Active Learning Machine Learning: How It Reduces Labeling Costs

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Active Learning Machine Learning Is Worth Your Attention
- How Active Learning Machine Learning Works
- Choosing the Right Sampling Strategy
- How Active Learning Reduces Labeling Costs
- Building an Active Learning Pipeline That Actually Works
- When Active Learning Machine Learning Fails
- About Label Your Data
-
FAQ
- What is the active learning method of machine learning?
- What are real-world examples of active learning in machine learning?
- What is active and passive learning in ML?
- What is the difference between deep learning and active learning?
- What tools or libraries support active learning in machine learning?

TL;DR
- Active learning helps reduce labeling costs by selecting only the most useful data points for training, instead of treating all samples equally.
- It runs in a loop: train a model, pick uncertain or diverse examples, label them, retrain, and repeat until performance plateaus.
- Sampling strategies like uncertainty, diversity, and query-by-committee make each annotation count more.
- When done right, teams reach target accuracy with far fewer labels, often 30 to 70 percent less.
- But it’s not always the best fit: some tasks don’t benefit, and poorly designed loops can introduce bias or unnecessary complexity.
Why Active Learning Machine Learning Is Worth Your Attention
You have thousands of unlabeled examples. You could label everything — and sometimes, that’s the right call. But when your budget is tight, your task is repetitive, or your machine learning algorithm already handles most examples well, labeling everything becomes inefficient.
That’s where active learning in machine learning comes in: it helps you prioritize the samples that actually improve performance, so your annotation effort isn’t wasted on data the model already understands.
Instead of labeling blindly, you let the model help decide which examples will move the needle. This approach can reduce annotation costs significantly without sacrificing performance.
The Annotation Bottleneck in Production ML
Data annotation is often the most expensive step in the pipeline, not model tuning, not infrastructure. And the problem isn’t just money. It’s also time. Human annotators spend hours labeling redundant or obvious samples that offer no real learning value.
In tasks like named entity recognition, document classification, or image recognition, a huge chunk of your dataset contains low-information examples. Labeling all of them adds cost without improving your model. Active machine learning helps surface the edge cases worth labeling and skip the rest.
When Passive Labeling Doesn’t Scale
Passive labeling means drawing random samples from your machine learning dataset and labeling them as-is. It’s easy to implement, but quickly falls apart at scale.
- You waste resources on examples your model already handles well
- You get diminishing returns from each new labeled batch
- You often don’t know when to stop labeling
By contrast, active learning machine learning pipelines focus your annotation effort where it counts: ambiguous, diverse, or high-impact samples. This makes every annotation work harder, which is exactly what you want when time and budget are limited.
How Active Learning Machine Learning Works
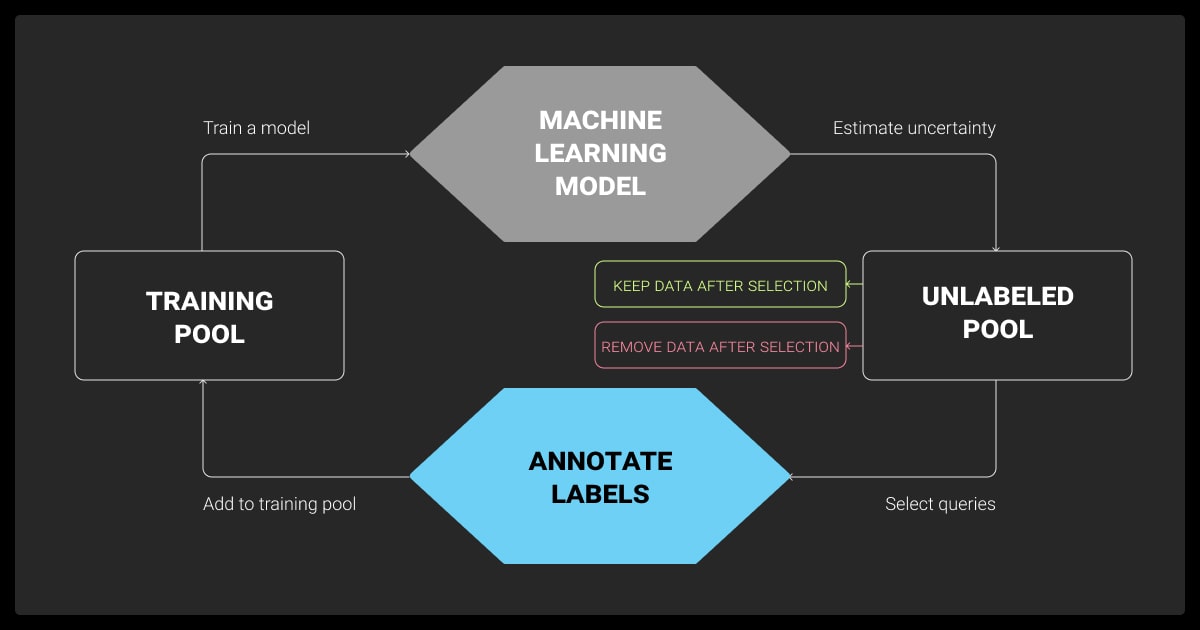
What is active learning in machine learning? The core idea is simple: instead of labeling everything upfront, let the model tell you what to label next.
This happens through an iterative loop. You start with a small labeled dataset, train a model, and use it to select new examples that are most worth labeling. Then you retrain the model on the updated dataset and repeat the cycle.
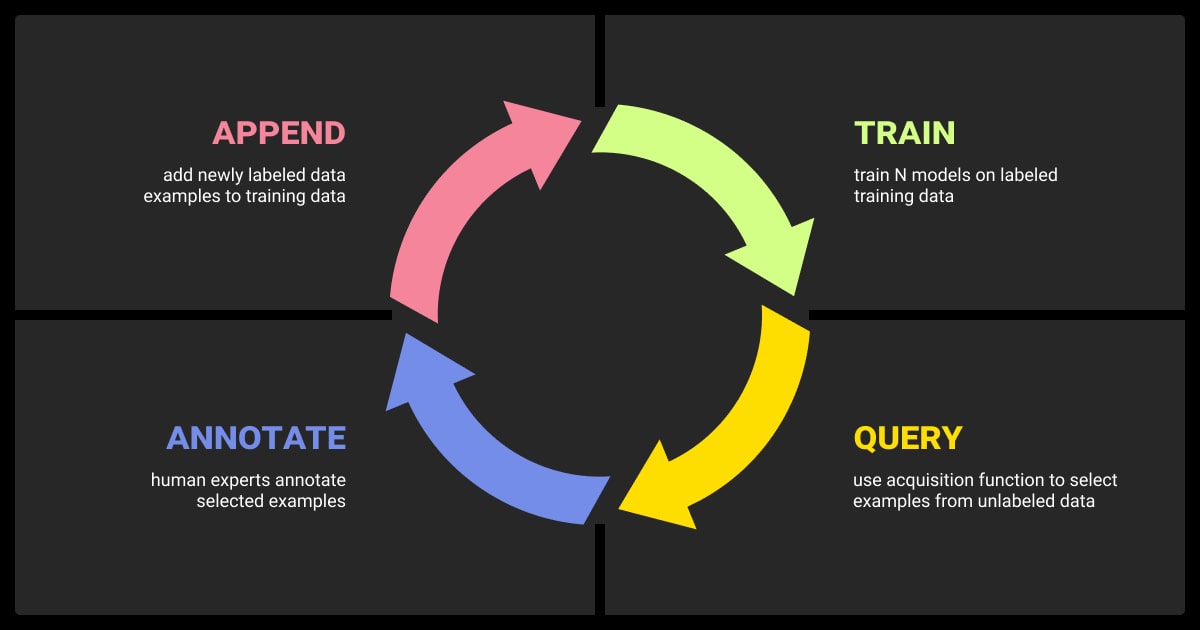
The Iterative Loop (Select → Label → Retrain)
This loop is what makes active learning machine learning practical. You’re constantly improving the model by feeding it high-impact examples, not random ones.
- Select: The model identifies samples it is most uncertain about, or ones that are diverse or underrepresented
- Label: A human annotator labels just those selected samples
- Retrain: The model updates using the expanded labeled dataset
Repeat until the model performance plateaus or the annotation budget runs out.
Human-in-the-Loop or Assisted Labeling
The labeling step doesn’t have to mean full manual input every time. You can use:
- Pre-labeling with weak models and fast correction
- Annotator feedback on partially predicted labels
- Annotation UIs that highlight uncertainty or flag edge cases
Human-in-the-loop setups help reduce friction in the loop, especially for high-volume or high-precision use cases like document classification, NER, or medical tagging.
When to Stop (Performance vs. Cost Curve)
One of the hardest questions is knowing when to stop the loop. Active learning saves effort, but not forever. At some point, each new label adds less value.
To decide when to stop:
- Track F1, accuracy, or task-specific metrics after each iteration
- Plot the performance gain per labeled batch
- Watch for flatlines or steep drops in improvement rate
Stopping too early limits model performance. Too late, and you might as well have used full supervision. A well-planned exit point helps balance quality and cost.
If I notice that adding more labeled data isn’t leading to significant improvements, it’s a good sign to pause. Another cue is the model’s overall uncertainty — when it drops below a certain level across the unlabeled data, it indicates the model is confident enough in its predictions.

 Co-Founder & CEO, AIScreen
Co-Founder & CEO, AIScreen
Choosing the Right Sampling Strategy
Not all data points are equally useful. Choosing what to label is the core value of machine learning active learning. The sampling strategy you use will determine how fast your model improves or stalls.
Each method has trade-offs, and not every one works for every task. Below are the most common strategies used in active learning in machine learning workflows.
Uncertainty Sampling: Picking What the Model Fears
This is the most popular strategy. The model selects examples where its predictions are the least confident. The ones with probabilities close to 0.5 in binary classification or evenly spread across classes in multiclass tasks.
Works well for:
- Classification problems with clear decision boundaries
- Models that can output meaningful probability scores
Pitfalls:
- Overfocus on outliers
- Requires calibrated confidence estimates
Query by Committee: Let Models Vote
In this approach, you train multiple models (or use different parameter settings) and have them “vote” on unlabeled examples. Samples with the most disagreement are selected for labeling.
Works well when:
- You can run lightweight model variations
- Uncertainty is hard to measure directly
Limitations:
- More compute-heavy
- Can be noisy if committee models are poorly tuned
Diversity Sampling: Avoiding Redundant Labels
Rather than picking uncertain samples, this strategy selects diverse examples to avoid labeling the same patterns repeatedly. You can measure diversity with clustering, distance metrics, or embedding-based similarity.
Use this when:
- Your dataset has a lot of repetition
- You want broad coverage of edge cases early
Watch out for:
- Overlooking rare but important edge cases
- Slower gains in model performance compared to uncertainty sampling
Query Synthesis: Generating New Examples (When It Works)
Instead of selecting from existing data, you generate synthetic examples the model finds hard. This is typically done using GANs, language models, or perturbation techniques.
Good for:
- Low-resource settings
- Stress-testing model robustness
But:
- Hard to control the quality of generated samples
- Not suitable for all domains or tasks
Choosing the right strategy often depends on the model, task, and labeling budget. Some teams even combine multiple strategies in a hybrid loop.
Pure uncertainty sampling tends to over-focus on ambiguous areas of the decision boundary, leading to redundant or overly similar samples. By adding a clustering or embedding-based diversity constraint, we ensured each batch of new labels covered more of the input space. This gave faster improvements per labeled sample, especially in domains with class imbalance or rare edge cases.
 Founder & Principal Software Architect, Cirrus Bridge
Founder & Principal Software Architect, Cirrus Bridge
How Active Learning Reduces Labeling Costs
The main reason teams explore active learning is simple: reduce the number of labels needed to reach production-level performance. Instead of paying for 100,000 annotations, you might get similar results with 20,000 if those labels are chosen well.
Higher F1 per Annotated Sample
In well-designed loops, active machine learning delivers more learning value per label. You’re not just labeling at random, you’re selecting examples that directly help the model resolve uncertainty, fill gaps, or correct errors.
In practical terms:
- F1 score increases faster with fewer samples
- Annotators spend time on high-impact examples
- You hit acceptable performance with less data
This effect is most visible in classification, NER, and image tagging, where error reduction is closely tied to specific edge cases. It’s also effective for LLM data labeling, where targeted sampling improves output without overfitting to large, generic corpora.
Reduced Time on Redundant or Easy Samples
Without active selection, annotators waste time on obvious examples the model already gets right. This is inefficient and costly, especially at scale.
Active learning helps filter these out:
- Avoids re-labeling repetitive or already-solved cases
- Focuses reviewers on the most informative content
- Frees up annotation capacity for harder tasks
This not only reduces data annotation pricing, it improves morale: reviewers spend less time on mindless labeling and more on solving real edge cases. Reviewers working through data annotation services spend less time on repetitive tasks and more on labeling edge cases that actually improve the model.
Practical Benchmarks from AL Research
Research consistently shows that active machine learning with Python frameworks like modAL and Cleanlab can cut labeling effort by 30 to 70 percent, depending on the domain and task complexity.
For example:
- In a binary classification task, uncertainty sampling reached 90% of final model performance using only 40% of the labeled data
- In NER, hybrid strategies combining diversity and uncertainty reduced the number of labeled sentences needed for training by half
The numbers vary, but the pattern holds: smart sampling pays off.
Active learning also supports better LLM fine tuning by helping teams identify the most valuable prompts or corrections early in the training cycle.
“I used a mix of uncertainty sampling and clustering — picking the most uncertain samples from different data clusters to make sure we weren't just labeling similar edge cases. The stopping point became clear when our model's predictions on the validation set stayed stable for 3 consecutive labeling rounds.”
— Runbo Li, CEO, Magic Hour (photo)
Building an Active Learning Pipeline That Actually Works

Knowing the theory is one thing. Getting a real pipeline running is another. Many teams stall when trying to connect selection logic, annotation tools, and retraining loops. This section covers what you actually need to get started.
Starting Requirements: Baseline Model and Unlabeled Pool
Before anything else, you need two things:
- A baseline model, even if it’s weak
- A pool of unlabeled data in a format your model can evaluate
That model doesn’t need to be accurate. It just needs to produce usable outputs (like probabilities or logits) so you can rank examples by uncertainty or disagreement.
Ideally, you also have:
- A small labeled set to warm-start training
- A simple retraining script or loop you can automate
- Storage or tracking for what has and hasn’t been labeled
Without these basics, active learning can't begin.
Plug-and-Play Toolkits
If you’re using Python, several libraries help speed things up:
- modAL: Lightweight, modular, and built on scikit-learn
- Cleanlab: Helps clean noisy labels and identify uncertain samples
- Prodigy: Great for human-in-the-loop NLP tasks with quick feedback cycles
These tools support common strategies like uncertainty sampling, clustering, and committee-based selection. Most come with prebuilt loops and scoring functions, so you can focus on connecting them to your data and models.
Some tutorials on active learning machine learning are available online, but they’re often outdated. Stick with tool-specific docs and GitHub repos when possible.
Integration with Annotation Workflows
Model output is only part of the loop. You still need humans to label the selected examples.
Options:
- Label Your Data: Annotation platform and service with API access and secure workflows
- Label Studio: Flexible, open-source, supports custom workflows and model integration
- CVAT: Best for image and video annotation
- Internal UIs: If your team already uses a custom labeling interface, just expose uncertainty scores or selection flags
Whatever tool you use, the key is minimizing friction:
- Selected samples should flow straight into annotation queues
- Labels should sync back into your training pipeline without manual steps
- You should be able to track which samples were selected, labeled, and used
The loop only works if it runs smoothly. Make integration part of your early planning.
When Active Learning Machine Learning Fails
Active learning isn’t always the right answer. It can save time and budget, but under the wrong conditions, it adds complexity without payoff.
Biased Queries and Annotation Drift
If your sampling strategy consistently picks outliers or ambiguous edge cases, you might end up with a skewed dataset. The model learns from the weirdest examples instead of the most representative ones.
This causes:
- Models that generalize poorly
- Annotators who burn out labeling unclear samples
- Inconsistent label quality across batches
You can reduce this risk by mixing sampling methods, monitoring class balance, and tracking inter-annotator agreement.
Tasks It Doesn’t Suit
Not every task benefits from active learning. It works best when:
- Labeling is expensive
- There’s high variation in sample informativeness
- The model has useful confidence signals
It’s less effective for:
- Simple binary classification with clean data
- Regression tasks where variance is low
- Use cases where all examples are equally hard
Before building a loop, test if your task actually benefits from selective sampling.
Overhead vs. Benefit in Fast-Moving Domains
In fast-changing environments, active learning may not move fast enough. If the data shifts weekly or labels are only valid for a short time, the overhead of building a loop might outweigh the benefit.
Look out for:
- Delays from manual retraining cycles
- Frequent re-annotation due to outdated data
- Engineering complexity that slows product teams
In those cases, fully supervised or semi-automated approaches might get you to production faster.If your team doesn’t have time to set up the loop in-house, a data annotation company can help implement active learning workflows at scale.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the active learning method of machine learning?
Active learning is a training method where the model selects the most informative unlabeled samples for annotation. Instead of labeling data randomly, it prioritizes examples that are uncertain, diverse, or likely to improve performance, making better use of limited labeling budgets.
What are real-world examples of active learning in machine learning?
Active learning is used in many production ML workflows where labeling is expensive. In autonomous driving, it helps prioritize rare edge cases like unusual traffic scenarios. In medical imaging, it reduces the number of scans doctors need to label by focusing on uncertain predictions. It's also used in email spam detection, where human reviewers label ambiguous messages to improve filtering systems over time.
What is active and passive learning in ML?
In active learning, the model plays a role in deciding which data to label next. In passive learning, samples are labeled in bulk or randomly, without model input. Active learning is typically more efficient when labeling is costly or datasets are large.
What is the difference between deep learning and active learning?
Deep learning refers to model architecture. Specifically, neural networks with many layers. Active learning is a data selection strategy. You can apply active learning to deep learning models to reduce the amount of labeled data they require for training. In addition, you can apply it across many types of LLMs, including encoder-decoder, causal, and instruction-tuned models.
What tools or libraries support active learning in machine learning?
Popular tools include modAL, a flexible Python library built on scikit-learn; Cleanlab, which helps identify mislabeled data and rank samples by uncertainty; and Label Studio, which supports integration with model outputs for human-in-the-loop workflows. For deep learning tasks, teams also use frameworks like Prodigy and scikit-activeml to build full annotation loops.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.