Training and Testing Data: How to Split, Use, and Evaluate

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- The gap between a strong test score and a model that survives production is mostly a data-splitting problem, and a few habits keep you on the right side of it.
- Training, validation, and test sets do different jobs, and cross-validation replaces a fixed split when data is scarce.
- Most inflated scores trace back to data leakage, which creeps in when preprocessing happens before the split.
- A test score is only as trustworthy as the data split behind it and the labels inside it.
Training and testing data in machine learning are the two foundations every supervised model rests on, and the way an ML engineer separates them decides whether a reported accuracy number means anything at all.
Below, we cover what separates the two sets, how to split a dataset correctly, where data leakage hides, and how to read evaluation results you can trust.
Training Data vs Test Data: Key Differences
The difference between training and testing data comes down to which data the model learns from and which it is judged on.
AI training data is the portion of a dataset a model studies to set its parameters, and testing data is a held-out portion used once to estimate how the trained model performs on inputs it has never seen:
- The training set shapes the model’s parameters.
- The test set never touches training and exists only to measure generalization.
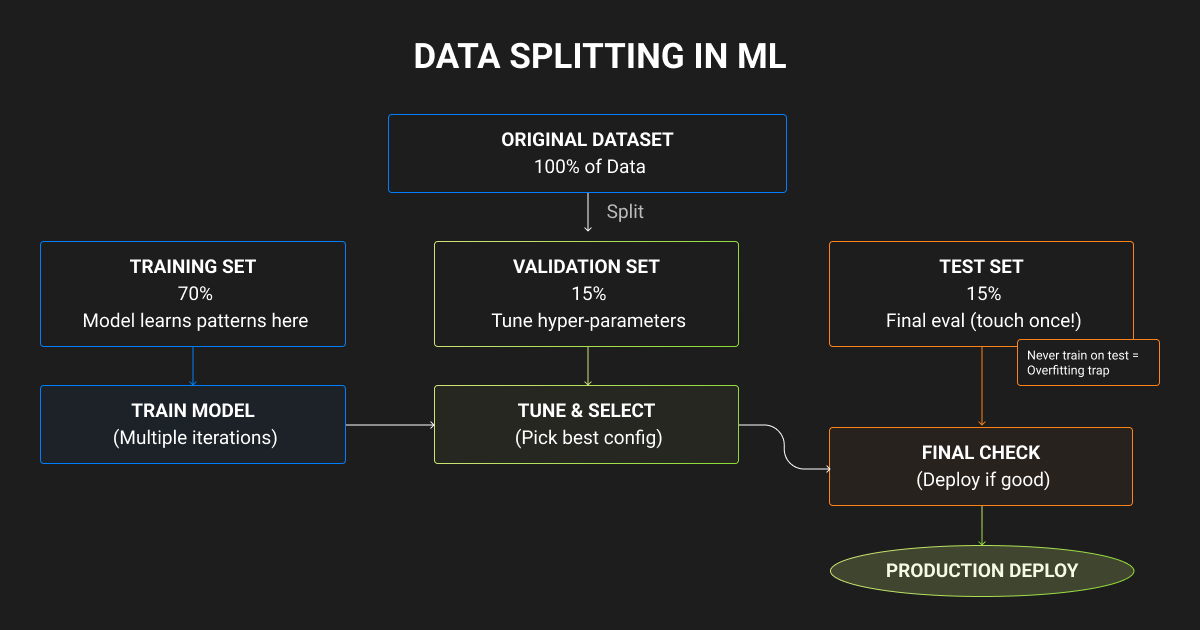
Most production workflows go beyond training data and testing data and split three ways rather than two.
A third subset, the validation set, sits between the other two. The validation vs test set split matters because the validation set absorbs the tuning decisions, which keeps the test set clean for a single final measurement.
Splitting into three parts is generally stronger than two because it isolates the estimate that matters from the decisions an engineer makes along the way. scikit-learn, the widely used Python machine learning library, provides the splitting functions most teams rely on for exactly this purpose.
If hyperparameters are tuned against the test set, the test score stops being an unbiased estimate and starts reflecting choices the engineer made to please that specific data.
What is a validation set used for?

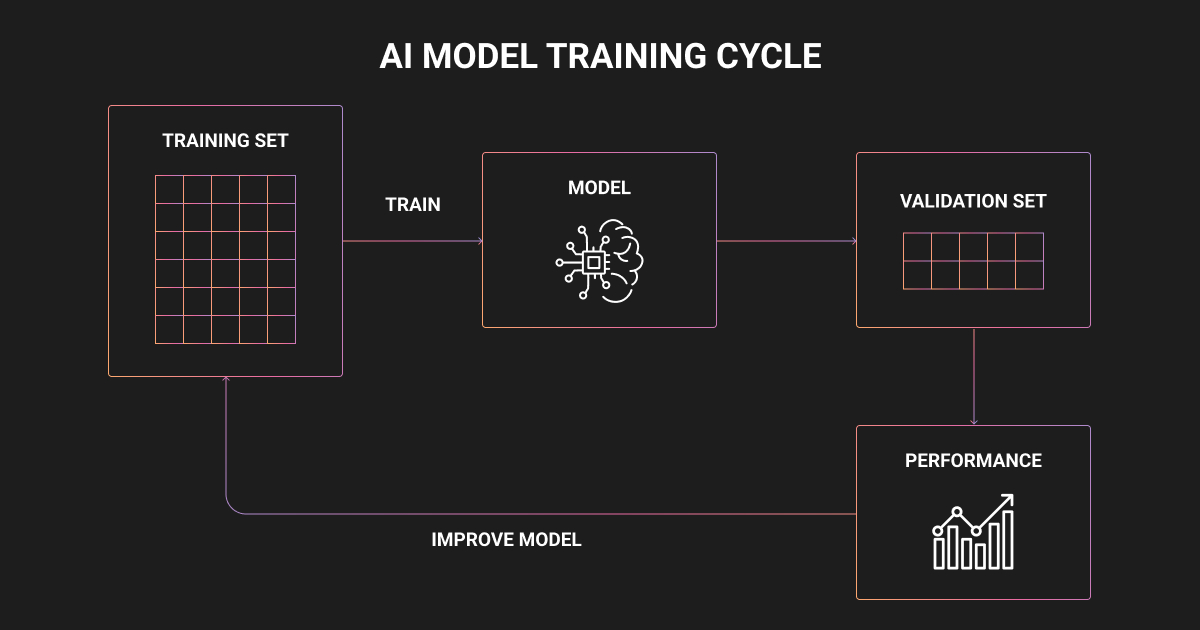
A validation set is the data used to select models and tune hyperparameters before the final test, so the test set stays untouched until the end.
During development you might train several variants, each with different learning rates or architectures, compare them on the validation set, and run only the winner against the test set. Skip this step and there is no clean way to choose between candidates without contaminating the final estimate.
Case in point, a team of PhD researchers from Yale University and the Paris School of Economics, building Random Forest and XGBoost models to detect landfills in satellite imagery, needed their model’s predictions validated across 10,400 coordinates from 16 locations. Label Your Data supplied that validation with a dedicated annotation team and a QA specialist, working through a heavily imbalanced class distribution.
As a result of this collaboration, the Yale team’s models’ AUC rose from a starting range of 82 to 84, reaching 92 for Random Forest and 94 or above for XGBoost.
How to Split Training and Testing Data
A train test split can take several forms.
Common splits are 80/10/10 and 70/15/15, with 60/20/20 also in regular use. The right ratio depends on dataset size, model complexity, and how much data each subset needs to produce a stable estimate.
For very large machine learning datasets the logic inverts: when a corpus holds millions of samples, even 1% is a large, statistically meaningful test set, so splits like 98/1/1 are common and leave the bulk of the data for training. For a simple two-way split, 80/20 remains the default many engineers reach for.
A few principles help when choosing:
- Larger datasets can spare a smaller percentage for validation and testing while still producing reliable estimates.
- The right machine learning algorithm also shapes the ratio, since neural networks usually need more training data than simpler models, pushing it toward 80/10/10 or higher.
- Smaller datasets often favor cross-validation over a single fixed split, because every record is scarce.
- Always shuffle before a random split unless the data has temporal or grouped structure that shuffling would break.
When to use cross-validation
Cross-validation is the better choice when data is limited, because it uses every record for both training and evaluation across multiple rounds.
The most common form is k-fold cross-validation, which divides the data into k equal folds, trains on k-1 of them, and tests on the remaining fold, repeating until each fold has served as the test fold once.
The payoff is a more stable performance estimate. Instead of one score that depends on a single lucky or unlucky split, you get k scores and report their average, which smooths out the variance a small dataset introduces.
A held-out test set is still kept separate for the final check, with cross-validation run inside the training portion for tuning.
Data Leakage Risks When Splitting Data
Leakage blurs the line between testing and training data, letting information that would not be available at prediction time reach the model during training, which inflates evaluation scores and breaks performance in production.
It is one of the most common reasons a strong test result fails to hold up.
Leakage takes three recurring forms:
- Target leakage occurs when a feature encodes the outcome itself, such as a “repayment_status” field used to predict loan repayment, information the model would not have at the moment of prediction.
- Train-test contamination occurs when preprocessing is fit on the full dataset before splitting, so scaling or imputation statistics carry knowledge of the test set into training.
- Temporal leakage occurs when a model trains on data from after the prediction point, which a random split on time-series data quietly causes.
In computer vision, near-duplicate images split across train and test sets let the model memorize specific pictures, inflating the test score. The same risk appears when multiple records from one person or device land in different subsets.
To prevent it, split before any scaling, imputation, or feature engineering, then fit every transformation on the training set alone. Keep all records from one entity in a single split, and for time-series data, replace random splitting with a time-based cutoff that trains on the past and tests on the future.
Splitting Methods for Imbalanced and Time-Series Data
Data splitting works best when the method matches the structure of the data rather than defaulting to a random shuffle every time.
Random sampling works well only when classes are balanced and records are independent, which production datasets often are not. Three structures come up most often, and each calls for a different split:
| Data structure | Splitting method | What it prevents |
| Imbalanced classes | Stratified sampling | A minority class vanishing from the test set |
| Grouped data, where one subject contributes many rows | Group-based split | The model being tested on a subject it trained on |
| Time-ordered data | Chronological split | The model training on data from after the prediction point |
These choices matter most exactly where models earn their keep, and getting them right often starts with how the data was labeled, which is where reliable data annotation services pay off.
One study on medical image processing using the BraTS dataset tested split ratios from 60:40 to 95:05 and found accuracy varied measurably across them, with different model types favoring different balances.
The split ratio behaves like a hyperparameter, so test a few on your own data and measure the variance before settling on one.
How to Evaluate a Model on the Test Set
Run the final model against the test set once, after all tuning is complete, and report the metrics that match the task. Touching the test set repeatedly turns it into a second validation set and destroys the unbiased estimate it exists to provide.
Pick a metric that matches the problem
Accuracy is misleading on imbalanced data, where a model that always predicts the majority class can post a high score while being useless. The right metric depends on what an error costs you.
| Metric | Use it when |
| Precision | False positives are costly |
| Recall | Missed positives are costly |
| F1 | You need to balance precision and recall |
| ROC AUC | You care about ranking across thresholds |
Check the labels before you trust the score
A clean split stops leakage, but it can't rescue wrong labels. If the ground truth in the test set is incorrect, a right prediction is scored as wrong and a weak model can look polished, so the result is only as honest as the labels inside it.
Even frontier models show this. In LLM research, benchmark contamination, where test items leak into the training corpus, inflates scores by rewarding memorization. During the GPT-3 evaluation, over 90% of examples in some benchmarks were flagged as potentially contaminated.
Label quality is what closes the gap. Consistent data annotation across the full dataset, including the test set, is what lets a score describe the model instead of the mistakes in the data.
Label Your Data is a data annotation company that delivers training and evaluation data with structured quality assurance built to hold accuracy steady as datasets scale into the millions of records.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies successfully scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is training and testing data?
Training data is the portion of a dataset a model learns from, adjusting its parameters to fit the examples. Testing data is a separate, held-out portion the model never sees during training, used once at the end to measure how well it generalizes to new inputs.
What are the three types of data splits?
In machine learning, the three working subsets are the training set (used to fit the model), the validation set (used to tune hyperparameters and compare models), and the test set (used once for a final, unbiased performance estimate). The validation and test sets are the two that hold out data the model does not train on.
What are examples of training data?
Training data takes whatever form the task requires: labeled images for object detection, transcribed audio for speech recognition, tagged text for sentiment analysis, satellite coordinates marked as landfill or not, or rows of customer records with a known outcome. Each example pairs an input with the correct answer the model learns to predict.
Does train test split actually include validation?
No. scikit-learn’s “train_test_split” produces only two subsets per call. To get a three-way split, run it twice: first separate the test set, then split the remaining data into training and validation. Some workflows skip a fixed validation set entirely and use cross-validation on the training portion instead.
When to use train test split?
Use a single train test split when you have enough data that one held-out set gives a stable estimate, typically thousands of records or more. With smaller datasets, a single split wastes scarce data and the score depends heavily on which rows happen to land in the test set, so cross-validation is the better choice.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.