SLM vs LLM: How to Pick the Right Model Size

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- SLMs in the 1-15B range can run on a single GPU or CPU, deliver sub-second responses, and rival older LLMs when fine-tuned on domain-specific data.
- LLMs above 100B parameters dominate reasoning benchmarks, handle longer context windows, and remain the best option for open-ended generation.
- Accuracy does not scale linearly with size; SLMs often match LLMs on structured or narrow tasks, while LLMs consistently outperform on complex reasoning.
- Latency shapes user experience, with SLMs serving tokens in tens of milliseconds compared to hundreds of milliseconds or more for cloud-hosted LLMs.
- Training frontier LLMs costs more than $100M and inference pricing grows steeply at scale, while SLMs reduce cost-per-million queries by over 100x.
Explaining SLM vs LLM in Real ML Projects
Small language models (SLMs) and large language models (LLMs) differ mainly in scale, training scope, and deployment demands, making the SLM vs LLM trade-off central to accuracy, latency, and cost.
SLMs typically range from 1 to 15 billion parameters, while LLMs stretch into the hundreds of billions and even approach the trillion-parameter scale. This size gap drives trade-offs in accuracy, latency, and cost.
Different types of LLMs, from balanced mid-sized models to frontier systems with hundreds of billions of parameters, vary widely in how they trade accuracy for latency and cost.
In practice:
- SLMs deliver agility, faster iteration, and deployment flexibility
- LLMs provide unmatched performance on open-ended, high-variance tasks
SLMs, such as Microsoft’s Phi-3-mini (3.8B) or Mistral 7B, are designed for efficiency. They can run on a single GPU or edge devices and still match or outperform older LLMs on common NLP benchmarks. Their smaller size makes them easier to fine-tune on domain-specific datasets, giving ML teams control and lower operational overhead.
LLMs like GPT-4 and Gemini Ultra are trained on massive datasets spanning trillions of tokens. They excel at broad generalization, multistep reasoning, and complex prompts. These models usually run in the cloud because they require specialized GPU/TPU clusters. Training alone can exceed $100M, and inference costs remain high due to energy and hardware demand.
If you’re weighing LLM vs SLM for your project, this breakdown shows where SLMs hold up and where LLMs lead.
Key Differences Between Small and Large Language Models
While LLMs dominate in raw accuracy and reasoning, SLMs often win on speed, control, and cost. Bigger isn’t always better, and choosing the right model between AI LLM vs SLM depends on workload and constraints.
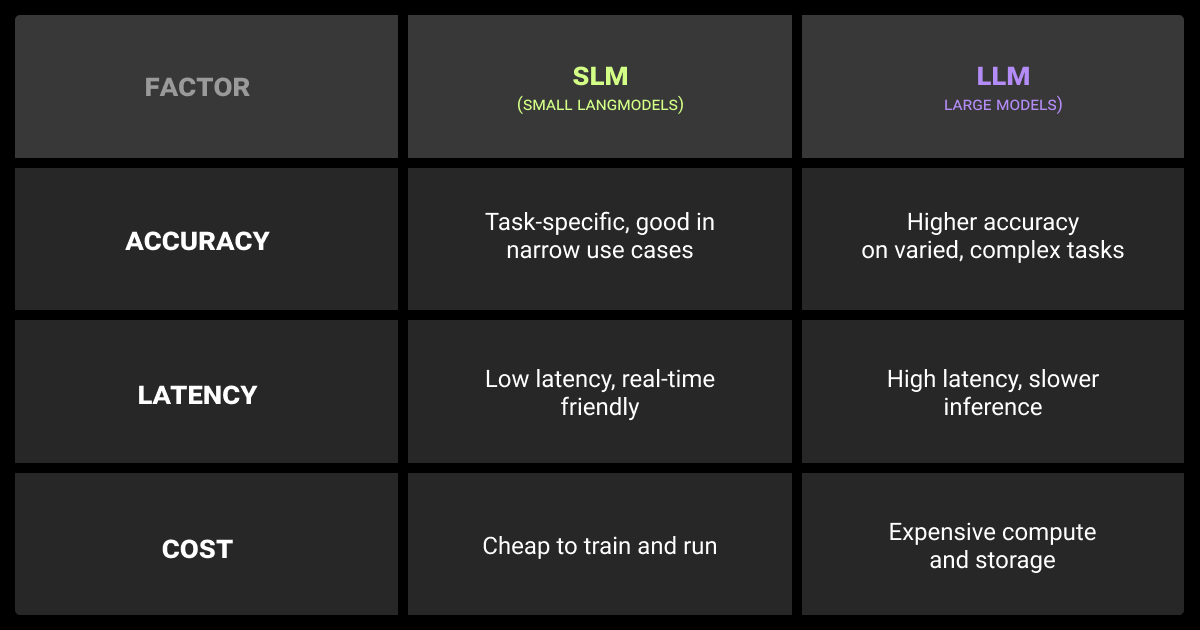
| Factor | SLM (Small Language Models) | LLM (Large Language Models) |
| Model Scale | ~1–15B parameters (e.g., Phi-3-mini, Mistral 7B) | 100B–1T+ parameters (e.g., GPT-4, Gemini Ultra) |
| Training Data | Narrower scope, curated for efficiency | Trillions of tokens across diverse domains |
| Deployment | Runs on single GPU, CPU, or edge devices | Requires multi-GPU/TPU clustersCloud-based APIs |
| Speed/Latency | Low latencyHigh TPSReal-time feasible | Higher latencySlower inference under load |
| Cost | Training <$10MLower inference costs | Training >$100MInference costly at scale |
| Control | Easier to fine-tuneSuitable for on-prem solutions | Stronger out-of-the-box, but often API-dependent |
Practical SLM vs LLM examples include Phi-3 Mini for lightweight chatbots versus GPT-4 for multistep reasoning.
Model scale and training data
SLMs operate in the billions of parameters, focusing on curated data to achieve efficiency. LLMs scale up to hundreds of billions, leveraging massive, diverse datasets for generalization and complex reasoning.
Deployment and control
SLMs can run on-premise or on-device, giving ML teams more control over data governance and costs. LLMs usually require cloud deployment and API access, which increases reliance on external providers but delivers cutting-edge capability.
Accuracy Trade-Offs in LLM vs SLM
Accuracy is the main reason teams reach for LLMs, but context matters. Benchmarks show that while LLMs dominate in open-ended reasoning, SLMs can match or even surpass them on well-defined, domain-specific tasks when fine-tuned. The trade-off in SLM vs LLM AI is between generalization and specialization.
Where LLMs lead
LLMs like GPT-4, Claude, and Gemini Ultra outperform smaller models on tasks requiring multistep reasoning, broad domain knowledge, or long-context understanding. They excel at zero-shot and few-shot scenarios, where minimal task-specific data is available. LLMs also show stronger resistance to distribution shifts, though hallucinations remain a concern in open-ended generation.
As one AI security leader puts it:
SLMs are perfect for chatbots, document processing, or real-time applications where speed is required, or even milliseconds matter. Moreover, SLMs cost less than LLMs and run locally, enhancing privacy. However, if accuracy and broad knowledge is required, pick LLMs. The sweet spot is using both: route simple tasks to SLMs and complex ones to LLMs.

 AI Security Advocate | Chief Marketing Officer, Mindgard
AI Security Advocate | Chief Marketing Officer, Mindgard
Where SLMs compete
SLMs such as Phi-3-mini or Mistral 7B can reach near-LLM accuracy when fine-tuned for narrow tasks: classification, structured inputs, or domain-specific Q&A. They often outperform LLMs in efficiency-critical settings because they hallucinate less when the task is tightly bounded and training data is tailored. In applied use cases, like customer support chatbots or document classification, SLMs can deliver production-ready accuracy at a fraction of the cost.
Accuracy benchmarks (LLM vs SLM)
Benchmark scores highlight where small models catch up to larger ones and where size still matters most.
| Model | Type | Parameters | MMLU (%) | HellaSwag (%) | GSM8K (%) | Inference Speed (tok/s) | Latency (ms) | Cost / 1M tokens ($) |
| GPT-4 | LLM | ~1.7T | 86.4 | 95.3 | 92.0 | 15 | 800 | 45.00 |
| GPT-4 Turbo | LLM | ~1.7T | 85.0 | 93.0 | 90.0 | 20 | 750 | 50.00 |
| Phi-3 (3.8B) | SLM | 3.8B | 69.0 | 76.0 | 82.0 | 250 | 80 | 0.30 |
| Mistral 7B | SLM | 7B | 60.1 | 81.0 | 50.0 | 200 | 100 | 0.25 |
| Qwen2-1.5B | SLM | 1.5B | 52.4 | 65.0 | 45.0 | 400 | 50 | 0.15 |
At their core, both SLMs and LLMs are built on the same underlying machine learning algorithm families, but scale and parameter count dictate whether a model generalizes broadly or specializes in narrow tasks.
SLMs can close the gap on structured or domain-specific tasks but still lag on broad reasoning, making them efficient for specialized deployments but less reliable for open-ended inference.
Latency Considerations for SLM vs LLM
Latency is often the deciding factor for production workloads. Research consistently shows that SLMs deliver faster responses and higher throughput, making them better suited for real-time or edge deployments. LLMs, while more accurate, introduce noticeable delays due to their parameter count and hardware requirements.
Scaling in production
Under high load, LLMs suffer from queueing delays and GPU saturation. In benchmarks, SLMs sustain higher tokens per second (TPS), enabling smoother scaling across millions of queries per day. For customer-facing systems like chatbots or search assistants, even a few hundred milliseconds of added latency can degrade user experience and increase drop-off rates.
Edge and on-device use
SLMs dominate scenarios where real-time and offline performance matter, such as mobile assistants, IoT devices, or regulated environments that restrict cloud use. Models like Phi-3-mini and Mistral 7B run efficiently on a single GPU or even CPUs, offering sub-second latency in many setups. LLMs like GPT-4 or Gemini, by contrast, require multi-GPU clusters and cloud APIs, which adds network round-trip latency on top of already slower inference.
Latency ties directly to reliability, user satisfaction, and the ability to serve workloads at scale. For enterprise AI teams, this often shifts the balance toward smaller models when real-time interactions are mission-critical.
Latency in common SLM vs LLM use cases
Latency benchmarks reveal which workloads can tolerate large models and which demand smaller ones for real-time performance.
| Use Case | SLM Latency (ms) | LLM Latency (ms) | SLM Fit | LLM Fit |
| Real-time Chatbot | 50 | 800 | Excellent | Poor |
| Content Generation | 100 | 1200 | Good | Acceptable |
| Code Completion | 80 | 900 | Excellent | Poor |
| Document Analysis | 120 | 1500 | Good | Acceptable |
| Edge IoT Device | 30 | Not feasible | Only Option | Not Feasible |
The numbers confirm that SLMs dominate latency-sensitive tasks, while LLMs only remain viable in workloads where speed is less critical than accuracy.
Cost Trade-Offs in SLM vs LLM
Cost varies widely between SLMs and LLMs, both in training and in inference. The scale of LLMs drives up hardware requirements, energy use, and deployment overhead. SLMs, by contrast, can be trained or fine-tuned affordably and deployed without massive GPU clusters.
Training and fine-tuning costs
Training frontier LLMs requires enormous investment. GPT-4-class models are estimated to exceed $100M in training cost, and Gemini Ultra has been reported around $191M. Even fine-tuning a large model for a new domain can cost tens of thousands of dollars in GPU time. SLMs are far more manageable: teams can fine-tune a 3–7B parameter model for domain-specific tasks at a fraction of that cost, sometimes on a single high-end GPU. This puts customization within reach for enterprises without hyperscaler budgets.
Training both SLMs and LLMs requires curated machine learning datasets. Many teams combine internal pipelines with external data collection services to keep data fresh and reduce bias
Inference costs
LLMs carry high inference costs because of their memory footprint and slower token throughput. Serving millions of queries can mean significant GPU rental expenses and energy bills. SLMs require less memory, deliver more tokens per second, and can often run on commodity hardware. This reduces cost-per-million queries and allows on-prem or edge deployments that keep infrastructure predictable.
Beyond raw spend, hosting SLMs in-house also gives organizations more control over security and privacy. With LLMs, teams often depend on external APIs, which shifts cost into ongoing subscription fees and raises governance concerns.
As one senior AI engineer points out:
A typical business conversation uses 500 to 1000 tokens each way. Process a million conversations monthly and teams face $15,000 to $75,000 bills with large language models, versus $150 to $800 with small language models. Most smart AI teams use hybrid approaches: start with cloud services, then move high-volume, routine tasks to small models, while keeping complex reasoning on LLMs.
 Staff Software Engineer, AI, Big 4 Accounting Firm
Staff Software Engineer, AI, Big 4 Accounting Firm
SLM vs LLM comparison: Enterprise cost factors
Cost modeling shows how quickly large-scale deployments can become unsustainable without smaller models.
| Scenario | GPT-4 Monthly Cost ($) | Mistral 7B Monthly Cost ($) | Savings Ratio | Break-Even |
| Small Business (10K queries/month) | 450 | 2.5 | 180x | Immediate |
| Medium Enterprise (100K queries/month) | 4,500 | 25.0 | 180x | Immediate |
| Large Enterprise (1M queries/month) | 45,000 | 250.0 | 180x | Immediate |
| High-Volume (10M queries/month) | 450,000 | 2,500 | 180x | Immediate |
Enterprises save orders of magnitude on inference by shifting to SLMs, which makes hybrid strategies attractive: deploy LLMs for complex reasoning while routing the bulk of predictable queries to cheaper small models.
Choosing the Right Model for Your ML Project
SLM vs LLM in AI serve different roles in production. LLMs set the performance ceiling, while SLMs give you practical speed and cost efficiency. The right choice depends on task complexity, latency tolerance, and budget, so model selection should be treated as an engineering workflow, not a one-off decision.
Key factors to weigh:
- Task complexity: open-ended reasoning vs narrow domain tasks
- Performance thresholds: acceptable accuracy vs latency trade-offs
- Deployment needs: API dependency vs on-premise or edge deployment
Start with an LLM for feasibility
Use a frontier model like GPT-4 or Gemini to test whether the task is even solvable. This sets a realistic benchmark for performance.
Step down to smaller models for efficiency
Once feasibility is confirmed, test SLMs such as Phi-3-mini or Mistral 7B. Track how much accuracy you lose versus how much latency and cost you save.
Identify the performance threshold
Define the minimum viable accuracy for production. For example, a chatbot might accept a 5% accuracy loss if latency improves 10x, but a medical application cannot.
Optimize with fine-tuning or retrieval
Bridge the gap with retrieval-augmented generation (RAG), prompt tuning, or fine-tuning. These methods often push SLMs close to LLM-level output while keeping efficiency gains.
Choose based on workload fit
Optimal results rarely come from committing to a single model size. Use an LLM first to establish a performance ceiling and identify the reasoning depth required. Then benchmark SLMs to measure efficiency gains against accuracy loss. Define your project’s tolerance for errors, latency, and cost, and use LLM fine tuning or retrieval augmentation to close any remaining gaps.
- SLMs: latency-critical, cost-sensitive, domain-specific tasks
- LLMs: complex reasoning, multi-domain coverage, research-heavy workloads
- Hybrid: cascade workloads (SLMs handle routine queries, LLMs handle the hardest cases)
In production, most reliable pipelines end up hybrid: routing routine or narrow queries through SLMs, while escalating complex reasoning tasks to LLMs. This layered approach gives you reproducibility, predictable cost, and performance that matches the actual demands of your workload.
The cost of deploying large models isn’t just about compute. ML teams also rely on high-quality data annotation, often sourced through a data annotation company or a managed data annotation platform. Factoring in data annotation pricing is as important as token-level inference costs when calculating total spend.
But this hybrid setup only works if the underlying models are tuned to your data and workflows. Off-the-shelf models rarely align with domain specifics, which is why fine-tuning becomes the lever for accuracy and cost control. If your team is weighing SLM vs LLM trade-offs, a targeted fine-tuning service is often the fastest way to balance performance with efficiency.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the advantage of SLM over LLM?
SLMs offer lower latency, smaller hardware requirements, and significantly reduced cost. They’re easier to fine-tune for domain-specific tasks and can be deployed on-premise or at the edge, giving ML teams more control over performance and governance.
What is the difference between SLM and LLM in Azure?
In Azure, LLMs such as GPT-4 are accessed through managed cloud APIs, optimized for high accuracy and general-purpose tasks. SLMs, like Phi-3-mini, can be deployed more flexibly, either via Azure AI services for efficiency or on local infrastructure, making them better suited for applications that prioritize cost, speed, or data privacy.
What is an SLM?
An SLM (small language model) is a language model with a relatively small parameter count, typically under 15 billion. These models are lightweight, faster to run, and easier to fine-tune, making them efficient for targeted use cases and real-time workloads.
What is the difference between small AI model and large AI model?
Small AI models (SLMs) use fewer parameters, require less compute, and are optimized for narrow or domain-specific tasks. Large AI models (LLMs) have hundreds of billions of parameters, are trained on massive datasets, and excel at broad generalization and complex reasoning. While many compare Gemini vs ChatGPT when evaluating frontier LLMs, the real question for ML engineers is how model scale affects accuracy, latency, and total cost in production.
When should ML teams choose SLMs over LLMs?
SLMs are the better choice when applications demand real-time response, strict cost control, or deployment outside the cloud. They are also well-suited for workloads with predictable patterns, such as customer service chatbots, classification tasks, or IoT/edge deployments where hardware resources are limited.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.