LLM Observability: Monitoring and Improving Performance

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Core Aspects of LLM Observability
- Key Metrics for Effective LLM Observability
- Monitoring Large Language Model Behavior
- Detecting and Mitigating Bias with LLM Observability
- Real-Time LLM Performance Monitoring in Production Environments
- Debugging LLMs and Root Cause Analysis
- Enhancing LLM Performance Through Observability
- Best Practices for LLM Observability
- About Label Your Data
- FAQ

TL;DR
- Captures logs, metrics, and traces to monitor LLM behavior.
- Key metrics: token-level performance, latency, resource usage.
- Layer-specific monitoring to identify inefficiencies.
- Mitigate bias and drift with real-time LLM monitoring and observability.
- Scalable LLM observability tools and AI-powered anomaly detection for improved performance.
Core Aspects of LLM Observability
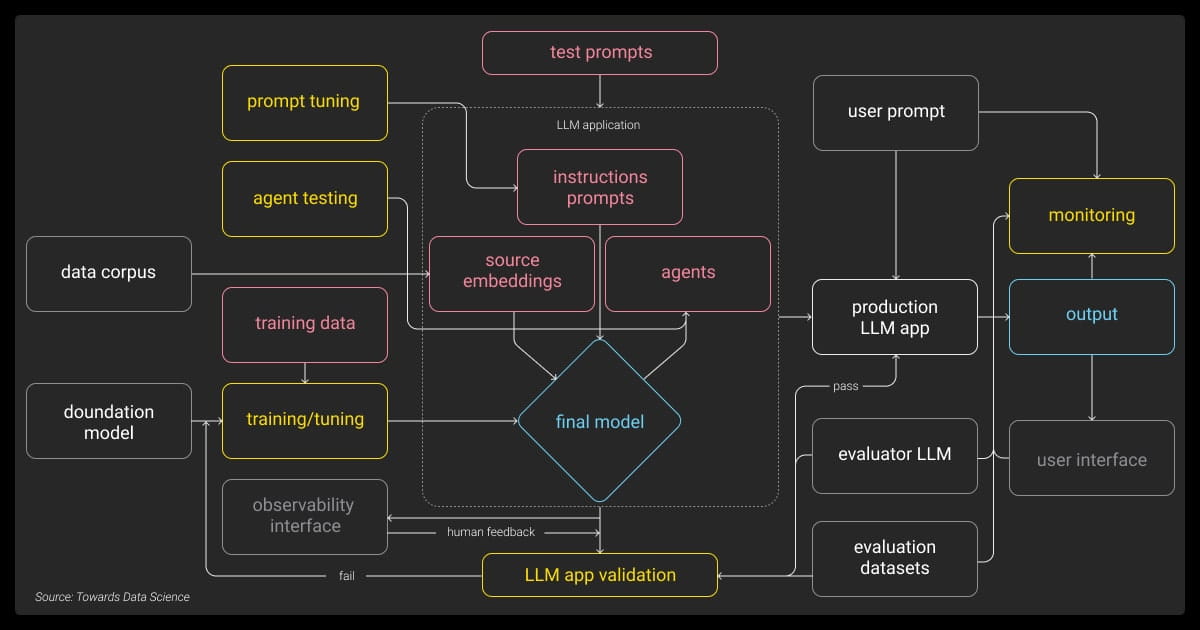
Observability is not merely about tracking outputs or computing loss values. So, what is LLM observability?
For large language models (LLMs), observability is a comprehensive system that captures metrics, logs, and traces to reveal what’s happening within the model across its layers. Unlike traditional machine learning models, LLMs have many parameters and context-based learning, which require a specialized approach to monitoring.
Observing how different types of LLMs handle context or rare word predictions can highlight areas where their performance might degrade over time. For instance, LLMs often struggle with out-of-vocabulary words, making token-level observability critical. Additionally, by visualizing model traces, you can follow individual data requests through the model layers, identifying errors or inefficiencies at specific points in the process.
Key Metrics for Effective LLM Observability
To effectively monitor LLMs, you need to track multiple metrics beyond the usual accuracy and loss. These include token-level performance, latency, resource utilization, and embedding drift.
Token-Level Metrics
One of the most important metrics for observability LLM is token-level performance. This involves monitoring how the model predicts individual tokens and sequences, especially at token boundaries. Misclassifications here can lead to larger interpretive errors in tasks like translation or summarization.
Take rare word predictions as an example: if the model frequently misclassifies rare tokens, it indicates that LLM fine-tuning or additional training data may be necessary.
Latency Metrics
For real-time applications, latency is crucial. Monitoring response times across different layers of the model helps you identify bottlenecks.
Consider the challenge of large-scale LLM deployment: latency issues often arise when handling longer inputs or increased user requests. By monitoring latency, you can ensure the model performs efficiently under high concurrency without sacrificing user experience.
“Monitoring LLM performance involves tracking metrics like latency, throughput, accuracy, and resource usage. Continuous evaluation of key datasets and real-time dashboards help maintain performance. Fine-tuning on domain-specific data reduces errors and improves task alignment. Additionally, feedback loops enable adaptive fine-tuning to handle drift and evolving needs.

 AI/ML Engineer, HubSpot
AI/ML Engineer, HubSpot
Resource Utilization
Keeping track of how your models consume computational resources is another key to maintaining performance. LLMs often require significant graphical processing unit (GPU) or tensor processing unit (TPU) resources, so understanding how memory and processing power are allocated can help you optimize both cost and efficiency.
| Resource Utilization Metrics | What It Monitors | Importance |
| GPU/TPU Utilization | How much hardware capacity is used | Helps optimize performance costs |
| Memory Footprint | Total memory used during inference | Ensures the model doesn't overuse memory |
| Inference Speed | Speed of processing large inputs | Critical for real-time applications |
By keeping an eye on these metrics, you can prevent hardware overuse, avoid performance issues, and ensure a smooth deployment even at scale.
Besides, LLM observability relies on such KPIs as data timeliness, completeness, validity, and consistency.
Monitoring Large Language Model Behavior
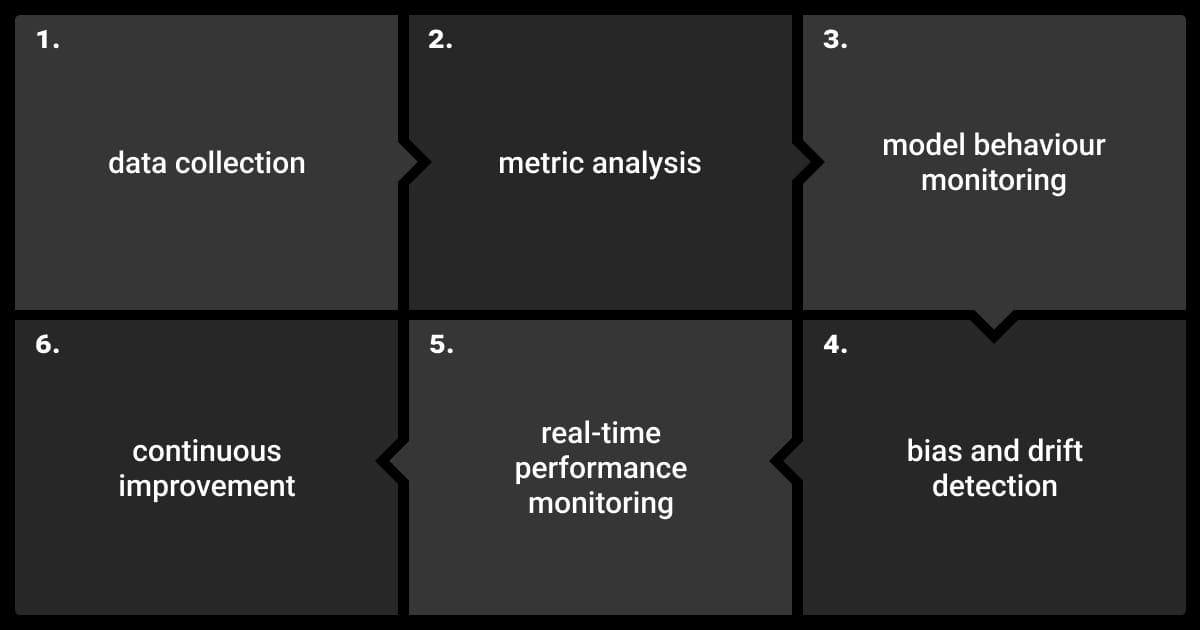
Observing how an LLM behaves internally is critical for diagnosing issues and understanding performance limitations. Instead of relying solely on output metrics, it’s essential to dig deeper into the internal workings of your model.
Layer-Specific Monitoring
LLMs operate through multiple layers, each contributing to the overall prediction. Layer-wise monitoring lets you understand how each layer processes the input and where potential issues arise.
For example, attention heads often play a crucial role in determining which part of the input receives focus. By visualizing these attention maps, you can track how different layers handle the data and identify specific layers that might contribute to model errors or inefficiencies.
Output Traceability
Tracing a model’s output back to specific inputs and processes provides deeper insights into failure points. When errors occur, it’s essential to understand not just the output but also how the model arrived at it.
Using detailed logging systems, you can trace erroneous predictions back to specific layers or data points. This is particularly useful when dealing with large models or multistep pipelines, where errors may originate from a small subset of the data but have widespread effects.
Enhance your LLM’s accuracy and reduce bias with our tailored LLM fine-tuning services. Discover how you can improve your LLMs.
Detecting and Mitigating Bias with LLM Observability
Implementing LLMs doesn't mean they will be bias-free by default. The examples include demographic, cultural, or gender biases. Implementing a powerful observability system can help you notice such instances of bias without waiting for a model's final deployment.
Bias Metrics
You can monitor specific bias metrics to track how well your model performs across different demographic groups. In defined groups, you can measure the precision or accuracy of outputs. By focusing on these metrics, you will notice if a model favors some groups more than others.
For example, if your model often underperforms a male group of people compared to female, this can be a red flag that you need to address this issue during model fine-tuning.
Monitoring Bias Drift
Bias is not static. Over time, as your model encounters new data or user inputs, bias can evolve. Tracking this phenomenon, known as bias drift, helps you stay proactive in mitigating these changes before they severely impact performance.
Embedding drift can also introduce bias. For example, the meaning of some words changes over time, and it's important to reflect this in your model performance. Whether due to social or cultural shifts, the model should reflect current realities, avoiding biased outputs.
Real-Time LLM Performance Monitoring in Production Environments
Once your LLM is live, real-time LLM monitoring and observability becomes essential. In production environments, models often face a wide variety of inputs and load conditions, making observability LLM crucial to ensure performance doesn’t degrade under pressure.
Challenges of Real-Time Monitoring
Handling large-scale LLM deployments introduces challenges like increased concurrency and dynamic input patterns. If your model is being used by thousands of users simultaneously, it’s essential to ensure it scales effectively.
For example, customer support systems using LLMs must maintain low response times even when handling high query volumes during peak hours. Monitoring in real-time ensures that the model adapts to changes in input and usage patterns without noticeable slowdowns.
To ensure that LLMs function properly and are utilized correctly, they must be evaluated against recognized standards to identify flaws in how they might be misled. Monitoring the models in real-time can help one understand what they can and cannot do. To further fine-tune LLMs, it is best to run A/B testing between different model versions. This helps identify the best-performing configurations.
 CEO & Founder, EvolveDash
CEO & Founder, EvolveDash
Solutions and Tools for Real-Time Monitoring
Implementing scalable solutions for observability in LLMs involves using open source LLM observability and custom LLM observability tools. These tools help you track real-time performance metrics and adapt to changing requirements without overwhelming your system resources.
| Observability Tool | Key Features | Use Case |
| Prometheus | Time-series data collection, alerting | Large-scale LLM deployments |
| Grafana | Real-time dashboard visualization | Monitoring resource utilization |
| Elastic APM | Distributed tracing for full-stack observability | Debugging and error tracing |
| Custom LLM Dashboards | Model-specific metrics and insights | Tailored monitoring for LLM behavior |
With these best LLM observability tools, either custom or LLM observability open source ones, you can build a scalable observability infrastructure. The on that keeps track of key metrics and adapts to high user demand while minimizing system overhead.
Debugging LLMs and Root Cause Analysis
When your LLM misbehaves or underperforms, identifying the root cause is crucial for quickly resolving the issue. Observability provides the tools needed for efficient debugging, helping you isolate problems and determine whether they stem from data issues, LLM architecture, or deployment conditions.
Isolating Errors in LLMs
By monitoring layer-specific outputs and tracing predictions back to their inputs, you can identify the exact point where the model fails. For instance, in cases where the model struggles with colloquial or domain-specific language, analyzing layer outputs might show that certain attention heads are ignoring critical context clues.
Tracking errors across multiple input types or usage conditions helps you pinpoint recurring issues. Once identified, you can focus on fine-tuning specific layers or training on additional data to resolve these problems.
Implementing Continuous Feedback Loops
Continuous feedback loops help not just notice issues but also prevent them from reoccurring in the future. With them, you can automatically retrain or fine-tune your model based on real-time performance data. As such, your model remains effective even as it encounters new data patterns or inputs.
Enhancing LLM Performance Through Observability

Observability LLM is that mechanism that helps us act proactively, enhancing a model's performance. With it, you refine your model continuously in different aspects of performance, with targeted improvements based on observability insights.
Active Learning and Data Annotation
Observability data can inform active learning strategies, where the model identifies difficult or misclassified examples and prioritizes them for human data annotation. This leads to more efficient training cycles and improves model accuracy in the areas where it struggles most.
By focusing on the weak points identified through observability, you can fine-tune your model’s dataset to address those gaps, resulting in better generalization and robustness.
Layer-Specific Fine-Tuning
With LLM observability, we can avoid retraining the entire model. This takes much time and resources. Instead, you can fine-tune specific layers that show the most performance degradation. This way, you adjust a model's performance in the areas where it’s needed most.
Boost your model’s performance with high-quality, domain-specific data annotation. Let our experts enhance your training data for superior results!
Best Practices for LLM Observability
To maintain effective observability, certain best practices should be followed. These practices ensure your system remains scalable, accurate, and easy to manage.
Data Retention and Management
Deciding how long to retain logs, traces, and metrics is critical for effective analysis. Retaining data over long periods allows you to identify trends and track performance drift, but too much data can overwhelm your system.
Cross-Team Collaboration
Observability is not just an ML responsibility. By fostering collaboration between data engineers, DevOps, and product teams, you can build a shared understanding of model performance, helping everyone stay aligned and informed.
Effective observability in LLMs ensures your models stay performant, accurate, and fair in real-world applications. By focusing on the right metrics, LLM observability tools, and processes, you can not only monitor model behavior but continuously improve it, leading to better outcomes for your business and users alike.
Ensure your LLMs are precise and reliable with our advanced LLM fine-tuning services. Let us help you monitor and optimize your models for peak performance!
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Check our performance based on a free trial
Pay per labeled object or per annotation hour
Working with every annotation tool, even your custom tools
Work with a data-certified vendor: PCI DSS Level 1, ISO:2700, GDPR, CCPA
FAQ
What is the difference between LLM monitoring and observability?
LLM observability provides a deep, holistic view of a model's internal workings, enabling you to understand and trace how decisions are made. Monitoring focuses on tracking specific metrics like latency and accuracy, without necessarily offering insight into the root causes of issues.
What are the pillars of LLM observability?
The pillars of LLM observability are logs, metrics, and traces. Logs capture real-time data on model behavior, metrics track performance indicators like accuracy and resource usage, and traces follow requests through the model, helping to identify and diagnose issues across different layers.
What is LLM in generative AI?
In generative AI, an LLM (Large Language Model) is a type of model trained on vast amounts of text data to generate human-like language responses. It can understand, predict, and produce text, making it useful for tasks like content creation, translation, and conversational AI.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.