Pose Estimation: Detecting Human Movement with Keypoints

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Pose Estimation?
- 2D vs 3D Pose Estimation: Which One Do You Actually Need?
- Top-Down vs Bottom-Up: How Multi-Person Pose Estimation Works
- Key Pose Estimation Models: ViTPose, RTMPose, YOLO-Pose
- Common Pose Estimation Use Cases
- How to Build Better Pose Estimation Models with Labeled Data
- About Label Your Data
- FAQ

TL;DR
- Pose estimation gives you a skeleton of keypoints per frame, so your model can reason about movement and not just presence.
- ViTPose wins on accuracy, RTMPose runs real-time on CPU and mobile, YOLO-Pose handles detection and keypoints in one pass.
- Accuracy ceilings come from annotation consistency, which is where most in-house keypoint pipelines break first.
ViTPose, RTMPose, YOLO-Pose, and the rest of the open-source pose estimation stack are good enough that model choice is no longer the hard part of shipping a pose-driven product. The hard part is the keypoint schema, the occlusion handling, the evaluation strategy, and the data annotation pipeline behind all of it.
In this article, we cover each of these challenges and how they shape your pose estimation model’s accuracy.
What Is Pose Estimation?
Pose estimation is the computer vision task of detecting and localizing anatomical keypoints, such as elbows, knees, wrists, ankles, and facial landmarks, in images or video. Connecting those keypoints with predefined edges produces a skeleton that captures posture and motion frame by frame.
That structural output is what enables downstream tasks like action recognition, gesture control, gait analysis, ergonomic assessment, and driver attention scoring. A detector gives you presence. A pose model gives you behavior.
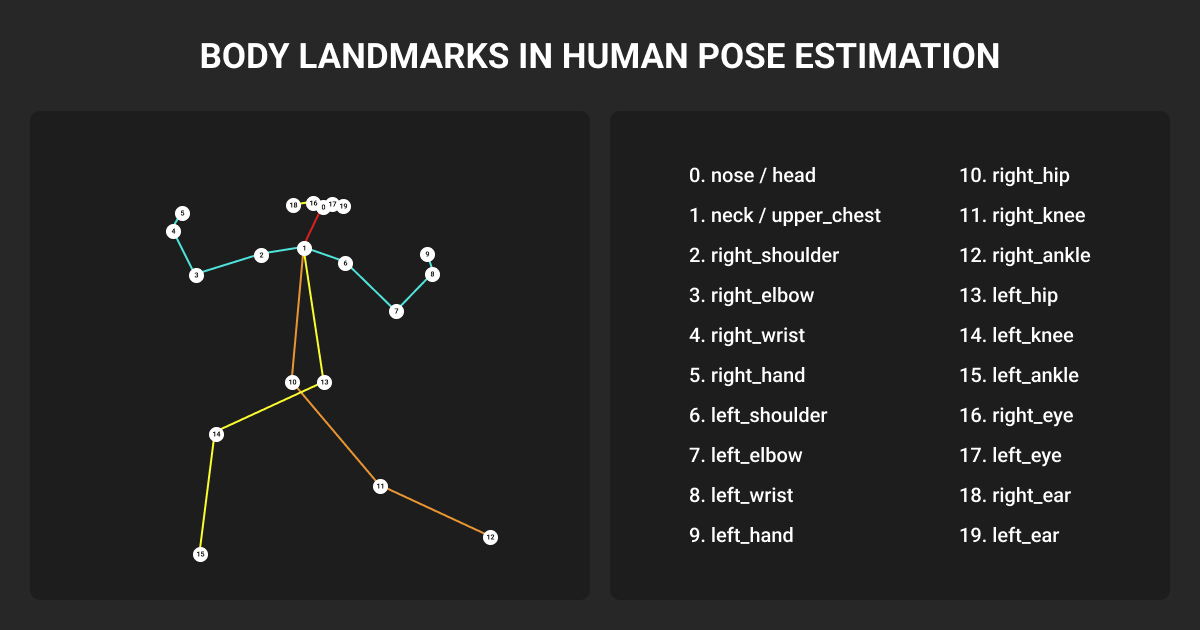
Most production systems today work with the 17-keypoint COCO schema (nose, eyes, ears, shoulders, elbows, wrists, hips, knees, ankles), though specialized applications often extend this. COCO WholeBody annotates 133 keypoints per person to cover face, hands, and feet. Animal pose datasets like AP-10K and APT-36K use their own schemas.
The right keypoint definition depends entirely on what you need the model to reason about.
Read more: What is keypoint annotation and how does it work?
2D vs 3D Pose Estimation: Which One Do You Actually Need?
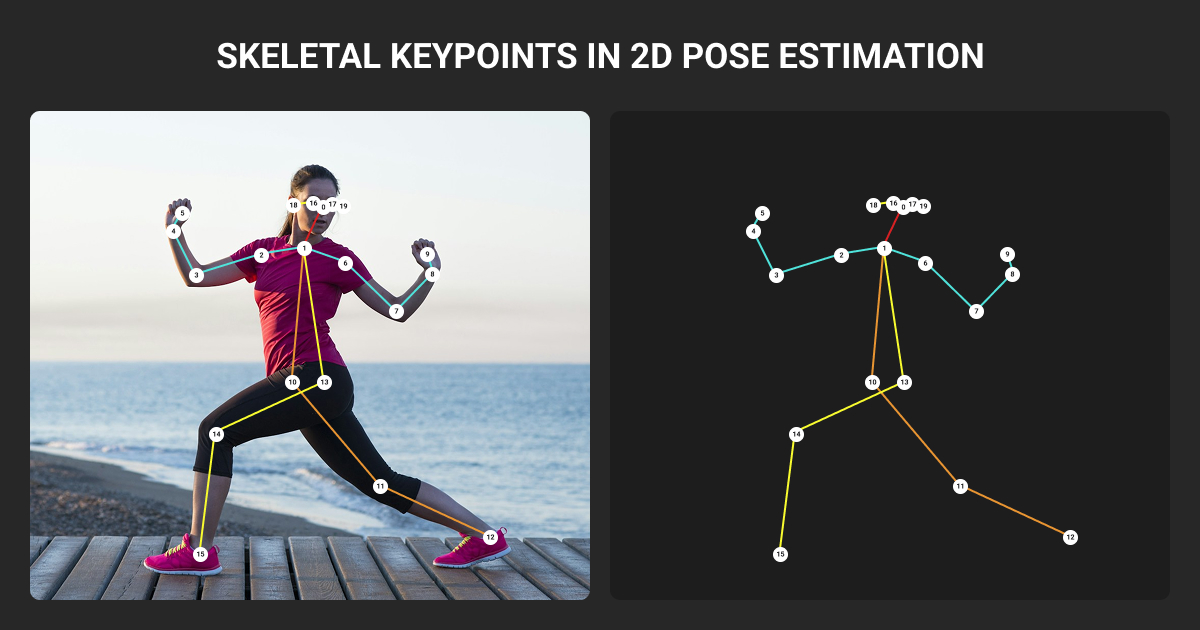
2D pose estimation predicts pixel coordinates (x, y) for each keypoint. 3D pose estimation predicts (x, y, z) in metric or normalized space, recovering depth and articulation in the real world.
For most consumer and fitness applications, 2D is sufficient and dramatically cheaper to train and deploy. You can infer repetition (rep) counts, joint angles in the camera plane, and basic form cues from 2D skeletons alone.
3D becomes worth the data annotation cost when your product depends on depth-aware reasoning:
- AR avatars that need correct limb foreshortening
- Biomechanical analysis for sports science or rehab
- Robot teleoperation
- Driver monitoring that separates a mirror check from a drowsy head drop
There are two ways to do 3D pose estimation. Single-image 3D lifts a 2D pose to 3D using learned priors, which is convenient but ambiguous under occlusion. Multi-view or sensor-fused 3D uses calibrated cameras, depth sensors, or IMUs, which is more accurate but harder to scale to consumer hardware.
Top-Down vs Bottom-Up: How Multi-Person Pose Estimation Works
Multi-person pose estimation pipelines come in two architectural patterns.
Top-down methods first detect each person with a bounding box, then run a keypoint estimator on each cropped region independently. They tend to be more accurate because the pose model sees a clean, person-centered crop. The cost is that inference time scales linearly with the number of people in the scene.
Bottom-up methods detect all keypoints in the entire image at once, then group them into individual skeletons using association machine learning algorithms like Part Affinity Fields (the approach pioneered by OpenPose). Inference time stays roughly constant regardless of crowd size, but the association step gets brittle in dense or heavily occluded scenes.
Today, most production systems use top-down pipelines because person detection is fast and cheap, and the accuracy advantage matters for downstream metrics. Bottom-up still wins in very crowded scenes, like retail footfall analytics or stadium broadcasts, where running a pose model per person is computationally prohibitive.
Evaluation is standardized around Object Keypoint Similarity (OKS), a distance-based analog of IoU. OKS normalizes the Euclidean error of each predicted keypoint by the object scale and a per-keypoint constant (sigma) that reflects how consistently human annotators agree on that keypoint’s location.
This is the part that surprises a lot of teams: your model’s reported COCO AP is bounded by the noise in your labeled data. If your annotators disagree more than the COCO sigmas allow for, your model hits an accuracy ceiling no amount of training can fix.
What usually breaks pose estimation systems is that the keypoints are just wrong. We kept seeing this happen because our annotation guidelines weren’t clear, especially when a limb was hidden. We wrote one clear rulebook and started spot-checking the work, and that small change made our final animations noticeably smoother.

 Founder and CEO, Superdirector (Enlighten Animation Labs)
Founder and CEO, Superdirector (Enlighten Animation Labs)
Key Pose Estimation Models: ViTPose, RTMPose, YOLO-Pose
The pose estimation model landscape has consolidated around three workhorses, each tuned to a different point on the accuracy-latency curve.
ViTPose
Applies a plain Vision Transformer backbone with minimal modifications. ViTPose-G with one billion parameters set a new state of the art on COCO test-dev. ViTPose++ extends the architecture with multi-dataset training, hitting top results on COCO, AI Challenger, MPII, OCHuman, and animal benchmarks AP-10K and APT-36K simultaneously.
Use it when accuracy is the gating constraint and you have GPU budget at inference.
RTMPose
RTMPose-m hits 75.8% AP on COCO at 90+ FPS on an Intel i7-11700 CPU and 430+ FPS on a GTX 1660 Ti GPU. RTMPose-s reaches 72.2% AP at 70+ FPS on a Snapdragon 865 mobile chip. It uses a SimCC head that treats keypoint localization as a classification problem on discretized coordinates, which removes the heatmap upsampling cost.
This model from the MMPose team is the go-to when you need real-time performance on commodity hardware.
YOLO-Pose
Currently YOLO26-Pose in the Ultralytics family, the model bundles person detection and keypoint regression in a single end-to-end pass. It is the easiest to integrate when your team already runs YOLO for object detection, and it ships with native edge deployment via TensorRT, ONNX, OpenVINO, and CoreML.
For most CV teams, choosing the model is easy; getting the keypoint annotation right is the hard part.
Common Pose Estimation Use Cases
Pose estimation runs in production across many verticals, but each one needs its own keypoint schema and handles edge cases differently.
- Fitness and sports analytics. Repetition counting, form feedback, and swing analysis, often with custom keypoints added for shoes, racquets, or barbells.
- AR/VR and gesture interfaces. Avatar driving and sign language recognition, where each hand alone needs 21 keypoints labeled precisely under heavy self-occlusion.
- Healthcare and rehab. Range-of-motion assessment, fall detection, and recovery tracking, all demanding medical-grade annotation accuracy.
- Robotics and human-robot interaction. Operator pose for teleoperation, worker pose for collaborative robots, and animal pose for agritech.
- Retail and shopper analytics. Dwell-time, queue detection, and shelf interaction, usually bottom-up across crowded multi-person scenes.
- Driver and in-cabin monitoring. Facial landmarks, gaze, head pose, and upper-body keypoints now power every compliant DMS stack, since Euro NCAP’s 2026 protocols make driver monitoring a hard requirement for a five-star rating.
Driver monitoring is the hardest of these cases to label for. The data has to capture head-based tracking, eye-based tracking, and body lean across day and night, sunglasses, facial hair, and partly hidden eyes, which puts it closer to medical imaging than to a consumer fitness app.
Read more on labeling driver-facing perception in our guide to ADAS data annotation.
How to Build Better Pose Estimation Models with Labeled Data
Pose estimation models live or die on keypoint annotation quality. Architectures plateau quickly, and training data is what separates a 65% AP demo from an 80% AP production system.
When Nex, a US motion entertainment company building camera-driven games, needed broader coverage of real player movements, our dedicated team of 9 annotators handled skeleton annotation and validated pre-annotations across nearly 15,000 images, alongside a parallel data collection track for the specific poses they were missing. The result was a 12% improvement in pose estimation model accuracy and measurably better body detection consistency.
Nex’s Deep Learning Engineer noted that our work at Label Your Data directly improved their motion tracking model accuracy:
Label Your Data’s expertise significantly improved the accuracy of our motion tracking models. This translated to a more consistent and enjoyable gameplay experience for our users, which aligns perfectly with Nex’s core mission of promoting physical activity through engaging games.
 Deep Learning Engineer at Nex
Deep Learning Engineer at Nex
Based on our experience with Nex and other human pose estimation projects, three things tend to break when teams try to scale keypoint annotation in-house instead of partnering with an expert data annotation company.
Annotator consistency on ambiguous keypoints
The COCO sigmas exist because hips, elbows, and shoulders are genuinely hard to pinpoint, even for trained humans. Without a written labeling specification, calibration sessions, and inter-annotator agreement (IAA) tracking, you get drift across annotators and across weeks. That drift looks like a noisy validation set, and it ceilings your model’s measurable accuracy.
Occlusion and visibility flags
COCO uses a three-state visibility flag (visible, occluded but labeled, not labeled). Many in-house teams collapse this to two states or skip it entirely. The downstream effect is a model that hallucinates keypoints behind walls or under jackets, because it never learned that occluded should still be located but flagged.
Edge cases that look rare but appear constantly
Side-view athletes, prone or supine subjects, children, wheelchairs, partial bodies at frame edges, infrared imagery, fisheye distortion. These are 1% of your machine learning dataset and 30% of your production failures. You only see this pattern after labeling at volume.
This is where dedicated teams delivering data annotation services earn their keep. Label Your Data is focused on training data for AI systems operating in complex environments, where consistency at scale is what determines your model performance.
About Label Your Data
If you choose to delegate keypoint annotation for pose estimation, run a data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How many labeled images do I need to train a pose estimation model?
For fine-tuning a pretrained model like RTMPose or ViTPose on a custom schema, you can start with around 5,000 to 10,000 labeled instances for useful results. Training from scratch on a new domain usually requires 50,000+ annotated images to match COCO-pretrained baselines.
What is the difference between pose estimation and action recognition?
Pose estimation predicts where the keypoints are in a single frame. Action recognition predicts what the subject is doing over a sequence of frames. Most action recognition pipelines run pose estimation first, then feed the keypoint sequences into a temporal model.
Can pose estimation work without bounding boxes?
Bottom-up methods do this directly. Top-down methods need a person detector first, but the detector and pose model are usually trained and deployed as a single pipeline.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.