What Is Handwritten Text Recognition with OCR?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

Today, there exist many known cases that have successfully addressed the complex matter of OCR (Optical Character Recognition) for printed text tasks. Meanwhile, human handwriting is an even taller mountain to climb for artificial intelligence, given many fonts and styles that humans can naturally develop.
Handwritten text recognition, or handwritten character recognition (HCR), is a much more arduous task for AI, compared to more common OCR issues. Why is that so? Handwriting is a distinctive trait that each individual possesses. Therefore, recognizing it is still at the forefront of AI research, since correctly identifying one-of-a-kind handwritten texts goes much beyond conventional pattern matching algorithms. Until recently, it seemed almost impossible for machines to identify unique patterns in human handwriting. Researchers and computer scientists now debut a new, upgraded algorithm every few months.
AI experts (read super minds) were unable to produce anything even somewhat meaningful. So what happened? Artificial neural networks (ANNs), to keep things brief. The same technological breakthrough that helped computers beat the global Go champion has now made it possible for us to confront human handwriting. This strategy significantly varies from traditional machine learning algorithms in that the recognition model now automatically learns from a group of examples rather than being manually designed. But there’s so much more to discover in handwritten OCR!
The underlying architecture of ANNs has been around for a while, but only recent advances in parallelized computing, network systems, training algorithms, and most importantly, the accessibility of training data, have put them to meaningful use. The so-called convolutional neural network, or convnet, is one of the most popular network types used today for extracting text from images or image recognition, if you will. Now, let’s define AI-powered handwriting recognition.
According to Gartner, handwriting recognition systems use pattern matching to instantly translate handwritten letters into equivalent computer text or actions. This analysis, however, doesn’t cover batch recognition of handwritten forms because it’s already a part of common form sorting and processing systems. Case in point, managing mail and checks, as well as other financial systems and transactions.
Perhaps you’ve ever heard of digital pens? If not, this is an example of smart handwriting recognition technology, which converts your handwritten text into digital data. Besides, there’s a good deal of handwriting recognition software on the market that have already demonstrated fantastic performance. But more about that later.
First, we’ll discuss the machine learning basics in handwriting recognition, including methods, algorithms, and databases. After that, we’ll review the key applications of handwritten text recognition technology across the major industries today. And, of course, we’ll share our professional experience of working on such projects. So stay tuned!
Handwriting Recognition with Machine Learning: The Essential Points

The term “handwriting” originally denotes manuscript and cursive written texts. Because the characters are separated and written in block letters, manuscript-style texts are simpler to recognize. Cursive handwriting, on the other hand, joins the characters as they are written. To correctly and accurately recognize each individual character, handwriting recognition software is required.
Our Label Your Data team has recently worked on the HCR project in two languages, French and German. We have annotated over 1,000 handwritten forms with 100 unique handwritings using bounding boxes, and then transcribed each of the documents. If you need a hand with your AI text recognition project, you can send your data to us and receive expert data annotation to help your model recognize the handwritten text as accurately as possible.
After many years of profound research and numerous studies, a plethora of ML algorithms and tools have been introduced in the effort to solve handwriting problems in AI. Yet, the work principle in handwriting recognition is the same, regardless of the ML task and algorithm applied. Generally, every handwriting recognition method will follow the same procedure:
- Image acquisition. The image, which is typically captured using a digitizer, is subjected to various preprocessing techniques once it has been collected as an input. Handwriting images (i.e., scans, photographs) are processed in exactly the same manner.
- Pre-processing (analogue and digital). Preparing an image for a handwritten text recognition task is quite a labor-intensive process. With the right images on hand, one can enhance a few key elements of the image data by suppressing some unnecessary data. Pre-processing aids in the removal of noise, segmentation of pictures, cleaning operations, scaling, cropping, resizing, and other tasks. The goal is to reduce noise as much as possible to facilitate subsequent procedures.
- Segmentation. In this stage, one deals with the process of dividing a digital image into several pieces (sub-images) to make it simpler to analyze. The text document, for example, is often handled hierarchically. Using a row histogram, lines are segregated at the first level. Then, using a column histogram, words are retrieved from each row, and finally, characters can be extracted from words.
- Feature extraction. An overfitting problem may arise if your dataset comprises many pictures, each with a wide range of features that may be even identical. But one can avoid this by performing regularization or dimensionality reduction, aka feature extraction. To simplify the picture retrieval, this process takes into account only the crucial elements.
- Classification. Arguably the most popular task in machine learning, classification deals with image categorization based on their attributes and in conjunction with a trained dataset. The key characteristics of an input image for handwriting recognition are retrieved and fed into classifiers, such as logistic regression, kernel neural networks, and ANNs. The featured picture is then compared to the training dataset by these ML classifiers, which then classify the image more accurately.
- Post-processing. At this final stage, post-processing is responsible for the correction of images that were incorrectly categorized before and for changes in detection. This method guarantees the most accurate results, so it cannot be skipped under any circumstances. Depending on the desired outcome, post-processing can be divided into many steps.
Modern approaches concentrate on identifying all the characters in a segmented line of text, as opposed to previous strategies that concentrate on segmenting individual characters for recognition. They bypass the restrictive feature engineering methods that were previously utilized and instead concentrate on machine learning algorithms that can learn visual characteristics.
Modern techniques extract visual information from a text line image using convolutional networks, which a recurrent neural network then utilizes to generate character probabilities.
Algorithms and Methods in Handwritten Character Recognition
With so many ML algorithms available today, it’s important to understand the differences between them to choose the best option for a handwriting recognition task. Although, several algorithms and methods can be used in this area, depending on the objectives of the task.
One of the most crucial techniques, that we have already talked about on our blog, is Optical Character Recognition, or simply OCR. It’s a DL-based method used to read handwritten and paper documents. If you want to quickly try this in practice, you can use image to text tool to instantly extract text from images without setting up any ML models. However, unsupervised ML methods, including feature learning, may also be useful for addressing issues with digit recognition systems.
As a rule, researchers often provide two alternative approaches to recognizing various natural languages: offline and online handwriting recognition. In offline handwritten OCR, the already-written and stored documents are used to identify the characters stored in the texts. Alphabets, integers, or any other type of sign can be used as characters. One way to use this method is to recognize mathematical expressions. This is a common feature in mobile apps, and it allows students to scan documents to let the mathematical expression recognizer identify the equations and provide answers.
On the other hand, with online handwriting recognition, the data is not scanned from a document but rather the characters are written using an electronic pen and the letters are identified in real-time. In this case, character identification is based on strokes.
The following list includes several machine learning methods for handwriting recognition:
- Convolutional Neural network
- Semi Incremental Recognition
- Incremental Recognition
- Line and word segmentation
- Part-based method
- Slope and Slant correction method
- Ensemble method
We’ll discuss each in detail in the following section.
Choosing the Right Approach to HCR in Machine Learning

As was already noted, several approaches may be used to recognize human handwriting with machine learning. This can be done with the help of image recognition and processing, but it’s far more challenging compared to the traditional tasks with image data.
Everyone has their own unique handwriting style, making image recognition in HCR so difficult. As a result, handwriting will be harder to identify than writings from computers, which already have a clear standard form. There will be several methods presented. But to spare you the details, the convolutional neural network (CNN) approach has the highest accuracy, while the Slope and Slant Correction Method demonstrates the lowest accuracy rate.
— Convolutional Neural Networks
Pros: The most popular method in HCR. The accuracy of handwritten text recognition depends on trained CNN, which is considered a successful method in some handwriting and computer recognition applications.
Cons: It requires many samples throughout the training process for the most accurate and reliable results. Plus, CNN training is time-consuming and there’s an excessive dependence on hardware.
— Support Vector Machines (SVM)
Pros: In contrast to neural networks, SVM focuses on learning from examples and structural behavior and has superior generalization due to structural risk reduction.
Cons: Choosing a good kernel function, as well as comprehending and interpreting, is challenging. Picturing the effects of SVM models is also a tricky business.
— Incremental Method
Pros: A much easier recognition stage, compared to other methods, given that the model only observes newly entered strokes while prior strokes are not noticed.
Cons: The segmentation process can be tricky.
— Semi-Incremental Method
Pros: The waiting time is not really obvious, and this method takes into account recent strokes and prior portions.
Cons: Other approaches should be used in addition to semi-incremental ones. Also, it operates in a more convoluted manner than the pure incremental technique.
— Line and Word Segmentation Method
Pros: Word segmentation is significantly more challenging if this approach needs to recognize the dial. A strong procedure may be projected using this method for printed documents. Line, word, and character segments are all possible in writing.
Cons: This method is unable to detect patterns in human handwriting.
— Part-Based Method
Pros: Low precision makes it reliable enough for writing recognition. If there’s a line or curve in the text, it’s still easy to recognize since this method is independent of the overall framework. It can be used for cursive script and scenery images.
Cons: The training procedure requires a considerable amount of samples to achieve a high accuracy rate.
— Slope and Slant Correction Method
Pros: Simpler segmentation and better writing recognition accuracy.
Cons: Inadequate for recognizing human handwriting.
— Ensemble Method
Pros: A novel classification method in ML, showcasing highly accurate results. The ensemble approach is used to increase the predictive performance of static learning strategies or model fitting.
Cons: Line segmentation elements can negatively impact the accuracy of the results.
— Zoning Method
Pros: Quite a successful approach to solving HCR tasks in machine learning that provides accurate results.
Cons: Many zones must be included in an image because a lesser number will result in lower accuracy.
Databases for Handwriting Recognition
To put it simply, the acquired handwriting will subsequently be turned into a database. For instance, many samples from each letter might be captured and utilized as a database. HCR databases fall under two categories:
— Handwriting characters databases
- NIST database
- MNIST database
- TICH database
- New COUT database
— General handwritten text databases
- IAM Database
- RIMES database
- Osborne database
The Methodology and Applications of AI Handwriting Recognition
One of the most capricious research areas in the pattern recognition domain is, without doubt, AI handwriting recognition. You must admit, it’s much harder for machines to decipher human handwriting, bank checks, or translate handwritten documents into a structural text form. Nevertheless, HCR can be even used for writer identification, safe driving, or as reading assistance for blind people.
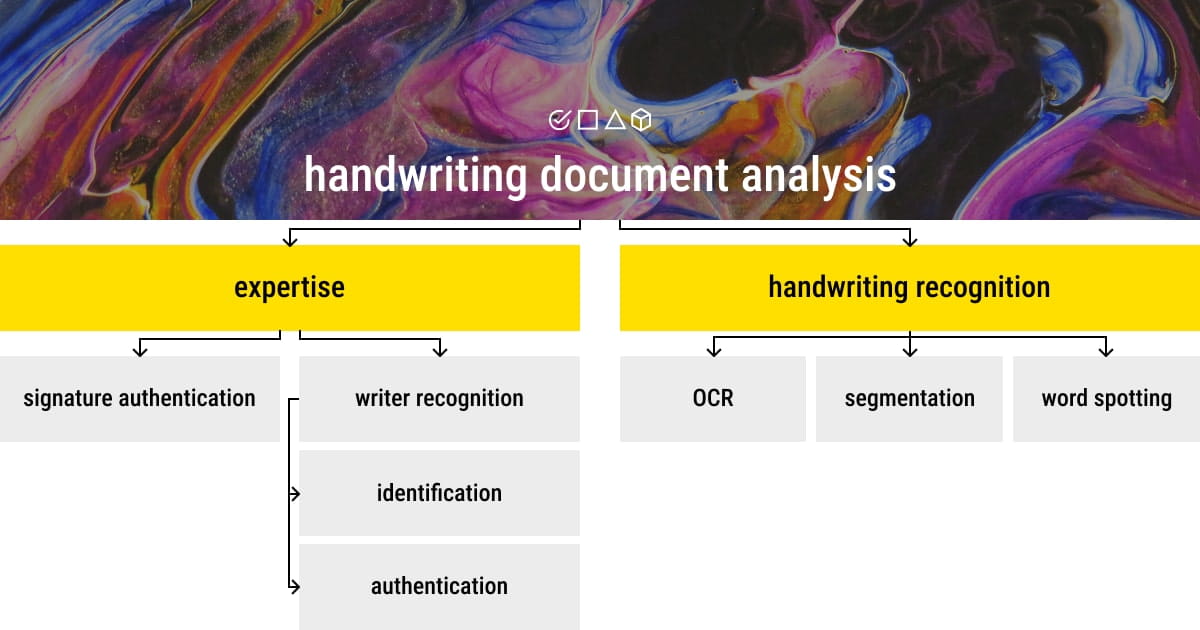
The field of handwriting recognition is seeing the emergence of new applications as the methods for digitizing handwritten documents and the tools for online handwriting capture advance. Applications for document analysis and recognition are divided into two categories: expertise and handwriting recognition. More specifically, writer authentication, as well as signature verification and authentication, are among the areas of expertise. Word spotting, word and character segmentation, and OCR are all components of handwriting recognition.
Handwritten Character Recognition
To detect handwritten characters, a variety of algorithms and classification techniques have been proposed, including statistical discriminating approaches such as Neural Networks, SVM, and CNNs. Additionally, nonparametric models are frequently applied, including K-nearest neighbor classifiers.
Numerous datasets have been suggested in the handwriting recognition literature to test the proposed system. The MNIST dataset is the most frequently utilized in the study on handwriting recognition, among other datasets. It includes actual samples that were gathered from the US returned mail.
However, apart from ML, deep learning methods are quite popular for HCR tasks, including Deep Neural Network (DNN), Deep Belief Network (DBN), and CNN. DL outperforms other classification algorithms by generating incredibly low error rates, making it useful for reading handwritten characters. But even though these are advanced systems for HCR, you can never reach 100% accuracy in AI due to numerous unclear handwritings.
Word and Text Recognition
It’s tricky to effectively preserve, retrieve, share, or search through books, documents, or notes that have been written by hand. As a result, many of these texts have been converted to digital format to preserve the valuable information they contain. To convert the scanned documents into machine code, several approaches have been suggested.
Preprocessing the document and then segmenting it into either characters or words is the first step in the recognition of handwritten text. The analytical technique is used to describe the first segmentation, whereas the holistic approach is used to describe the second. Additionally, a different method that was motivated by speech recognition seeks to combine segmentation and recognition.
A word or line of text is treated as a collection of subunits or graphemes, such as letters, in analytical segmentation. To identify each character independently, it attempts to divide the text line into letters. This method may be used with scripts that use alphabetic characters, such as those of Latin and Arabic. The segmented characters may be recognized using classifiers like the Bayesian classifier, SVM, and K-nearest neighbor. However, the biggest drawback of this approach is segmenting words into letters.

Signature Verification
In signature verification, the main task is to check if the signature is genuine and belongs to the person concerned. But the problem is that there are no two signatures alike, so how can AI detect a forgery?
The sensitive data for this task can be obtained from physical items (e.g., a key or badge), a PIN or password, and personal identifying characteristics (a fingerprint, retina, or signature). Signature verification has previously been an offline issue. Important papers, like checks and invoices, need the signatures to be verified. Online signatures, in contrast, provide the advantage of practically noise-free capture of the signature. As such, because they are typically noisy, offline signatures require a more rigorous pre-processing stage.
It’s necessary to compare the function parameters of an unknown signature to the actual parameters of the signature. Many options were taken into consideration: comparing the parameters, dividing the sets into segments and then comparing them, or a matching method. The common methods used in this domain include Dynamic Time Warping (DTW), Euclidean distance classifier, and classifiers like Hidden Markov Models (HMM), Support Vector Machines (SVM), and pixel matching technique.
Handwritten Word Spotting/Indexing
The requirement for indexing becomes increasingly important as more and more handwritten documents are being digitized. A technique called word spotting enables a user to look for keywords in spoken or written material.
In fact, word spotting was primarily created for Automatic Speech Recognition (ASR), but is now used for indexing a rising amount of handwritten texts. Some methods adapt voice recognition techniques, even though speech is analog in nature and handwritten documents are spatial in form. Eventually, handwritten document-specific approaches and algorithms were created.
Early indexing tasks were using traditional OCR techniques, and the results were sent to specialized search engines for word searches. But OCR simply fails when it comes to indexing words. Today, many algorithms and techniques are employed to spot words in the text. These techniques include template matching, learning-based approaches, and shape code mapping.
On a Final Note

Well-organized documentation matters for almost every industry today. Yet, with the beginning of mass digitization, it became necessary to devise effective methods for identifying and evaluating these documents.
Handwritten text recognition is quite a dynamic research area in artificial intelligence, but there are still many issues that need to be solved using the latest techniques and tools in ML or DL. But the richness and variety of human handwriting, coupled with the documents or other valuable papers we write (or that machines create), continue to be the fundamental problem in HCR.
Still, even though such issues are prevalent in this field, the efforts must be focused on creating large databases with professionally annotated datasets containing handwritten text. Why is data labeling so crucial here? The answer is simple. Annotated datasets help enhance the performance of many handwriting recognition applications, which we’ve mentioned earlier. Contact our Label Your Data team to find out more about annotation solutions for your HCR initiative!
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.