AI Training Data: Top Sources and Dataset Providers

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Model Accuracy Starts (and Fails) with AI Training Data
- Types of AI Training Data
- The AI Training Data Pipeline (Collection to Curation)
- What AI Training Data Sources ML Teams Use in 2025
- Legal and Ethical Dimensions of AI Model Training Data
- Key Challenges in AI Training Data
- Best Practices for Managing Your AI Training Data
- About Label Your Data
- FAQ

TL;DR
- AI systems are only as strong as the data that trains them, and poor-quality inputs still remain the main cause of model failure.
- Human-in-the-loop labeling is essential for building accurate, safe, and context-aware models that reflect real-world conditions.
- Selecting trusted, bias-free AI training data providers and maintaining clear dataset documentation are now the cornerstones of scalable, responsible AI development.
Why Model Accuracy Starts (and Fails) with AI Training Data
Andrej Karpathy, co-founder of OpenAI, emphasizes that high-quality, well-structured, and vetted data, not just large-scale web-scraped text, is essential for effective model pretraining. He notes that organizations focusing on clean, diverse, and well-documented data have a stronger foundation for building trustworthy AI systems.
In 2025, and looking ahead, developing the most robust machine learning models has shifted significantly from architecture to the integrity of the data they are built on. From large language models to computer systems, model accuracy begins (and often fails) with the training data that forms the foundation for these mega data structures.
Gartner estimated that poor data quality costs the average organization between $12.9 and $15 million annually (excluding the hidden “emotional tax” from burnout!). It is similar to building the best Formula 1 car, but you power it with low-grade fuel.
Any machine learning algorithm relies on quality data to learn. Poorly curated datasets directly limit how reliable, fair, and explainable your model can become.
What is AI training data?
At its simplest form, the collectively known concept of AI training data is the information — numbers, text, images, audio and video properties used to teach an ML model to “make predictions, recognize patterns or generate content”. Forbes calls data the primary determinant of downstream accuracy, robustness and fairness.
Data for AI training are the experiences through which an algorithm develops its understanding of the world. Whether through labeled data that carries human- or program-assigned tags that teach models how to map inputs to outputs, or unlabeled data (tagless, raw) which fuels today’s large self-supervised and foundation models. They learn patterns from vast amounts of text, image, or audio files before simplified into smaller labeled datasets.
The bridge between the two is weak supervision, which uses programmatic rules to scale labeling more quickly.
Furthermore, real data, collected from the world, versus synthetic data, which is generated or simulated, provides greater depth to the data discussion. Gartner predicted that by 2030, synthetic data will completely dominate and overshadow real data in AI development.
When you evaluate an AI training data providers, you should ask more than just “how much data do you have?” It is essential to find out how they collected, labeled, balanced, governed, and licensed their data. The data should also be scalable and safe to use across different languages, formats, and high-stakes areas.
In this article, we break down the primary data sourcing methods, highlight the top provider categories for 2025, outline key evaluation criteria, and discuss the current realities of data annotation.
Types of AI Training Data

Understanding the new data supply chain requires recognizing that every AI system depends on distinct data types, from text and video to tabular and synthetic streams. They form the raw material of ML intelligence.
Here follows a summary of the types of AI training data sets:
Text data
Text data is basically natural-language content, such as sentences, paragraphs and documents. It is used to train ML models for language understanding, generation, translation, and prediction, as well as for summarizing information and generating content.
Use cases: large language models (LLMs), chatbots, NLP pipelines, sentiment analysis.
Sources: Common Crawl, Wikipedia, PubMed, OpenWebText, multilingual corpora.
Image & video data
Image and video data consist of frames or sequences of visual information, such as images, pixels, or moving footage. It may also include possible annotated labels, such as boundaries, objects, or actions, used for computer vision or multimodal AI tasks.
Use cases: object detection, image recognition, segmentation, video understanding, computer vision, multimodal systems incorporating text or audio, and robotics.
Sources: ImageNet, COCO, YouTube-8M, Kinetics-700, custom in-house recordings.
Audio & speech data
Audio and speech data, like sound recordings, voice samples, transcripts, and annotated audio features are used to train systems for voice assistants, speech recognition, speaker identification, and also audio-based sentiment or event detection.
Use cases: Automatic Speech Recognition (ASR), voice-enabled assistants or interfaces, sentiment analysis.
Sources: LibriSpeech, VoxCeleb, Common Voice, proprietary datasets.
Tabular & sensor data
Tabular and sensor data consist of structured numerical, categorical or time-series measurements, such as tables, telemetry, and logs. They often originate from IoT systems, business analytics or simulation environments.
Use cases: predictive analytics, anomaly detection, autonomous systems training, simulation-based modelling.
Sources: industry databases, manufacturing sensor logs, vehicle telemetry, and finance transaction tables.
Synthetic data for AI training
Synthetic data is artificially generated, either simulated or generated from models. They mimic the properties of real data and are used to expand datasets and protect private or obscure rare edge cases. Beth Stackpole warns that using the wrong synthetic data for AI training can easily lead to legal risks, bias, or lower-quality models; hence, use synthetic data as a supplement.
Use cases: privacy-safe training in regulated domains, simulation for autonomous vehicles, edge-case expansion in computer vision.
Sources: NVIDIA Omniverse, Gretel.ai, computer-simulated environments, GAN-based data generators.
The strongest dataset providers are transparent about how often they refresh their data and how their labeling process works. I always ask when their data was last updated and whether their labels reflect actual outcomes or predictions. If they call their lineage documentation proprietary, you’re buying a black box that will fail your audit later.

 Founder, KNDR
Founder, KNDR
For teams building computer vision or genAI models, licensed visual datasets can simplify sourcing high-quality training material. Resources like DepositPhotos AI training data offer curated image collections that can support model development across a wide range of visual AI use cases.
The AI Training Data Pipeline (Collection to Curation)
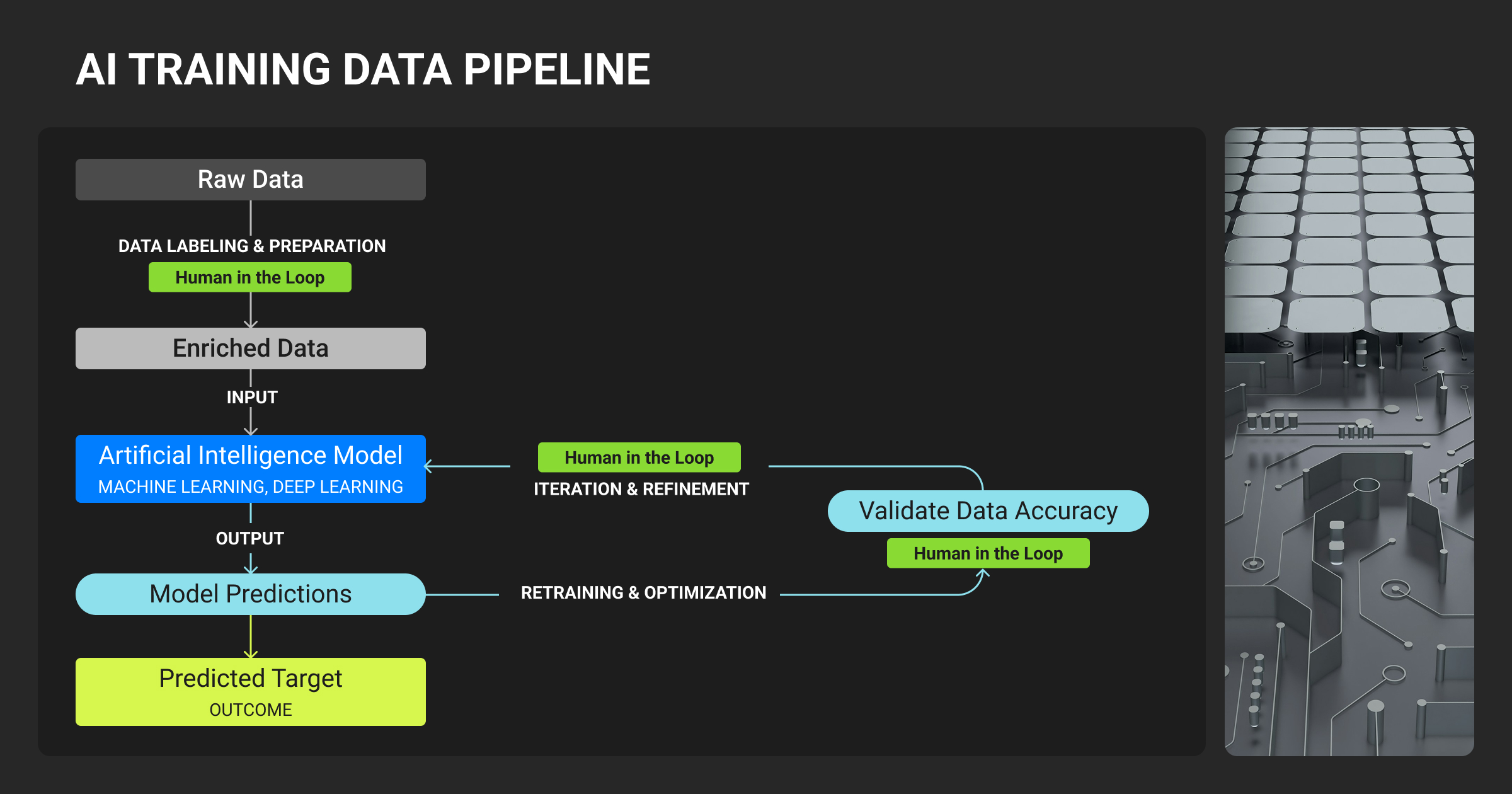
Understanding what kinds of data are available is only the beginning of your exploration. You should also know how that data was collected, cleaned, labeled, and curated – all parts of a structured framework called an AI pipeline, where raw data is transformed through various stages into actionable insights.
The modern training data AI pipeline produces high-integrity machine learning datasets, which explains why data engineers and MLOps teams spend most of their time on data preparation rather than model tuning. Even different types of LLMs require distinct data preparation strategies.
By leveraging expert data annotation services to provide the required expertise and skills that handle and streamline complex, manual (but critical) labeling tasks, teams can focus on tasks that add higher value, like model alignment and deployment.
AI training data sets collection and sourcing
Peeking into the beginning of the pipeline, it all starts with acquisition: data collection and sourcing — understanding where your training data for AI originated, how it was obtained, and the ethical and legal considerations associated with it.
There are three primary avenues to source data from, each with its own trade-offs:
Free AI training data sources
One can find large volumes of publicly available data on platforms such as Google Datasets, Kaggle, and community forums such as Reddit and Quora. Although valuable for academic purposes or experimentation, it often requires extensive cleaning and validation.
Data scraping
Data scraping is the process of using automated tools to extract data from websites, public portals, or documents. Primarily used to gather domain-specific or niche datasets, it is acceptable for personal or research use, but when it is used for commercial purposes, one might breach site terms or data-protection laws.
External vendors
There are specialized vendors, like Label Your Data, Scale AI, Appen and other data annotation service companies in the US or UK that specialize in data collection and deliver ready-to-use, high-quality datasets, tailored to a project’s needs. Such data annotation company can handle all the sourcing, labeling, and regulatory compliance, saving you time and ensuring data integrity, reliable, scalable and audit-ready AI model training data.
Keep in mind that transparent data annotation pricing models help companies plan large-scale projects more effectively.
AI teams strategically blend these three sources: free and scraped data for early data exploration, and vendor-supplied datasets for larger-scale or high-stakes applications.
Cleaning and transformation
As soon as data is sorted, it needs to become usable, requiring two main preprocessing steps: cleaning and transformation. This process involves:
- Deduplication: Removing redundant records
- Normalization: Standardizing formats and values
- Feature extraction: Deriving meaningful signals from raw data
- Metadata enrichment: Adding descriptive or contextual information
- Structural alignment: Bringing all data into a consistent format
These steps prepare the dataset for downstream machine learning tasks and improve its overall reliability.
Cleaning processes remove noise, prevent data bias, and ensure consistency across all sources utilized. There are great modern ML Ops tools like Data Version Control (DVC) and LakeFS to help with this. Such platforms can transform messy, fragmented data into high-integrity datasets.
AI training data annotation
The next step is teaching the model what the data means, bringing annotation into the pipeline, together with the element of the human touch, referred to as the human-in-the-loop annotation, crucial to ground AI systems in real-world accuracy and ethics. In the annotation process, datasets are labeled or tagged so that AI models can “see,” “hear,” and “understand”.
Text annotation (tagging, sentiment classification, part-of-speech labeling) is essential for NLP models, such as chatbots. In contrast, object recognition in image annotation uses bounding boxes, polygons or pixel-level segmentation.
Audio annotation includes transcription, speaker identification, and emotion tagging, which power AI sound recognition and voice analytics. And lastly, video annotation adds a temporal layer — tracking objects, gestures, or actions across frames for applications in robotics and autonomous driving.
Modern teams often manage labeling workflows using a data annotation platform that integrates human oversight with automation for faster turnaround.
The most sophisticated data annotation AI training process is only as effective as the sources that feed it, ranging from open, community-driven datasets to vendor pipelines and privacy-safe synthetic data.
What AI Training Data Sources ML Teams Use in 2025
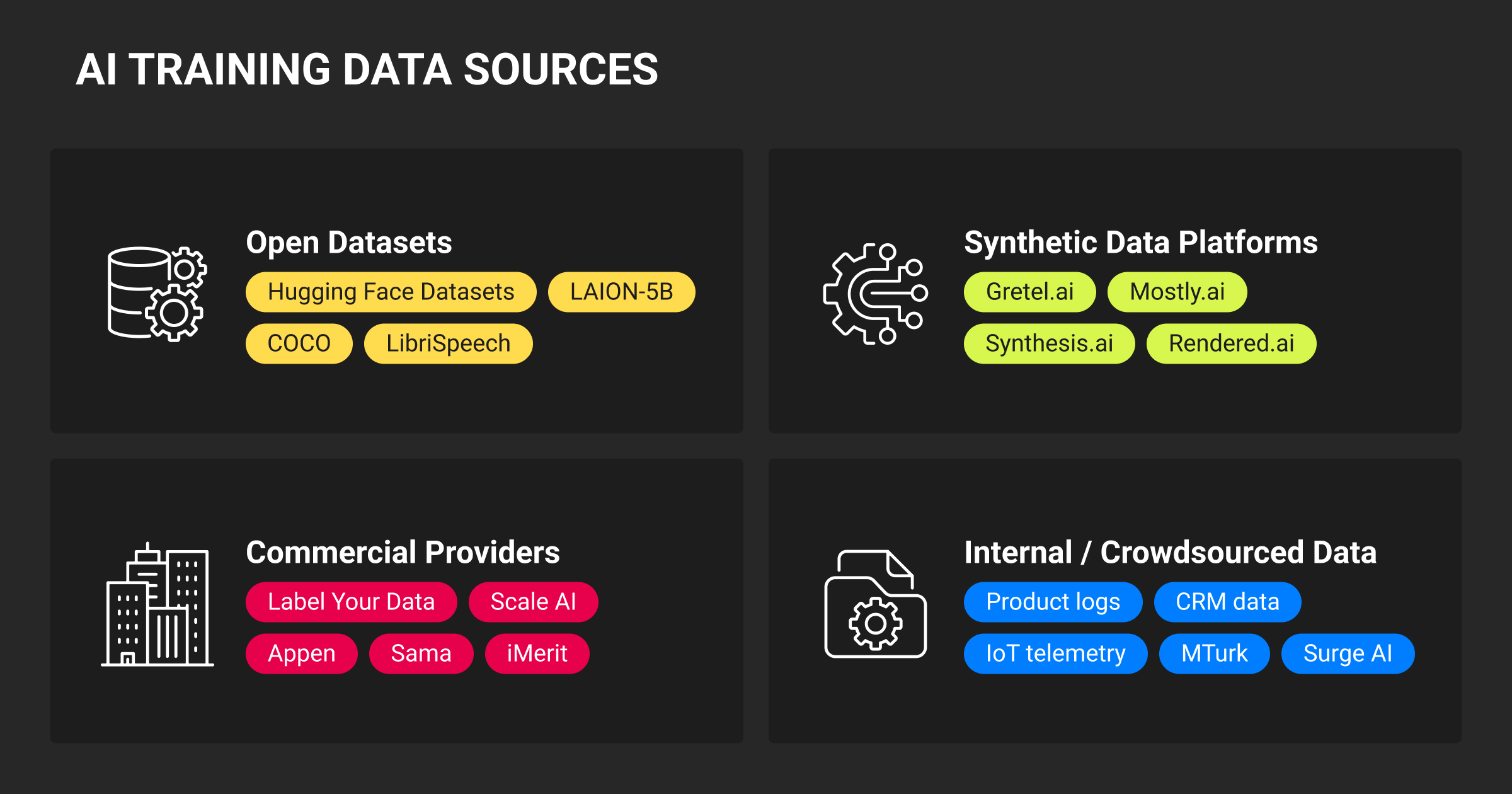
By 2025, AI teams have more options than ever for sourcing data for AI training. The choice depends on project scale, domain sensitivity, and data availability. Most teams rely on a mix of AI training data sources: open repositories, commercial datasets, synthetic generation, and internal data pipelines.
Open datasets
Freely available datasets remain an important foundation for research and prototyping. Public AI training data sources like Kaggle, Hugging Face Datasets, and Google Dataset Search offer text, image, and tabular data across multiple domains. However, these datasets often require additional cleaning, documentation, and validation before production use.
Commercial AI training data providers
AI training data companies such as Label Your Data, Scale AI, or Appen deliver tailored datasets that include sourcing, annotation, and compliance checks. These AI training data providers are often used when quality, volume, or domain-specific coverage is more important than speed or cost. Vendor collaboration also ensures clearer licensing and data provenance.
Synthetic data platforms
Synthetic data generation tools like Gretel.ai, Synthesis AI, and NVIDIA Omniverse help create data that mirrors real-world distributions while protecting privacy and addressing class imbalance. They are increasingly integrated into pipelines for simulation, domain adaptation, and edge-case generation.
Internal and crowdsourced data
Many companies now collect proprietary data from sensors, user interactions, or business systems, using internal labeling teams or crowdsourcing platforms to annotate it. This approach offers better control over privacy, domain coverage, and data diversity, though it demands more internal oversight and infrastructure.
The most effective ML teams blend these sources, using open data for exploration, vendor data for reliability, synthetic data for coverage, and internal data for fine-tuning domain-specific models.
High-quality data providers can clearly explain what happens when their data conflicts with yours. In our company, we integrate over 80 marketing platforms, and the reliable ones always document how they handle gaps and discrepancies. If a provider can’t show their data provenance and filtering criteria within minutes, walk away.
 Founder, ASK BOSCO
Founder, ASK BOSCO
Legal and Ethical Dimensions of AI Model Training Data
Training data for AI is already a competitive asset worldwide. For that, legal and ethical dimensions come into play, including ownership, privacy, and compliance.
Three essential aspects take center stage:
Ownership and copyright
Although no one can claim ownership of raw data, copyright and database ownership rights still apply to protect its structure and content. Licensing frameworks, such as Creative Commons, dictate whether AI teams can reuse or monetize datasets.
Privacy and compliance
Laws like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) require consent-based collection, anonymization, and data minimization.
Licensing best practices
Before teams even decide to buy AI training data or use open-source sets, they should verify the dataset's provenance and usage rights, confirm vendor indemnification clauses, and maintain license logs for audit readiness.
Key Challenges in AI Training Data
Some pressing technical and operational hurdles in managing training data come to mind when one considers the key challenges in data for AI training today.
Bias and representation gaps
A Penn State University study found that most users cannot identify bias in AI systems, even when told where it originates.
Data annotation AI training quality
Label noise, inconsistent tagging, and missing the context remain some of the most significant cost drivers and can consume up to 80% of your ML project effort.
Scale and cost
IBM reminds us that in multimodal generative AI training data, teams constantly face trade-offs between vast data volumes and maintaining acceptable-grained accuracy. In their report, they revealed that the average cost of computing rose by 89% from 2023 to 2025, and executives cite training data for generative AI as the critical driver of this increase.
Privacy, security, and compliance
In the world of AI, privacy, security and compliance will be on the agenda of many teams, especially when data scraping and opaque vendor chains make headlines. Fact is: transparent sourcing, consent management, and ethical data governance are now baseline expectations.
A credible dataset provider prioritizes accuracy, documentation, and independent validation. They disclose how data is collected, labeled, and cleaned, and they’re willing to share audit results or bias assessments. Trust comes from openness and consistency, not marketing claims.
 CEO & Founder, Blogger, Speaker, Podcaster, Omniconvert
CEO & Founder, Blogger, Speaker, Podcaster, Omniconvert
Best Practices for Managing Your AI Training Data
ML pioneer Andrew Ng called it data-centric AI, the idea that real progress doesn’t come from bigger models but from better data. From Stanford’s AI Lab to labeling companies like Label Your Data, there is consensus that mastering the data lifecycle is a strategic advantage.
ML teams today should combine several best practices:
- Audit dataset sources and licenses to stay ahead of evolving privacy and copyright regulations.
- Blend public, proprietary, and synthetic data to balance diversity, control, and compliance.
- Version and track datasets using platforms like DVC or LakeFS to ensure reproducibility and transparency.
- Embed human-in-the-loop QA throughout the annotation process to reduce drift and maintain trust in the data pipeline.
- Document metadata, lineage, and usage rights, transforming datasets from transient inputs into auditable digital assets.
IBM’s 2025 AI Governance Outlook notes, “AI accountability starts with dataset clarity,” and that’s precisely where our team thrives — helping organizations transform fragmented, unverified data into high-integrity fuel for ethical, performant, and future-proof AI systems.
About Label Your Data
If you choose to delegate the annotation of your AI training data, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is training data in AI?
Training data AI is the information used to teach a machine learning model how to recognize patterns and make predictions. It provides the examples a model learns from, allowing it to adjust its internal parameters to minimize prediction errors.
Where can I find training data for AI?
Training data for AI can come from public repositories such as Kaggle, Google Dataset Search, Hugging Face, or OpenML, as well as commercial vendors like Label Your Data, Scale AI, and Appen that deliver curated and annotated AI language model training data sources or any other data your model needs. Many organizations also use their own collected data or generate synthetic data to fill gaps and avoid privacy issues.
What is AI training data?
AI training data refers to any digital content such as text, images, audio, video, or structured records that help a model learn to perform a task. It can be labeled for supervised learning, unlabeled for unsupervised or self-supervised learning, or partially labeled for semi-supervised approaches.
Where to find top data storage for AI training?
The best data storage for AI training depends on scale, privacy, and workflow needs. Cloud options like AWS S3, Google Cloud Storage, or Azure Blob are common choices, while platforms such as Snowflake, Databricks, or BigQuery offer integrated data lake and warehouse solutions. In highly regulated settings, on-premise or hybrid storage is often preferred.
What is the 30% rule in AI?
There is no established 30% rule in AI. Some use it informally to describe situations where models degrade when a significant portion of data or features is missing, but this is not a formal guideline. Data quality, relevance, and balance are far more important indicators of model performance.
What does an AI training dataset look like?
An AI training dataset usually contains input examples with expected outputs for supervised learning or raw examples for unsupervised tasks. It might include text paired with sentiment labels, images with object annotations, audio with transcripts, or structured tables with numerical features. A complete dataset also records metadata such as source, license, and labeling quality.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.