Data Versioning: Best Practices for ML Engineers

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Dataset Versioning Fundamentals for Machine Learning
- Key Benefits and Use Cases of Data Versioning
- Data Version Control Concepts and Implementation Approaches
- Data Versioning Checklist to Avoid Pipeline Failures in Your ML Projects
- Data Versioning Tools for ML Engineers
- About Label Your Data
- FAQ

TL;DR
- Data versioning tracks changes in datasets to improve reproducibility and reliability in ML projects.
- Common approaches range from simple file copies to advanced Git-like systems such as DVC or lakeFS.
- The main benefits are consistent model training, faster debugging, safer CI/CD pipelines, and compliance support.
- Best practices include semantic versioning, automated tracking, TTL policies, dataset branching, and clear governance.
- Key tools for ML teams include DVC, Git LFS, lakeFS, Nessie, Dolt, Pachyderm, dbt snapshots, and Monte Carlo.
Dataset Versioning Fundamentals for Machine Learning
Data versioning is the practice of tracking and managing changes to machine learning datasets over time. It gives ML engineers the same control over data that Git provides for code. Each dataset snapshot can be referenced, compared, and restored, ensuring that experiments are reproducible and pipelines remain stable.
Without versioning, teams often rely on ad-hoc file naming like “dataset_v2.csv” or “dataset_final.csv” to keep track of changes. This creates serious risks: lost reproducibility when a model can’t be tied back to its training data, silent schema drift that breaks production pipelines, and conflicts when multiple engineers work on different copies of the same dataset.
Versioning turns data into a single source of truth. With immutable snapshots and lineage tracking, you can roll back to any previous state, audit how a dataset evolved, and safely collaborate across teams. In modern ML workflows, it’s the backbone of reproducibility and operational reliability.
Yet, without reliable data annotation, version control can only do so much; mislabeled data propagates errors no matter how well it’s versioned.
Key Benefits and Use Cases of Data Versioning
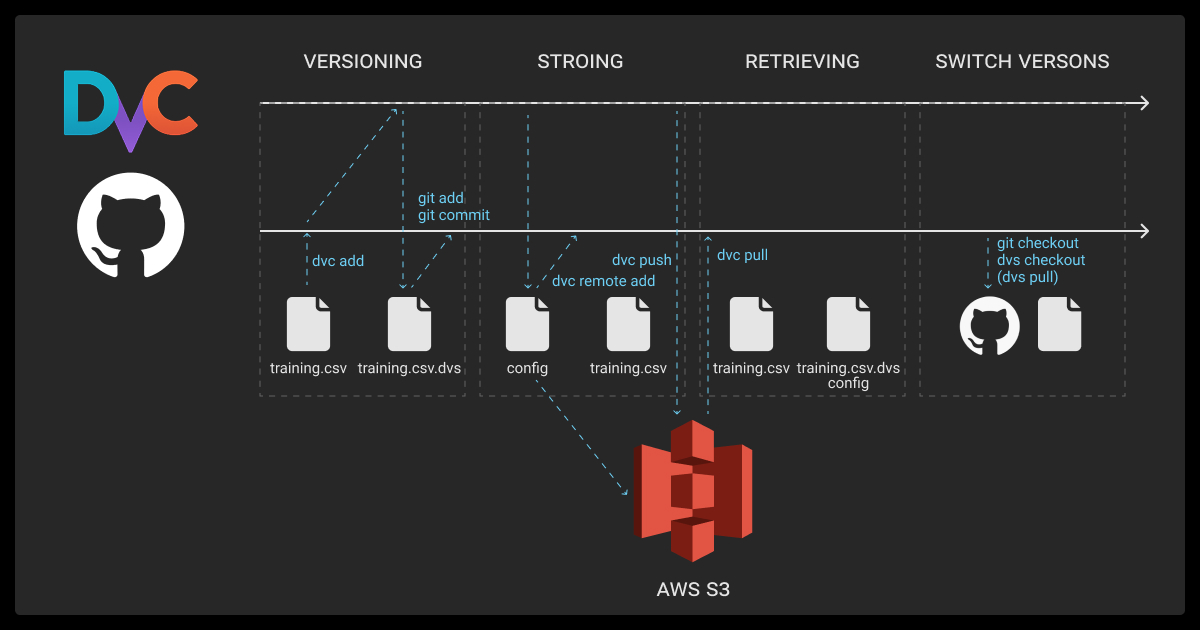
Every machine learning algorithm is only as good as the machine learning datasets it was trained on, and versioning ensures those datasets remain reproducible.
Machine learning data versioning gives teams the ability to reproduce, audit, and scale their workflows with confidence. Beyond just storing snapshots, it enables structured collaboration and reliable model development.
The main benefits are:
- Reproducibility: link datasets directly to model versions, so experiments can be rerun exactly
- Reliability: roll back to earlier datasets when new changes introduce errors
- Compliance: maintain lineage and audit trails for regulated industries
- Collaboration: avoid conflicts by keeping every team member on a consistent dataset view
Machine learning model training
Connecting image classification models, for example, or any other model to specific dataset versions ensures experiments are repeatable. If accuracy drops, engineers can reproduce the exact conditions of the training run, compare results, and identify whether the issue comes from code or data.
Data pipelines and CI/CD
Versioned data makes pipelines safer. Engineers can deploy changes with confidence, test on controlled versions, and roll back if new data breaks the system. This is particularly important for continuous training, where pipelines must absorb new data without risking production stability.
The breakthrough came when we implemented immutable snapshots of our entire database at specific timestamps. Each model training run is now tied to a unique snapshot ID, so we always know which data produced which results. Debugging that used to take weeks now takes hours because there’s zero ambiguity about dataset versions.

 Co-Founder, Entrapeer
Co-Founder, Entrapeer
For image recognition projects, data versioning makes it possible to roll back to earlier datasets if new augmentations degrade accuracy.
Data Version Control Concepts and Implementation Approaches
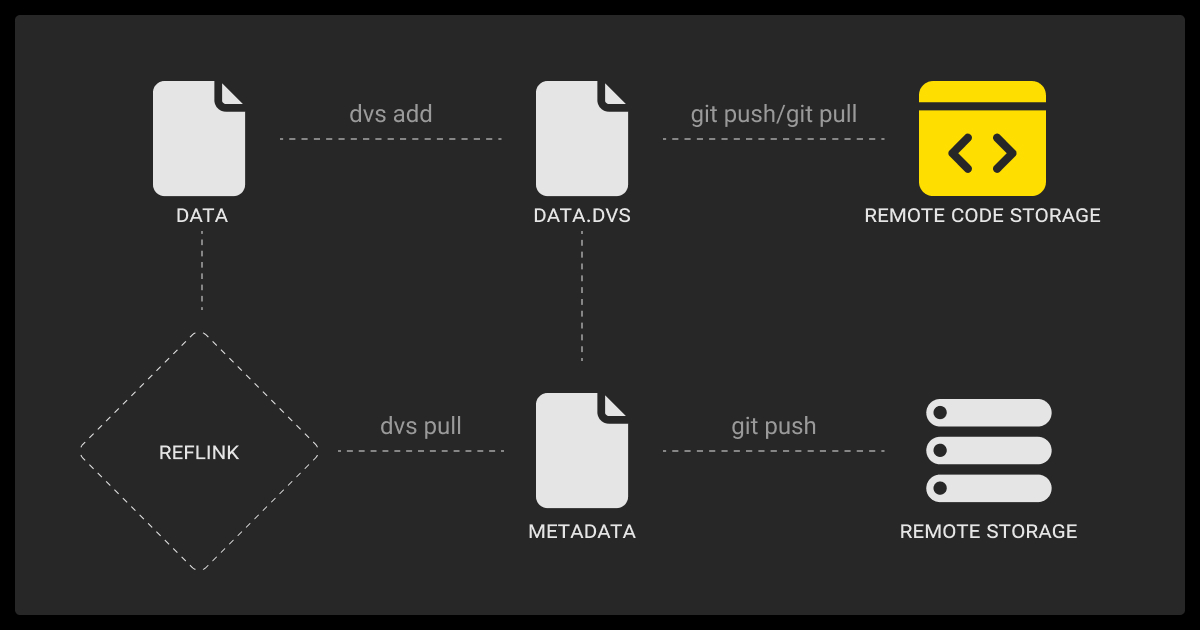
The principles behind data version control are simple: treat data as immutable, keep a full history of changes, and preserve lineage, so every version is auditable. How teams apply these principles varies, from quick fixes to enterprise-grade systems.
Full duplication
The most basic approach is duplicating datasets whenever they change. Each copy acts as a snapshot. It’s simple to set up but quickly becomes storage-heavy and messy at scale, especially with large image or video datasets.
Metadata fields
For tabular data, versioning can be managed by adding fields such as “valid_from” and “valid_to.” This creates a form of “time travel” within SQL systems, letting engineers query the dataset as it existed at any point in time. It’s more efficient than duplication, but it increases query complexity and can be hard to maintain for non-tabular data.
First-class data version control
Modern tools bring Git-like semantics to data. Systems like lakeFS and DVC let engineers branch, commit, and roll back datasets just as they would with code. These solutions scale to terabytes, integrate into CI/CD pipelines, and provide audit trails for compliance, making them the preferred choice for production ML environments.
Data Versioning Checklist to Avoid Pipeline Failures in Your ML Projects

A structured checklist helps ML engineers keep pipelines reproducible and resilient. Use these data versioning best practices to reduce risk and improve collaboration:
Define what to version
Decide early which datasets need versioning. Raw inputs, processed features, and labels all impact model behavior, so skipping one creates gaps in reproducibility. Teams that rely on external data annotation services should also track versions of labeled datasets, since updates to annotations can shift model performance as much as new raw data.
Capture metadata
Store schema, data lineage, and details of changes. This makes debugging easier when pipelines break and provides an audit trail for compliance.
Link data with code and experiments
Always tie dataset versions to code commits and model artifacts. Without this link, it’s impossible to know which dataset trained which model.
Automate versioning in pipelines
Integrate versioning into ETL and CI/CD workflows so every run produces a traceable snapshot. Manual versioning is error-prone and won’t scale. Versioning also saves costs: with data annotation pricing tied to volume, you avoid paying to re-label data you’ve already validated.
Clean up old versions and monitor impact
Apply retention rules and track the impact of data changes on models. This keeps storage under control while ensuring versioning remains useful instead of bloated.
The tipping point was triggered by a product demo, when our model lost 23% accuracy overnight. We found out three engineers had been training on varying versions of the same dataset with no record of changes. The fix was a strict data lineage system with checksums, mandatory metadata tagging, and immutable snapshots tied to model versions. Taking data versioning as seriously as model versioning has since saved us months of rework.
 CTO / Software Engineer, AlgoCademy
CTO / Software Engineer, AlgoCademy
Data Versioning Tools for ML Engineers
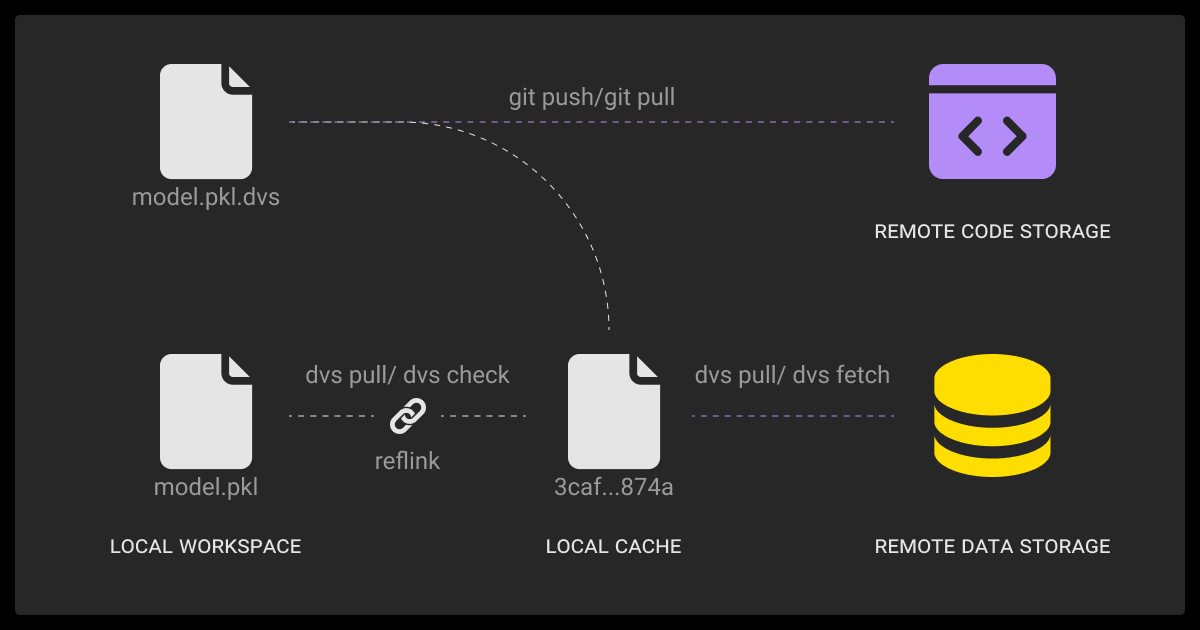
Different teams approach versioning with different dataset versioning tools. Some extend Git, others bring Git-like semantics directly into data lakes or databases, and others manage versioning inside workflow engines. Each category has its own fit and limitations.
Git-integrated tools
These data versioning tools extend Git to track datasets and model artifacts. They work best for teams already using Git-based workflows and want tight coupling between code and data. The downside is scalability: very large datasets require special storage backends and can slow operations.
Lake-based systems
These systems add branching, committing, and rollback directly to object stores like S3. They scale to terabytes and integrate with Spark, Presto, and other lakehouse engines. The trade-off is infrastructure complexity: they require setup, monitoring, and governance policies.
Versioned databases
Examples: Dolt
Dolt is a SQL database with Git-style branching and merging. It’s effective for tabular data and supports SQL-native time travel. The limit is scope: great for structured data, but not designed for unstructured modalities like video or images.
Workflow and observability tools
Examples: Pachyderm, dbt snapshots, Monte Carlo
These data versioning tools integrate versioning into pipelines. Pachyderm tracks data lineage with containerized stages, dbt snapshots version transformations in SQL, and Monte Carlo monitors data quality and changes. They are best for teams needing CI/CD integration and observability, but they can add overhead if the main need is just dataset versioning.
We overcame hidden data corruption across environments by implementing semantic data versioning. Instead of tracking only data content, we also captured preprocessing parameters, environment configs, and dependencies. This revealed that ‘identical’ datasets had actually gone through different pipelines. The solution was environment-agnostic preprocessing, parameter standardization, and automated drift detection.
 Co Founder, VoiceAIWrapper
Co Founder, VoiceAIWrapper
The same principles apply beyond vision tasks. Teams working on LLM fine tuning also need reproducible data pipelines. Without consistent versioning, even small data drifts can derail LLM fine-tuning services. This is especially important when experimenting with different types of LLMs.
So pick your starting point based on pipeline maturity:
- Git-integrated tools are easiest if your workflow already revolves around Git
- Lake-based systems make sense once datasets hit terabyte scale
- Versioned databases are useful for SQL-heavy teams, while workflow tools are ideal when observability and CI/CD matter most
A pilot project with one tool from each category is often the fastest way to see which approach fits your environment. And remember: data versioning only works if the underlying labels are consistent, so starting with a small (and in our case – free) data annotation pilot ensures the foundation is reliable before scaling.
Partnering with a data annotation company or using a managed data annotation platform helps produce high-quality labeled datasets before scaling version control. Teams often compare data annotation pricing against the cost of maintaining internal services.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is data versioning?
Data versioning is the practice of tracking and managing changes to datasets over time. It creates immutable snapshots of data, allowing teams to reproduce experiments, roll back to earlier states, and maintain a full lineage of how data evolves.
What is an example of versioning?
A simple example is keeping multiple versions of a dataset used in model training. Instead of overwriting “training.csv,” each snapshot is stored and labeled as a distinct version. Engineers can then re-run experiments with the exact dataset that produced a given model, ensuring reproducibility.
What are the benefits of data versioning?
Data versioning improves reproducibility, reliability, and compliance in machine learning workflows. It allows teams to debug pipelines more effectively, roll back when new changes cause regressions, and maintain an audit trail for governance and collaboration.
What are different types of versioning?
Common approaches include full duplication of datasets, adding metadata fields like “valid_from” and “valid_to” for tabular time travel, and using first-class tools that apply Git-like branching and commits to data. Each method balances ease of use, storage efficiency, and scalability.
What are the best dataset versioning tools for computer vision?
For computer vision, Git-integrated dataset versioning tools like DVC work well for smaller projects, while lakeFS scales better for large image or video datasets stored in data lakes. Teams also combine these with workflow systems such as Pachyderm for lineage tracking or observability in production pipelines.
Can tools like Gemini or ChatGPT handle data versioning?
While some compare Gemini vs ChatGPT for downstream tasks such as text generation or analysis, neither replaces the need for structured versioning of datasets. Data versioning tools are designed to manage snapshots, lineage, and reproducibility, which large language models do not provide on their own.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.