Agentic RAG: How Autonomous Agents Use Retrieval at Runtime

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Traditional RAG Hits a Ceiling
- What Agentic RAG Really Means
- Architectures: Agentic RAG Variants in the Wild
- When to Use Agentic RAG (vs Vanilla RAG or Fine-Tuning)
- How to Build Agentic RAG Systems: Tools, Frameworks, Models
- Lessons from Real Systems
- Beyond Retrieval: What’s Next for Agentic Architectures
- About Label Your Data
- FAQ

TL;DR
- Traditional RAG systems rely on one-shot retrieval, which limits their ability to adapt during complex, multistep reasoning tasks.
- Agentic RAG uses autonomous agents that plan, remember, and use tools dynamically while executing tasks.
- These systems turn LLMs into task-solving agents that retrieve and adapt on the fly, rather than just reacting to prompts.
- Agentic RAG supports ongoing validation and refinement, reducing errors in high-stakes tasks.
- It balances flexibility with extra latency and complexity, so it’s not ideal for every project.
Why Traditional RAG Hits a Ceiling
RAG (Retrieval-Augmented Generation) has become a solid option when you need your language model to reference up-to-date or external knowledge. By injecting relevant documents into the context window at inference time, you can sidestep a lot of the limitations baked into the model’s pre-training data.
But classic RAG is still pretty rigid, it retrieves once, generates once, and calls it a day. This approach falls apart with more complex tasks where you need more specific in-context learning. That’s one reason agentic systems are gaining traction: 33% of enterprise software is expected to include agentic AI by 2028, up from under 1% in 2024.
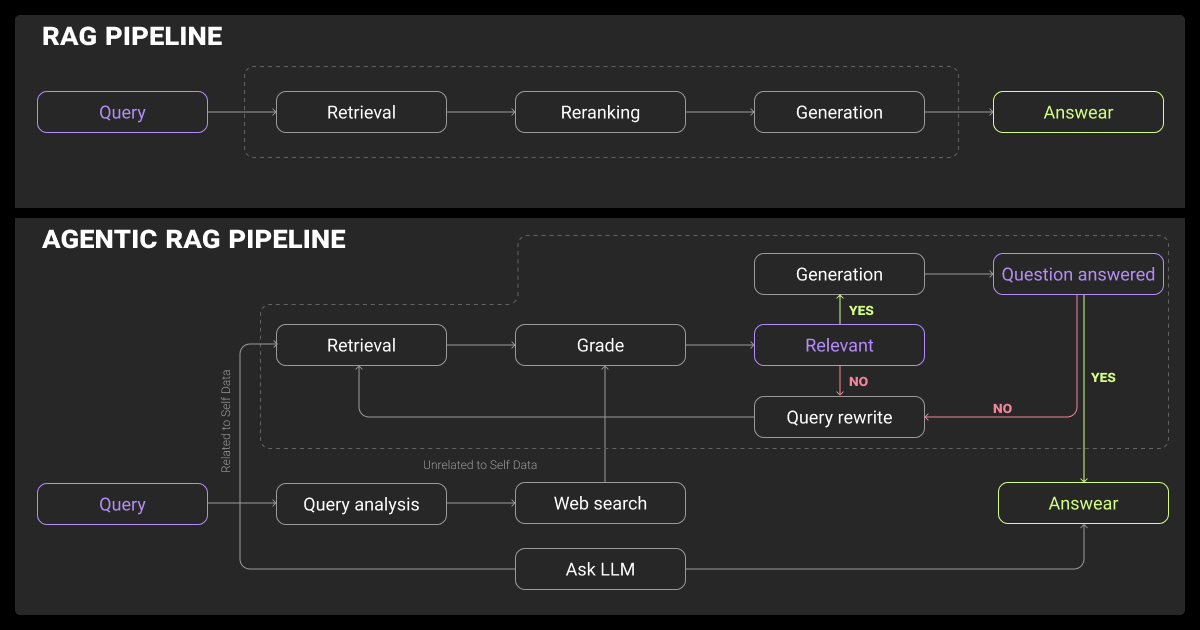
Static RAG agents won’t cut it if the model needs to:
- Reason through multiple steps
- Adapt as it learns new information
- Validate its own answers
One-Shot Retrieval and Static Context Windows
In a standard RAG setup, the process is dead simple:
- Retrieve a few documents based on the input
- Cram them into the context window
- Let the model generate a response
This works fine for basic Q&A or single-turn tasks where you already know what to look for. But that simplicity is also its weakness. You only get one shot at finding the right documents.
If your initial retrieval is off, too vague, or just misses something important, the model doesn’t get a second chance. Worse, even if you manage to pull in decent context, you’re still at the mercy of the window size. Going beyond 100K tokens helps a bit, but once you pack in too much loosely relevant content, performance drops fast.
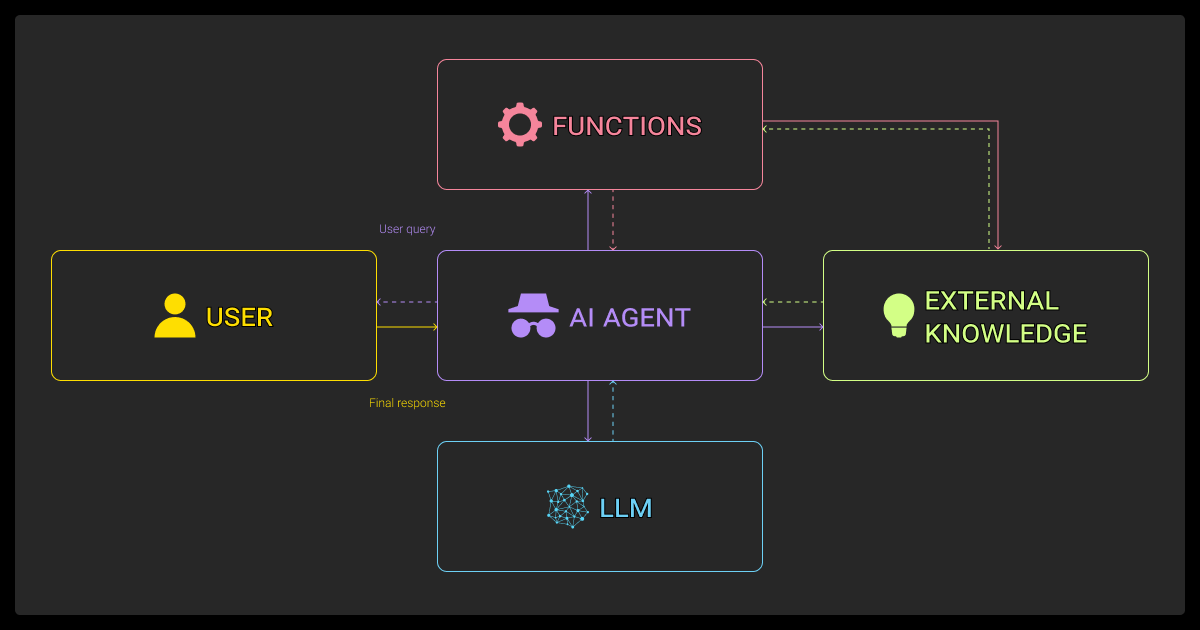
What Agentic RAG Really Means
Agentic RAG isn’t just a tweak to RAG, it’s a fundamental shift in how we approach retrieval and generation. Instead of asking the LLM agents to do everything in one pass, you build a loop around it.
What you get is something that seems similar to a multi agent LLM. It can plan, fetch new data, call tools, evaluate outcomes, and keep going. When it comes to RAG vs fine tuning, the difference is that the LLM here improves by thinking things through rather than just examining examples.
Key Components of Agentic Systems
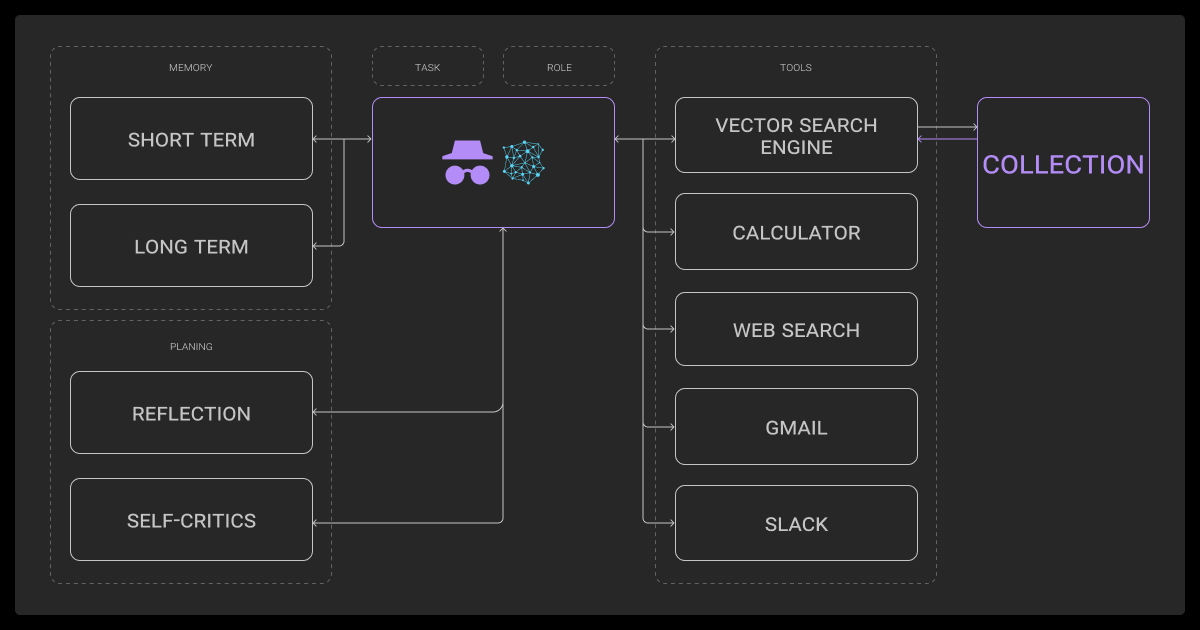
At their core, agentic RAG LLM systems tend to share three big features:
Memory
Agents don’t start from scratch every time. They track what they’ve done and use that history to guide their next steps.
Planning
Instead of just reacting, agents break down the task into sub-goals. That could mean identifying what to retrieve, when to validate, or how to chain together tools. This makes the LLM fine tuning process especially important.
Tool use
Retrieval is just one of many actions. Agents might use calculators, APIs, or even other models depending on what the task demands.
That interactivity changes the whole game. Instead of “Here’s your context, now generate,” we’re saying “Work out what you need, get it, and keep refining until you’re done.”
Agentic RAG depends on quality training data. Data annotation services supply accurate labels that help fine-tune LLMs for better planning and retrieval. Without this, agents risk errors and hallucinations.
From Query to Action: The Role of Planning and Tools
In these systems, retrieval doesn’t happen only at the beginning, it can occur at any point during execution. The agent decides when it needs more information, what to search for, and what to do with the results.
Say, for example, that you’re training an image recognition program for security software. How do you define what makes for suspicious behavior? The definition would depend on what your LLM data labeling and video annotation services develop over time. This can change as the model learns.
Planning mechanisms vary widely. Some use lightweight scratchpads like ReAct-style prompts. Others go heavier, with modules that explicitly predict a sequence of tool calls.
Either way, agents use feedback from each step to decide what to do next. They might think: “That answer is too vague; better re-retrieve,” or “Confidence is low, it’s time to validate with a second model.”
This is another example of why good data annotation and LLM fine-tuning services are so vital. Experts in LLM reasoning and LLM evaluation will ensure that the machine learning dataset is full of highly-relevant, top-quality examples so your model can learn properly.
Those training large action models in these complex step-by-step processes might use LLM reinforcement learning at each step so that the machine learning algorithm learns the right way.
Architectures: Agentic RAG Variants in the Wild
There’s no universal architecture for building RAG agents with LLMs. Agentic RAG systems may include up to five distinct agents working in tandem to improve retrieval accuracy and reduce hallucinations.
You’ll see everything from single-agent loops to teams of specialized agents passing messages. What you choose depends on your task complexity, performance needs, and how many moving parts you’re willing to juggle.
Single-Agent Routers vs Multi-Agent Systems
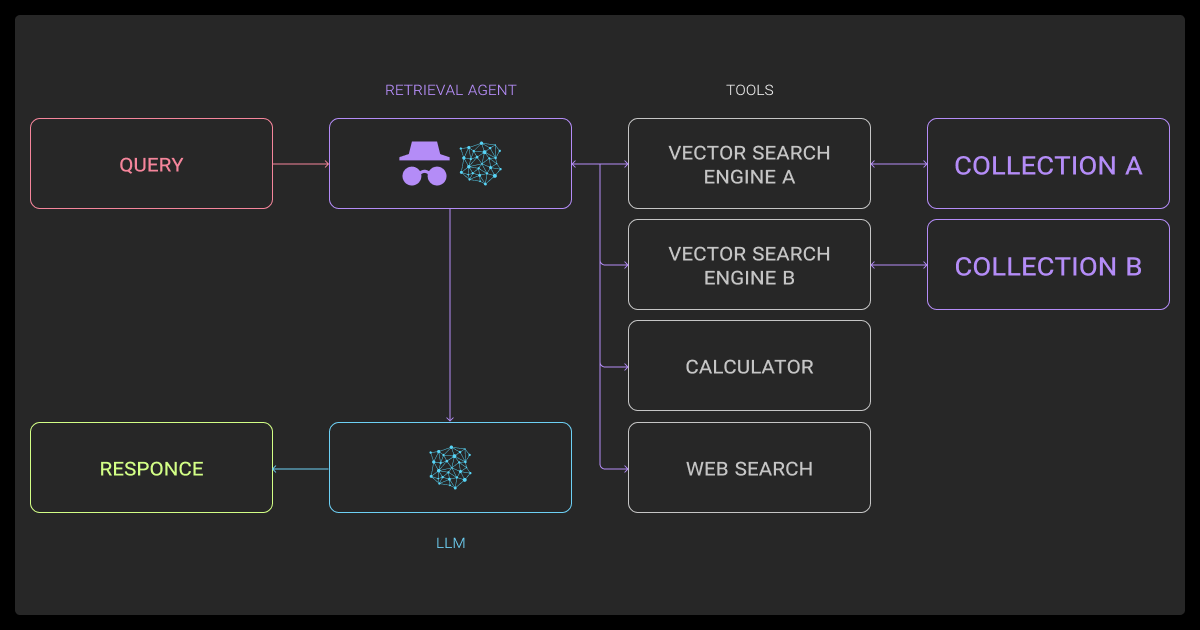
A lot of teams start with a single agent that does everything:
- Plans the steps
- Retrieves documents
- Runs tools
- Generates the answer.
This kind of setup is easier to debug and manage. It works well for narrow domains, like summarizing documents, extracting data, or assisting with code.
For bigger or more ambiguous tasks, a multi-agent design helps. You might break things out into:
- A planner that figures out which tools to use and in what order
- A retriever that handles search and document selection
- An executor that pulls it all together and produces the output
Frameworks like LangGraph, CrewAI, and DSPy support these kinds of modular setups, usually through graph-style orchestration or message passing.
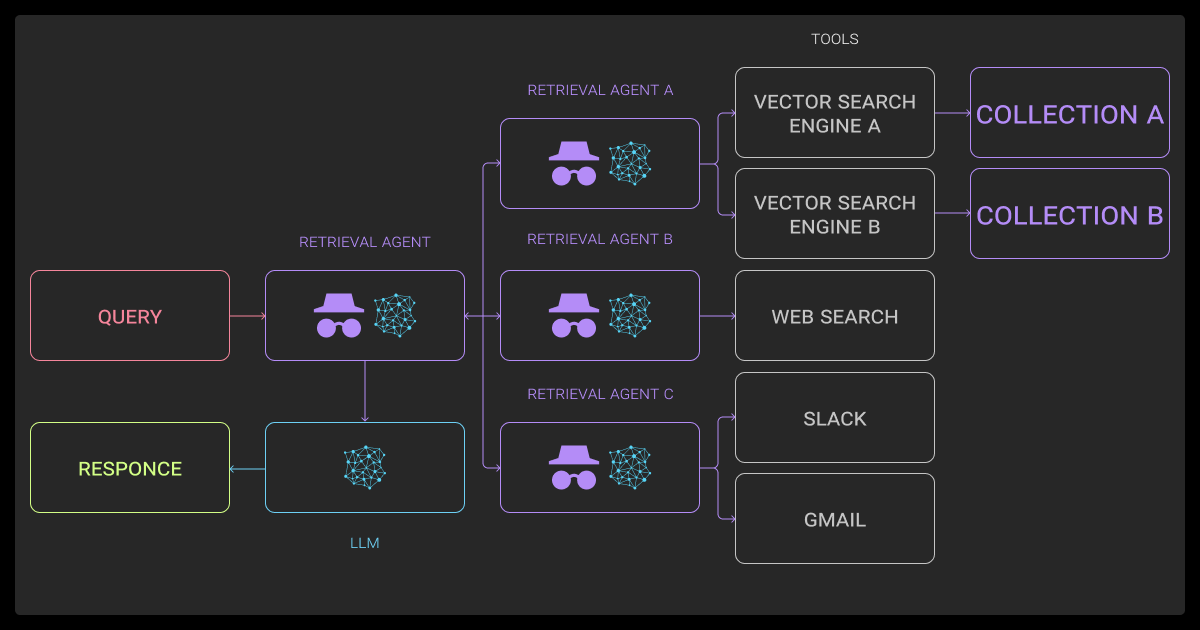
Retrieval Agents, Planners, and Tool-Calling Agents
In more advanced Agentic RAG systems, agents fall into specific roles:
- Retrieval agents handle dense, sparse, or hybrid search. Some even reformulate queries on the fly depending on the evolving task.
- Planners predict action sequences; either all at once or step by step.
- Tool-callers handle structured outputs and run external tools like calculators, APIs, or summarization chains.
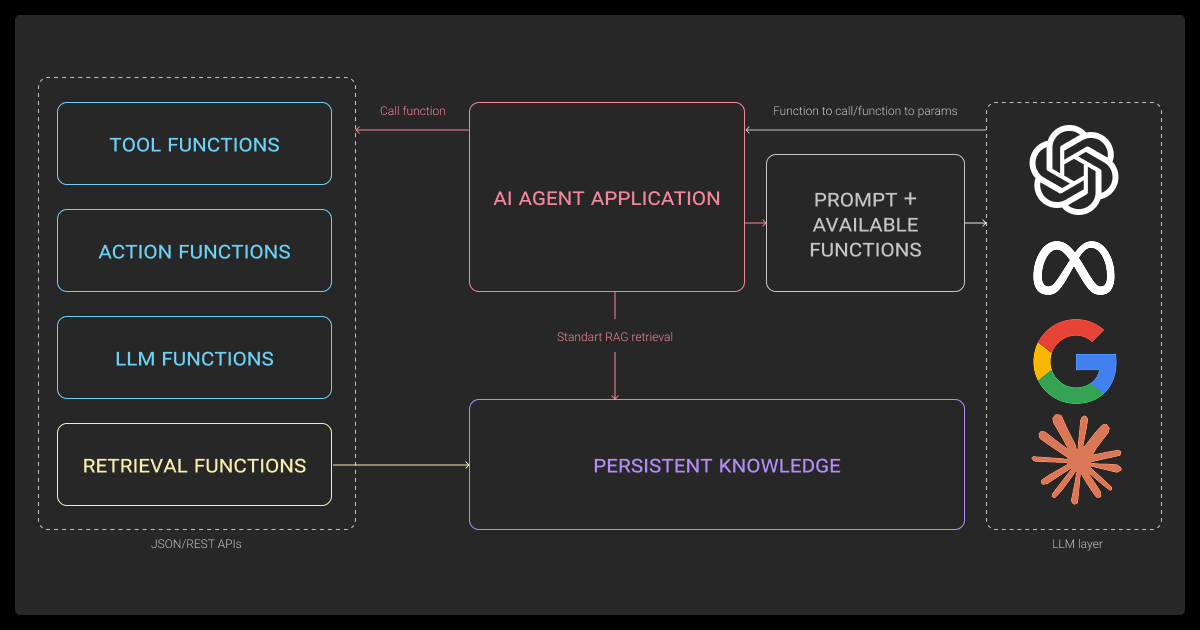
You’ll need orchestration glue to make these pieces talk to each other. A professional data annotation company might use tools like LangChain, CrewAI, or Letta.
We developed a tiered retrieval system for time-sensitive security agents, delivering immediate response patterns while loading nuanced context in the background. This cut false positives by 47% in a manufacturing client’s phishing defense, making responses business-aware, not just technically correct.

 Owner at tekRESCUE
Owner at tekRESCUE
For a visual breakdown of how Agentic RAG lets LLMs choose data sources and adapt retrieval strategies in real time, watch this explanation.
When to Use Agentic RAG (vs Vanilla RAG or Fine-Tuning)
Just because you can build an agentic system doesn’t mean you should. These systems are powerful, but they also come with more moving parts, longer latencies, and new places where things can go wrong.
Use Cases That Require Runtime Adaptation
Agentic RAG architecture really shines when:
- The prompt doesn’t give you everything you need to retrieve relevant data in one pass
- The model needs to make intermediate decisions or interpret results before moving on
- The knowledge base is huge or constantly changing
- You need to validate facts, not just generate likely-sounding answers
Some real-world examples:
- Legal tools that follow citation trails across statutes and case law
- Enterprise systems with access-controlled, multi-tenant knowledge graphs
- Research assistants parsing long, technical documents in biomedical or academic domains
- Dev copilots that mix logs, API docs, and runtime debugging
Trade-Offs: Cost, Latency, and Complexity
Every time your RAG architecture LLM agent decides to retrieve or validate something, you’re adding latency and token costs. And every orchestration layer introduces more things that can break.
Fine-tuning, by comparison, gives you more predictable outputs and simpler runtimes—but at the cost of flexibility and freshness. You’re baking knowledge in, which limits flexibility for fast-changing or ambiguous problems.
Our agents use a memory and reasoning loop to detect gaps and formulate semantic queries to a domain-specific vector store. This allows retrieval of richer, context-aware chunks, improving relevance. Yet hallucinations persist if retrieved docs are logically off or lack enough disambiguation, so we rely on strict grounding constraints in prompts.
 Marketing Content Manager at Techstack
Marketing Content Manager at Techstack
How to Build Agentic RAG Systems: Tools, Frameworks, Models
Let’s talk about what’s actually under the hood of a RAG agent.
Agent RAG Frameworks
These are the main orchestration libraries you’ll see:
- LangChain: Want a flexible agentic rag? LangChain delivers with support for memory, tools, chains, and agent loops. Works for everything from POCs to full prod systems.
- CrewAI: Optimized for multi-agent collaboration. Uses role-based messaging and shared objectives.
- DSPy: Think of it like a compiler for agent workflows: declarative modules and trainable chains.
- Letta: A newer take focused on LLM-native planning and minimal boilerplate.
Each one offers a different balance of control and convenience.
Function Calling with LLMs
Modern LLMs now support structured function calls, letting you define tools with specific input/output schemas.
Popular setups:
- OpenAI (gpt-4-turbo): Clean JSON-based calling with auto-schema validation and dynamic routing
- Anthropic (Claude 3): Leans into transparency and safe reasoning through tool-use messages
- Ollama: Great for local deployments with offline tool support
You define something like search(query) or calc(expression); the model picks the tool when needed.
Integrating Tool Use
Here’s what tool use usually looks like in practice:
- Search APIs (Google, Bing, internal KBs) for live lookups
- Vector stores (FAISS, Pinecone, LanceDB) for semantic retrieval
- Calculators/logic engines for anything involving math or validation
- APIs or databases (SQL, REST, GraphQL) to pull structured data
You can also plug in rerankers like ColBERT or Cohere to fine-tune search results in real time.
Lessons from Real Systems
A lot of teams are experimenting with Agentic RAG right now, some with great success, others hitting roadblocks. Here’s what we’ve learned so far.
What Works Well Today
- Keep the agent loop short. Use it to summarize, validate, or chain small actions, not simulate a whole project.
- Hybrid retrieval (dense + sparse + reranking) works better than just dense search, especially in complex domains.
- Using function-calling models for planning and execution improves output quality and reduces hallucinations.
- Letting the model label and build its own retrieval corpus bootstraps performance fast, especially in niche verticals.
What Still Breaks
- Long-term memory is hit-or-miss. Most systems fake it with document threading.
- Tool failures are painful. If an API fails or returns junk, most agents don’t recover well.
- Latency scales fast. Multi-agent chains can easily stack up 20+ seconds per run.
- Cost tracking across retrievals and tools is still murky, especially at scale.
Our biggest breakthrough came when implementing contextual retrieval for video script generation, pulling from style guides, high-performing content, and client testimonials simultaneously. The key challenge was ‘hallucination bleed’—agents blending retrieved info with made-up details. We solved this with a triple-verification system requiring multiple sources to validate claims.
 CEO at REBL Labs
CEO at REBL Labs
Beyond Retrieval: What’s Next for Agentic Architectures
Agentic RAG is just the start. The next wave of architectures will push into reflection, memory, and fully autonomous workflows.
Memory-Augmented Agents for Long-Term Interaction
LLMs don’t remember anything by default. But agents with memory layers, whether vector-based or symbolic, can start building continuity across sessions.
- Short-term memory: Scratchpads, context stitching, or windowed attention
- Long-term memory: Semantic logs, project graphs, conversational timelines
Projects like MemGPT and models with longer context windows (Claude 3, Gemini 1.5) are moving this forward.
Autonomy Loops and Reflection-Based Agents
Agents that can step back and rethink their own approach are starting to show up.
- Reflexion, CAMEL, AutoGPT: All explore agents that critique, revise, and replan
- Tool feedback loops: Let agents rate their own outputs and decide whether to retry
- Simulated environments: Test and refine agent behavior through trials or feedback-driven replay
The goal is not just retrieving the right snippet, but learning which strategies work over time.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an agentic RAG?
It’s a retrieval-augmented generation system where the LLM acts as an agent and plans, retrieves, uses tools, and adapts its behavior throughout the task.
What is the difference between RAG and agentic search?
RAG does retrieval once, then generates. Agentic search treats retrieval as an action that can happen anytime, based on the agent’s evolving plan.
What is the performance of the agentic RAG?
It depends on the task, but Agentic RAG tends to beat vanilla agent RAG in complex or under-specified problems, especially in accuracy. The trade-off is more latency and higher costs.
What does RAG mean in AI?
It stands for Retrieval-Augmented Generation, basically combining different types of LLMs with a search system to answer questions using external data. An agentic RAG AI agent can handle more complex tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.