Supervised Fine Tuning: Enhancing Your LLM Accuracy

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Supervised Fine-Tuning?
- Key Benefits of Supervised Fine Tuning
- How Supervised Fine-Tuning Works
- Top Techniques for Supervised Fine-Tuning of Large Language Models
- Best Practices for Effective Supervised Fine-Tuning
- Challenges and Solutions in Supervised Fine-Tuning
- About Label Your Data
- FAQ

TL;DR
- What It Is: Supervised fine-tuning adapts pre-trained models to specific tasks using labeled data for improved accuracy.
- Key Benefits: Enhances task-specific accuracy, reduces errors, and improves user experience with domain-specific customization.
- How It Works: Refines model parameters through iterative training with labeled datasets, validation, and optimization.
- Techniques: Includes instruction-based fine-tuning, LoRA, RLHF, and parameter-efficient methods like layer freezing.
- Challenges: Requires high-quality data, significant resources, and careful measures to avoid overfitting and catastrophic forgetting.
What Is Supervised Fine-Tuning?
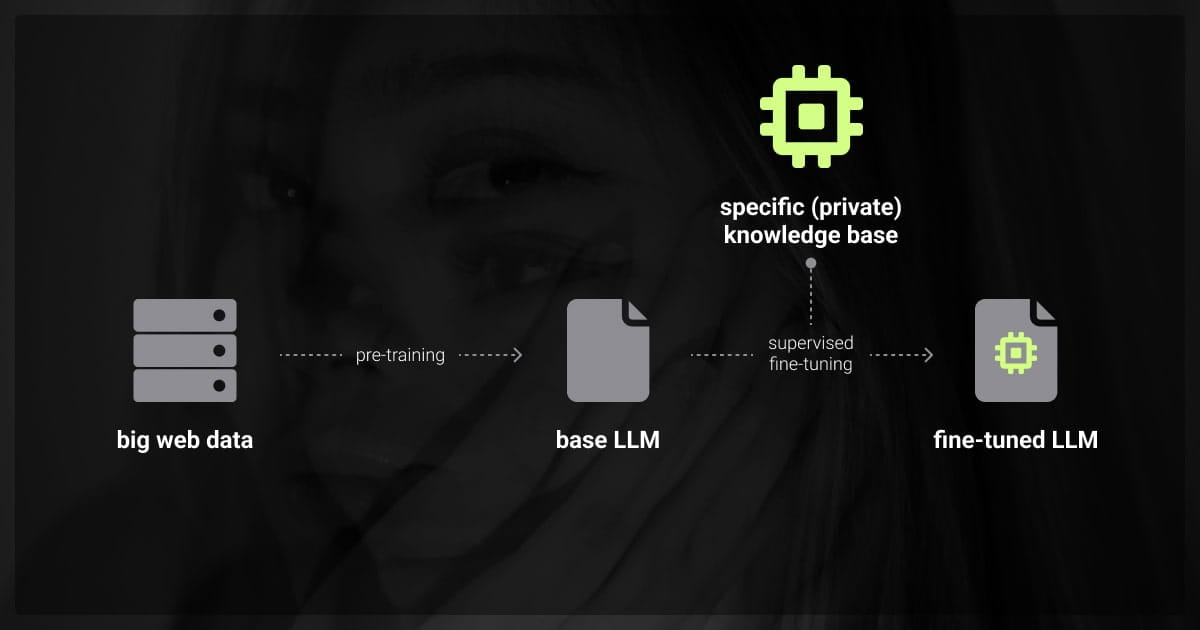
Supervised fine-tuning (SFT) is how you make a pre-trained language model better for a specific task. It uses labeled data to teach the model exactly what to do.
Pre-trained models are good at basic, general tasks. But they often miss the mark for specialized needs. Fine-tuning fixes this by training the model on examples related to the task. This process refines the model’s parameters and helps it perform specific functions more effectively.
For example, if you want a model to summarize legal documents, you train it with labeled legal text using expert data annotation services. This helps the model focus on the most important information.
By curating datasets that are not only large but also relevant to the specific tasks or domains for which the model is being trained, we can significantly enhance its performance.

 CEO, Software House
CEO, Software House
Key Benefits of Supervised Fine Tuning
While pre-trained LLMs possess a broad understanding of language, they may not excel in specialized tasks without further training.
Supervised fine tuning LLM bridges this gap by:
Task-Specific Accuracy
Fine-tuning sharpens the model’s focus on your specific needs. For example, it helps an LLM understand industry-specific terms and processes, whether in healthcare, finance, image recognition or automatic speech recognition. This reduces mistakes and improves relevance.
Enhanced Understanding
A fine-tuned model gains a deeper understanding of your task. It learns to process your unique data and deliver outputs that align closely with your expectations.
Improved User Experience
Supervised fine-tuning results in smoother and more natural interactions with the model. Whether it’s customer service chatbots or internal tools, a tailored model delivers responses that feel human-like and appropriate for the context.
Error Reduction
Fine-tuning minimizes irrelevant or incorrect responses. By training on labeled data, the model learns to avoid common pitfalls, increasing its reliability.
Efficiency Boost
A fine-tuned LLM saves time. It delivers accurate outputs that require little to no manual correction. Such efficiency makes a big difference for workflows that rely on fast, high-quality results.
Scalability
Once fine-tuned, the model can scale to handle similar tasks across different projects or domains. It becomes a reusable asset, saving time and resources for future tasks.
These benefits underscore the value of supervised fine-tuning in optimizing LLMs for specific applications, leading to more accurate, efficient, and user-friendly outcomes.
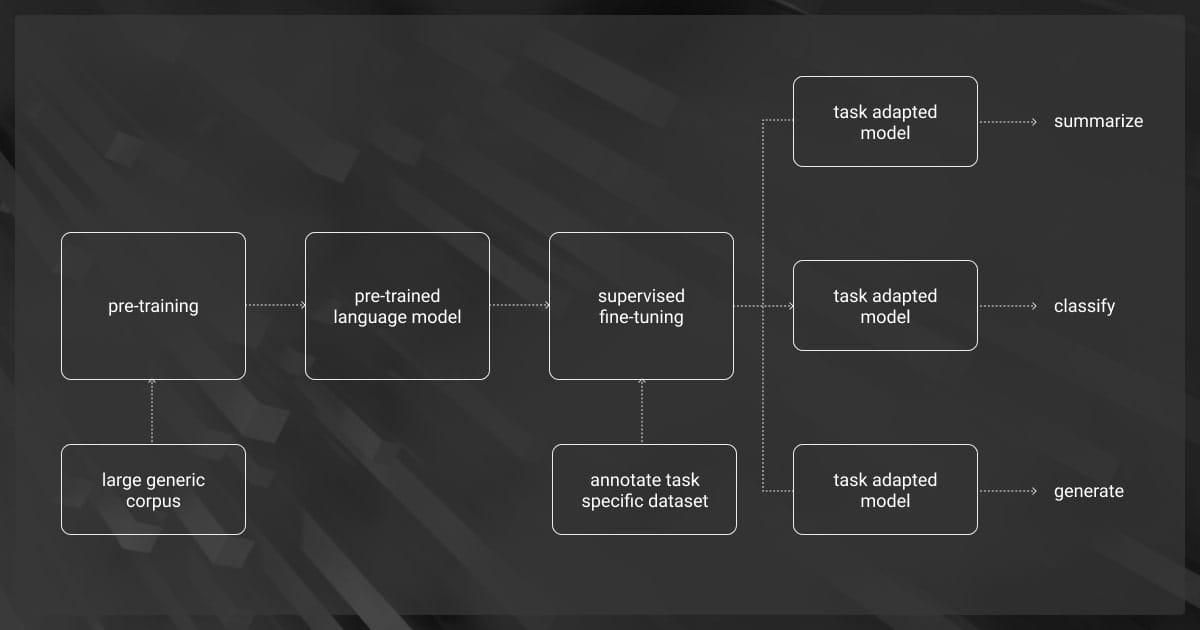
How Supervised Fine-Tuning Works

Supervised LLM fine tuning refines a pre-trained model by exposing it to labeled datasets. These datasets include input-output pairs that teach the model how to respond in specific scenarios.
Step 1. Preparing the Dataset
The first step is selecting or creating a dataset that matches your task. Each example in the dataset includes:
- Input data: What the model will process (e.g., text, images).
- Labeled output: The desired result (e.g., a summary, a classification label).
High-quality, well-structured data is essential for effective LLM supervised fine tuning.
Step 2. Adjusting the Model
Fine-tuning involves updating the model's parameters (weights). This aligns its predictions with the labeled outputs in the dataset. Unlike training from scratch, fine-tuning builds on the pre-trained model’s existing knowledge.
Step 3. Validation and Testing
The model is tested on a separate validation dataset during training. This helps ensure it improves without overfitting or relying too heavily on the training data. After training, it’s tested on new data to confirm its effectiveness.
Step 4. Iteration and Optimization
Fine-tuning often requires multiple rounds. Hyperparameters like learning rate or batch size are adjusted to improve results. Each iteration refines the model further, making it more accurate and reliable.
This process transforms a general-purpose model into a specialized tool for your unique tasks. But how do you fine-tune effectively? Let’s explore the top techniques used to maximize the potential of large language models.
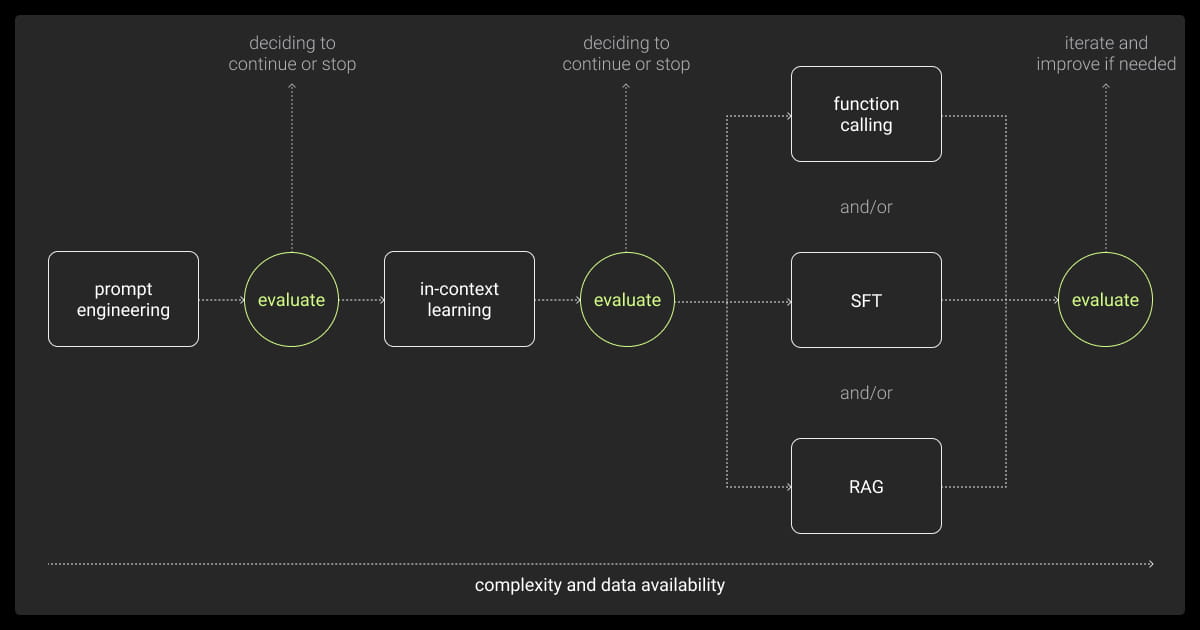
Top Techniques for Supervised Fine-Tuning of Large Language Models
SFT supervised fine tuning can be achieved through several approaches. Each technique caters to specific use cases and resource constraints.
Here are the most commonly used methodologies:
Instruction-Based Fine-Tuning
Instruction-based fine-tuning has been transformative for tasks like geospatial annotation, where models need to handle highly specialized datasets and workflows. This approach involves training the model to respond to specific instructions.
It enhances the model’s ability to:
- Follow complex prompts.
- Generate contextually appropriate responses for diverse tasks.
Example: Fine-tuning a model to handle customer service queries by training it with labeled examples of customer problems and their ideal solutions.
Instruction-based fine-tuning has been transformative in improving model performance because it narrows the potential response space, helping the model learn how to produce more accurate, concise, and contextually appropriate answers.
 Co-Founder, AI Tools
Co-Founder, AI Tools
Low-Rank Adaptation (LoRA)
LoRA focuses on updating only a small subset of the model's parameters during fine-tuning. This makes it a highly efficient technique for tasks with limited computational resources. Key benefits include:
- Cost Efficiency: Reduced memory and compute requirements.
- Flexibility: Easily applicable to large models without extensive retraining.
Use Case: Adapting a large LLM to specific domains (e.g., legal or medical) while keeping the process lightweight.
Reinforcement Learning from Human Feedback (RLHF)
RLHF refines the model using human feedback to align its outputs with desired behavior. It involves:
- Human Input: Collecting feedback to identify preferred outputs.
- Reward Modeling: Training the model to prioritize responses that align with user preferences.
- Fine-Tuning: Reinforcing the model based on reward signals.
Example: Aligning a chatbot’s tone and style with user expectations in customer-facing applications.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT techniques like adapters or prefix tuning update only specific layers or embeddings in the model. This method:
- Keeps most of the model frozen, retaining its general knowledge.
- Minimizes overfitting risks and computational costs.
Use Case: Fine-tuning a large LLM to handle specific tasks in multilingual contexts without retraining the entire model.
Layer Freezing
Freezing certain layers of the model, particularly the earlier ones, retains general-purpose knowledge. This technique reduces computational load and focuses training on the task-specific layers.
Use Case: Training the later layers of a language model for sentiment analysis while preserving its broader language understanding.
Each SFT LLM methodology offers distinct advantages. Here, the best choice depends on the task, resources, and level of customization needed.
Best Practices for Effective Supervised Fine-Tuning
Fine-tuning can significantly improve model performance, but it requires careful planning and execution. Below are best practices to ensure success.
Use High-Quality Data
The quality of your labeled dataset directly impacts the model’s performance. Ensure the data is:
- Clean: Remove duplicates, inconsistencies, or irrelevant entries.
- Representative: Cover all variations and edge cases for your task.
- Balanced: Avoid data skew to prevent bias in the model’s outputs.
Optimize Hyperparameters
Fine-tuning involves several parameters that influence the training process. Key ones to optimize include:
- Learning Rate: A lower rate often works better for fine-tuning to avoid overwriting pre-trained knowledge.
- Batch Size: Choose a size that balances computational efficiency and stability.
- Epochs: Too many can lead to overfitting; too few may result in undertraining.
Experimenting with these parameters ensures a balance between performance and training efficiency.
Monitor Overfitting
Overfitting happens when a model performs well on training data but poorly on unseen data. Use techniques like:
- Early Stopping: Halt training when performance on the validation set stops improving.
- Dropout Layers: Randomly deactivate some neurons during training to improve generalization.
- Weight Regularization: Add penalties to overly large weights to control complexity.
Leverage Transfer Learning
When LLM supervised fine tuning, freeze certain layers of the model—especially those capturing general knowledge—and train only the task-specific layers. This reduces computational requirements and prevents the model from "forgetting" its pre-trained knowledge.
Use Continuous Evaluation
Set up regular checkpoints to evaluate the model during training. Track metrics like:
- Accuracy: For classification tasks.
- BLEU or ROUGE Scores: For text generation.
- Loss Value: To monitor convergence during training.
Frequent evaluation ensures that the training process stays on track.
Test in Real-World Scenarios
After fine-tuning, test the model on real-world inputs. This helps identify any gaps or edge cases the training data didn’t cover. Feedback from real use cases can guide further refinement.
Following these best practices helps make supervised fine-tuning more effective, ensuring your model provides accurate and dependable results.
Challenges and Solutions in Supervised Fine-Tuning
While supervised fine-tuning LLM offers significant benefits, it also comes with challenges that can impact its success. Understanding these issues is essential to address them effectively.
Challenges
Data Limitations
High-quality labeled datasets are critical for fine-tuning, but they can be hard to find or expensive to create. Common issues include:
- Limited Availability: Specific domains (e.g., legal, medical) may lack large datasets.
- Labeling Costs: Annotating data requires time and expertise.
- Bias in Data: Incomplete or uneven datasets can cause biases in the model.
Ensuring the accuracy of large language models requires quality data annotation and iterative feedback. This technique enables accurate tuning while reducing errors and ensuring outcomes are contextually relevant.
 VP of Healthcare Solutions, OSP Labs
VP of Healthcare Solutions, OSP Labs
Resource Demands
Fine-tuning large models can be computationally expensive:
- Hardware Requirements: High-end GPUs or TPUs are often necessary.
- Training Time: The time required for fine-tuning varies, ranging from hours to days, based on the model's size and dataset.
- Energy Consumption: Running large-scale training processes can be energy-intensive, increasing costs.
Risk of Overfitting
If a model relies too much on the training data, it has trouble handling new inputs. Overfitting is especially problematic with small or imbalanced datasets. Techniques like regularization and dropout can help mitigate this risk but require careful implementation.
Model Forgetting
During fine-tuning, a model can lose the general knowledge it gained during pre-training. This is known as catastrophic forgetting. To avoid this:
- Freeze Layers: Preserve general-purpose knowledge by freezing earlier model layers.
- Careful Learning Rates: Use a lower learning rate to make gradual updates.
Scalability Challenges
Fine-tuned models are often task-specific, which limits their reuse across other tasks or domains. Creating multiple fine-tuned models for different needs can lead to higher costs and resource usage.
Solutions
Invest in High-Quality Data Annotation
High-quality data annotation ensures models learn effectively from task-specific examples thanks to balanced, accurate datasets.
Optimize Training Resources
Use efficient techniques like Low-Rank Adaptation (LoRA) or parameter-efficient fine-tuning methods.
Iterative Training
Continuously refine the model with new data and feedback to improve performance.By anticipating and addressing these challenges, you can maximize the benefits of supervised fine tuning LLM while minimizing potential drawbacks. And if you’re looking for a reliable data annotation company to provide high-quality labeled data, our expert team is here to support your fine-tuning process.
About Label Your Data
If you need a labeled dataset for your supervised fine-tuning task, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is supervised fine-tuning?
Supervised fine-tuning is the process of improving a pre-trained model’s performance by training it on a labeled dataset. This method aligns the model with specific tasks or objectives, enhancing its accuracy and reliability for targeted applications.
What is the difference between instruction fine-tuning and supervised fine-tuning?
Instruction fine-tuning focuses on training models to follow general instructions across a wide range of tasks, often using diverse datasets. Supervised fine-tuning, on the other hand, involves training the model on specific labeled data to improve performance on a particular task or domain.
What is an example of SFT?
An example of supervised fine-tuning is training a large language model on a dataset of customer service transcripts to enhance its ability to generate accurate, context-aware responses for a help desk chatbot.
What type of data is typically used for supervised fine-tuning?
Supervised fine-tuning typically uses labeled datasets tailored to the task at hand. Examples include annotated text for sentiment analysis, question-answer pairs for conversational models, or domain-specific documents for specialized knowledge tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.