What Is a Movie Recommendation System in ML?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Movie recommendation systems use ML to predict user preferences based on past behavior.
- Filtration strategies include content-based filtering, focusing on individual user preferences, and collaborative filtering, which considers multiple users' preferences.
- Building a system requires data, personalization, and combining filtering strategies for accuracy.
- Neural networks improve recommendation precision through layers of user and movie embeddings.
- Popular use cases: Netflix and YouTube use complex recommendation models to enhance user experience and drive engagement.
Introduction to the Movie Recommendation System Architecture
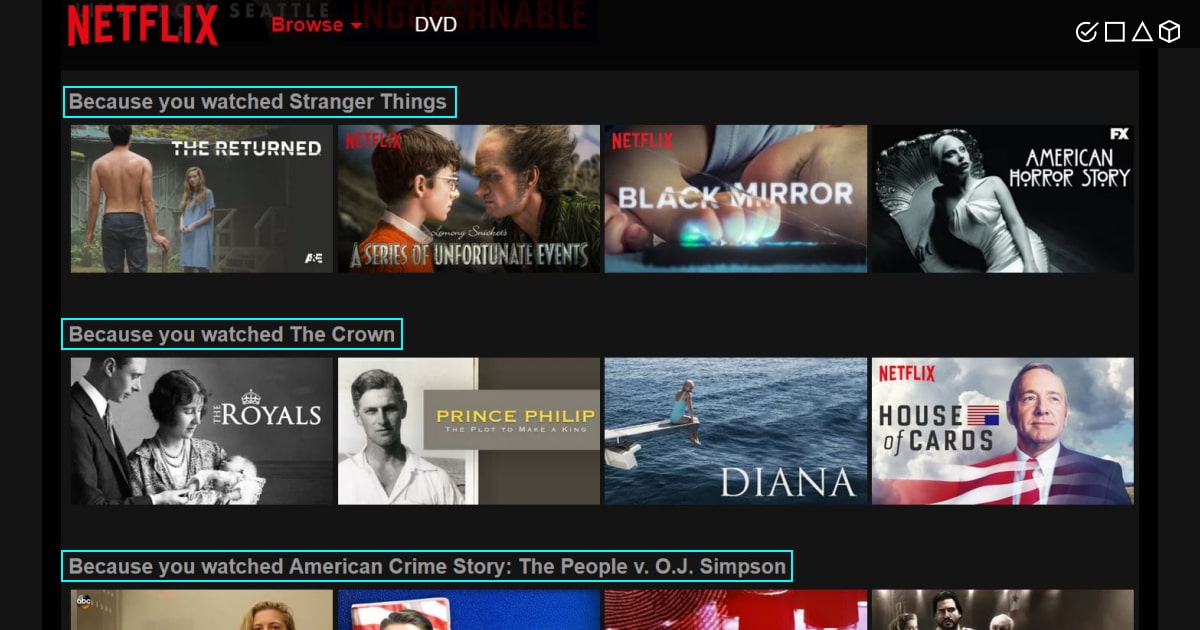
A movie recommendation system, or a movie recommender system, is an ML-based approach to filtering or predicting the users’ film preferences based on their past choices and behavior. It’s an advanced filtration mechanism that predicts the possible movie choices of the concerned user and their preferences towards a domain-specific item, aka movie.
The largest movie libraries in the world are all digitized and transferred to online streaming services like Netflix, HBO, or YouTube. Enhanced with AI-powered tools and supported by essential data annotation processes, these platforms can now assist us with probably the most difficult chore — picking a movie. Machine learning plays a crucial role here, with data scientists exploring our behavioral patterns and the ones of the movies to build sophisticated predictive systems for true movie fans.
The basic concept behind a movie recommendation system is quite simple. There are two main elements in every recommender system: users and items. The system generates movie predictions for its users, while items are the movies themselves.
The primary goal of movie recommendation systems is to filter and predict only those movies that a corresponding user is most likely to want to watch. A chosen machine learning algorithm for these recommendation systems uses the data about this user from the system’s database. This data is used to predict the future behavior of the user concerned based on the information from the past.
Filtration Strategies for Movie Recommendation Systems
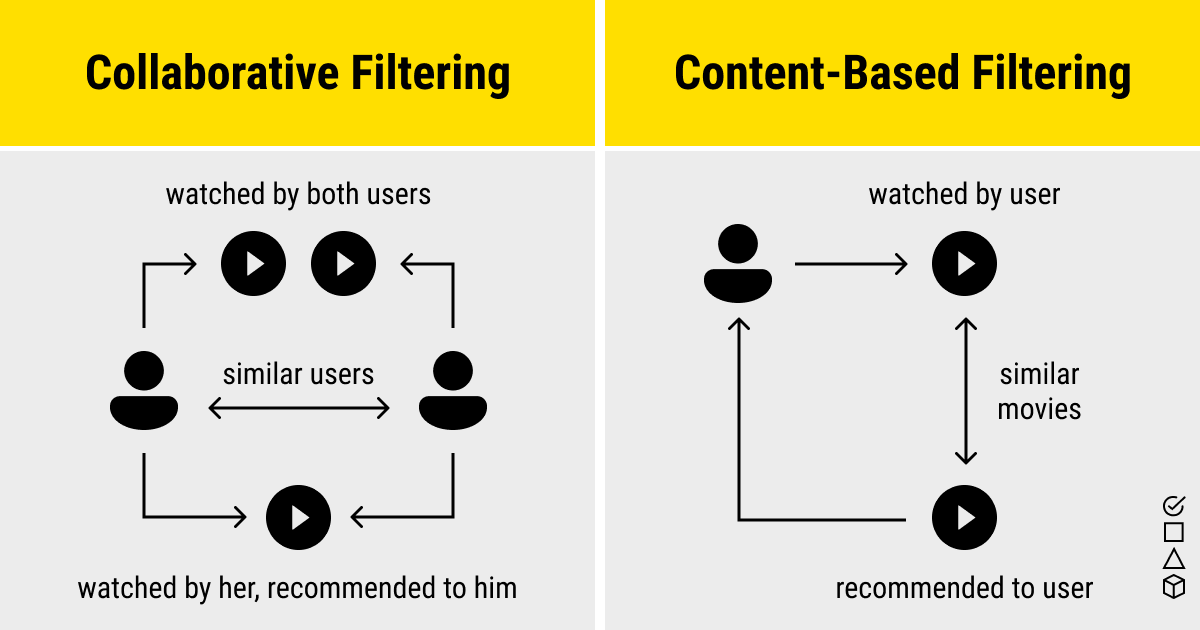
Movie recommendation systems use a set of different filtration strategies and algorithms to help users find the most relevant films. The most popular categories of the ML algorithms used for movie recommendations include content-based filtering and collaborative filtering systems.
Content-Based Filtering
A filtration strategy for movie recommendation systems, which uses the data provided about the items (movies). This data plays a crucial role here and is extracted from only one user. An ML algorithm used for this strategy recommends motion pictures that are similar to the user’s preferences in the past. Therefore, the similarity in content-based filtering is generated by the data about the past film selections and likes by only one user.
How does it work? The recommendation system analyzes the past preferences of the user concerned, and then it uses this information to try to find similar movies. This information is available in the database (e.g., lead actors, director, genre, etc.). After that, the system provides movie recommendations for the user. That said, the core element in content-based filtering is only the data of only one user that is used to make predictions.
Collaborative Filtering
As the name suggests, this filtering strategy is based on the combination of the relevant user’s and other users’ behaviors. The system compares and contrasts these behaviors for the most optimal results. It’s a collaboration of the multiple users’ film preferences and behaviors.
What’s the mechanism behind this strategy? The core element in this movie recommendation system and the ML algorithm it’s built on is the history of all users in the database. Basically, collaborative filtering is based on the interaction of all users in the system with the items (movies). Thus, every user impacts the final outcome of this ML-based recommendation system, while content-based filtering depends strictly on the data from one user for its modeling.
Collaborative filtering algorithms are divided into two categories:
- User-based collaborative filtering. The idea is to look for similar patterns in movie preferences in the target user and other users in the database.
- Item-based collaborative filtering. The basic concept here is to look for similar items (movies) that target users rate or interact with.
The modern approach to the movie recommendation systems implies a mix of both strategies for the most gradual and explicit results.
How to Build a Movie Recommendation System?

Once we’ve discussed the basics of film recommendation engines in machine learning, we can move on to building an actual movie recommendation system. So, we need to build an engine that learns and recognizes patterns in a user’s viewing history before using these patterns to generate new recommendations. What’s required for this?
- Data. ML systems need data, so find and import the essential libraries with movie datasets that already have global ratings.
- Analysis. Create generic recommendations of top-rated movies from the existing dataset.
- Personalization. Get personalized ratings by providing your own movie scores.
- Strategy. Implement content-based or collaborative filtering strategy.
- Combination. Combine recommendation lists to get a reasonable estimate across the ratings. The combined dataset of movie ratings can now be used for either filtering model.
In a nutshell, all it takes to build a movie recommendation engine is to analyze the data, build the recommendation system, and get recommendations. But ML algorithms are a little more complicated than that.
Additionally, LLM fine-tuning can enhance these systems by refining large language models to interpret nuanced language from user reviews and feedback. By fine-tuning these models specifically for recommendation tasks, platforms can better understand and cater to each viewer’s unique tastes, leading to more accurate and satisfying movie suggestions.
How to Create a Neural Network Model in a Movie Recommendation System?

The importance of artificial neural networks (ANNs) has been frequently discussed before when we talked about image classification, speech recognition, and other issues in AI. Neural networks are well-suited to help humans solve problems and challenges in real-life scenarios by improving decision-making processes in different areas. Cinematography is one of them.
In movie recommendation systems, ANNs are particularly helpful and can be used as autoencoders in many sectors. The neural networks use the training data to predict movie recommendations with high accuracy for the target users. Therefore, the most important part is to get the right movie datasets to create a neural network model for movie recommendation systems. Equally important is to make the right manipulations with this data.
A neural network model, in this case, consists of three layers:
- Input. The first layer of a neural network model, where the movie and user vectors are selected as input.
- Embedding. The second layer contains embeddings for both movies and users. They are updated during the model training to get the best values of these embeddings and lower the error rate between actual and predicted values.
- Output. The final third level generates the predicted values and can consist of one or more neurons provided by the user to the movie.
Once a neural network model is created for the movie recommendation system, it’s time to train the model on the training movie dataset and make predictions.
Movie Datasets for Recommendation Systems in ML
Finding proper movie datasets is crucial to mastering the basic ML methods, and give your movie recommendation project a try. The right movie datasets that are most valuable for machine learning projects should contain information on the cast, script, screen time, reviews, plot, etc. Such datasets might be hard to find, so we’ve prepared a list of the most popular movie datasets for machine learning for your convenience:
- MovieLens 25M data set
- IMDB Datasets
- Linguistic Data of 32k Film Subtitles with IMBDb Meta-Data
- Film data set from UCI
- Full MovieLens dataset on Kaggle
- Cornell Film Review Data
- French National Cinema Center datasets
- Movie Industry on Kaggle
- OMDb API
- Movie Body Counts
- Movie datasets on data.world
The Top Movie Recommendation System Use Cases
One can spot the increased use of the recommendation systems on almost every popular streaming service, social media, or e-commerce platform. These include Amazon, YouTube, Netflix, Facebook, to name a few. How do the recommendation systems help different industries provide more personalized experiences to their users? Let’s see how it works, based on the example of popular movie recommendation systems!
Netflix

ML algorithms are the key to personalized service on the most widely used streaming platform, Netflix. Its users know how effortless it is to find the right movie to watch since almost 80% of Netflix users follow the title recommendations offered by its algorithms. What are they, and how do they make this possible?
- Personalized Video Ranking (PVR)
- Top-N Video Ranker
- Trending Now Ranker
- Continue Watching Ranker
- Video-Video Similarity Ranker
As you can see, Netflix employs a number of ranking algorithms, each of which goes through the row generating process. Also, Netflix uses a two-tiered row-based ranking system of titles: within each row and across rows. Aside from ranking the titles, the system chooses what titles to add to the user’s Netflix homepage based on:
- Interactions (viewing history, personal ratings)
- Other users with similar tastes
- Information about the titles (genre, actors, release year, etc.)
To generate movie recommendations as personalized as possible, Netflix also takes into account additional user data, such as when users watch movies, what devices they use to watch them, and how much time they spend watching movies on Netflix. Altogether, this user data is used as inputs that are processed into ML algorithms for Netflix. With these algorithms, it became possible to build complex recommendation systems — a major driving force behind the most popular movie recommendation system project and the most personalized experience on Netflix.
YouTube
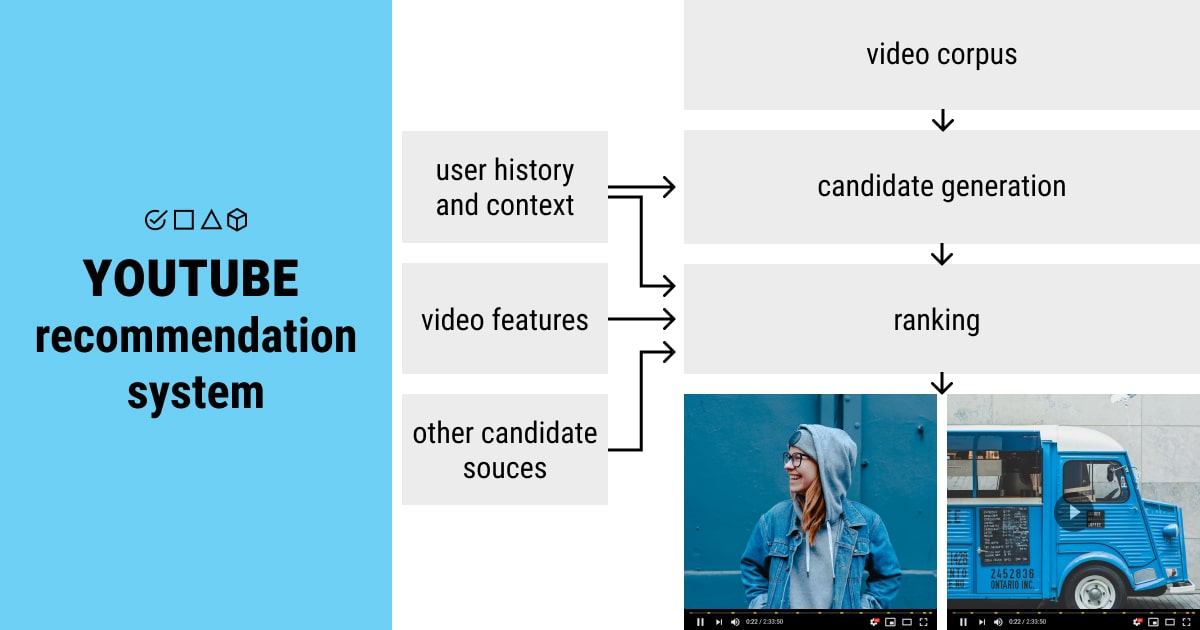
The first thing you see on YouTube is, of course, recommendations that the platform has generated based on your past preferences. While it might seem that all recommendation systems work in the same way, let’s discuss another popular streaming service to prove you otherwise.
How does YouTube’s recommendation system work? The videos are categorized as authoritative or borderline by using ML classifiers. Yet, these categorizations depend on human evaluators who analyze and assess the information in each video. After that, the YouTube system is trained based on these evaluations to model the final decisions and produce credible recommendations across the platform.
YouTube’s network structure consists of:
- Candidate generation network, which leverages the user’s activity history and provides videos most applicable to the user.
- Ranking network, which uses a broader set of features for each video and rates each item from the first network’s output to select top videos for the target user.
An interesting fact: recommendations fuel a significant portion of overall YouTube views, even more than channel subscriptions or searches. This immediately makes the recommendation systems a top priority for developing a responsible and reliable platform for all around the world. The workflow and goals here are a little different from the ones of Netflix.
Recommendations provide YouTube users with filtered information to reduce the chances they come across inappropriate content and misinformation. Besides, the platform has launched a new project to develop a recommendation system respectful of marginalized communities. In other words, fair ML algorithms that power YouTube’s recommendations.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the best movie recommendation system?
There isn’t a single “best” movie recommendation system—it depends on what you’re looking for. Netflix and YouTube, for example, are known for using advanced algorithms that factor in user preferences, viewing history, and similar users to deliver personalized recommendations. If you’re developing a recommendation system and need accurate training data, Label Your Data offers high-quality annotation services to help refine your model.
What does a recommendation system do?
A recommendation system suggests content, like movies or videos, based on what it thinks you’ll enjoy. It considers your past choices and those of other users with similar tastes to make browsing easier and more engaging. Think of it as your personal guide for discovering new content without endless scrolling.
What is a movie recommender using machine learning?
A movie recommender that uses machine learning learns from user behavior and movie data to suggest films you’ll likely enjoy. It analyzes what you’ve watched, rated, or interacted with to predict what you’d want to watch next. With annotation services like those from Label Your Data, it’s possible to enhance this accuracy by training the model with well-annotated, relevant data.
What is a video recommendation system?
A video recommendation system helps you find videos you’ll enjoy by analyzing what you’ve watched and interacted with before. YouTube’s recommendation system, for example, uses machine learning to consider things like your viewing history and similar users’ preferences. It’s all about tailoring your experience and helping you discover more of what you like.
What are the objectives of a movie recommendation system?
The main goal of a movie recommendation system is to make sure you’re seeing movies you’ll want to watch. It’s designed to boost user satisfaction, keep you engaged, and make it easy to find content that fits your tastes. For companies building these systems, working with experts like Label Your Data can ensure that their recommendation models are trained with high-quality, accurately labeled data.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.