LLM Reinforcement Learning: Improving Model Accuracy

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- LLM reinforcement learning (RL) improves accuracy and adaptability using feedback-driven training.
- RL enables dynamic learning, user alignment, and scalability in evolving environments.
- It’s ideal for tasks like conversational AI, domain-specific models, and generative AI.
- Key challenges include computational costs, feedback scalability, and reward design.
- Best practices involve using pre-trained models, clear rewards, scalable feedback, and robust evaluations.
What is Reinforcement Learning?
Reinforcement learning (RL) is a learning method where a system, called an agent, learns by trying different actions in a given situation.
It does so by receiving feedback on how good or bad those actions are. Unlike in supervised learning, which relies on LLM data labeling, in RL the agent defines what works best over time. It aims to maximize rewards for its actions.
Core Components of LLM Reinforcement Learning
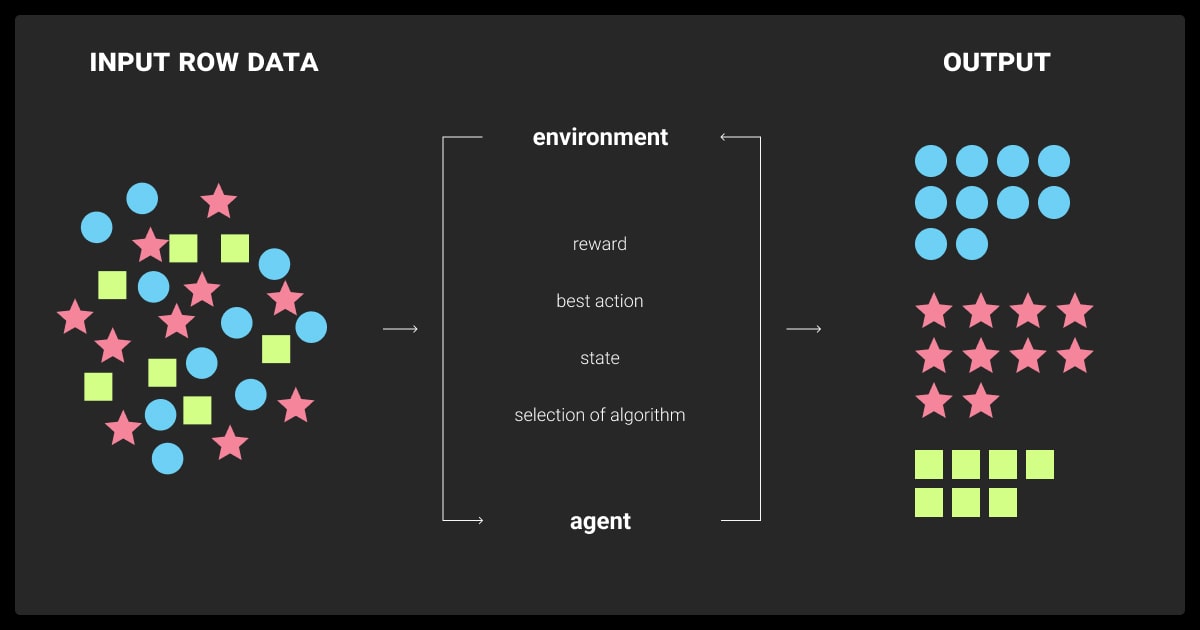
In its nature, reinforcement learning operates on a feedback loop between the agent and the environment. The agent plays a central role by making decisions. It receives feedback in the form of rewards or penalties and fine-tunes its strategy to achieve better results over time.
This iterative process allows models (e.g. large language models) to dynamically learn and adapt to complex tasks. The main components of the reinforcement learning include:
- Agent. The decision-maker (e.g., an LLM selecting the next token in a sequence).
- Environment. The context or framework in which the agent operates (e.g., a dialogue system).
- Actions. Choices available to the agent (e.g., generating different tokens).
- States. Current environment, informing the agent’s decisions.
- Rewards. Feedback signals indicating the quality of an action (e.g., alignment with user intent).
Popular LLM Reinforcement Learning Algorithms
The choice of reinforcement learning algorithms plays a significant role in how effectively a model learns from its environment. These algorithms differ in how they approach decision-making, policy optimization, and learning from rewards.
Below are top RL techniques used for LLM training:
- Q-Learning. Focuses on estimating the value of actions in discrete state spaces.
- Policy Gradient Methods. Directly optimize policies using gradients for better decision-making.
- Proximal Policy Optimization (PPO). Balances exploration and stability for training complex models.
Why Reinforcement Learning Matters for LLMs
Reinforcement learning provides unique benefits for large language models, addressing key challenges that traditional training methods often struggle to resolve. Its importance lies in the following capabilities:
- Dynamic Learning. Allows LLMs to refine their outputs through iterative interactions.
- Alignment with Goals. Customizes model behavior to prioritize fluency, accuracy, and user preferences.
- Scalability. Adapts to evolving datasets and diverse real-world contexts.
Reinforcement learning (RL) can significantly improve the accuracy and reliability of large language models (LLMs) by enabling them to learn from feedback and adapt over time. This approach is particularly effective for improving model performance in complex applications where traditional supervised learning may fall short.

 CEO, Cyber Chief
CEO, Cyber Chief
Difference Between Supervised and Reinforcement Learning

| Feature | Supervised Learning | Reinforcement Learning |
| Data Requirement | Requires labeled datasets | Learns dynamically from feedback |
| Focus | Static pattern recognition | Dynamic decision-making |
| Adaptability | Limited to training data | Adapts to changing environments |
| Feedback Mechanism | Predefined labels | Rewards based on interactions |
Core Concepts of LLM Reinforcement Learning
Reinforcement learning introduces unique concepts that are particularly suited for optimizing large language models. These concepts revolve around creating a feedback loop that refines the model's decision-making process to align with desired outcomes.
Reward Functions and Their Design
The reward function is a fundamental component of reinforcement learning, steering the agent (LLM) toward achieving desirable behavior. In the context of LLMs:
- Positive Rewards. Given for desired outcomes, such as generating accurate, coherent, and contextually appropriate responses.
- Negative Rewards (Penalties). Applied for undesirable actions, such as producing offensive or nonsensical outputs.
Challenges in Reward Design
- Ambiguity: Complex tasks often require balancing multiple objectives like fluency, accuracy, and ethical considerations.
- Overfitting to Rewards: Poorly designed rewards may lead to outputs that satisfy the function but fail in real-world scenarios.
Example: In a conversational AI system, the reward function might prioritize politeness and relevance, but if not balanced, it could ignore creativity or adaptability.
Policy Optimization Techniques
Policies determine how the agent selects actions. For LLMs, this translates to choosing tokens or phrases during generation.
- Stochastic Policies: Introduce randomness in actions to encourage exploration.
- Deterministic Policies: Focus on reliably choosing the most likely optimal action.
- Proximal Policy Optimization (PPO): A commonly used technique for training LLMs, PPO ensures the model explores diverse responses while avoiding radical shifts that destabilize training.
Exploration vs. Exploitation
Finding the right balance between exploring new possibilities and leveraging proven strategies is essential for effectively training LLMs.
- Exploration: Encourages the model to generate diverse, creative outputs.
Example: Testing uncommon phrases in dialogue generation. - Exploitation: Reinforces reliable, high-performing outputs.
Example: Reusing patterns proven to align with user expectations.
Techniques like entropy regularization are used to manage this balance, ensuring the model doesn’t become overly conservative or unpredictable.
RL encourages models to explore various response strategies while leveraging what they've learned. This flexibility generates diverse, high-quality answers and enhances trustworthiness by teaching models to admit uncertainty when unsure, such as saying 'I don’t know' instead of fabricating answers.

Role of Feedback Mechanisms
Feedback is integral to RL, shaping the reward function and optimizing the policy. In LLM training:
- Human Feedback: Provides high-quality insights, but is costly and difficult to scale.
- Synthetic Feedback: Uses predefined metrics or automated systems to evaluate outputs, offering scalability at the cost of precision.
When to Use Reinforcement Learning in LLMs
Reinforcement learning is not always the default choice for training LLMs, but it excels in scenarios where traditional supervised learning falls short. By focusing on dynamic, feedback-driven optimization, RL proves invaluable in addressing specific challenges and requirements.
Complex Task Requirements
- Ideal for tasks requiring multistep reasoning or decision-making.
- Works well for generating outputs where multiple variables impact the result, such as logical problem-solving or strategy games.
User Alignment and Adaptability
- Helps align LLM outputs with user preferences through reward modeling.
- Ensures personalized responses in applications like conversational AI and customer service.
Dynamic Environments
- Suited for situations where the environment evolves over time.
- Includes applications like real-time data processing or adapting to changing user needs.
Multi-Objective Optimization
- RL can balance conflicting goals such as accuracy, efficiency, and fairness.
- By designing multi-objective reward functions, LLMs can prioritize multiple outcomes simultaneously.
Supervised vs. Reinforcement Learning in Task Suitability
| Scenario | Supervised Learning | Reinforcement Learning |
| Static datasets | ✔️ | ❌ |
| Real-time adaptation | ❌ | ✔️ |
| Multi-step reasoning tasks | Limited | ✔️ |
| Personalized user interactions | Partially effective | ✔️ |
Key Challenges in LLM Reinforcement Learning
While reinforcement learning offers significant advantages, implementing it for large language models comes with unique challenges. These issues should be addressed for effective LLM training.
Computational Complexity
Training RL-enhanced LLMs is resource-intensive due to the size and complexity of modern models.
- RL training for LLMs requires substantial computational resources, especially for large-scale models.
- High costs of computation limit experimentation and scalability.
Solution: Use distributed RL frameworks and cloud-based platforms to optimize resource utilization.
Reward Design Issues
Designing effective reward functions is critical but often difficult, as it requires a precise balance between multiple competing objectives.
- Poorly designed rewards can lead to undesirable behaviors or overfitting.
- Accurate reward models that align with real-world goals rely heavily on high-quality data annotation.
- Ambiguity in defining success criteria complicates reward engineering.
Solution: Leverage multi-objective rewards that balance diverse goals such as accuracy, creativity, and fairness.
Scalability of Feedback
Feedback is essential for reinforcement learning LLM training, but scaling this feedback — especially when it involves human evaluators — presents significant hurdles.
- Collecting high-quality human feedback at scale is costly and time-intensive.
- Collaborating with a trustworthy data annotation company can simplify the process and provide consistent, high-quality feedback essential for training models effectively.
- Over-reliance on human evaluators may create bottlenecks in training.
Solution: Use synthetic feedback or automated evaluation metrics alongside human-in-the-loop processes.
Performance Evaluation
Evaluating RL-enhanced LLMs requires metrics that go beyond standard measures, capturing both technical and contextual performance.
- Standard metrics may not fully capture RL model performance.
- Evaluating contextual relevance and user satisfaction is complex.
Solution: Develop task-specific evaluation frameworks that combine quantitative and qualitative metrics.
Top Use Cases for Reinforcement Learning in LLMs
Reinforcement learning is particularly effective in specific use cases where traditional methods may fall short. These scenarios highlight RL's ability to enhance adaptability, personalization, and decision-making in LLMs.
Conversational AI
Conversational systems often require real-time adaptability and alignment with user expectations, making RL an ideal approach.
- Enhances context awareness, ensuring responses are relevant and coherent.
- Optimizes user satisfaction by balancing politeness, engagement, and precision.
Example: ChatGPT, trained using RLHF (LLM Reinforcement Learning from Human Feedback), shows significant improvements in producing user-aligned conversational outputs.
Domain-Specific Models
Specialized industries, such as medicine, law, and finance, demand precise, reliable outputs. RL allows LLMs to excel in these high-stakes environments.
- Ensures the model adheres to strict domain-specific guidelines.
- Enables optimization for both accuracy and interpretability.
- Fields like geospatial annotation can leverage RL to improve the precision of location-based data processing and analysis.
Example: Legal document review systems use RL to prioritize compliance and clarity in generated summaries.
Reinforcement learning has helped our insurance-focused LLMs learn from agent-client interactions to provide more accurate policy explanations. By creating a feedback loop based on successful claim processing outcomes, we significantly reduced misinterpretations and improved client satisfaction rates.
 Founder, Strawberry Antler
Founder, Strawberry Antler
Generative AI and Creative Tasks
For tasks that require creativity, such as storytelling or artistic content generation, RL fosters innovation and adaptability.
- Helps maintain coherence while encouraging unique and creative responses.
- Supports fine-tuning tone, style, and complexity based on task-specific needs.
- Enhances capabilities in areas like image recognition, enabling models to interpret and generate visuals in alignment with creative requirements.
Example: Generative AI applications like narrative-building tools benefit from RL’s capacity to refine stylistic preferences.
Complex Interactive Systems
Systems that involve dynamic interactions with users or other models greatly benefit from RL.
- Facilitates decision-making in environments where outputs must adapt in real time.
- Enables multi-agent coordination in scenarios like collaborative AI or advanced simulations.
- Applications such as automatic speech recognition systems can use RL to enhance adaptability, improving accuracy in diverse and evolving acoustic environments.
Example: AI-powered customer service platforms use RL to improve user query resolution rates while managing response time efficiency.
Strategies for Implementing LLM Reinforcement Learning
Successfully incorporating reinforcement learning LLM into large language models requires a strategic approach. By following best practices, ML teams can maximize RL's benefits while mitigating its challenges.
Start with Pre-Trained Models
Leveraging pre-trained models significantly reduces computational costs and time.
- Use foundational models as a starting point for reinforcement learning optimization.
- Combine reinforcement learning with LLM fine tuning to address specific application needs and improve performance in targeted tasks.
Example: Applying RLHF on pre-trained LLMs like GPT to refine conversational alignment.
Design Effective Reward Functions
Reward functions are critical for guiding LLM behavior and ensuring outputs align with desired goals.
- Define clear, measurable criteria for success to minimize ambiguity.
- Use multi-objective rewards to balance competing priorities like accuracy and fairness.
Regularly validate reward functions to avoid unintended biases.
Incorporate Scalable Feedback Mechanisms
Efficient feedback collection ensures models improve without resource bottlenecks.
- Combine human feedback with automated evaluation systems for scalability.
- Employ synthetic feedback methods to complement human-in-the-loop processes.
- Leverage high-quality data annotation services to enhance the accuracy and consistency of feedback for model training.
Example: Using pre-trained evaluative models to simulate feedback in large-scale training.
Optimize Training Efficiency
Training RL-enhanced LLMs requires managing computational demands effectively.
- Utilize distributed RL frameworks and parallel processing to reduce training time.
- Implement techniques like gradient clipping and early stopping to avoid overtraining.
Robust Evaluation Frameworks
A comprehensive evaluation framework ensures RL-enhanced LLMs perform as expected in real-world applications.
- Develop task-specific metrics that measure both technical accuracy and contextual relevance.
- Include user satisfaction as a qualitative performance indicator.
- Regularly test models on edge cases to identify potential gaps in training.
Reinforcement learning has become a vital tool for enhancing large language models. It addresses challenges in accuracy, adaptability, and alignment with user needs. By leveraging RL’s dynamic feedback-driven approach, LLMs can excel in complex tasks. They can deliver more in personalized interactions and dynamic environments.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is reinforcement learning in LLM?
Reinforcement learning in LLMs is a training approach where the model improves by engaging with its environment and adjusting based on rewards or penalties it receives as feedback. This helps optimize the model's behavior, such as generating coherent and user-aligned outputs.
What is the feedback loop of an LLM?
The feedback loop in an LLM involves generating outputs, evaluating them based on predefined criteria or user feedback, and adjusting the model’s parameters to improve future responses. It’s an iterative process that refines performance over time.
What is Markov decision process in LLM?
A Markov Decision Process (MDP) in LLMs frames the learning problem as a sequence of decisions. Each decision depends only on the current state (not the past history), and the goal is to maximize cumulative rewards by selecting optimal actions at each step.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.