Named Entity Recognition: A Practical Guide

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What is NER?
- Common Applications of Named Entity Recognition
- Types of Entities Recognized in NER
- Techniques for Building a NER Model
- Challenges in Named Entity Recognition
- How to Label Data for NER
- Best Practices for Training NER Models
- Named Entity Recognition Tools and Libraries
- Future Trends in Named Entity Recognition
- About Label Your Data
- FAQ

TL;DR
- Named Entity Recognition (NER) finds and sorts key information like names, places, and dates in text.
- It helps search engines, customer support, and healthcare by turning messy text into organized data.
- A NER model includes rule-based systems, machine learning, and deep learning like BERT.
- Challenges include dealing with tricky words, different languages, and inconsistent labeled data.
- Future trends focus on learning from fewer examples, combining text with images, and using large language models (LLMs).
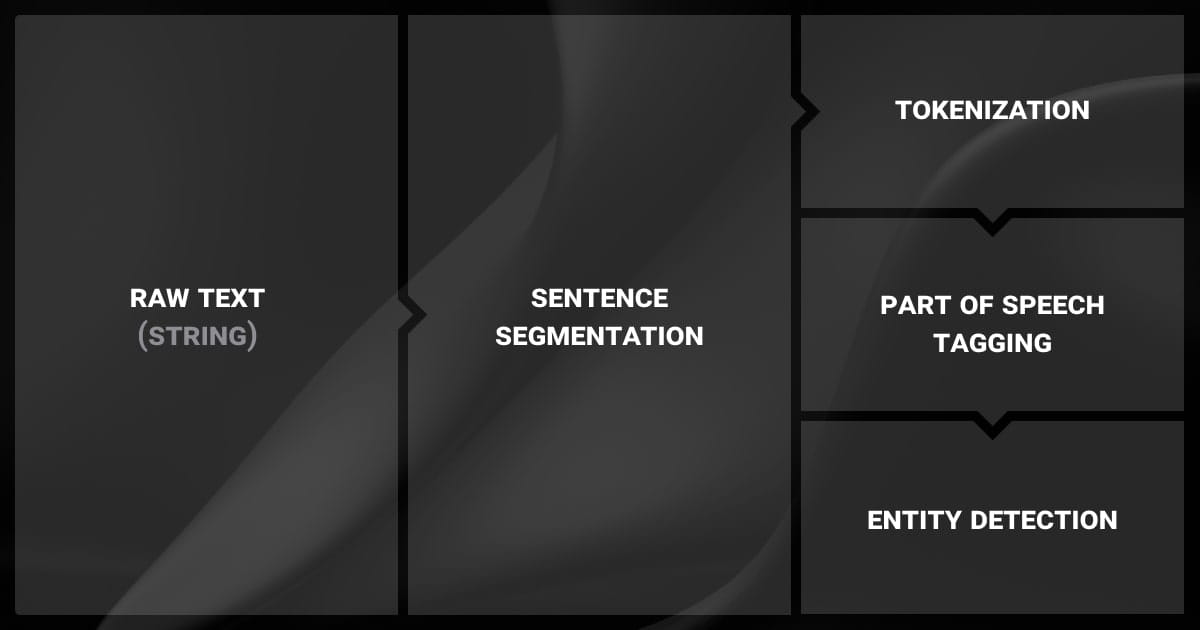
What is NER?
Named Entity Recognition (NER) is a Natural Language Processing technique that picks out important information from text and puts it into categories like people, places, organizations, dates, and more.
It turns messy text into organized data that’s easy to understand and use.
NER helps answer questions like who, where, and when by finding key parts of text. For example, it can highlight names, dates, and places in a news article. This process is also called entity extraction or entity chunking and is used in search engines, chatbots, and text summaries.
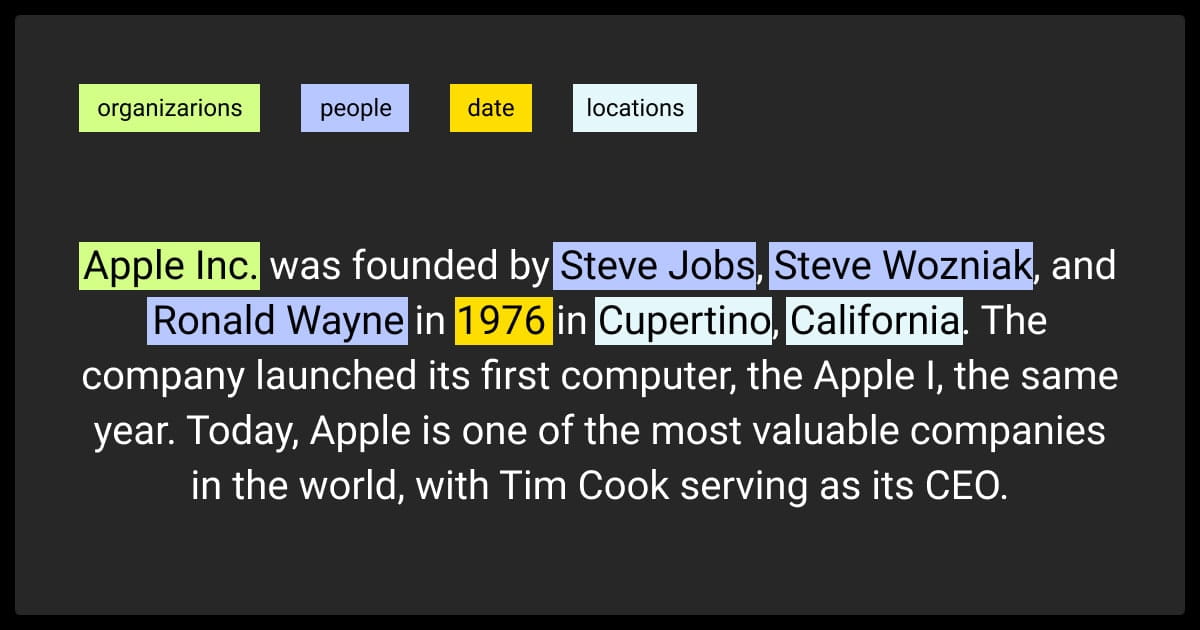
Here’s how it works:
- First, NER finds possible important words (like names or dates).
- Next, it sorts those words into categories.
For example, in the sentence: “Tesla unveiled its latest model in California on January 1, 2025,”
- Tesla → Organization
- California → Location
- January 1, 2025 → Date
Modern named entity recognition models uses a machine learning algorithm and deep learning to improve over time. These models learn from data and get better at recognizing entities.
NER is useful because it saves time, improves search accuracy, and helps organize large amounts of text. Businesses use it to process reports, answer customer questions faster, and make better decisions with data.
Common Applications of Named Entity Recognition
Named Entity Recognition (NER) is used in many industries to make sense of large amounts of text. It helps businesses, researchers, and organizations organize and analyze text faster.
Now that you know what is named entity recognition, here are some of its most common applications:
Search Engines
NER improves search accuracy by identifying names, places, and dates in search queries. This makes it easier for users to find the right information.
Customer Support
Companies use NER to sort customer questions and complaints. This helps support teams respond faster by sending requests to the right department.
Healthcare
NER extracts key details from patient records, such as symptoms, treatments, and dates. This reduces manual work for doctors and helps them make quicker decisions.
Finance
Financial companies use NER to process financial datasets, extract company names, transaction details, and identify trends. It speeds up tasks like credit analysis and fraud detection.
News and Media
NER helps categorize news articles by identifying people, events, and locations mentioned in stories. This makes it easier to find related news.
Human Resources
NER can analyze job applications by picking out key details like skills, experience, and education, helping recruiters find the right candidates faster.
NER’s ability to quickly turn raw text into organized data makes it essential for improving search accuracy, automating data entry, and gaining valuable insights from unlabeled data.
Types of Entities Recognized in NER
Named entity recognition in NLP can identify a wide range of entities in text. These entities fall into standard categories and specialized ones, depending on the task.
Standard Entities
These are common types used in NER:
- Person: Names of individuals (e.g., Elon Musk)
- Location: Cities, countries, and geographic regions (e.g., Paris, France)
- Organization: Companies, institutions, and groups (e.g., Tesla, United Nations)
- Date/Time: Specific dates or times (e.g., January 1, 2025, 2 PM)
- Monetary Values: Amounts of money (e.g., $1,000,000)
- Percentages: Percent-based information (e.g., 85%)
Domain-Specific Entities
Some industries need custom entity categories that go beyond the standard ones:
- Healthcare: Disease names, drug names, medical codes (e.g., diabetes, Ibuprofen)
- Finance: Stock symbols, financial instruments (e.g., AAPL, Bitcoin)
- E-commerce: Product names, SKUs, brands (e.g., iPhone 15 Pro)
Customizing NER to recognize these specialized entities is essential for tasks like medical research, financial analysis, or product management. Modern named entity recognition models allow this level of customization by training on domain-specific datasets.
Techniques for Building a NER Model
There are several techniques for building a NER model, ranging from simple rule-based approaches to advanced deep learning models. The right technique depends on your data and the complexity of the task.
Rule-Based Systems
These systems use predefined rules like word patterns, capitalization, and context to identify entities.
- Example: Capitalized words after titles like “Mr.” or “Dr.” may be identified as names.
- Limitations: Hard to scale and struggles with variations in text.
Dictionary-Based Systems
This method checks words against a dictionary of known entities. It works well for simple tasks but needs constant updating.
- Example: A list of company names to identify business-related entities.
- Limitations: Misses new or uncommon terms not in the dictionary.
Machine Learning-Based NER
Machine learning models are trained on labeled datasets to identify and classify entities. These models require feature engineering and can generalize well to unseen data. Common algorithms include Conditional Random Fields (CRF) and Support Vector Machines (SVM).
- Advantages: More adaptable than rule-based methods.
- Example: Training a model to recognize names and dates in news articles.
Deep Learning-Based NER
Deep learning models, like LSTM and BERT, are the most accurate. They automatically learn features from text and handle complex patterns in large datasets.
- Example: BERT-based models can process entire sentences and understand context to identify entities.
- Advantages: Highly accurate and scalable.
These techniques offer different levels of complexity and accuracy. For tasks that require high accuracy and scalability, deep learning models are often the best choice.
We developed a hybrid deep learning approach combining transformer-based models with custom domain-specific training data, significantly improving entity recognition accuracy in complex contexts. Treating NER as a contextual understanding problem rather than a pure classification task was a key breakthrough.

 Senior Software Engineer, StudioLabs
Senior Software Engineer, StudioLabs
Challenges in Named Entity Recognition
Building and using Named Entity Recognition (NER) models isn’t without its difficulties. Despite advancements in technology, NER faces several challenges:
Ambiguity and Context Dependency
Words can have multiple meanings depending on the context.
- Example: Washington can refer to a person, a state, or the capital city.
Named entity recognition models must rely on surrounding words to classify the correct entity.
Handling Multilingual Texts
NER performance drops when dealing with different languages, especially those with fewer labeled datasets.
- Example: Models trained in English may struggle to process text in Hindi or Arabic due to differences in grammar and vocabulary.
Detecting Rare or New Entities
NER named entity recognition models often miss newly introduced entities or those that don’t appear frequently in training data.
- Example: Emerging company names or newly discovered diseases may not be recognized.
Data Annotation Complexity
High-quality data annotation is crucial, but creating labeled datasets is time-consuming and prone to inconsistency. Models trained on poorly labeled data may deliver inaccurate results.
Understanding these challenges, including data annotation pricing, is key to improving NER and deploying them effectively in real-world applications. Solutions include using domain-specific datasets, continuous training, and expanding multilingual support from expert data annotation services.
The biggest hurdle we faced was handling inconsistent entity formats across different data sources, where company names would appear differently (like 'IBM' vs 'International Business Machines Corp.'). We solved this by implementing a custom fuzzy matching algorithm combined with a maintained database of entity variations, improving our recognition accuracy from 75% to 94%.
 CIO and Founder, Local Data Exchange
CIO and Founder, Local Data Exchange
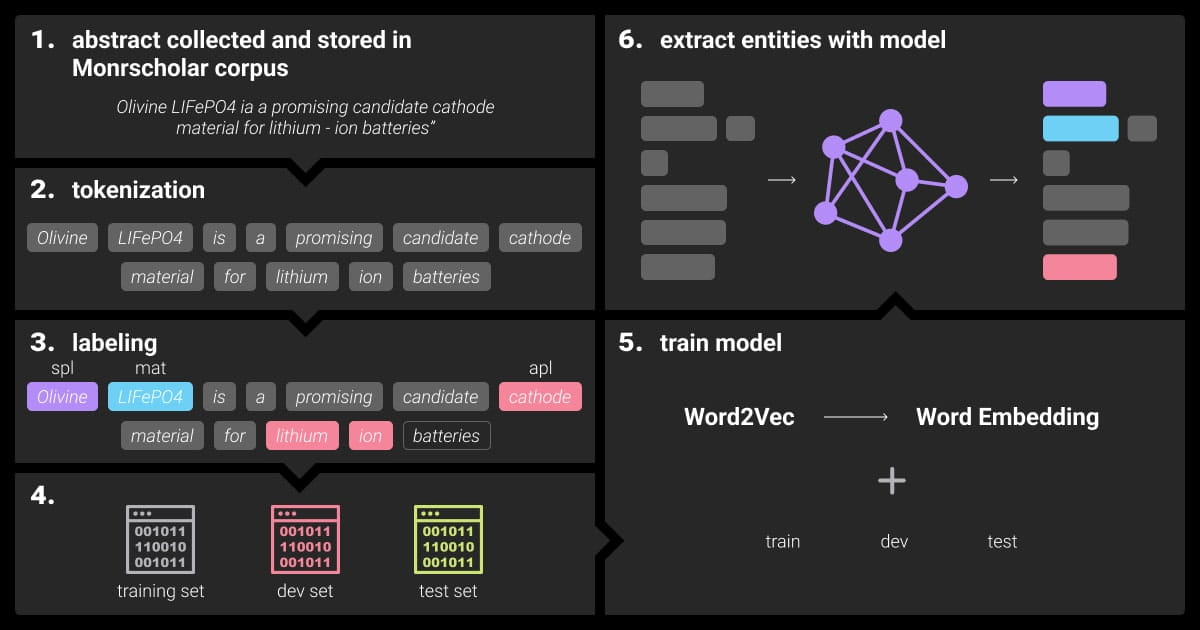
How to Label Data for NER
High-quality labeled data is the foundation of an accurate NER model. Creating a named entity recognition dataset involves several steps to ensure consistency and reliability.
Key Steps in NER Data Annotation
Define Entity Categories
Clearly specify what types of entities you want to label (e.g., Person, Location, Organization).
Use Consistent Guidelines
Create detailed instructions for annotators to avoid confusion and ensure consistency.
Quality Control
Regularly review annotated data to catch and correct mistakes.
NER is not limited to text-based data; it can be applied alongside OCR deep learning to recognize and classify entities in scanned documents. In tasks involving visual data, understanding the difference between image classification vs. object detection is crucial.
Object detection focuses on locating entities in images, while image classification categorizes them without identifying specific locations.
Choosing the Right Annotation Tool
Several tools make it easier to label data for NER tasks. Some popular ones include:
- Labelbox: Ideal for large teams, with built-in quality control.
- Doccano: Open-source and great for text annotation.
- Prodigy: Fast, Python-based, and supports machine learning integration.
Managing Annotation Complexity
- Long Texts: Break them into smaller chunks for easier annotation.
- Ambiguous Entities: Provide clear examples to help annotators decide how to label tricky cases.
- Regular Feedback: Give annotators feedback to improve the quality over time.
A trusted data annotation company is crucial for training effective named entity recognition models. Without such vendors, even the most advanced algorithms will struggle to deliver reliable results.
Best Practices for Training NER Models
Training an accurate and reliable NER model requires careful planning and attention to detail. Following these best practices can help improve model performance and reduce common errors.
Focus on Data Quality
High-quality, consistent data is the most important factor for successful model training.
- Ensure your NER dataset is clean and free of labeling errors.
- Use diverse examples to help the model generalize better across different contexts.
Handle Imbalanced Entity Classes
If some entity types appear more often than others, the model may overfit to the most frequent ones.
- Solution: Use data augmentation to create more examples of rare entity types or apply weighting techniques during training.
Incorporate Domain Knowledge
For specialized tasks (like medical or legal text), adding domain-specific knowledge improves accuracy.
- Example: For a medical NER model, train with datasets containing disease names and drug information.
Evaluate and Fine-Tune Regularly
Monitor the model’s performance with metrics like precision, recall, and F1 score.
- Continuously fine-tune the model based on evaluation results.
- Use cross-validation to test how well the model performs on different subsets of data.
Following these practices ensures your named entity recognition model can handle real-world text more accurately, delivering reliable and actionable results.
To solve ambiguity issues like 'Python' referring to either a programming language or a reptile, I focused on context-aware methods using a mix of part-of-speech tagging, dependency parsing, and transformer-based models like BERT, fine-tuning them on domain-specific data.
 Head of SEO, WP Creative
Head of SEO, WP Creative
Named Entity Recognition Tools and Libraries
Building and implementing NER is much easier with the right tools and libraries. Whether you want to train a custom model or use a pre-built solution, here are some of the top options:
Open-Source Libraries for NER
- SpaCy: A fast, modern NLP library in Python with built-in NER support. It’s great for production-ready applications.
- NLTK (Natural Language Toolkit): One of the oldest and most popular libraries for NLP tasks. It offers a simple interface for NER but is better suited for educational purposes.
- Stanford NLP: A Java-based library known for its accuracy and pre-trained models. It supports several languages and is widely used in research.
Cloud-Based NER Solutions
- AWS Comprehend: Amazon’s NLP service that provides NER, sentiment analysis, and language detection.
- Google Cloud Natural Language API: Offers entity recognition, sentiment analysis, and syntax analysis through an easy-to-use API.
- IBM Watson NLU: Provides advanced NER capabilities along with emotion detection and intent analysis.
Choosing the right tool depends on your project needs. For fast deployment, cloud-based APIs are ideal, while open-source libraries are better for custom solutions with full control over the model.
Future Trends in Named Entity Recognition
Named Entity Recognition (NER) is evolving rapidly with new techniques and applications on the rise. Here are some key trends shaping the future of NER:
Few-Shot Learning
Few-shot learning allows models to recognize entities with just a few examples, reducing the need for large labeled datasets. This approach is especially useful for identifying rare or newly introduced entities.
Multimodal NER
Multimodal NER combines text with other data types like images and audio for richer context. For example, analyzing a product image along with its description can improve accuracy in recognizing product-related entities.
Integration with LLMs
As new types of LLMs emerge, including GPT-4, they are making NER more accessible and powerful. LLMs can identify entities in text while understanding broader context, improving accuracy and reducing errors.
Domain-Specific NER Models
As industries like healthcare and finance adopt NER, the focus is shifting to specialized models trained on domain-specific data. These models can better identify complex entities like medical terms, drug names, or financial instruments.
Joint NER and Entity Linking
Future models will combine NER with entity linking—connecting identified entities to external knowledge bases for deeper insights and context. This will improve tasks like recommendation systems and data enrichment.These trends will continue to push the boundaries of named entity recognition models, making them smarter and more versatile across industries.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are the three types of NER?
The three common NER types are rule-based, machine learning-based, and deep learning-based. Rule-based uses patterns, while machine learning and deep learning rely on models trained on labeled data for higher accuracy.
How does an NER work?
NER detects important words in text and classifies them into categories like Person, Location, or Date. It first identifies possible entities, then sorts them into predefined labels.
What are the disadvantages of NER?
NER struggles with word ambiguity, rare entities, and multilingual text. Creating consistent labeled datasets is also time-consuming and can lead to errors.
What is an example of named entity recognition text?
In the sentence “OpenAI launched ChatGPT in November 2022,” NER identifies OpenAI as an organization, ChatGPT as a product, and November 2022 as a date.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.