LLM Evaluation: Benchmarks to Test Model Quality

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Evaluating LLMs Is So Hard (and Important)
- LLM Evaluation by Use Case: No One-Size-Fits-All
- Key LLM Evaluation Metrics That Actually Matter
- Core LLM Benchmarks: What to Know
- Beyond Benchmarks: Evaluating Fine-Tuned LLMs
- LLM Evaluation Tools and Frameworks
- Challenges in LLM Evaluation
- Continuous Evaluation in Production
- Where LLM Evaluation Is Going Next
- Pulling It All Together
- About Label Your Data
- FAQ

TL;DR
- LLM evaluation is complex because models handle many different tasks.
- No single benchmark is enough; you must tailor evaluations to your specific use case.
- The best results come from combining quantitative metrics (like BLEU, groundedness scores) with human judgments.
- Fine-tuned, RLHF, and domain-specific models need deeper, customized evaluation pipelines.
- Continuous real-world monitoring is essential — static benchmarks alone won’t catch performance drift.
Why Evaluating LLMs Is So Hard (and Important)
LLM evaluation is a challenging but crucial task. Their versatility across various tasks makes it difficult to design a one-size-fits-all evaluation. Accurate evaluation is crucial for building reliable LLM applications.
In this post, we’ll look at LLM evaluation benchmarks that make this task easier.
LLMs don’t have a single task. LLMs can perform a range of tasks from text generation to summarization. That means that any LLM evaluation framework you choose must be multidimensional.
Good benchmarks prevent bad decisions. Some people don’t think that robust LLM model evaluation is worth the time or effort when there are time or budgetary restraints. If you don’t take this step, LLM fine tuning can fall flat.
LLM Evaluation by Use Case: No One-Size-Fits-All

Given the diverse applications of large language models, you must tailor your evaluations to specific use cases to obtain meaningful insights into model performance. A data annotation company focused on image recognition tasks will evaluate model output differently than a company using LLMs for document summarization or customer support.
Instruction-Following and Chat
Benchmarks like MT-Bench, AlpacaEval, and the LMSYS Chatbot Arena assess models on their ability to follow instructions and engage in dialogue.
These evaluations focus on metrics like:
- Helpfulness
- Harmlessness
- Honesty
These are all important to the end user.
Reasoning and Multi-Step Tasks
Datasets like GSM8K, MATH, BBH (Big Bench Hard), and DROP test your model’s reasoning capabilities and its ability to handle multistep tasks. These benchmarks often employ:
- Few-shot learning
- Chain-of-thought prompting
- Tool-augmented approaches
Code Generation
Benchmarks such as HumanEval, MBPP, and APPS evaluate your model’s ability to generate functional code. Key evaluation criteria include:
- Functional correctness (does the code solve the problem?)
- Syntax validity
- Successful execution of test cases
Retrieval-Augmented Generation (RAG)
In RAG systems, models generate responses based on retrieved documents. Evaluations focus on:
- Grounding, ensuring responses are based on retrieved information
- Factual accuracy
- The detection of hallucinations
You can use datasets like TruthfulQA and FEVER, along with custom grounding tests. Datasets like FEVER can be adapted for evaluating factual consistency in RAG systems, but custom grounding tests are typically needed for more precise RAG evaluation.
Multilingual and Domain-Specific Tasks
Benchmarks like XTREME, XQUAD, and Flores-200 assess your model’s performance across multiple languages. You’ll need specialized quality assurance sets in domain-specific evaluations for fields like law or medicine.
Key LLM Evaluation Metrics That Actually Matter
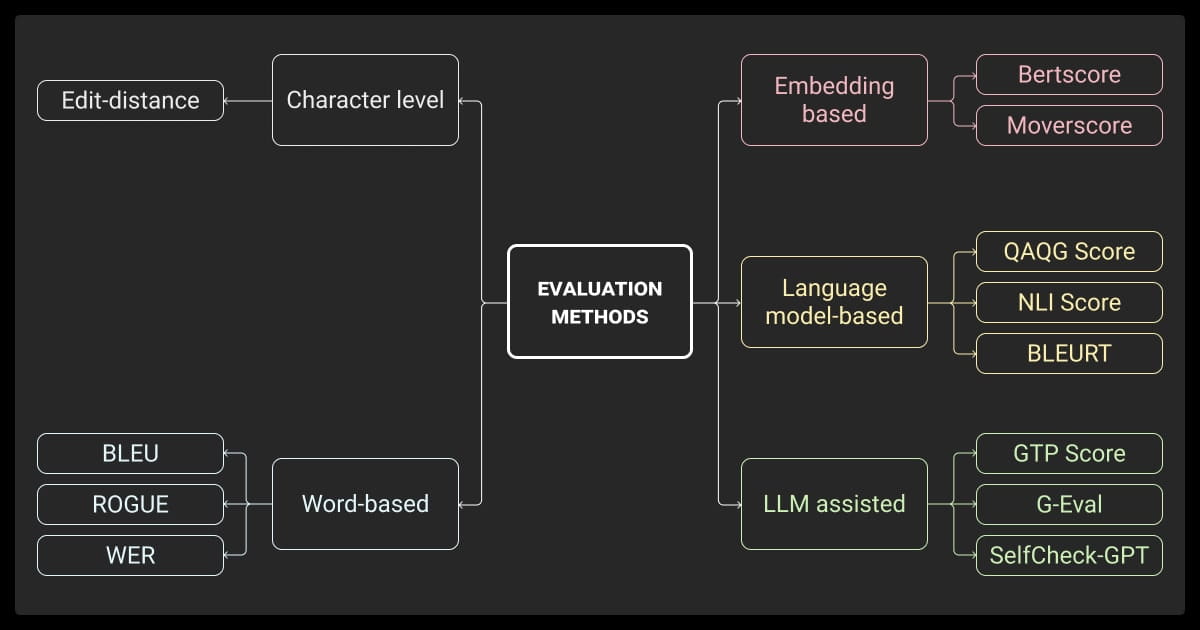
Want the best results from your LLM evaluation methods? You’ll need to combine quantitative and qualitative assessments that cover different aspects of the model’s performance.
Token-Level and Overlap Metrics
Metrics such as BLEU, ROUGE, METEOR, and BERTScore measure the overlap between the model’s output and reference texts. While useful for tasks like translation and summarization, these LLM evaluation metrics may not fully capture semantic nuances or the quality of generated content.
Newer metrics like revision distance focus on how much human editing is required to improve an LLM’s output, offering a more human-centered way to measure quality and usability.
Semantic and LLM-as-Judge Evaluations
Want to know how human users will rate your model? You can get an idea of this with evaluations using:
- Win rates in pairwise comparisons,
- GPT-4 judge pipelines
- Elo rankings
Benchmarks like MT-Bench and Vicuna evaluations use these methods for a more holistic view.
Faithfulness and Grounding Metrics (for RAG)
You have to use metrics like Precision@K, groundedness scores, and hallucination rates to evaluate RAG systems. They measure how accurately your model’s responses align with the retrieved documents.
Human Preference Judgments
Collecting clean pairwise data through human evaluations provides valuable insights into model preferences and performance. Companies like OpenAI, Anthropic, and Meta use various methods to gather and interpret human feedback, enhancing their model’s performance in line with user expectations.
When collecting human preference data, providing clear calibration guidelines to annotators improves consistency and reduces noise in evaluations.
Core LLM Benchmarks: What to Know

Now let’s look at the key benchmarks you’ll need to create good LLM evaluation frameworks.
MMLU
The Massive Multitask Language Understanding benchmark assesses general multitask reasoning across 57 subjects. However, its usefulness is becoming more limited as models approach saturation. MMLU-Pro is the natural evolution because:
- It’s more challenging
- Poses reasoning-focused questions
- It expands the choice set
TruthfulQA
TruthfulQA evaluates your model’s ability to provide factually accurate responses, especially under adversarial prompting. It’s instrumental in assessing how often your model generates misinformation.
HellaSwag and PIQA
These benchmarks test commonsense and physical reasoning. HellaSwag focuses on everyday scenarios, while PIQA assesses physical commonsense knowledge, both critical for real-world applications.
Beyond general benchmarks, domain-specific tests like ScienceBench push LLMs to demonstrate true scientific understanding and multistep reasoning
HumanEval and MBPP
HumanEval and MBPP are benchmarks for evaluating functional code generation accuracy. They test your model’s ability to produce correct and executable code snippets.
MixEval and LMUnit
MixEval offers a composite evaluation across diverse tasks, while LMUnit provides unit-test-style LLM agent evaluation.
Human-in-the-loop validation has been our game-changer for measuring LLM performance at PlayAbly.AI, especially in e-commerce applications. We now use a combination of automated accuracy scores and regular merchant feedback samples, which helped us improve our real-world accuracy from 65% to 92% in just three months.

 CEO, PlayAbly.AI
CEO, PlayAbly.AI
Beyond Benchmarks: Evaluating Fine-Tuned LLMs
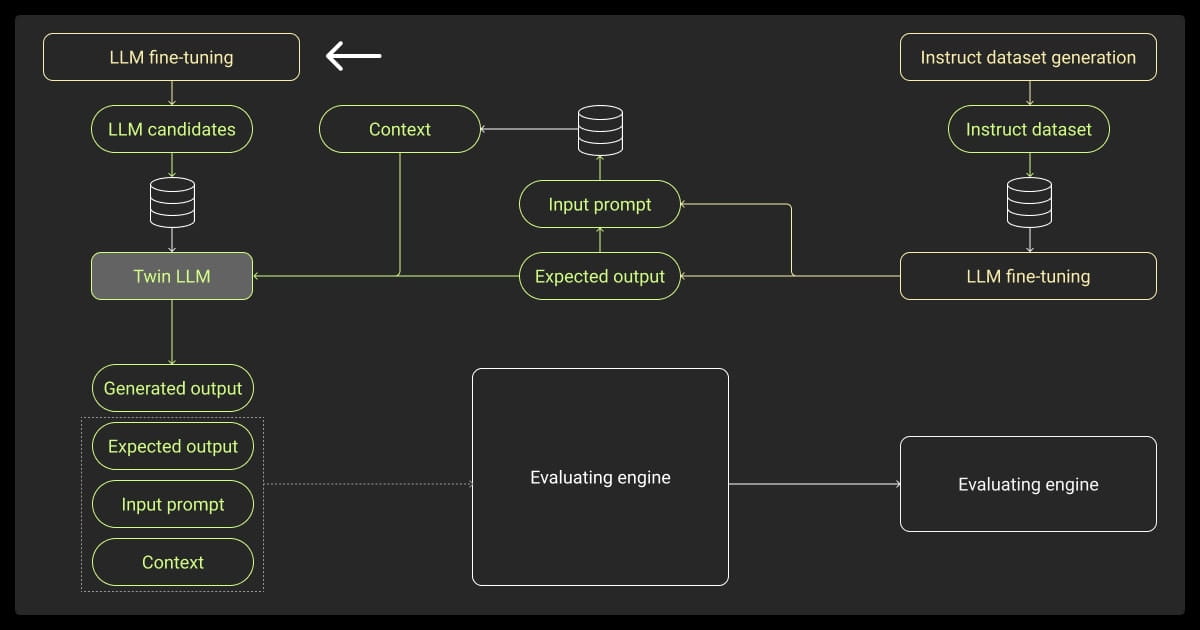
You can get a high-level view of your model’s general capabilities, but you need to dig deeper to pick up the nuances that crop up after fine-tuning. Whether you’re applying instruction tuning, reinforcement learning from human feedback (RLHF), or adapting a foundation model to a niche domain, your evaluation method needs to evolve with your model.
LLM Evaluation Before and After Fine-Tuning
Is fine-tuning helping or harming your model? You can use tools like AlpacaEval to compute deltas in win-rates or helpfulness scores before and after fine-tuning, helping you track progress.
You should also look for signs of overfitting or regressions. For example, a model that becomes overly verbose or loses generalization capabilities after instruction tuning likely needs further regularization or revised objectives.
Watch for signs of catastrophic forgetting, where the model loses previously acquired capabilities unrelated to the fine-tuning domain.
Comparing performance across tasks and user prompts before and after fine-tuning highlights these shifts.
Evaluating RLHF, DPO, or RLAIF Models
Things change a bit with an LLM evaluation platform for models you train with reward optimization like RLHF, Direct Preference Optimization (DPO), or Reinforcement Learning with AI Feedback (RLAIF). Here you’re not checking the raw predictive accuracy, but rather how well the model will work in terms of human preferences.
You can use:
- Measuring pairwise win rates with human or model judges.
- Tracking agreement with reward models.
- Watching for behavioral drift or reward hacking, where the model finds loopholes in the objective function (e.g., sounding helpful while avoiding real answers).
It’s useful to periodically re-run prior evaluations on updated models and analyze qualitative shifts in behavior.
Note that reward models can introduce their own biases, so it's important to validate reward functions against real-world preferences periodically.
Evaluating Custom Domain Performance
If you’re deploying LLMs in sensitive domains like law, finance, or medicine, general benchmarks won’t cut it. You’ll need a custom evaluation machine learning dataset that reflects domain-specific tasks, tone, and expectations.
IBM Research recently proposed a new set of enterprise benchmarks designed to bridge the gap between traditional academic tasks and real-world business needs.
Examples include:
- Legal question answering with citation grounding.
- Clinical summarization with attention to accuracy and terminology.
- Finance-focused reasoning over earnings transcripts or filings.
You should never rely too heavily on public benchmarks for niche domains, as they may already exist in the model’s pretraining data, contaminating results. Instead, build held-out internal test sets and manually verify their uniqueness.
Don’t know where to start? Consider hiring data annotation and data collection services to supplement your machine learning and training data.
LLM Evaluation Tools and Frameworks
Now that you know what to measure, it’s time to find the right tools. Fortunately, there are a lot of open-source libraries and in-house frameworks for rigorous evaluation.
Open Source Tools
You can use these tools to run standardized benchmarks and track the performance of your machine learning algorithm:
- OpenAI Evals: Framework for custom LLM test cases and scoring.
- DeepEval: Automates multi-metric LLM evaluations, including LLM-as-judge.
- Eleuther’s Evaluation Harness: Community tool for classic NLP benchmarks on open models.
All of these support integration with your model via API or local inference, which makes them useful in comparing open and closed models.
Custom Evaluation Pipelines
For more control and relevance, you can build internal pipelines:
- Dataset generation and curation for specific use cases.
- LLM-as-judge pipelines that incorporate prompts like “Which of these two responses is better?” using GPT-4 or Claude as reviewers.
- Logging, versioning, and feedback workflows that support iterative development.
- Metadata tagging, for example, input type, user intent, to enable nuanced performance slicing.
Custom pipelines support regulatory compliance, reproducibility, internal audits, and better risk management.
Challenges in LLM Evaluation
No matter what types of LLMs you’re working with, there’s a lot of debate about effective evaluation. The challenges arise from limitations in today’s benchmarks and data sources.
Benchmark Saturation
As top-tier models approach the upper bounds of static benchmarks like MMLU or HumanEval, these tests become less useful for distinguishing new progress. This can result in overfitting on those benchmarks because the test sets are no longer challenging or representative.
Composite and adversarial benchmarks (like MixEval or MMLU-Pro) are gaining traction because they introduce novelty and harder reasoning tasks. These help you avoid plateauing and push deeper understanding.
Data Contamination and Train-Test Leakage
Many people worry that open benchmarks are present in the model’s pretraining data. This introduces data leakage, inflating evaluation scores without reflecting real generalization.
To mitigate this:
- Use held-out evaluation sets that are explicitly excluded from training.
- Prefer synthetic test sets generated post-training.
- Validate critical benchmarks with adversarial checks
Evaluation Bias and Subjectivity
LLMs are sensitive to prompt wording, formatting, and tone, which can skew results. This makes comparison tricky, especially for instruction-following and open-ended generation.
To reduce evaluation bias:
- Use template consistency across prompts.
- Run A/B tests with randomized orderings.
- Use multi-annotator voting for human preference data.
Real-world task completion rates and error tracking tell us more than theoretical metrics. Just last month, we caught a critical issue in our content generator by monitoring user correction patterns, which wouldn't have shown up in standard benchmark tests.
 CIO and Founder, Local Data Exchange
CIO and Founder, Local Data Exchange
Continuous Evaluation in Production
Static benchmarks can’t capture how models behave in the wild. You need ongoing monitoring and real-world feedback for this.
Evaluation as Part of Deployment Workflow
You should make evaluation part of your CI/CD loop. Every model update, whether it’s a fine-tuning checkpoint or a new backend provider, should trigger:
- Regression tests across standardized tasks and prompts.
- Hallucination detection for RAG-based applications.
- Tracking concept drift, where model performance degrades as input distributions or user behaviors shift.
This reduces the risk of silent regressions and gives you clear metrics to compare versions over time.
User Feedback and Implicit Signals
Structured user feedback is invaluable. Common signals include:
- Thumbs up/down ratings
- Edit rates (e.g., how often users change model responses)
- Downstream success metrics, like form completion or retention
Even passive metrics, when aggregated properly, can supplement your internal benchmarks with a real-world lens. Just make sure your logs are tagged and privacy-compliant.
I have found the correction-to-completion ratio to be the most reliable evaluation metric when judging LLM performance in production use cases. It measures the accuracy and effectiveness of the LLM in providing correct information or completing a given task. In content-heavy pipelines, such as marketing copy, email drafts, and chat replies, a consistently low CCR means the LLM is genuinely useful, not just plausible.
 Founder, Deep AI
Founder, Deep AI
Where LLM Evaluation Is Going Next
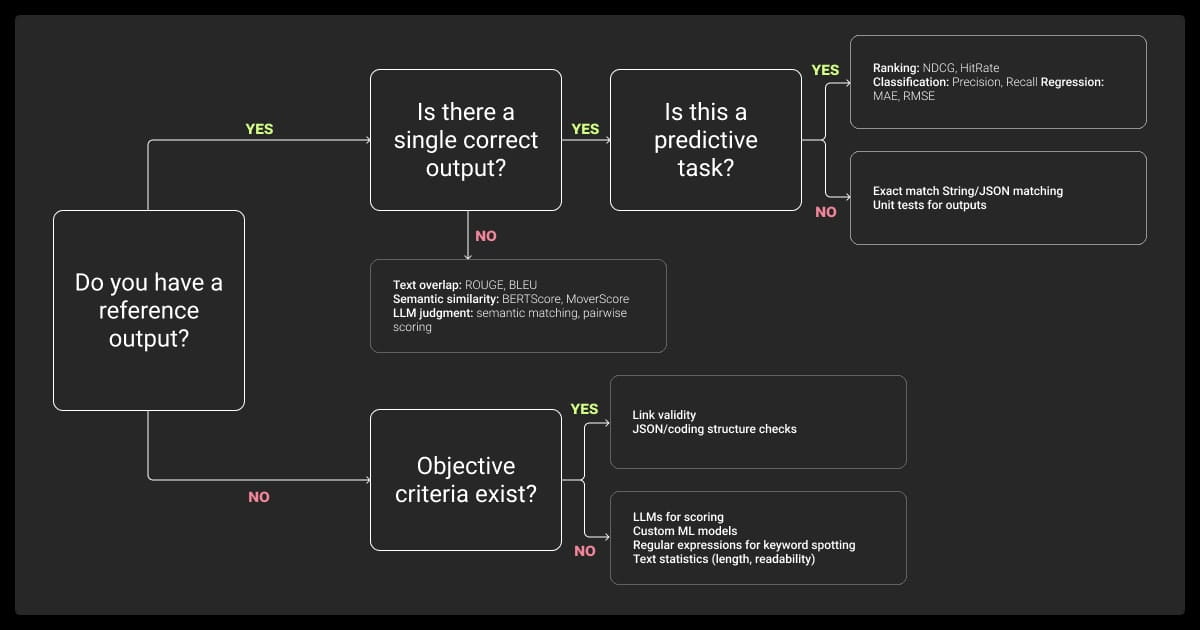
Evaluation is rapidly evolving alongside LLM capabilities. The next wave of tools and methodologies is aiming to stay ahead of emerging model capabilities and risk factors.
As LLM applications move beyond static tasks into autonomous decision-making, evaluating LLM-based agents presents new challenges in reasoning, tool use, and collaboration
Adaptive Benchmarks
Instead of static test sets, adaptive benchmarks dynamically generate evaluation tasks based on the model’s strengths and weaknesses. For example:
- Generating edge-case prompts based on prior failures.
- Creating new QA pairs with varying complexity and novelty.
- Auto-generating distractors to challenge reasoning chains.
This keeps evaluation a moving target, pushing models beyond memorization.
Multimodal Evaluation
With models like GPT-4V, Claude 3, and Gemini handling image + text inputs, we’re seeing new benchmark types:
- Chart understanding and data extraction.
- Visual question answering (VQA) and OCR-based reasoning.
- Diagram interpretation, combining spatial and textual reasoning.
Evaluation here blends computer vision and NLP metrics, so you need new tools and datasets tailored to multimodal logic and fidelity.
LLM Evaluation for Safety, Bias, and Alignment
Measuring alignment is increasingly important, especially for public-facing or sensitive deployments. Popular benchmarks include:
- RealToxicityPrompts: Test for harmful or offensive outputs.
- BBQ and Stereoset: Measure social and stereotype bias.
- Adversarial red-teaming: Explore worst-case behaviors via probing.
Pulling It All Together
As LLMs become more capable, you have to move towards strategic evaluation. The key isn’t finding one perfect metric, it’s understanding how multiple signals work together.
There’s No Single Score That Matters
Think of evaluation like model architecture—it’s multi-layered. Combine a few metrics to get the full picture:
- Quantitative metrics like BLEU, ROUGE or accuracy
- Preference-based scores like win rates or LLM judges
- Domain-specific checks like groundedness or bias
Build LLM Eval Pipelines Early
Don’t treat evaluation as an afterthought, integrate it from the start. Build your pipeline alongside your training loop, before you even start looking at data annotation services. You’ll catch regressions early, accelerate iteration, and reduce surprises later on, reducing the overall data annotation pricing in the end.
Treat Evaluation as a Competitive Advantage
The best LLMs aren’t just intelligent, they’re measurable. Teams that invest in evaluation frameworks:
- Move faster
- Detect issues earlier
- Ship safer, more reliable models
In an increasingly crowded landscape, how you measure performance can be as important as the performance itself.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are LLM evaluations?
LLM evaluations are methods to assess the performance of large language models across various dimensions like reasoning, generation quality, factual accuracy, and alignment.
What is an example of a LLM?
Examples include OpenAI’s GPT-4, Anthropic’s Claude, Google DeepMind’s Gemini, and Meta’s LLaMA models.
What is LLM translation evaluation?
LLM translation evaluation measures how accurately a model translates text from one language to another. Metrics like BLEU or METEOR are common, but semantic similarity or human preference is often more reliable.
How to evaluate an LLM prompt?
- Check consistency: See if the model gives stable answers to the same prompt.
- Test helpfulness: Make sure responses are clear, accurate, and useful.
- Check sensitivity: Slightly change wording and see if outputs stay consistent.
- Run A/B tests: Compare different prompts to find which performs better.
- Use LLM-as-judge: Let another model or humans rate output quality.
- Track quality: Monitor which prompts consistently deliver better results.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.