Model Distillation: Teacher-Student Training Guide

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How Does Model Distillation Work?
- Model Distillation vs Fine-Tuning and Pruning
- Setting Up Model Distillation: Architectures and Losses
- Emerging LLM Model Distillation Strategies
- Evaluation: Ensuring Student Quality and Efficiency
- Scaling Model Distillation Machine Learning to Production
- Advanced Practices and Pitfalls
- When to Use Model Distillation in Machine Learning Projects
- About Label Your Data
- FAQ

TL;DR
- Model distillation builds smaller models from larger ones by transferring behavior through soft logits, feature maps, and relational knowledge.
- Use it when you need faster inference, lower latency, or edge deployment without retraining from scratch.
- The main strategies include soft-target, feature-based, and relational distillation. Many workflows combine all three using composite loss.
- Distillation works best when data is limited, inference speed matters, or you’re replicating general-purpose knowledge.
- LLM distillation is becoming standard practice. Examples include Amazon Bedrock model distillation, DeepSeek, and OpenAI’s own student models.
How Does Model Distillation Work?
Model distillation trains a smaller student model to mimic a larger teacher. The process transfers probability distributions, intermediate features, and relational patterns. It replicates the teacher’s behavior while reducing size and complexity.
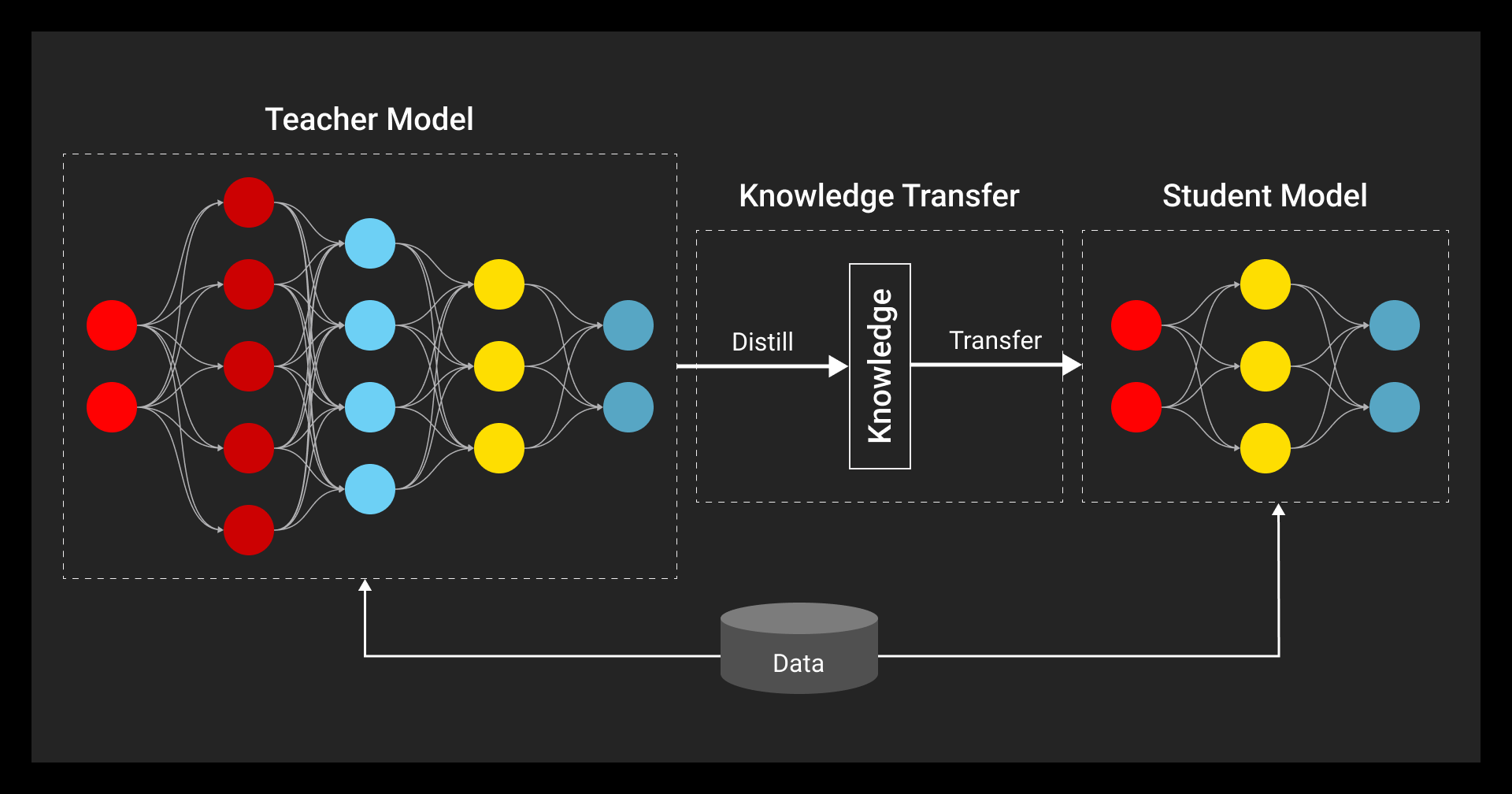
The most common techniques:
- Logit-based: The student learns from the teacher’s probability outputs instead of just hard labels.
- Feature-based: Intermediate activations are aligned across layers.
- Relation-based: Structural relationships between predictions or features are copied over.
You’ll see this in LLM model distillation, image recognition, and edge deployments. It speeds up inference and reduces compute without a large hit to accuracy. Distillation models like DeepSeek or OpenAI model distillation use these methods to scale models across tasks. Bedrock model distillation also builds on this foundation.
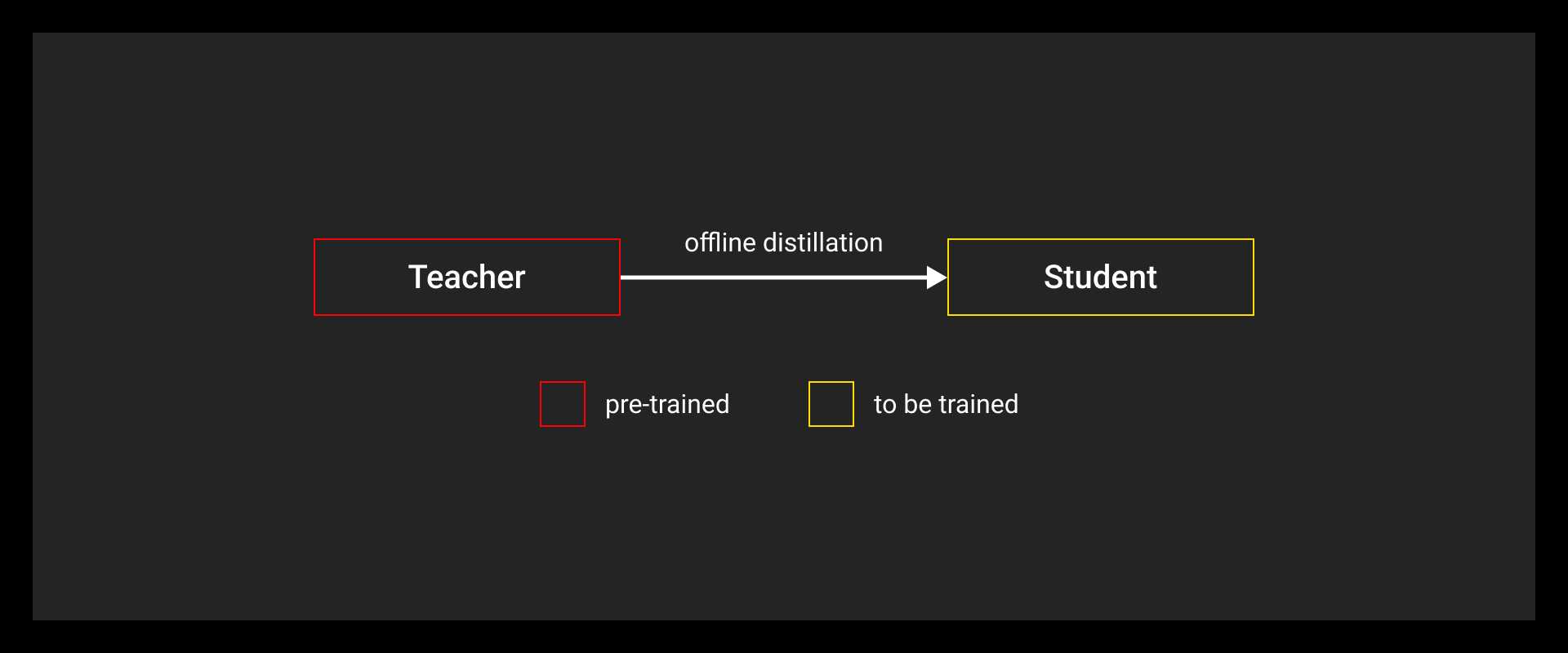
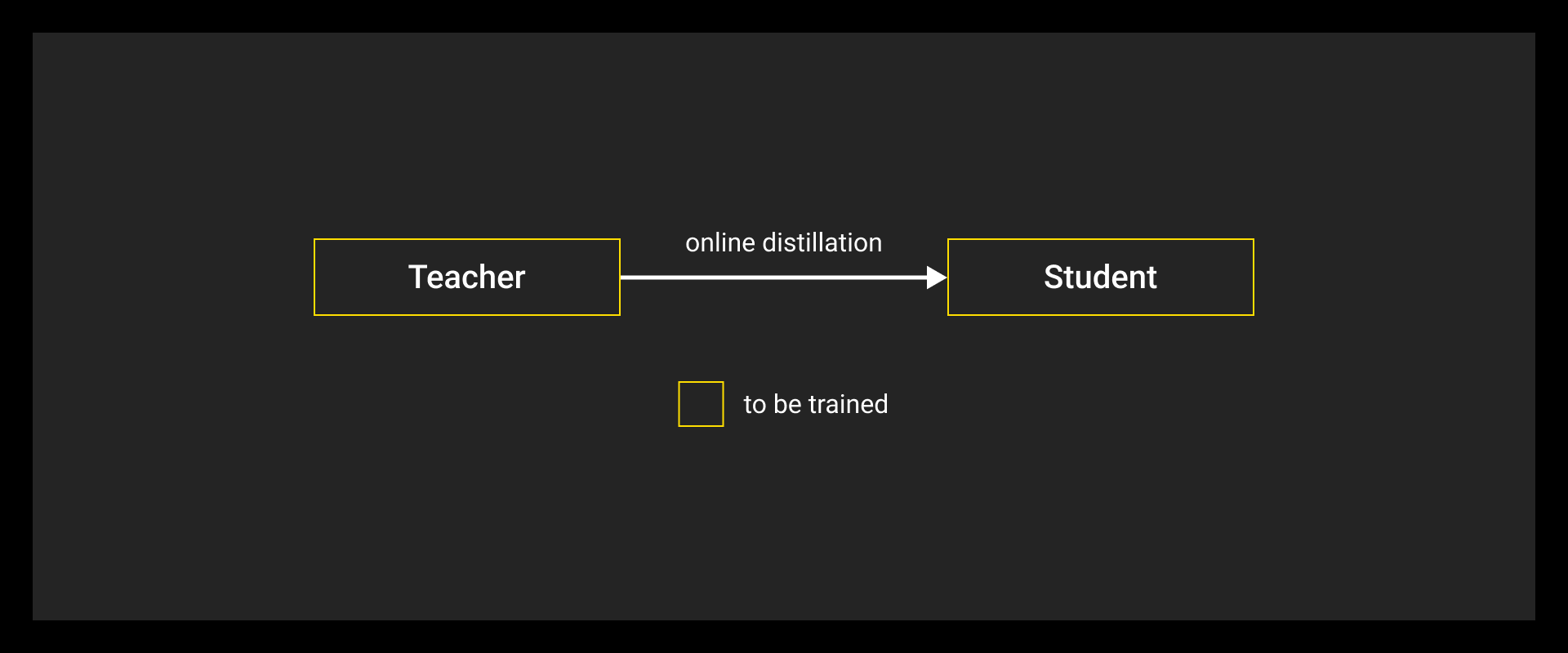
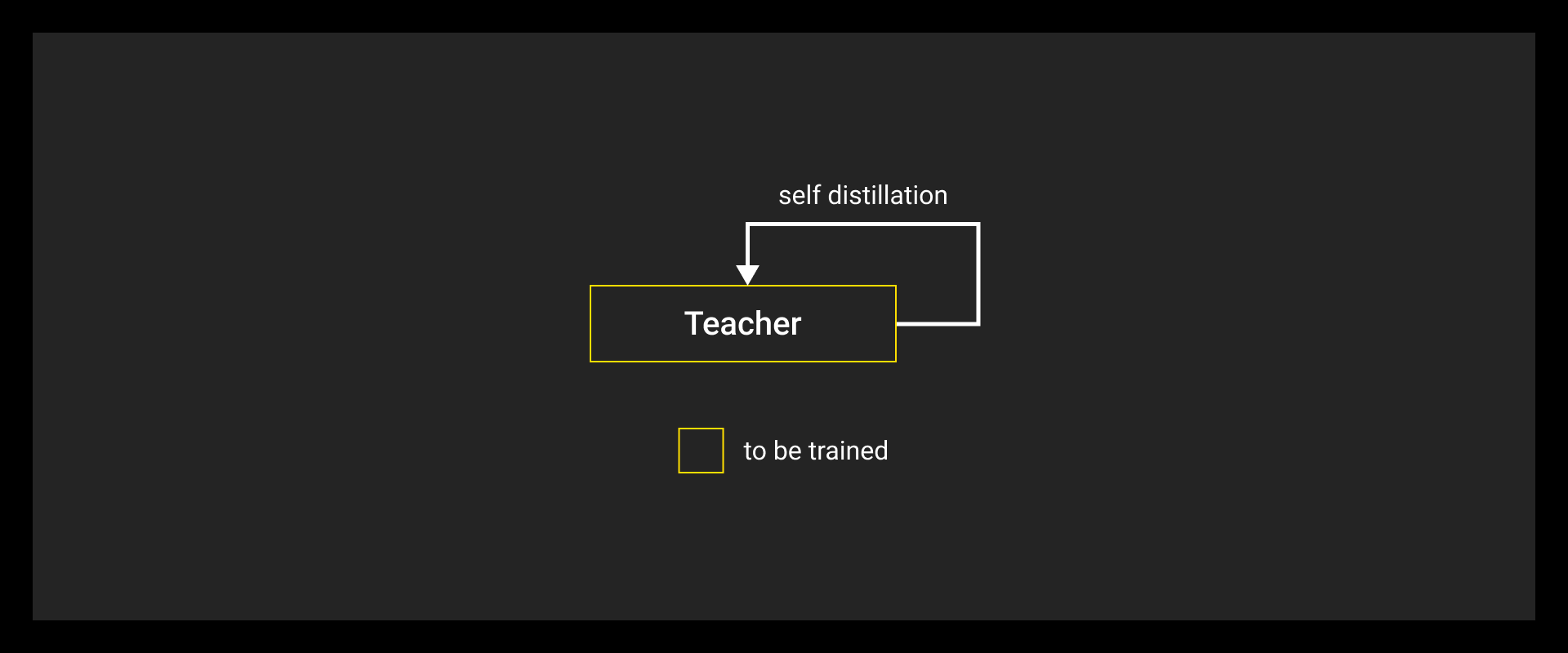
Common Distillation Modes
Different setups depending on training workflow and resource constraints:
- Offline distillation: Train the teacher first, freeze it, and then train the student on saved outputs. Most common setup.
- Online distillation: Teacher and student train together. More dynamic, but needs careful tuning.
- Self-distillation: A model learns from its own past checkpoints or intermediate predictions. No separate teacher needed.
- Multi-teacher distillation: The student learns from multiple teachers. Works well when combining models trained on different tasks.
- Cross-modal distillation: Transfer knowledge across modalities (e.g., guiding a text model using a vision model). Useful for retrieval or zero-shot setups.
Distillation Techniques
These strategies define how knowledge is transferred:
- Soft-target distillation: The student learns from the teacher’s logits. Preserves uncertainty and class relationships missed by hard labels.
- Feature-based distillation: Student matches intermediate representations of the teacher. Common when model architectures are similar.
- Relational distillation: Student mimics how the teacher relates different inputs. Works well in contrastive learning or multimodal tasks.
Many setups use a combination of all three with weighted losses.
Model Distillation vs Fine-Tuning and Pruning

These three methods get lumped together a lot. But they solve different problems.
Distillation
Model distillation lets you train a smaller model (the student) using the predictions, features, or internal structure of a larger, pre-trained model (the teacher). You’re teaching the student to replicate the teacher’s reasoning, not just its answers.
Useful when:
- You already have a high-performing model
- You need faster inference or lower memory without retraining from scratch
- You want to keep accuracy as close as possible
Fine-tuning
Fine-tuning takes a pretrained model and updates it on task-specific data. It’s direct and powerful but comes with trade-offs.
Useful when:
- You want to improve performance on a narrow task
- You’re okay with the model staying large
- You don’t need speed or size improvements
Standard model or LLM fine tuning doesn’t reduce its size or compute. It just adjusts what the model knows.
Keep in mind that fine-tuning requires labeled data and often depends on high-quality data annotation to adapt models for narrow use cases.
Pruning and Quantization
These techniques reduce model size by removing weights (pruning) or lowering precision (quantization). They’re straightforward, fast, and often used post-training.
Useful when:
- You want to deploy the same model with fewer resources
- You don’t have time to retrain a student
- Accuracy loss is acceptable
They’re simpler than distillation but usually less accurate.
When to Distill Instead
Distillation wins when you care about both speed and quality. It’s especially worth using if:
- You’re working with large foundation models (like LLMs)
- You need models on edge devices or mobile
- You want to combine compression with feature learning
If you’re comparing options like fine-tuning, pruning, or outsourcing labels, it’s worth factoring in data annotation pricing to assess the total cost of building smaller models.
Many teams also pair distillation with pruning or quantization to squeeze out more gains. Distillation isn’t the fastest trick but it pays off when done right.
I identify redundant layers or neurons that make negligible contributions... then apply structured pruning and iterative retraining cycles.

 Chief Technology Officer, Cybersecurity Consultant and Author, The Cyber Threat
Chief Technology Officer, Cybersecurity Consultant and Author, The Cyber Threat
Setting Up Model Distillation: Architectures and Losses
Getting a distilled model to perform well starts with solid teacher–student architecture planning and careful loss design. If you mismatch them or oversimplify the loss, your student model won’t learn the right things or won’t learn fast enough.
Aligning Teacher and Student Architectures
Start with architecture alignment:
- Match layer depths where possible. If the student is shallower, map teacher outputs to intermediate layers.
- Use projection layers to bridge hidden state size gaps between models.
- Avoid pairing models with totally different internal layouts unless you’re ready to invest in custom loss tuning.
Smaller doesn’t mean random. Even a compact student needs enough capacity and structure to absorb what the teacher is offering.
Designing the Distillation Loss
Distillation loss is usually a weighted sum of three components:
- Soft targets from the teacher's logits (via Kullback–Leibler divergence or MSE)
- Hard labels from the original dataset (via cross-entropy)
- Feature-level loss to align intermediate representations
The total loss often combines three components: soft target loss, hard label loss, and a feature alignment loss. You can control how much each contributes with weights like alpha, beta, and gamma.
Use temperature scaling (T > 1) on soft targets to make the logits more informative. Higher temperatures smooth out the distribution, revealing class similarities.
Set α, β, γ based on your model size and task. Text classification may rely more on soft targets; image recognition might benefit from stronger feature alignment.
Picking the Right Layers
Don’t distill from every layer. Pick teacher layers that carry high-level semantic information. For students with fewer layers, align only key stages (early, middle, final) and use interpolation or projection where needed.
Emerging LLM Model Distillation Strategies
Distillation in large language models has moved past logits and hidden states. New approaches make use of instruction tuning, synthetic data, and cross-modal supervision to create compact models that still generalize well.
LLM Model Distillation from Assistant Outputs
Instead of real user data, many teams now use AI-generated outputs to train smaller models. This can be done using proprietary teachers (like GPT-4) or open ones (like DeepSeek or Mistral).
- You don’t always need gold-standard human data annotation services. High-quality assistant completions can guide student models effectively.
- This approach supports closed-source-to-open-source transfer, which some call "OpenAI model distillation" or "DeepSeek model distillation."
- It also sidesteps licensing issues when original training data isn't accessible.
This setup is common in Amazon Bedrock model distillation pipelines, where large providers distill their foundation models for latency-sensitive use cases.
Many teams use outputs from large models to train smaller ones without relying on a data annotation company, especially when rapid iteration matters more than ground-truth labels.
Cross-Modal and Zero-Shot Distillation
Cross-modal supervision is increasingly used in retrieval, ranking, and multimodal tasks.
- Vision encoders can guide text models via shared embeddings or similarity signals.
- This helps student models learn aligned representations across modalities without needing separate datasets for each task.
- Works well in retrieval-augmented generation setups, or when scaling multimodal agents.
Other Model Distillation LLM Trends
Distillation helps compress different types of LLMs, from general-purpose chatbots to domain-specific assistants, making them more usable in production.
- Multi-teacher ensembles: Some teams average or mix outputs from multiple large models to avoid biasing the student toward a single teacher’s failure modes.
- Privacy-safe synthetic data: Especially relevant when original data is restricted. Teachers generate instruction–response pairs, which are then filtered or audited before training the student.
We’ve had success maintaining 95% accuracy on core subject predictions by carefully selecting teacher-student model pairs and using a focused dataset of our most common learning patterns.
 Chief Product Officer, Cognito Education
Chief Product Officer, Cognito Education
Evaluation: Ensuring Student Quality and Efficiency
Once the student is trained, you need to evaluate it across more than just accuracy. Compression doesn’t mean much if the model fails under real-world conditions.
Balancing Accuracy and Speed
You’re typically sacrificing a few points of accuracy for gains in speed, size, and energy usage. The goal is to make the trade-off worth it.
Track:
- Task accuracy (classification, generation, retrieval)
- Inference latency (on target hardware)
- Memory footprint
- Energy or FLOPs used per prediction
If your distillation model can run on CPU instead of GPU, or cut inference time by 50%, that can matter more than a 1–2% accuracy dip.
Testing Across Different Tasks
Small student models often overfit to the teacher’s style or task. This hurts transferability.
To evaluate robustness:
- Use held-out tasks or domains (e.g., different question types for QA, different accents for ASR)
- Test out-of-distribution (OOD) behavior
- Measure calibration (confidence vs correctness)
- Try mixed evaluation datasets (e.g., multitask benchmarks like HELM or MMLU)
LLM model distillation often suffers from narrow generalization if trained only on synthetic or templated data. Broader eval helps you catch that early.
Scaling Model Distillation Machine Learning to Production
Distillation in a research notebook is one thing. Running it as part of a production pipeline is another.
On-the-Fly vs Offline Distillation Setup
There are two main ways to run distillation in production:
- Offline distillation: Pretrain and distill models separately. This works well when you have fixed datasets and clear performance targets.
- On-the-fly distillation: Run distillation as part of training or retraining workflows, often triggered by new data or performance drops.
On-the-fly setups are common in large-scale ML systems. They help reduce dev–prod drift and adapt to new edge cases. Some teams use data collection services alongside on-the-fly distillation to continuously expand and refresh training datasets from production inputs.
If you’re deploying to mobile, edge, or embedded systems, automate the retraining cycle. That includes evaluation, distillation, quantization, and packaging.
Monitoring Performance After Deployment
A distilled student might look good in testing, then slowly drift in production.
To avoid that:
- Log input distributions and compare them to training data
- Track per-task accuracy or regression metrics in real time
- Watch for spikes in OOD inputs or unseen classes
- Set up alerts for model underperformance
Some teams version machine learning datasets and retrain periodically. Others use data drift triggers or active learning to refresh the student. Distillation is a repeatable process.
Reliable edge models need elastic memory, not just smaller parameters. We reduce edge power consumption by 50% while letting models dynamically scale memory usage.
 CEO, Kove
CEO, Kove
Advanced Practices and Pitfalls
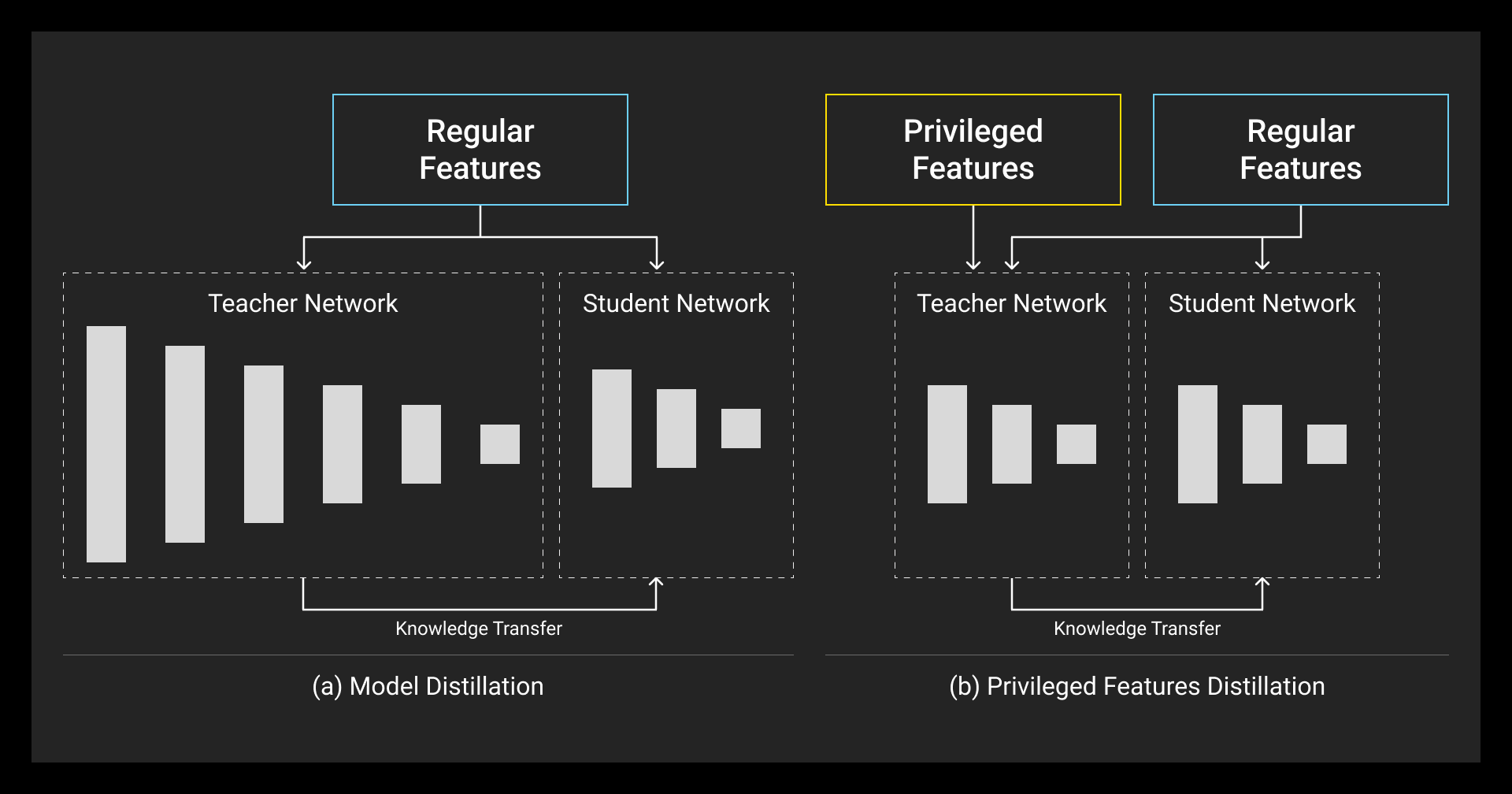
Model distillation can fail if you ignore two things: noise and mismatch.
Avoiding Overfitting to Teacher Noise
Sometimes, the teacher model is wrong or overconfident. The student blindly copies those mistakes. You can mitigate this by:
- Using temperature scaling to soften overconfident outputs
- Regularizing the student with dropout or label smoothing
- Combining hard and soft targets, so the student doesn’t rely on one signal
Also, don’t distill from a teacher that was overfit to the training set. The student will learn the same bad habits.
Preventing Teacher Misguidance
If your student and teacher architectures differ a lot, naive layer matching can confuse the student.
What helps:
- Projecting teacher features into student space with learnable adapters
- Aligning layers based on semantic meaning, not just depth
- Skipping noisy intermediate layers that don’t improve performance
When distilling across domains or modalities, test feature transfer layer by layer. Not every part of the teacher should be copied.
Distillation is fragile when treated as a black box. Careful matching and loss design make the difference.
When to Use Model Distillation in Machine Learning Projects
Not every project needs distillation.
Here’s how to decide:
- You need to deploy on low-resource devices (mobile, edge, embedded)
- Inference speed is a bottleneck
- Training a small model from scratch doesn't match your accuracy needs
- You already have a strong teacher model (LLM or CV backbone)
- You want a lightweight version for offline or private environments
Tools to consider:
- DistilBERT, TinyBERT, MobileBERT: Pre-distilled NLP models
- Hugging Face Transformers: Includes distillation scripts and pretrained student models
- Microsoft DeepSpeed and Amazon Bedrock Model Distillation: Tooling for large-scale or production LLM distillation pipelines
Distillation makes sense when you already have a good model and need to scale or simplify without starting over. If you’re unsure, start with a benchmarked task and compare results from distillation vs pruning, quantization, or smaller models trained from scratch.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is model distillation?
Model distillation is a technique where a smaller model (the student) learns from a larger, pre-trained model (the teacher). It mimics the teacher’s outputs, intermediate features, or relational behavior to match its performance as closely as possible, using less compute and memory.
What is the difference between model distillation and fine-tuning?
Fine-tuning adapts a pre-trained model to a specific task using labeled data. LLM fine-tuning services typically help teams update large language models for domain-specific tasks. Model distillation, on the other hand, trains a new, smaller model to behave like a larger one. Fine-tuning updates the teacher. Distillation builds a student from scratch.
What are the benefits of model distillation?
Distilled models are smaller, faster, and easier to deploy without a big drop in accuracy. They’re ideal for mobile, edge, or latency-sensitive environments. Distillation preserves generalization better than pruning and doesn’t require full retraining like fine-tuning. It’s also useful for compressing large LLMs while keeping their behavior.
What is LLM model distillation?
LLM model distillation applies the distillation process to large language models. A smaller student LLM is trained to replicate a larger model’s responses, embeddings, or behavior. This is key for edge LLMs, privacy-preserving chatbots, or cost-effective inference.
What is the difference between model distillation and quantization?
Distillation trains a new model to behave like the original. Quantization reduces a model’s size by lowering the precision of its weights (e.g., float32 to int8) without retraining. They’re often combined: distill first, then quantize.
What are the algorithms for model distillation?
Distillation uses a few core strategies, each compatible with different machine learning algorithm choices.
Soft-target distillation trains the student on the teacher’s logits instead of hard labels. Feature-based distillation aligns hidden states or layer outputs. Relational distillation preserves the relationships between data points in the embedding space. Many setups combine these into a weighted composite loss. Variants include self-distillation, multi-teacher distillation, and online training.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.