Machine Learning: The Engineer’s Ultimate Handbook 2026

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- AI Machine Learning, Defined for Engineering Teams
- Core Types of Machine Learning (and When to Use Each)
- How Does Machine Learning Work: From Data to Deployment
- Machine Learning Algorithms Engineers Actually Use
- Evaluating Machine Learning Models: Metrics and Tests
- Data Quality, Bias, and Human-in-the-Loop
- MLOps Fundamentals for Stable Machine Learning Systems
- Applied Machine Learning: High-Impact Use Cases
- Choosing the Right Machine Learning Stack
- Challenges in Machine Learning Projects (and How Teams Solve Them)
- The Role of Annotated Data Quality in Machine Learning
- What’s Next in Machine Learning: 2026 and Beyond
- About Label Your Data
- FAQ

TL;DR
- Machine learning systems turn data into predictions via trained models, but real-world reliability depends on the full pipeline: from data sourcing to deployment.
- Engineering teams must optimize not just for model accuracy, but for stability, retraining loops, and operational cost across ML infrastructure.
- Choosing the right ML type, algorithm, and deployment pattern depends on the problem, available data, and production constraints like latency or compliance.
- Most ML failures stem from upstream data issues like label noise, drift, or poor coverage, not model choice.
- Data quality and annotation frameworks are critical to long-term model performance.
AI Machine Learning, Defined for Engineering Teams
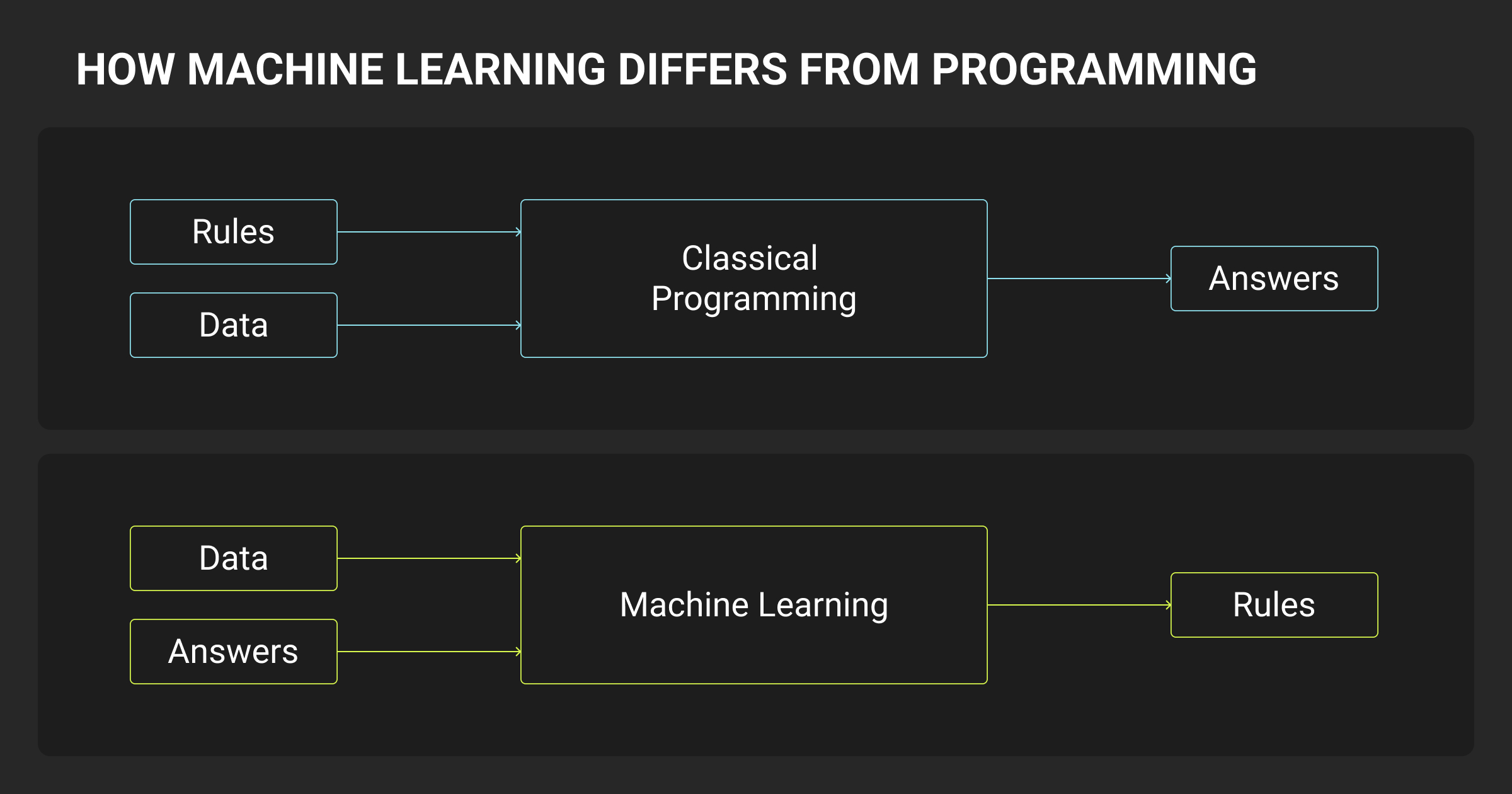
Machine learning (ML) is the practice of teaching machines to make predictions or decisions based on data. Instead of writing explicit rules, engineers provide examples (structured as inputs and outputs) and train models that generalize to new, unseen data.

Machine learning is a critical part of infrastructure across fraud detection, search ranking, personalization, forecasting, and multimodal AI. Unlike traditional software systems that follow fixed instructions, ML models evolve as new data is ingested, requiring engineers to build for data volatility, evaluation drift, and probabilistic failure modes.
At its core, AI machine learning solutions consist of three parts:
- Input data: features or raw signals used to train and evaluate models
- Model: a statistical structure (linear model, tree, neural net) that maps inputs to outputs
- Inference: the process of making predictions with a trained model in production
For engineers, the real challenge is making these components reliable at scale. This implies handling noisy data, building pipelines that don’t break with schema drift, monitoring for performance decay, and aligning predictions with business value.
Core Types of Machine Learning (and When to Use Each)
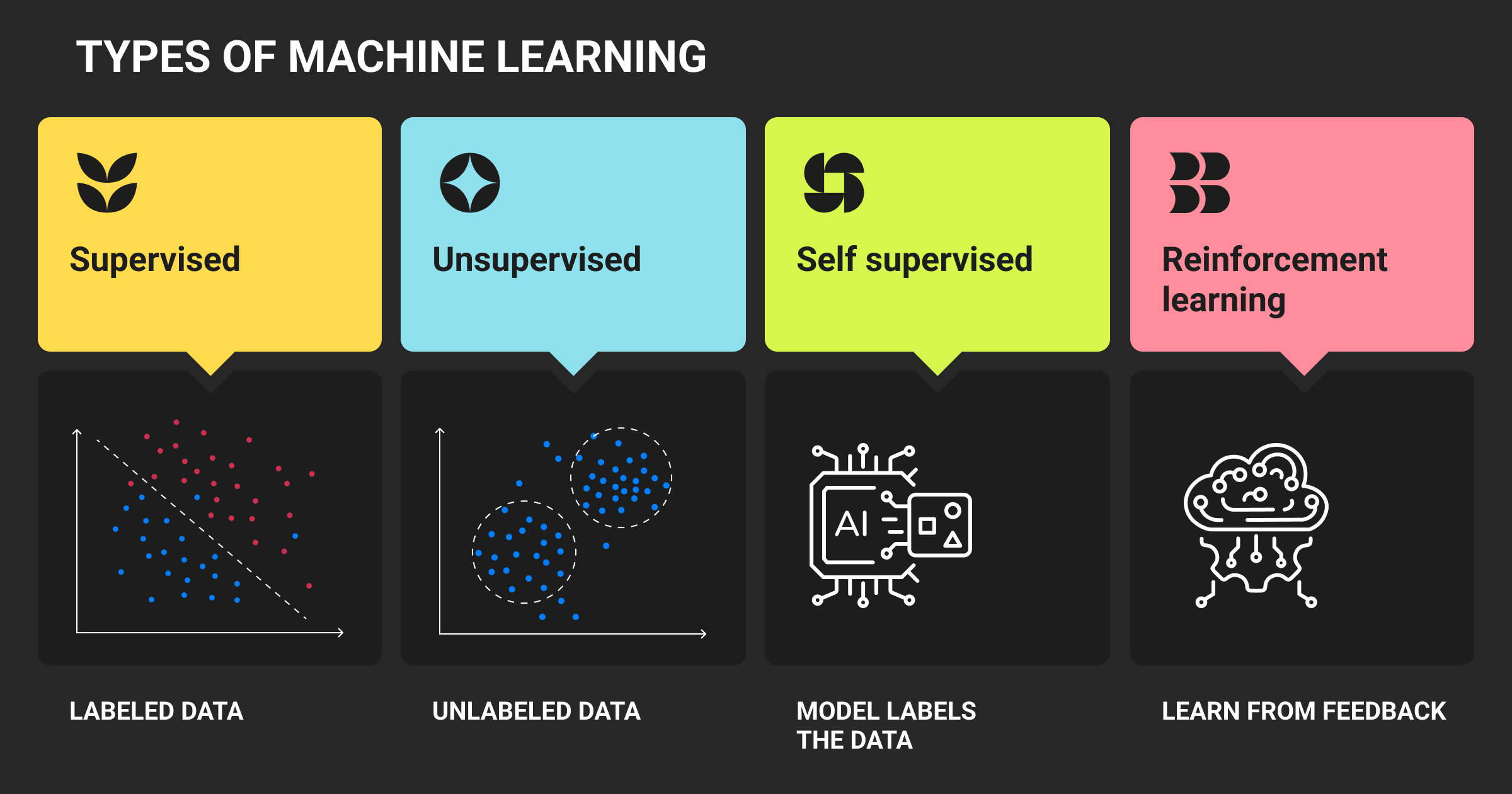
Not all AI and machine learning is built the same. The type of learning you choose depends on your data, your problem type, and how success is defined. Below is a breakdown of supervised vs. unsupervised learning, along with other ML categories used in production.
Supervised machine learning
Supervised learning is used when you have labeled input-output pairs and want to predict outcomes. Classification models sort inputs into discrete categories (e.g., spam detection), while regression predicts continuous values (e.g., demand forecasting). Most business ML starts here.
Use it when:
- You have historical ground truth data
- Business logic maps cleanly to a prediction target
- You need interpretable or deployable models quickly
Common challenges: label imbalance, leakage between train/test splits, and overfitting on noisy features.
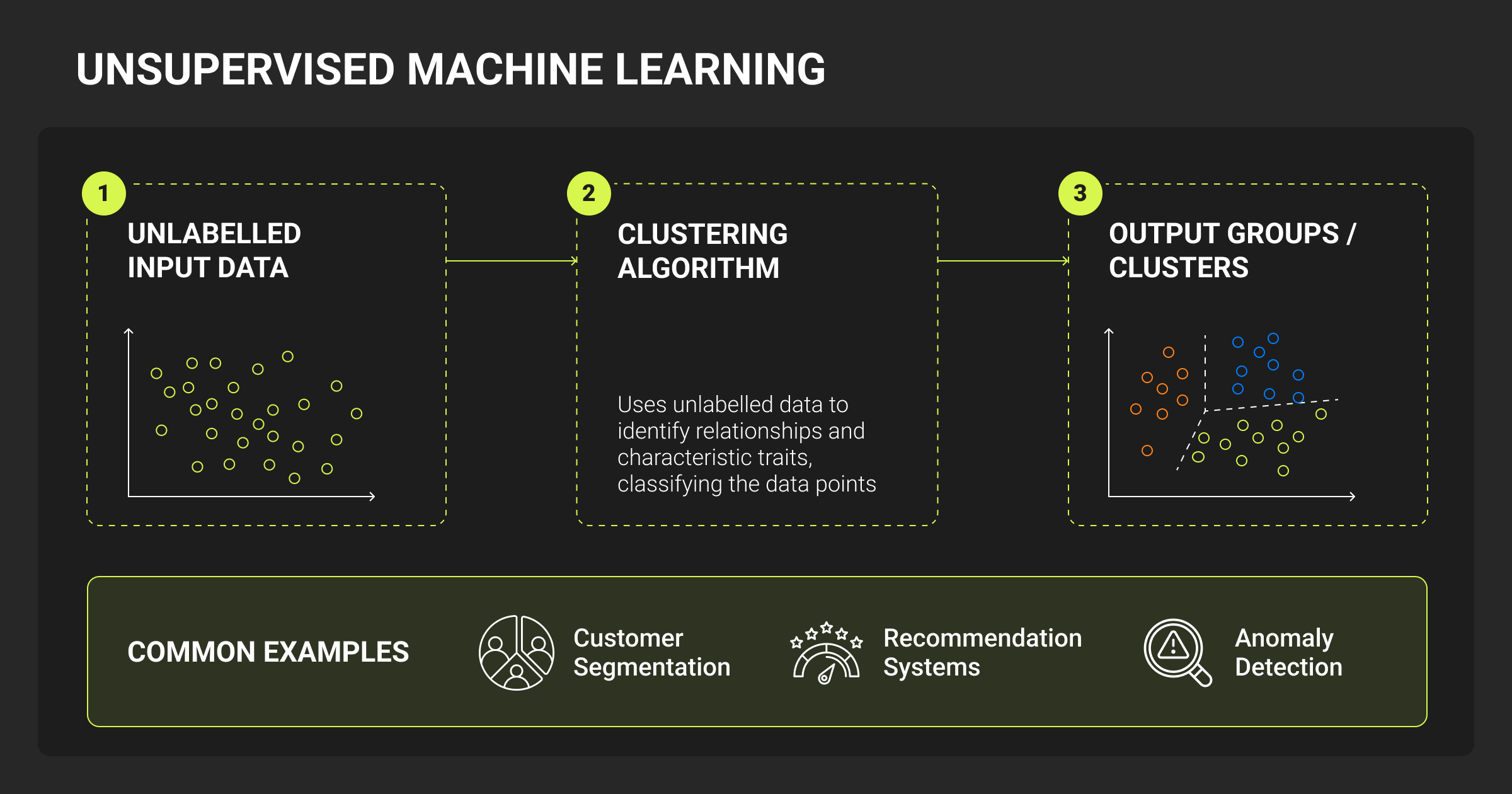
Unsupervised machine learning
Unsupervised methods find patterns without labeled outputs. Clustering groups similar instances (e.g., customer segmentation), while dimensionality reduction techniques like PCA or t-SNE help visualize or compress data.
Use it when:
- Labels are expensive or unavailable
- You want to explore structure or compress high-dimensional inputs
- The task is exploratory or preprocessing-focused
Evaluation can be tricky: no labels means you measure cluster separation or reconstruction error, not accuracy.
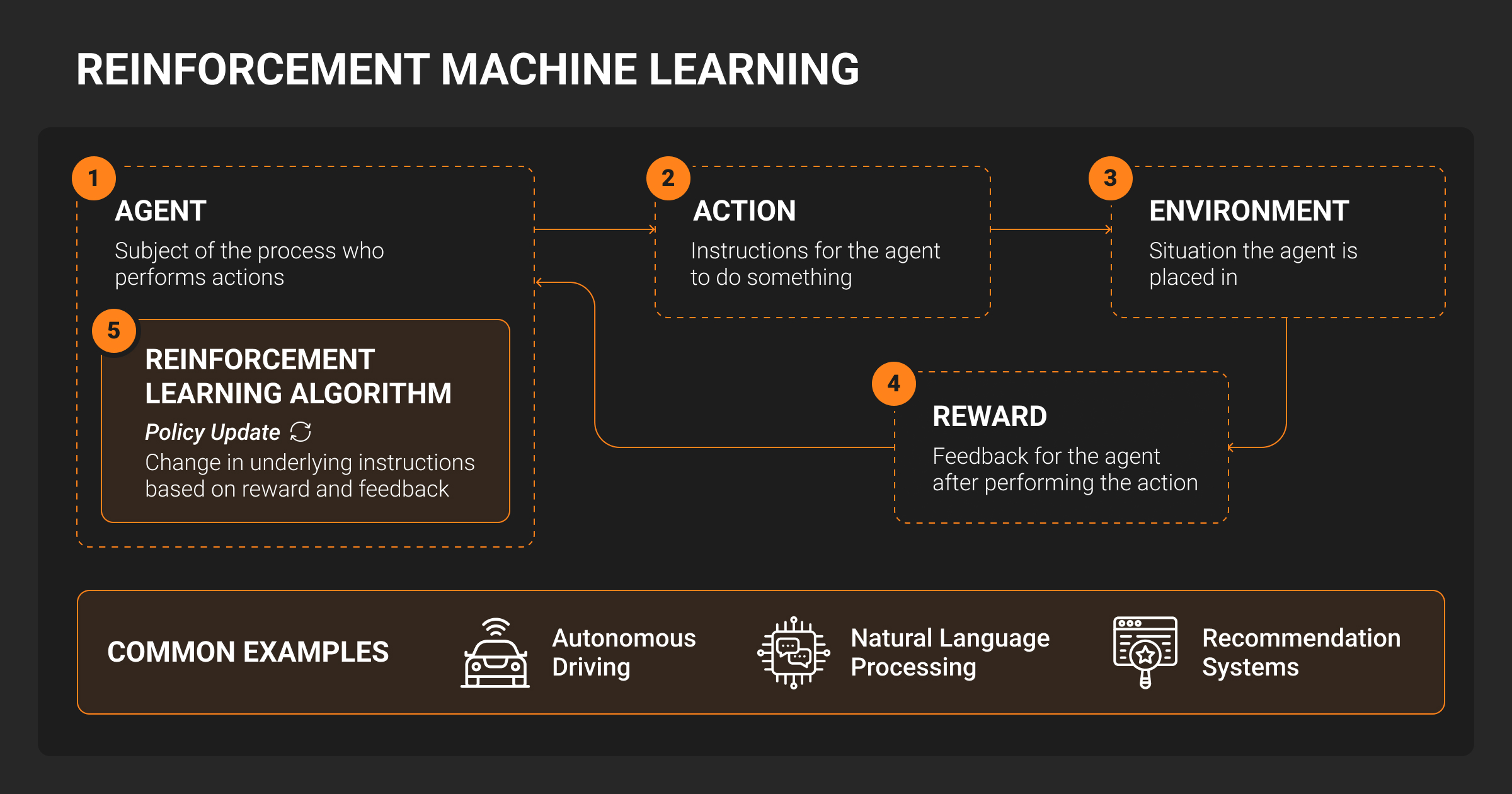
Reinforcement machine learning
Reinforcement learning (RL) trains agents to take actions in an environment by maximizing long-term reward. Think robotics, recommendation engines, or autonomous control systems.
Use it when:
- Actions influence future state (non-i.i.d. setups)
- You can simulate or log interaction data
- You care about sequential decision-making, not static predictions
RL is powerful but brittle: sensitive to hyperparameters, reward shaping, and environment dynamics. Most teams start with off-policy learning or bandits before scaling to full RL.
Semi- & self-supervised machine learning
These approaches make use of large unlabeled datasets with minimal manual labeling. Self-supervised learning uses proxy tasks (like masked language modeling) to pretrain models, which are later fine-tuned. Semi-supervised learning combines small labeled sets with large unlabeled ones.
Use them when:
- You have more data than labels
- You want foundation models or strong encoders
- You plan to fine-tune on downstream tasks
These methods are foundational for modern ML pipelines, especially in computer vision and NLP, where labeled data is expensive. They’re also essential in training types of LLMs and multimodal models.
How Does Machine Learning Work: From Data to Deployment
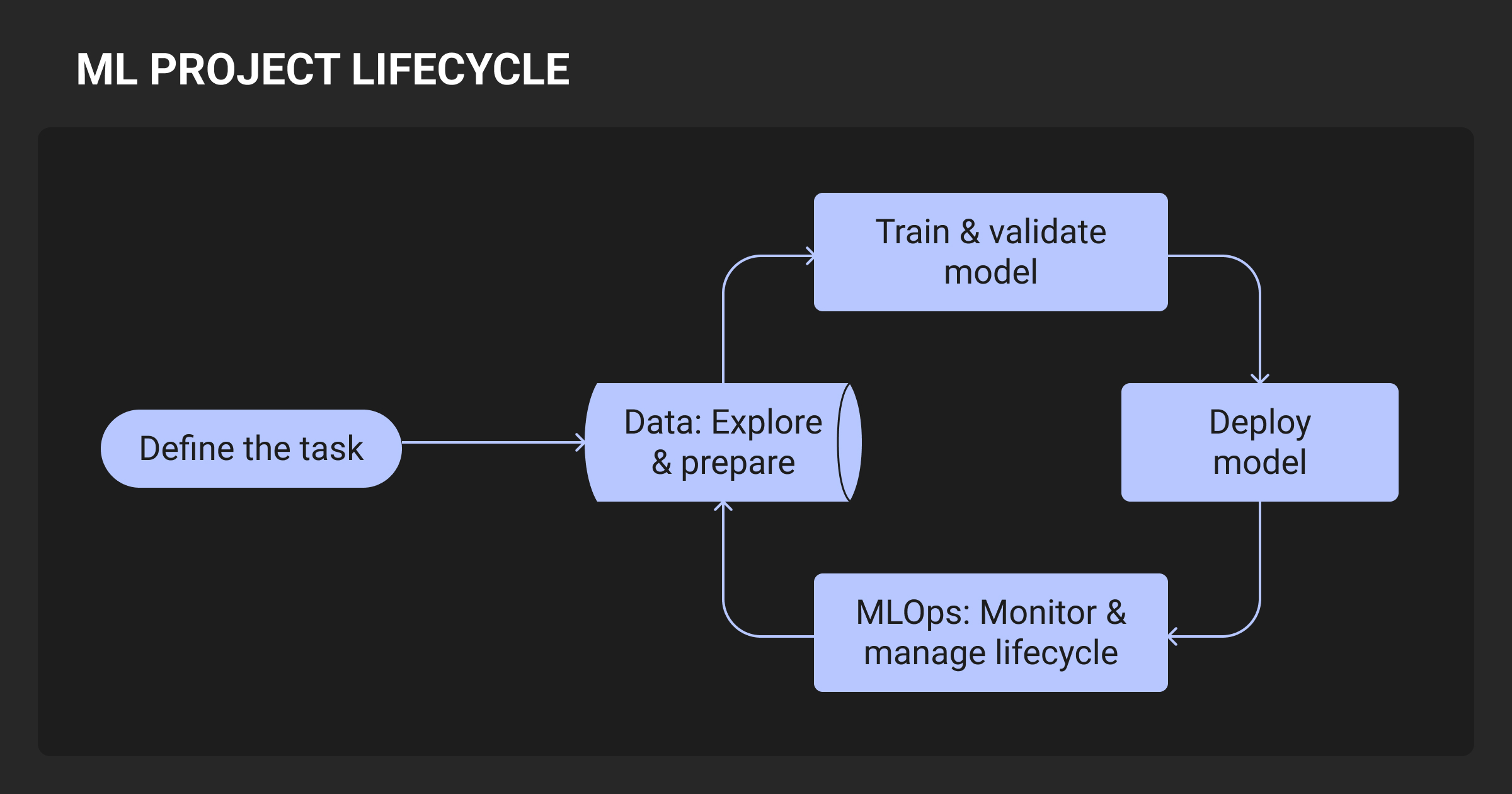
Your goal is to build an AI machine learning system that transforms raw data into repeatable predictions. The stages are tightly coupled, and failure in one often cascades. Below is what a robust ML pipeline looks like in real-world systems.
Data sourcing, governance, and privacy
ML starts with data, but not just any data. It must be relevant, representative, and legal to use.
Sourcing
Data can come from internal logs, third-party APIs, user interactions, or public information sets used in machine learning. Always verify that your data reflects the real-world population you want to model. Poor sampling leads to poor generalization.
Governance
Engineers must track data lineage, enforce access controls (RBAC), and use tools like DVC or lakeFS for data versioning. Without governance, debugging and auditing are impossible at scale.
Privacy
Regulations like GDPR or HIPAA are obligatory. Use techniques like encryption, consent tracking, federated learning, or synthetic data when working with sensitive data.
Data preprocessing and feature engineering
Raw data needs transformation before machine learning models can consume it.
Preprocessing
Handle missing values, normalize features, encode categoricals (e.g. one-hot, label encoding), and validate schemas. Use tools like Great Expectations or TensorFlow Data Validation to automate this step.
Feature engineering
Injects domain knowledge. For example, from timestamps → “hour of day,” from GPS → “distance traveled.” Features often matter more than the model. Ensure consistent feature generation between training and inference to avoid skew. Feature stores like Feast or Michelangelo help manage this.
Annotation and QA (human-in-the-loop)
For supervised learning, good labels are everything. That’s also been the core focus at Label Your Data as we’ve been helping ML teams get reliable, high-quality training data through a combination of expert annotators, QA frameworks, and human-in-the-loop workflows since 2020.
Data annotation
Use hybrid systems: automation for speed, human annotation for precision. Label Your Data, Label Studio, Snorkel, and Scale AI are common tools. For complex tasks, use trained annotators or SMEs.
Quality assurance
Multiple annotators, adjudication, and consensus help reduce noise. Even post-deployment, you can loop human feedback into retraining. Never treat labels as absolute truth, verify them like you would model outputs.
Training, validation, and experiment tracking
This is the core loop: fit models, evaluate, and iterate.
Training
Try multiple model types, tune hyperparameters, and watch for leakage. Use cross-validation and ensure your test data reflects real-world deployment.
Experiment tracking
Use MLflow, W&B, or your own system. Track code, data version, metrics, and environment to guarantee reproducibility.
Deployment patterns
How you serve models depends on latency and compute constraints.
- Batch: Good for non-urgent use cases (e.g. nightly churn predictions)
- Online: Use FastAPI, TensorFlow Serving, or TorchServe. You’ll need load balancing and caching
- Edge: Quantized models run on phones or IoT sensors; prioritize minimal latency and high privacy
Monitoring, drift, and retraining loops
Machine learning models need ongoing care: without drift detection and retraining, performance quietly degrades.
Monitoring
Track input distribution, output scores, and data schema. Tools like Evidently, Arize, or Seldon can help.
Drift detection
Detect covariate or concept drift early. Use statistical tests (e.g. KS, Chi-square) to catch shifts before performance drops.
Retraining
Automate it when possible. Set thresholds for triggering new training cycles and store all model artifacts for rollback if needed.
Business leaders treat ML like a black box, but it only works if you start with clean data, solid labeling, and consistent feature engineering. The real challenge is monitoring. Most teams ignore drift until accuracy collapses. Reliable systems need retraining pipelines, fallbacks, versioning, and alerts long before deployment fails.

 CTO / Software Engineer, AlgoCademy
CTO / Software Engineer, AlgoCademy
Machine Learning Algorithms Engineers Actually Use
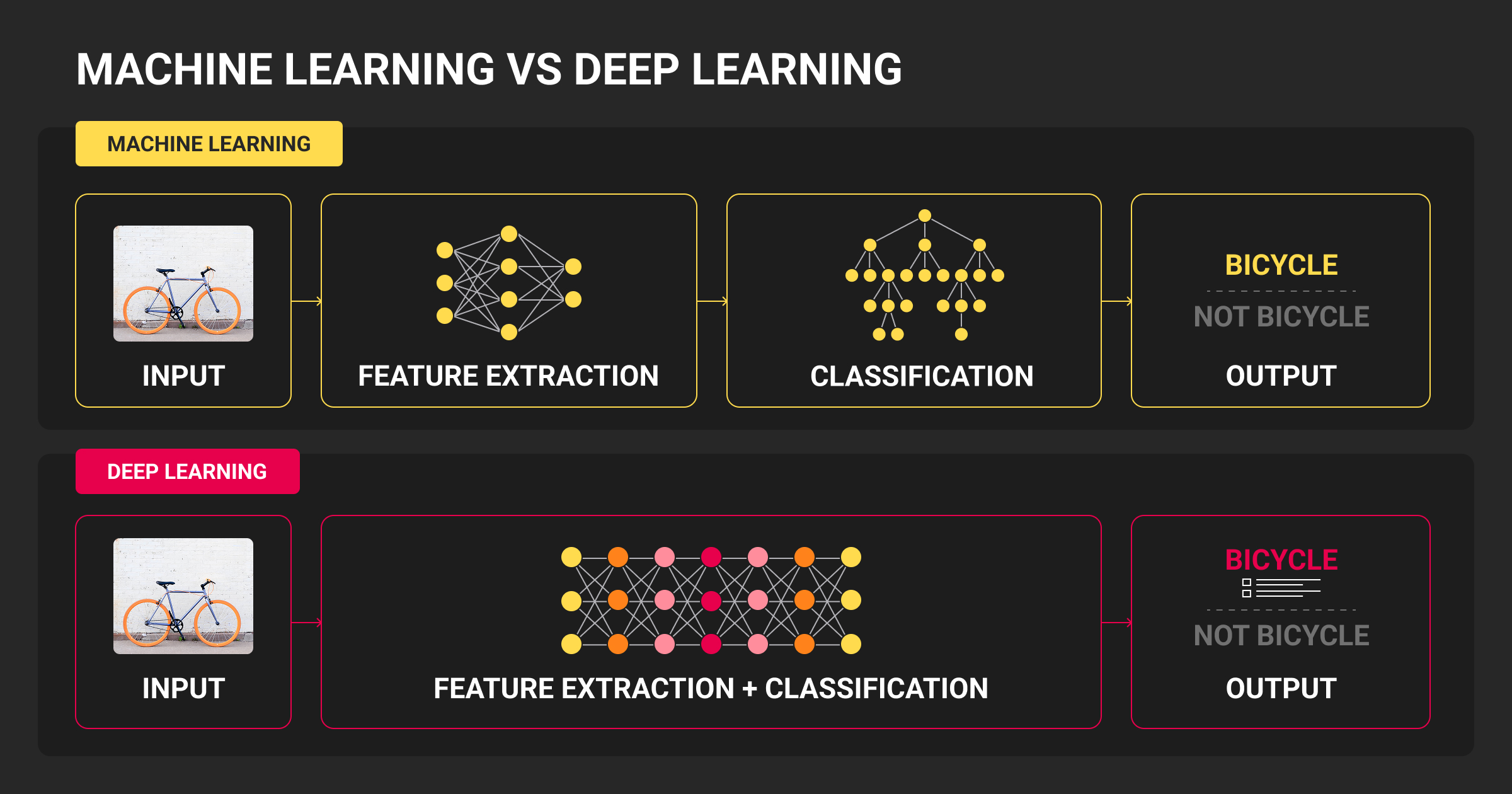
Choosing the right algorithm depends on the problem type, data size, resource constraints, and interpretability needs. This section outlines the core families of machine learning algorithms that engineering teams deploy.
Understanding when to use linear models versus deep neural networks (deep learning vs machine learning) is crucial for building scalable and reliable pipelines.
Linear and logistic models
Linear regression and logistic regression remain the go-to baseline models for many tasks. They’re fast, interpretable, and surprisingly strong when features are well engineered.
- Best for: tabular data, quick iteration, problems needing explainability
- Strengths: low variance, fast training, easy to debug
- Watch for: underfitting on complex patterns, multicollinearity
In real-world ML systems, linear/logistic models often serve as first-line baselines to test pipeline health and data assumptions before deploying more complex architectures.
Trees and ensembles
Tree-based models dominate structured-data ML tasks, especially gradient boosting frameworks like XGBoost and LightGBM. They handle non-linearities and interactions without manual feature engineering.
- Best for: tabular datasets, structured business data, ranking tasks
- Strengths: minimal preprocessing, strong performance out of the box
- Watch for: overfitting (especially Random Forest), longer training times on large datasets
These are the default for many Kaggle winners and production teams working with large-scale transactional or behavioral data.
SVM and k-NN
Support Vector Machines and k-Nearest Neighbors are legacy models that still shine in niche domains.
- SVMs: excellent for text classification, smaller datasets, or high-dimensional data
- k-NN: useful in recommendation systems, fast prototyping, or explainable nearest-neighbor search
Both struggle to scale to millions of samples and are generally replaced by more scalable methods in large deployments.
Deep learning
Deep learning is essential for unstructured data like images, audio, video, and natural language. Engineers typically use:
- CNNs for image recognition, segmentation, OCR, and visual search
- RNNs/LSTMs for time series, speech, and sequential modeling
- Transformers (BERT, ViT, etc.) for modern NLP and vision tasks
Today, pre-trained models and transfer learning (e.g. CLIP, SAM, Whisper) often replace training from scratch, while also reducing compute cost and data requirements.
Foundation machine learning models and adaptation paths
Large pre-trained models (e.g. LLMs, LMMs) are becoming the new foundation layer for many ML systems. Engineers increasingly choose between:
- Prompting: light, fast iteration, great for exploration
- RAG (Retrieval-Augmented Generation): when grounding to a custom knowledge base is needed
- LLM fine tuning: for domain-specific reasoning or safety-critical outputs
- SLMs: smaller language models offering better latency and cost efficiency
Use cases range from virtual assistants to multimodal document understanding, and the right adaptation path depends on latency, context size, and compute budget.
Evaluating Machine Learning Models: Metrics and Tests
ML engineers need to align metrics with business goals and failure tolerances. A model that performs well in the lab but fails unpredictably in real-world edge cases can create more risk than value.
This section breaks down core evaluation strategies by task type and highlights diagnostic techniques to improve reliability.
Classification metrics
For tasks like fraud detection or medical diagnosis, you often care about precision (avoiding false positives) and recall (catching all positives), not just accuracy.
- Precision = TP / (TP + FP)
- Recall = TP / (TP + FN)
- F1 Score: Harmonic mean of precision and recall
- ROC-AUC: Area under curve of TPR vs FPR across thresholds
- PR-AUC: Better for imbalanced datasets
Use PR-AUC when positives are rare (e.g. spam detection), and F1 when false positives and false negatives are both costly.
Regression metrics
For continuous predictions (e.g. demand forecasting, time-to-event):
- MAE (Mean Absolute Error): easy to interpret; linear penalty
- MSE / RMSE (Root Mean Square Error): penalizes large errors more
- MAPE (Mean Absolute Percentage Error): scale-independent but undefined at zero
- R² (Coefficient of Determination): proportion of variance explained
When business impact increases non-linearly with error size (e.g. understocking vs overstocking), RMSE may be more appropriate than MAE.
Ranking & retrieval metrics
For tasks like search engines, recommenders, or document retrieval:
- mAP (mean Average Precision): average precision across ranked results
- nDCG (Normalized Discounted Cumulative Gain): accounts for position of relevant items
- Recall@K / Precision@K: what fraction of top-K results are relevant
These metrics matter most when the order of outputs affects user experience or decision-making.
Robustness and reliability tests
Even machine learning models with good validation scores can fail under real-world pressure. Include:
- Cross-validation: especially for small datasets
- Stress tests: e.g., performance on adversarial/noisy inputs
- Ablation studies: remove features or modules to assess contribution
- Calibration checks: do predicted probabilities reflect real-world likelihoods?
The best ML model is the one whose failures you understand and can monitor.
Data Quality, Bias, and Human-in-the-Loop
Model performance depends less on clever architecture and more on what goes into training. In real-world ML systems, poor data quality (i.e., mislabeled samples, skewed distributions, missing edge cases) remains the top cause of model failure.
That’s why debugging datasets, not just model code, has become a key engineering focus.
Label noise, drift, and coverage gaps
Even small label errors can compound during training. In medical imaging or sentiment analysis, a few mislabeled examples can shift decision boundaries and reduce trust. You also need to monitor data drift, when new inputs differ from the training distribution, and check whether your dataset covers enough real-world scenarios.
This is where structured QA matters. For such cases, we at Label Your Data use label validation checks, annotator disagreement scores, and spot audits to detect silent failures early.
Bias and fairness checks
Machine learning models often reflect social and systemic ML biases hidden in training data. For instance, a voice model trained only on US English accents may underperform for global users.
Fairness audits should include subgroup performance metrics, balanced datasets, and policy-aligned labeling rules (e.g., hate speech, facial recognition). You want consistent performance across the demographics that matter.
Human evaluation and feedback loops
Automated metrics can’t catch every failure. Engineers still rely on human-in-the-loop evaluations for edge cases, nuanced reasoning, and subjective tasks. Reinforcement Learning from Human Feedback (RLHF) and newer variants like RLAIF are now standard for tuning LLMs and vision-language models. Outside of LLMs, classic human evaluation loops include:
- Gold sets for regression testing
- Crowdsourced QA for post-labeling review
- Internal SMEs to spot-check ambiguous or failed cases
Many teams maintain “gold sets.” They are high-trust test examples labeled by domain experts to benchmark model behavior before and after deployment.
Why clean data beats bigger machine learning models
Investing in high-quality labels and clean data pipelines often improves downstream accuracy more than adding model parameters. Instead of chasing marginal model gains, debugging mislabeled, duplicated, or unbalanced data gives you faster, cheaper wins, while also improving generalization.
MLOps Fundamentals for Stable Machine Learning Systems
In production ML systems, failure modes often stem from fragile pipelines, silent data drift, or deployment mismatches. Here, we break down the core building blocks of MLOps that allow teams to ship ML features continuously and recover gracefully when things break.
Data versioning
You can't debug what you can't reproduce. ML teams must version not just code, but also:
- Raw and processed datasets
- Model checkpoints and training configs
- Feature engineering code and outputs
Tools like DVC, Weights & Biases, and MLflow help snapshot the full pipeline state. For machine learning datasets, many teams store hashes or metadata to track exact input versions, even when using large lakehouses.
Model versioning ties directly into rollback workflows. Each production model should have a unique identifier, associated evaluation metrics, and retraining lineage so that when performance drops, you know what changed.
Engineer tip: Treat each experiment as a reproducible artifact. Even baseline models should be fully versioned.
Feature stores and inference infrastructure
A key MLOps challenge is feature leakage and training-serving skew. That’s why many production teams use feature stores. They are centralized systems that standardize feature generation for both training and inference.
Feature stores manage:
- Online/offline feature consistency
- Feature freshness guarantees
- Versioned transformation logic
For inference, infrastructure varies by latency and scale:
- Batch inference for scoring datasets in chunks (e.g., churn scoring)
- Online inference APIs for real-time predictions (e.g., ranking, personalization)
- Edge inference where models run on-device (e.g., mobile, IoT)
Inference infra must be monitored like any service: latency, uptime, and output integrity are critical SLAs.
Model monitoring
Most model failures come from silent changes in input data or real-world distributions. Monitoring must go beyond uptime to cover:
- Prediction quality (e.g., real-time accuracy proxies, business metric correlation)
- Input data drift (e.g., feature distribution shift, out-of-domain inputs)
- Label drift (e.g., if ground truth updates, like fraud patterns)
- Concept drift (e.g., when relationships between features and labels change)
Safety monitoring includes:
- Toxicity/harmful output detection
- Detection of rare/outlier inputs
- Uncertainty estimation or abstention logic
Pro tip: Always compare online model predictions against shadow models or gold-labeled slices. It’s your early warning system.
Rollbacks, canaries, and A/B tests
MLOps deployment is risky. A single model update can degrade performance in unexpected ways, especially across long-tail inputs. That’s why teams adopt staged rollout strategies:
- Canary deploys: Release to a small % of traffic, monitor metrics
- A/B tests: Run multiple models in parallel, compare real-world impact
- Shadow mode: Serve new model passively, compare predictions to current version
If issues arise, a rollback must be fast, safe, and complete: model, dependencies, and feature pipelines Use gated deploy workflows where a model must meet performance, latency, and safety thresholds before promotion.
People think an ML model is the finished product. It almost never is. Building Superpencil taught me that 70% of the work is everything around the model: data checks, quality control pipelines, validation logic. You have to plan for human-in-the-loop checks and strong infrastructure from day one. Launching is just the start.
 CEO and Head of Research, Superpencil (Enlighten Animation Labs)
CEO and Head of Research, Superpencil (Enlighten Animation Labs)
Applied Machine Learning: High-Impact Use Cases
Each domain applies AI machine learning differently. Below are real-world ML use cases where engineering constraints matter as much as model choice.
Computer vision
Used for image classification, object detection, segmentation machine learning, OCR, and more, from autonomous vehicles to medical imaging to retail.
| Task | Common Models | Constraints |
| Object detection | Faster R-CNN, YOLOv5 | Real-time inference (e.g. AVs) |
| Image classification | ResNet, EfficientNet | Accuracy vs. latency |
| Panoptic segmentation | Mask R-CNN, SAM | Detailed boundaries + class labels |
| OCR | CRNNs, TrOCR | Robustness to noise, fonts, rotation |
Labeling is often the bottleneck, especially for dense or multilabel CV tasks. Auto-labeling combined with human QA pipelines are now standard.
Natural Language Processing (NLP) and LLMs
From customer support bots to legal doc summarization, NLP tasks are now largely LLM-driven.
| Task | Example | Constraint |
| Retrieval-Augmented Generation (RAG) | Internal QA systems | Accuracy, citation grounding |
| Classification | Toxic content filtering | Precision > recall in high-risk cases |
| Entity extraction | Contract parsing | Must handle messy formats |
| Translation/summarization | Legal, healthcare | Faithfulness and reproducibility |
- RAG is easier to update, modular, and cheaper to maintain
- Fine-tuning is better for consistent tone or domain adaptation but risks drift
Time series & forecasting
From inventory planning to predictive maintenance, these systems must capture seasonality, trends, and shocks.
| Task | Models | Challenges |
| Demand forecasting | XGBoost, LSTMs | Missing data, holiday effects |
| Anomaly detection | Isolation Forests, autoencoders | Label scarcity |
| Pricing optimization | Reinforcement learning | Feedback loops, policy constraints |
Accuracy isn’t sufficient; confidence intervals and explainability matter in business ops.
Recommenders & ranking
Critical in e-commerce, media, and search. Even tiny performance gains lead to major revenue lifts.
| Component | Common Approaches |
| Candidate generation | Matrix factorization, embeddings |
| Scoring/ranking | DNNs, LambdaMART, transformers |
| Feedback loops | Bandits, RL-based optimizers |
Deployments must be highly optimized for latency, and systems often run continual A/B tests to detect drift or fatigue.
Multimodal machine learning
Emerging use case with models like GPT-4o and Gemini, which take inputs from text, images, audio, and more.
Key requirements:
- Aligned training data: Need image-caption pairs, video-transcript pairs, etc.
- Cross-modal annotation: Image regions tied to text spans, audio timestamps matched with text
- Efficient inference: Must process multiple modalities without ballooning latency or cost
Multimodal machine learning enables AI systems that can "see, hear, and read," this way unlocking use cases in robotics, assistive tech, video analysis, and more.
Choosing the Right Machine Learning Stack
Your machine learning stack shapes how quickly you can iterate, debug, and deploy. A good stack aligns with your team’s maturity, problem size, and production goals. We break it down by layer:
Languages & core libraries
Python machine learning remains the dominant language for ML thanks to its ecosystem and readability.
| Purpose | Tools |
| Numerical computing | NumPy, SciPy, Pandas |
| ML modeling | scikit-learn, XGBoost, LightGBM |
| Deep learning | PyTorch (flexibility), TensorFlow (deployment) |
| Experiment tracking | MLflow, Weights & Biases |
| Jupyter workflows | JupyterLab, VSCode notebooks |
Scikit-learn is still the baseline for tabular ML. PyTorch is now the default in research, but TensorFlow remains common in production (especially with TFX pipelines).
Data infrastructure layer
ML teams today need modern data platforms that support scale, querying, versioning, and real-time pipelines.
| Layer | Tools |
| Storage | S3, GCS, Azure Blob (Azure Machine Learning) |
| Querying | Spark, BigQuery, DuckDB |
| Lakehouse | Delta Lake, Apache Iceberg, Snowflake |
| Feature stores | Feast, Tecton |
| Vector databases | Pinecone, Qdrant, Weaviate |
| Streaming | Kafka, Apache Flink, dbt for transformation logic |
Your choice depends on volume, latency, and team skillsets. Feature stores are a must for mature teams dealing with real-time inference or shared features across models.
Compute layer
The compute setup should scale with model complexity and cost constraints.
| Task | Compute |
| CPU-only batch jobs | Cheap EC2, on-prem clusters |
| GPU training | A100s, H100s on AWS/GCP, or Lambda Labs |
| TPU training | GCP-specific (use with TensorFlow/JAX) |
| On-device/edge | NVIDIA Jetson, Apple Neural Engine, Coral |
For large-scale training, schedulers like Ray, Kubernetes, or Slurm coordinate distributed runs. For most teams, spot instances with autoscaling can significantly reduce cost.
Challenges in Machine Learning Projects (and How Teams Solve Them)
Every ML team hits recurring walls. Addressing them early can be the difference between a successful pipeline and one that quietly fails in production.
Data imbalance and bias
Imbalanced classes or biased source data can cripple performance, especially in critical domains like fraud detection or hiring.
Common fixes include:
- Resampling (oversampling minority classes, undersampling majority)
- Synthetic data generation (e.g., SMOTE)
- Reweighting loss functions
- Targeted re-labeling of underrepresented classes
In high-risk domains, fairness audits and debiasing strategies must be integrated from the start.
Model drift and stale features
Models trained on yesterday’s data degrade over time. Concept drift (changing relationships) and data drift (changing input distributions) often go undetected until metrics tank.
Solutions:
- Monitor input distributions and prediction confidence
- Use continual learning or active learning loops
- Automate retraining pipelines based on drift signals
For fast-changing environments (retail, finance), schedule-based retraining isn’t enough. Drift-triggered machine learning updates are more robust.
Explainability and trust
Non-transparent models (like deep nets or ensemble methods) are tough to debug and harder to justify in regulated industries.
Common tools:
- SHAP for local/global feature attribution
- LIME for instance-level explanations
- Decision trees or GAMs as interpretable baselines
- Counterfactual explanations for user-facing ML
Trust also depends on stable behavior. Even perfect models lose credibility if outputs change for no apparent reason.
Compute and latency constraints
Not every deployment can handle 30-second inference on a 13B model.
| Constraint | Solution |
| High latency | Distillation, quantization, early exits |
| Limited memory | Model pruning, parameter sharing |
| Edge devices | Run-on-device with ONNX, TensorRT |
| Cost | Batch inference, request caching |
Teams working on real-time products often switch from large models to compact versions (e.g., MobileNet, DistilBERT) with 90% of performance but 10× speedups.
Most teams try to scale AI with cloud-native tools, but Kubernetes and static autoscalers don’t suit ML workloads. ML needs dynamic compute across CPUs, GPUs, and memory, managed in real time. AI-native systems like Ray treat the cluster as one intelligent computer. The future is optimized runtimes, not more containers.
 Technical Lead, ML, Anyscale
Technical Lead, ML, Anyscale
The Role of Annotated Data Quality in Machine Learning
Engineers often focus on model selection, tuning, and architecture. But in production ML systems, data quality is what makes or breaks reliability. No amount of modeling effort can compensate for mislabeled samples, schema drift, label imbalance, or inconsistent ontologies.
Poor data annotation introduces silent failure modes: inflated metrics during training, inconsistent behavior in production, and brittleness when generalizing to edge cases or new domains. For high-stakes systems, these risks can be unacceptable.
In this section, we unpack how to think about annotation strategically, how to engineer robust QA pipelines, and why clean data offers more leverage than any model trick.
HITL labeling vs. automated pre-labeling
Automated pre-labeling using weak models, LLMs, or heuristics is attractive for scale. But it introduces risks: automation bias, hallucinated labels, or overconfidence on edge cases.
That’s where human-in-the-loop (HITL) strategies come in. Instead of labeling from scratch, annotators at a data annotation company can:
- Validate or correct pre-labeled outputs
- Handle ambiguous or subjective cases directly
- Flag low-confidence regions for escalation
This hybrid setup delivers scale and quality if you monitor confidence thresholds and agreement. Examples include:
| Scenario | Best Approach |
| High-volume image detection | Pre-label + QA sampling |
| Subjective tasks (e.g., toxicity, intent) | Human-first with calibrators |
| Long-tail class detection | Active learning + manual validation |
| LLM-generated label suggestions | Human spot-check + bias detection |
The sweet spot: use models to speed up labeling where precision isn’t critical and use human data annotation services to govern ambiguity, safety, and correctness.
QA frameworks and inter-annotator agreement
You need to validate whether labeling is done right. That’s where QA and agreement frameworks come in. Usually, a data annotation platform supports these best practices:
- Gold sets: Manually curated examples with known ground truth
- Consensus labeling: Multiple annotators per task, resolved via majority vote or reviewer arbitration
- Inter-annotator agreement: Measures like Cohen’s Kappa or Krippendorff’s Alpha signal consistency across reviewers
- Annotation analytics: Track annotator-level accuracy, disagreement clusters, task fatigue, and error types
- Feedback loops: Incorporate model errors into label correction cycles
High IAA (above 0.75) doesn’t guarantee correctness but low IAA (<0.5) is a red flag, especially in subjective domains. For multimodal data, apply agreement not just within modalities but across them.
The data-centric AI machine learning shift
Data-centric AI prioritizes data iteration over model iteration. Why?
Because every mislabeled training sample is a false supervision signal. Every imbalance skews your loss function. Every drifted schema breaks inference downstream.
Here’s how top teams operationalize data-centric workflows:
- Model audit → Data correction: Train baseline, collect false positives/negatives, analyze where data fails, fix examples, retrain
- Ontology refinement: Track ambiguous labels and update label definitions collaboratively with subject-matter experts
- Coverage monitoring: Use clustering or embedding projections to see which data regions are underrepresented
- Regression protection: Version labels, re-run evaluation on stable test sets, and detect when data “fixes” hurt downstream metrics
The industry is moving toward data annotation tools that support this: label versioning, QA dashboards, active learning loops, and integrated feedback from model errors to annotation teams. All while offering more transparent data annotation pricing models for better cost tracking across projects.
Your model will only be as consistent, fair, and robust as the data you feed it and the humans who label it.
A smart model cannot fix messy inputs. In every production system I’ve worked on, the data model sets the ceiling and the ML just tries to reach it. Fix joins, define label logic, enforce contracts. Start from the decision you want to support. If the data is broken, the model will be too.

What’s Next in Machine Learning: 2026 and Beyond
The future of AI and machine learning is about who builds systems that are efficient, interpretable, and usable at scale. In 2025, engineering teams face growing demands to ship models faster, cheaper, and under heavier regulatory scrutiny.
Here are the key AI and machine learning trends reshaping how systems are built and deployed:
SLMs over giant LLMs
Smaller language models (SLMs) are replacing massive LLMs for many real-world tasks. With fine-tuning, LoRA adapters, and better retrieval pipelines, SLMs can achieve comparable performance while being easier to deploy and monitor.
Why this matters:
- Cost control: SLMs are 5–10x cheaper to run at inference
- Faster iteration: Smaller models train and evaluate quickly, enabling rapid experimentation
- Edge-readiness: SLMs can run on consumer devices, opening use cases in mobile, IoT, and offline tools
- Fewer safety risks: Smaller model scopes reduce unexpected outputs in regulated domains
Multimodal becomes default
Multimodal benchmarks like Gemini vs ChatGPT highlight how model performance increasingly depends on the quality of diverse training data, including tightly aligned text, image, and audio inputs.
Gemini, GPT-4o, and Claude 3 Opus proved that AI systems must handle not just language, but also vision, speech, and structured data, often in the same prompt. Engineers now need to think beyond modality silos.
Implications:
- Model architecture: Cross-modal fusion layers and unified embeddings are becoming standard
- Data pipelines: Teams must collect, annotate, and QA aligned image–text–audio data
- Evaluation: You’ll need metrics that assess consistency across modalities
- Annotation strategy: Multimodal labeling projects are now a core part of training data ops
Synthetic data at scale
Synthetic data generation lets teams sidestep label scarcity and privacy constraints by generating labeled data in-house. It’s gaining traction in robotics, AV, and medical imaging, and moving fast into general ML.
Advantages:
- Full control: You define edge cases, balance classes, and simulate rare scenarios
- Scalability: 10K labeled images? Generate them overnight
- Security: No real PII is needed, reducing compliance burdens
- Limitations: Synthetic data still needs validation; artifacts and domain shifts can hurt generalization
Privacy-preserving ML and compliance pressure
Laws like the EU AI Act and growing internal governance standards mean ML teams must think like compliance engineers. Pipelines must be explainable, traceable, and defensible.
Engineering impact:
- More audit logs: Track who labeled what, when, and with what guideline version
- VPC deployments: Expect security reviews before using third-party tools or clouds
- Data governance: Federated learning, DP-SGD, and synthetic overlays are becoming essential for sensitive data
Human feedback as a default loop
RLHF and RLAIF are no longer just for OpenAI. Any system that interacts with users (think chatbots, recommenders, search engines) benefits from human feedback to improve subjective outcomes.
What changes:
- QA becomes model tuning: Feedback teams influence reward shaping
- Evaluation shifts: Top-k accuracy isn’t enough; pairwise preference data is critical
- Cross-functional coordination: Human feedback teams need to be embedded in ML workflows, not bolted on after deployment
Future-ready ML teams are lean, modular, and human-aware. They choose smaller models when possible, rely on feedback loops over hard-coded rules, and treat multimodal data and governance as first-class citizens.
The biggest shift coming in ML is the rise of agentic systems. These learn from real-time feedback and adapt on their own. Fixed models and rigid workflows will be replaced by applications that adjust continuously. This allows teams to build more flexible, self-improving ML products that evolve with the data.
 Senior Product Manager
Senior Product Manager
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is exactly machine learning?
Machine learning is a method of building systems that learn patterns from data to make predictions or decisions without being explicitly programmed. It relies on training algorithms using labeled or unlabeled datasets to generalize across unseen examples.
What is the difference between AI and machine learning?
AI (artificial intelligence) is the broader goal of building intelligent systems, while ML (machine learning) is a subset focused on algorithms that learn from data. All ML is AI, but not all AI is ML; rule-based systems and symbolic reasoning are AI, too.
Is ML full of coding?
Machine learning involves a significant amount of coding, but it’s not just about writing algorithms from scratch. Engineers regularly code pipelines for data preprocessing, model training, evaluation, and deployment.
They also work with libraries like scikit-learn, PyTorch, or TensorFlow, and often need to integrate models into production environments. While low-code tools exist, real-world ML still demands strong programming skills to customize models, handle edge cases, and maintain reproducibility at scale.
Is ChatGPT AI or ML?
ChatGPT is both. It's built using machine learning techniques (specifically, transformer-based deep learning) and is considered a form of AI because it generates human-like text responses in natural language.
What are the 4 types of ML?
The four main types of machine learning are supervised learning, which trains on labeled data; unsupervised learning, which finds patterns in unlabeled data; reinforcement learning, where models learn through rewards and actions; and semi‑supervised or self‑supervised learning, which uses limited or indirect labels to improve training efficiency.
How does big tech use machine learning?
Big tech companies use machine learning across nearly every product and infrastructure layer. Search engines like Google rank results using learning-to-rank models; platforms like YouTube and TikTok use deep learning for personalized recommendations. Amazon and Netflix apply ML for forecasting, inventory optimization, and content delivery.
At the infrastructure level, ML powers resource allocation, security anomaly detection, and developer tools. Large-scale training pipelines are core to their AI products, and internal teams rely on specialized MLOps stacks to manage data, models, and experimentation at scale.
How does machine learning use gradient descent?
Gradient descent is an optimization algorithm used to minimize a model’s loss function during training. It updates model parameters (like weights in neural networks) in the direction that reduces error, based on the gradient of the loss. Common variants include stochastic gradient descent (SGD), mini-batch, and Adam, each balancing convergence speed and stability.
What is a transformer in machine learning?
A transformer is a deep learning architecture designed for sequence modeling without relying on recurrence. It uses self-attention mechanisms to process all input elements in parallel, enabling scalable training on large datasets. Transformers power most modern NLP and multimodal models, including BERT, GPT, and Vision Transformers (ViT).
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.