable parts for efficiency.
- Latent Space Compression: Reduces raw video data into simplified representations, speeding up training and inference.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.