LLM Parameters: Key Factors for Model Optimization

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- LLM parameters control output creativity, accuracy, length, and structure.
- Temperature and Top-P balance creativity and coherence by controlling token randomness and diversity.
- Max tokens and context window define output length and improve coherence over long texts or conversations.
- Penalties (frequency & presence) reduce repetition and introduce novelty in responses.
- Fine-tuning customizes models for specific industries or tasks, enhancing relevance and accuracy.
- Advanced features like prompt caching and JSON mode boost efficiency and ensure structured outputs.
- Optimization strategies combine parameters thoughtfully and use AutoML or APIs for efficient tuning and real-time adjustments.
What are LLM Parameters?
LLM parameters are settings you can adjust to control how a Large Language Model (LLM) works.
But what are parameters in LLM, exactly? They influence how the model processes input and generates output. By tweaking these settings, often guided by insights from data annotation services, you can make the model create responses that meet specific goals. Whether you need concise summaries, creative ideas, or structured data, adjusting parameters in LLM helps you get the results you want.
Key LLM Parameters for Fine-Tuning LLMs
LLM fine-tuning is the process of training pre-existing large language models on domain-specific datasets. With fine-tuning LLM model parameters, each parameter shapes how the model behaves, allowing you to tailor its responses to your needs.
Temperature: Steering Creativity
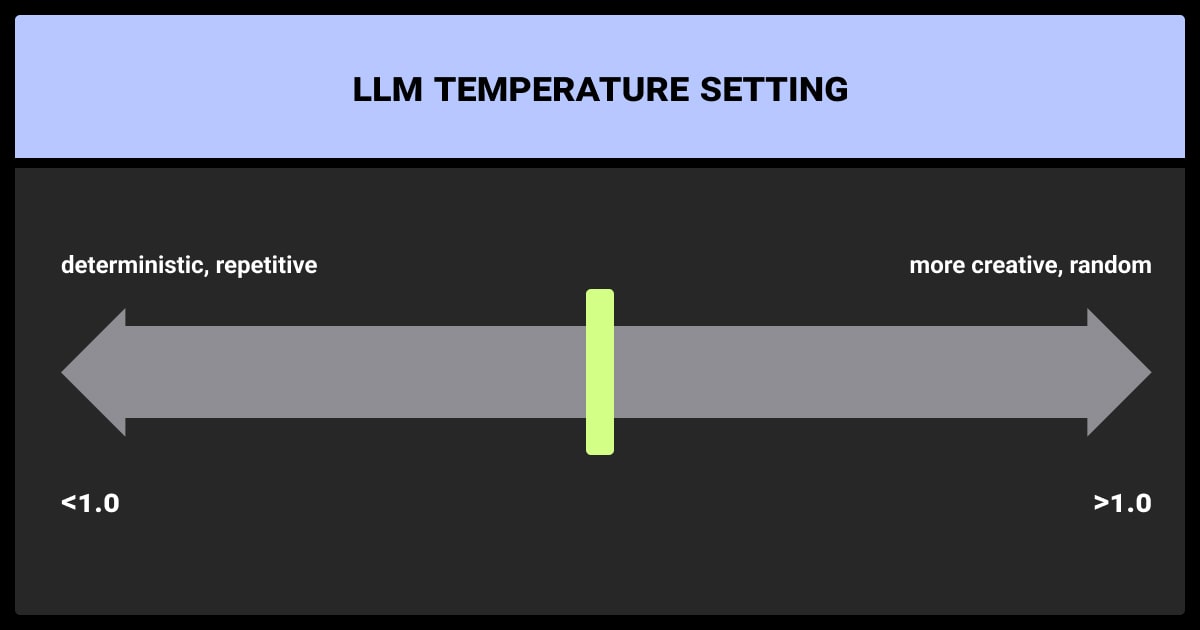
Temperature controls how creative or predictable the model’s responses are. Low values (like 0.2) make the model stick to safe, logical answers. High values (like 0.8) encourage the model to take risks, leading to imaginative and varied responses.
Use Cases:
- Low Temperature: Use this for creating factual content like manuals or legal documents.
- High Temperature: Best for creative tasks like brainstorming or marketing copy.
A balanced temperature setting can also work wonders in tasks where you need a mix of coherence and creativity.
Top-P: Fine-Tuning Diversity
Top-P sampling narrows or widens the range of words the model considers, offering a more nuanced approach than temperature. It allows you to define how diverse or focused the responses should be. A low value (e.g., 0.1) limits the model to the most likely words, ensuring reliable and focused responses. A higher value (e.g., 0.9) expands the range, used primarily for various creative outputs.
Use Cases:
- Low Top-P: Good for tasks like technical reports or precise Q&A responses.
- High Top-P: Ideal for generating unique ideas or creative text.
Number of Tokens: Controlling Length
Number of tokens, or max tokens sets a limit on the length of the output. Understanding tokens, parameters, LLM settings together is crucial to get the desired outputs carved for particular requests. Short limits are great for concise responses, while higher limits allow for detailed explanations or narratives.
Use Cases:
- Low Max Tokens: Ideal for generating one-sentence summaries, concise email drafts, or short-form responses.
- High Max Tokens: Perfect for writing long-form articles, whitepapers, or detailed instructional guides.
| Max Tokens Setting | Task | Output Style |
| 50 | Summarizing a news article | Brief and focused |
| 150 | Explaining a technical concept | Detailed and illustrative |
| 500 | Writing a research paper section | Comprehensive and thorough |
Adjusting tokens allows you to strike a balance between verbosity and clarity, ensuring the output is fit for purpose.
Frequency Penalty: Fighting Repetition
This parameter reduces how often the model repeats the same words or phrases. By applying a frequency penalty, you can make the text more engaging and varied. Lower penalties are better for tasks where repetition adds clarity, like step-by-step guides.
Use Cases:
- High Frequency Penalty: Useful in poetry, blog writing, or storytelling, where varied vocabulary enhances reader interest.
- Low Frequency Penalty: Great for structured guides and FAQs, where repetition aids understanding.
The balance here depends on context. A high penalty is great for creative applications, while a lower one works better for structured, repetitive tasks like procedural documentation.
Presence Penalty: Encouraging Novelty
Presence penalty pushes the model to introduce new words and ideas. It’s useful for brainstorming sessions or creative tasks. High-quality data annotation helps here to prepare data for further LLM model accurate performance. Low values allow the model to stick to the same ideas, which is better for tasks needing consistency.
Use Cases:
- High Presence Penalty: Ideal for generating fresh ideas during product ideation sessions or creating novel artistic content.
- Low Presence Penalty: Useful for customer queries needing continuity.
Presence penalty helps strike the right balance between maintaining coherence and introducing novelty, making it a versatile tool in a wide range of applications.
Fine-tuning on domain-specific datasets significantly enhances performance for specialized tasks. Combining this with retrieval-augmented generation (RAG), it integrates real-time knowledge, making outputs more accurate and contextually relevant.

 Growth, Wanderboat
Growth, Wanderboat
Advanced LLM Parameters for Precision Tasks
When exploring advanced features, understanding which LLM has the most parameters can provide insight into their capabilities. Advanced settings to set up LLMs’ environment and context unlock new ways to optimize LLM performance.
Prompt Caching: Boosting Efficiency
Prompt caching saves processed prompts and outputs. The model becomes faster and provides better results for tasks with repetitive queries. This parameter is applicable in high-traffic environments, which requires a model's speed.
Use Cases: Chatbots handling repetitive customer queries, automated FAQ systems, or product recommendation engines.
Seed: Ensuring Consistency
Seed fixes the randomness in outputs. This ensures the model gives similar answer for the same type of input on every request. It’s ideal for testing and debugging or creating standardized documents.
Use Cases: Quality assurance for AI applications, standardized legal documents, or testing new prompts.
LLM Streaming: Real-Time Responsiveness
Streaming lets the model generate output one token at a time, so users see responses forming in real time. This feature is particularly useful in live applications, such as automatic speech recognition systems, live chat interfaces, or voice assistants.
Use Cases: Live chat systems, voice-controlled AI assistants, or interactive teaching tools.
Context Window: Improving Long-Form Coherence
Context window size determines how much prior text the model can consider when generating responses. Expanding this size allows the model to remain coherent over longer discussions and materials. For example, in fields like geospatial annotation, larger context windows enable the model to accurately process and correlate complex spatial datasets, improving analytical outputs.
Use Cases: Summarizing long research papers, analyzing legal documents, or providing detailed and context-aware customer support.
Expanding the context window size, like increasing it from 512 to 2048 tokens, dramatically improves the model's ability to maintain coherence in longer conversations. Efficient attention mechanisms help balance resource usage with performance gains.
 Developer, TROYPOINT
Developer, TROYPOINT
JSON Mode: Ensuring Structured Outputs
For tasks needing structured data, JSON Mode makes sure the model outputs text in machine-readable formats. Partnering with a data annotation company can help streamline the preparation of structured datasets, ensuring compatibility with JSON outputs.
Use Cases: Automated data entry workflows, API responses, or generating reports that feed directly into databases.
Function Calling: Extending Capabilities
Function calling allows the model to interact with external tools or APIs. It can fetch real-time data, perform calculations, or integrate with other systems.
Use Cases: Weather updates, inventory management systems, or integrating LLMs with business intelligence platforms.
Logprobs: Gaining Insights
Logprobs shows the likelihood of each word the model generates. This helps in debugging and refining outputs, especially for critical tasks like legal or medical content. Applications like image recognition can also benefit from analyzing token probabilities to refine outputs in descriptive tasks.
Use Cases: Analyzing confidence levels in generated text, refining model outputs for high-stakes applications, or debugging unexpected responses.
How to Apply LLM Parameters in Real-World Scenarios

Fine-tuning parameters of an LLM do not have a one-size-fits-all approach. You need to combine the right parameters for the task at hand.
Combining LLM Parameters for Better Results
Combining multiple parameters allows for nuanced control of the model’s behavior, enabling it to deliver outputs that meet precise requirements. However, finding the right balance between parameters can be challenging. Here are some key considerations when combining settings to optimize performance.
Balancing Creativity and Coherence
Pairing a high Temperature with a moderate Top-P encourages diverse and imaginative outputs while maintaining enough focus to avoid nonsensical results. This combination is useful when you want variety but still need a coherent structure.
Preventing Repetition While Retaining Clarity
Using a moderate Frequency Penalty alongside a low Presence Penalty ensures that the model avoids repetitive phrases without completely steering away from key topics. This balance helps maintain relevance and fluency in the text.
Optimizing for Length and Depth
High Max Tokens combined with low Temperature ensures that the model generates detailed and logical responses without unnecessary creative flourishes. This is particularly effective for producing technical or in-depth content.
Avoiding Common Pitfalls
While parameter adjustments offer immense flexibility, they can lead to challenges if not used carefully. Here are some common pitfalls and how to avoid them:
Over-Tuning
Adjusting parameters excessively can make the model rigid, limiting its ability to generalize. Always test outputs across various prompts to ensure adaptability. Strike a balance by starting with moderate adjustments and fine-tuning incrementally to avoid overfitting the model to specific tasks.
Ignoring Task Context
Misaligned settings can result in suboptimal results. For example, high creativity settings (high Temperature and Top-P) are inappropriate for applications requiring factual accuracy. Always align parameter adjustments with the primary goals of the task to ensure relevance and usability of outputs.
Neglecting Output Testing
Regularly evaluate outputs to ensure they meet quality and relevance standards. Combine manual review with automated checks where possible. Use diverse test prompts to uncover inconsistencies and refine parameters accordingly for broader applicability.
Automating LLM Parameters Optimization
Fine-tuning parameters manually can be labor-intensive, especially in enterprise environments with diverse tasks. Automation tools and techniques streamline this process, ensuring efficiency without compromising quality.
Leveraging AutoML for Parameter Tuning
AutoML (Automated Machine Learning) is a game-changer for LLM parameter optimization. It automates the trial-and-error process by systematically testing various parameter combinations and identifying the most effective settings. AutoML algorithms analyze performance metrics like output coherence, diversity, and relevance to select optimal configurations.
Benefit:
- AutoML reduces manual experimentation, ensures consistent parameter settings, and scales easily across workflows.
Learning rate acts like the throttle for model training. Gradually lowering it over time strikes a balance, allowing the model to capture broad trends early and refine its understanding later. Similarly, a moderate batch size captures subtle data patterns while keeping training efficient.
 Co-Founder, AI Insider Tips
Co-Founder, AI Insider Tips
Dynamic Parameter Adjustments via APIs
Modern LLM platforms allow developers to adjust parameters dynamically through APIs. This flexibility ensures that the model can adapt to changing requirements in real time.
Benefit:
- Lowering Temperature for a technical query ensures concise and factual responses.
Pre-Configured Parameter Training
Many platforms offer pre-configured training or templates for parameter tuning. These templates are designed for common use cases, making it easier to get started.
Benefits:
- Speeds up deployment by eliminating the need for in-depth parameter knowledge upfront.
- Provides a starting point for fine-tuning, allowing users to build on pre-optimized configurations.
Monitoring and Feedback Loops
Optimization doesn’t stop with initial tuning. Regularly monitor outputs and use feedback to refine settings. Combine automated evaluations with manual reviews for the best results.
- Output Evaluation: Use metrics like accuracy, coherence, and creativity to assess performance.
- Iterative Refinement: Regularly update parameter configurations based on performance data.
Human Oversight: Pair automated systems with manual review to catch nuances that algorithms may miss.
About Label Your Data
If you need help with LLM fine-tuning task, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the parameter in LLM?
A parameter in LLMs is a numerical value that guides how the model processes and understands data. These values are fine-tuned during training to improve predictions and language comprehension.
What are tokens and parameters in LLM?
Tokens are the text's building blocks, such as words or subwords, while parameters are numerical values defining how the model processes these tokens. Together, they enable LLMs to generate coherent and context-aware responses.
How many parameters does LLM have?
LLMs can have millions to billions of parameters, depending on their size and design. For instance, GPT-3, which has some of the largest LLM parameters, boasts 175 billion, making it highly capable of handling complex language tasks.
What do 7 billion parameters mean in LLM?
A 7-billion-parameter LLM has 7 billion trained values that help it understand patterns and context in text. It offers a balance between performance and computational efficiency for various NLP tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.