PyTorch vs TensorFlow: Comparing Deep Learning Frameworks

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Should I Use PyTorch or TensorFlow?
- Quick PyTorch vs TensorFlow Frameworks Overview
- Ease of Use and Debugging
- Flexibility and Research Workflows
- Deployment and Production
- Performance, Scalability, and Hardware
- Ecosystem, Community, and Tooling
- Which Framework Fits Your Use Case: PyTorch vs TensorFlow
- Can You Switch Later Between PyTorch vs TensorFlow?
- What Else You Need to Succeed with PyTorch or TensorFlow
- About Label Your Data
- FAQ

TL;DR
- PyTorch is the stronger default for most new AI projects, especially LLMs, generative AI, and research-heavy work.
- TensorFlow still wins when deployment matters most, especially for mobile, browser, edge, and TensorFlow-native production stacks.
- Raw speed rarely decides the PyTorch vs TensorFlow choice, but your teamєs skills, model ecosystem, and target runtime do.
- Keras 3 gives teams more flexibility, but it does not remove the need to test real deployment paths early.
- No framework can fix bad data, so clean labels and strong QA matter as much as the model stack.
Choosing between PyTorch and TensorFlow is a project-risk decision. The right framework choice helps your team build, debug, deploy, and maintain a deep learning model with the least friction.
With the wrong framework, your model may not export cleanly to the target device. The architecture your researchers want may ship PyTorch-first. Or the training data underneath may be too noisy for the framework to matter.
The idea was always that PyTorch is for research and TensorFlow is for production. But that assumption doesn’t work in 2026 anymore. Read on to learn why and which framework to choose for your project..
Should I Use PyTorch or TensorFlow?
Use PyTorch for most new deep learning projects in 2026, especially for research, LLMs, generative AI, and rapid prototyping. It’s Python-first, easier to debug, and sits at the center of the open-model ecosystem, with the large majority of new architectures and Hugging Face models shipping PyTorch-first.
Choose TensorFlow when your deployment target or existing stack makes it the lower-friction option: mobile and edge through LiteRT, in-browser inference through TensorFlow.js, Google Cloud TPU training, or established TFX and TensorFlow Serving pipelines.
For standard server-side GPU training the performance difference is marginal, so the deciding factors are your deployment target, your team’s existing skills, and the ecosystem your models come from rather than raw framework speed.
Quick PyTorch vs TensorFlow Frameworks Overview
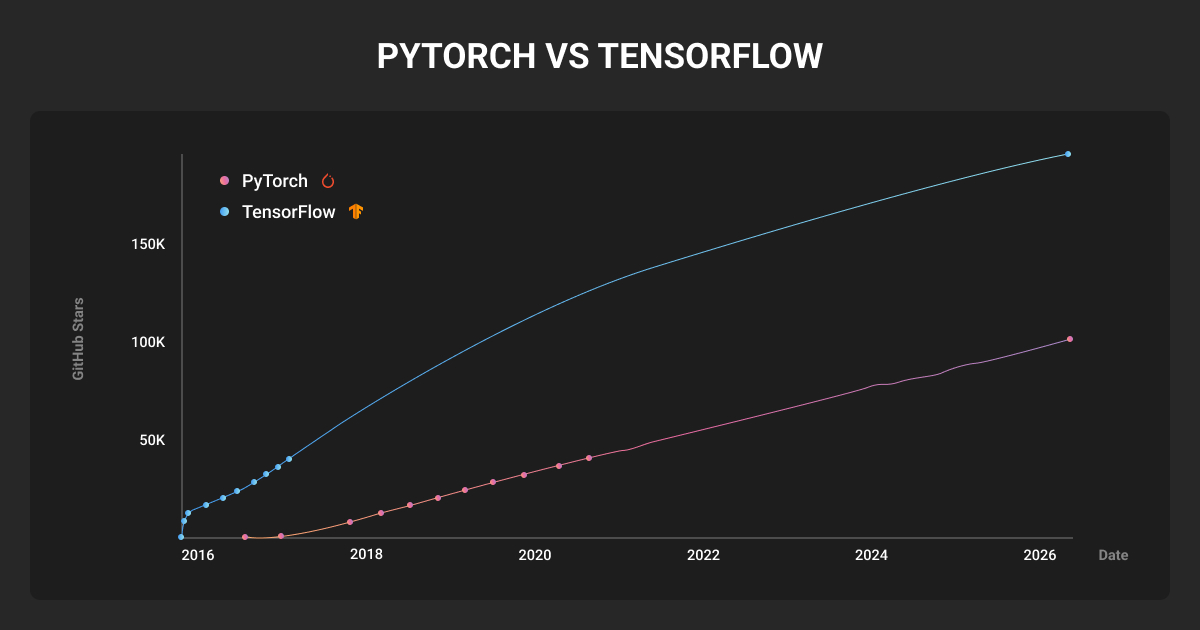
PyTorch is a Python-first deep learning framework governed by the PyTorch Foundation under the Linux Foundation, with Meta as the largest contributor. Its defining feature is torch.compile, which JIT-compiles eager Python code into optimized GPU kernels.
That gives PyTorch static-graph-level speed without forcing developers to give up dynamic, line-by-line debugging.
TensorFlow is Google’s deep learning framework with eager execution on by default since 2.0. Its high-level API, Keras, changed in late 2023. Keras 3 is a full rewrite that runs on TensorFlow, PyTorch, or JAX, with OpenVINO available for inference.
Teams can author a model once in Keras and switch the backend with a single environment variable.
PyTorch is the stronger default for research-heavy and open-model-heavy teams. It works well with custom training code, and sits at the center of much of today’s generative AI ecosystem. TensorFlow is strongest when deployment matters more than research speed, especially for mobile, browser, edge, TPU, and TensorFlow-native production pipelines.
| Axis | PyTorch | TensorFlow | Practical notes |
| Ease of use | Pythonic, eager, easy to inspect | Keras is clean; lower-level TensorFlow can feel layered | PyTorch for custom work; Keras/TensorFlow for standard workflows |
| Research | ✅ Strong open-model momentum | Capable, but less central to many new open-model releases | PyTorch leads |
| LLMs and generative AI | ✅ Strong Hugging Face, diffusion, and serving ecosystem | Less common as the first release target | PyTorch leads |
| Server production | Strong but modular | Coherent first-party stack with SavedModel, Serving, and TFX | Context-dependent |
| Mobile and edge | ExecuTorch is improving | ✅ LiteRT is mature and Google-backed | TensorFlow leads |
| Browser | Usually indirect through export paths | ✅ TensorFlow.js is first-party | TensorFlow leads |
| Performance | torch.compile, DDP, FSDP | XLA, tf.distribute, TPU support | No universal winner |
| TPU | Supported through PyTorch/XLA | ✅ More native TensorFlow path | TensorFlow or JAX |
| Best fit | Research, LLMs, custom training | Mobile, browser, edge, TF-native production | Choose by deployment target |
Both frameworks support eager execution, graph compilation, distributed training, and cloud deployment. The deciding factor is where the model will run, what your team already knows, which infrastructure you use, and which ecosystem contains the tools you need.
Ease of Use and Debugging
PyTorch is usually easier for custom model development. You can drop into a debugger, print intermediate tensors, inspect gradients, and follow stack traces that point back to normal Python code.
This DL framework helps when building a custom loss, testing a nonstandard training loop, or debugging dynamic control flow.
TensorFlow is easier when teams stay inside high-level Keras patterns. For standard supervised learning, Keras gives teams a concise way to define, train, evaluate, and save models. That reduces onboarding time when teams do not need low-level control.
Things get harder when TensorFlow users move beyond the high-level API.
Traced @tf.function code can be harder to debug because errors may point to graph tracing or generated code, not the original line the engineer wrote. That doesn’t affect every Keras workflow, but it matters if your team is building custom training logic.
PyTorch is usually easier for custom work and imperative debugging. Keras/TensorFlow is often easier for standard model-building patterns.
Flexibility and Research Workflows
PyTorch is usually the better choice for research, prototyping, LLMs, and generative AI because the ecosystem is more active there.
New open models and research implementations often appear in PyTorch first, so teams can start from public checkpoints, reuse reference code, and fine-tune faster. TensorFlow can support the same work, but it often requires more porting, weight conversion, or custom implementation.
Unless deployment requirements point clearly to TensorFlow, PyTorch is the more practical default for research-heavy workflows.
The practical factor I would prioritize when choosing between PyTorch and TensorFlow is how quickly your team can diagnose and fix model failures six months after deployment. Every AI system eventually drifts because data changes. A framework that matches your team’s debugging habits, tooling and deployment process will save far more engineering time than one that wins a performance benchmark by a few percentage points.

 Full Stack Engineer & Tech Lead, Know Roaming
Full Stack Engineer & Tech Lead, Know Roaming
Deployment and Production
PyTorch is no longer research-only, and TensorFlow is no longer the only production option. The better choice depends on the target runtime.
For server-side production, TensorFlow still offers the cleaner first-party path through TensorFlow Serving, with built-in support for production environments and HTTP/gRPC APIs.
PyTorch production is more modular; teams often combine PyTorch export paths with ONNX Runtime, TensorRT, Triton, vLLM, or managed cloud serving. This works well for LLM teams, but it adds more decisions around export formats, runtime setup, dependencies, and monitoring.
But TorchServe should not be treated as the default PyTorch serving option anymore, since the project is no longer actively maintained.
For mobile and edge, TensorFlow has the stronger first-party path through LiteRT, Google’s on-device framework for ML and GenAI deployment. PyTorch’s ExecuTorch is improving on-device inference, but TensorFlow still has the more mature mobile, browser, and embedded ecosystem.
Performance, Scalability, and Hardware
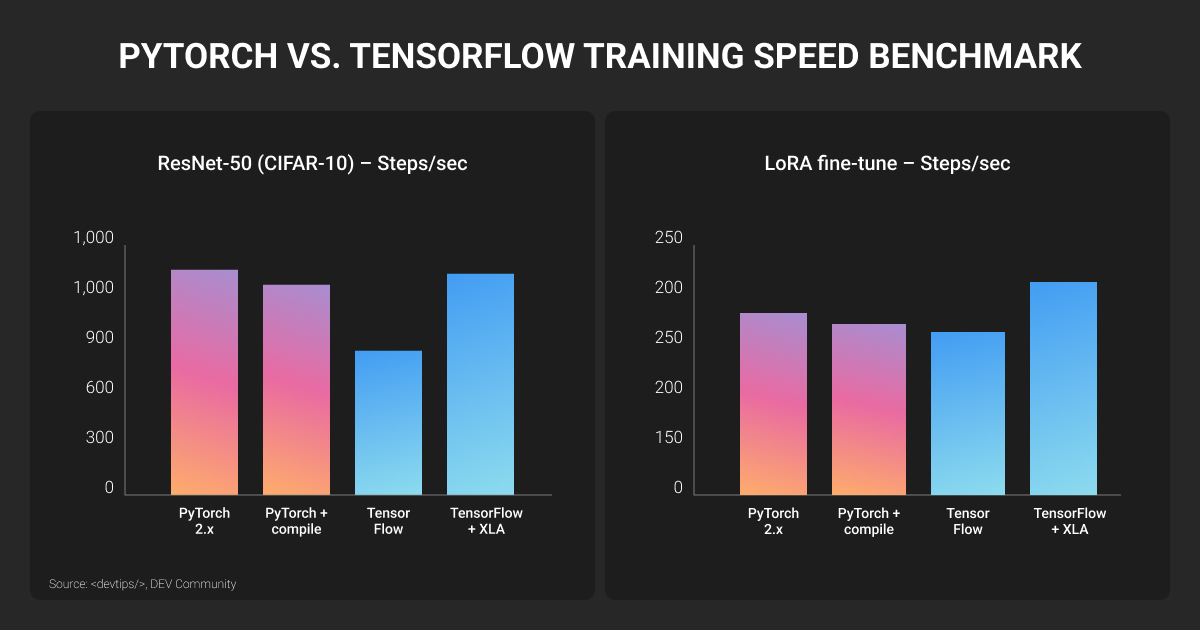
There is no universal performance winner between PyTorch and TensorFlow. Speed depends on the model, hardware, batch size, precision mode, compiler path, and runtime.
PyTorch 2.x reduced much of the performance gap with torch.compile, which optimizes many PyTorch programs with minimal code changes. TensorFlow still has a strong graph execution and compiler story, especially for TPU-heavy workflows.
For multi-GPU and large-model training, PyTorch has strong momentum through DistributedDataParallel, FullyShardedDataParallel, DeepSpeed-style workflows, and the wider LLM training ecosystem. TensorFlow’s tf.distribute.Strategy remains a solid option for TensorFlow-native teams and TPU-oriented setups.
The practical answer is to benchmark your own workload. Test training and inference on your real model, hardware, batch sizes, quantization plan, export path, and serving runtime, since these choices can affect performance as much as the framework itself.
Ecosystem, Community, and Tooling
PyTorch has the stronger ecosystem for open models, NLP, LLMs, diffusion, and research code. It is often the better fit for teams using public checkpoints, fine-tuning foundation models, or tracking new architectures.
TensorFlow is stronger across specific deployment surfaces. TensorFlow.js supports browser and Node.js workflows, LiteRT covers Google-backed on-device deployment, and TensorFlow Serving and TFX support production pipelines.
Talent also matters; researchers and generative AI engineers are often more PyTorch-heavy, while enterprise teams with legacy ML platforms, mobile ML apps, or Google Cloud pipelines may have deeper TensorFlow experience.
For technical leads, the best framework is the one the team can build, deploy, and maintain confidently.
The practical factor that teams should prioritize is their endpoint deployment. If you have an enormous existing pipeline or you predominantly work from Google Cloud and use their TPU hardware, then TensorFlow would be the better option. Unless your workloads are deployed on NVIDIA GPU clusters, then PyTorch may be a better option, only because their GPU utilization is unmatched.
 CEO and CTO, HasData
CEO and CTO, HasData
Which Framework Fits Your Use Case: PyTorch vs TensorFlow
Choose PyTorch for LLMs, generative AI, diffusion, Hugging Face workflows, research prototypes, and custom model development. It gives you fast iteration, strong debugging ergonomics, and the most direct path into much of today’s open-model ecosystem.
Choose TensorFlow for mobile apps, browser ML, embedded AI, TensorFlow-native production systems, and teams already standardized on SavedModel, TensorFlow Serving, TFX, or LiteRT.
Choose TensorFlow or JAX for TPU-heavy projects on Google Cloud. PyTorch/XLA is viable, but TensorFlow and JAX remain more natural options when TPUs are central to the compute strategy.
Choose Keras 3 when your team wants a high-level API and some backend flexibility. This is most useful for standard model-building workflows where you want to avoid committing too early to TensorFlow, PyTorch, or JAX. It is not a magic portability layer for every low-level optimization or deployment target, so test backend behavior before treating it as a migration strategy.
| Use case | Best choice | Why | Watch out for |
| Research, LLMs, and generative AI | PyTorch | PyTorch is strongest in the open-model ecosystem, including Hugging Face, vLLM, and diffusion tooling. | Plan the export path early if you need browser or mobile deployment later. |
| Mobile, edge, and browser | TensorFlow | LiteRT supports Android, iOS, and microcontrollers, while TensorFlow.js is built for browser ML. | ExecuTorch is improving, but TensorFlow still has the stronger first-party edge path. |
| Server-side production inference | Contextual | TensorFlow offers a smoother first-party stack through SavedModel and TFX. PyTorch also works well with ONNX Runtime, TensorRT, or cloud-native serving. | Choose based on your existing stack, runtime, and team expertise. |
| TPU-heavy training on Google Cloud | TensorFlow or JAX | Both offer a cleaner native TPU path. | PyTorch/XLA is viable, but less natural for TPU-first workflows. |
| Teams already on Hugging Face or PyTorch | PyTorch | It fits the ecosystem and reduces migration friction. | Only reconsider if deployment requirements strongly favor TensorFlow. |
| Cross-platform or uncertain future | Keras 3 | It lets teams write model code once and switch between TensorFlow, PyTorch, or JAX backends. | Test backend behavior before treating it as a full migration strategy. |
Stick with what your team already knows when the framework difference is small. A TensorFlow-fluent team may ship a standard server-side model faster in TensorFlow than by switching to PyTorch. A PyTorch-fluent team can still build for mobile, but should plan export and device testing early.
Can You Switch Later Between PyTorch vs TensorFlow?
Switching is possible, but it takes work. The cost depends on how much framework-specific code you write.
ONNX can help move trained models between frameworks and runtimes, especially for standard architectures. The friction starts with custom operators, unusual layers, dynamic shapes, and backend-specific behavior.
Keras 3 can reduce early lock-in by letting teams write high-level model code across supported backends. But backend-agnostic code often means giving up framework-specific optimizations. If your team needs a PyTorch-native LLM stack or a TensorFlow-native mobile path, choose the native framework instead of abstracting over both.
The safest move is to decide early what needs to stay portable. Keep model architecture, evaluation logic, and dataset versioning clean. Avoid putting critical business logic inside framework-specific training scripts unless the performance or deployment gain is worth it.
What Else You Need to Succeed with PyTorch or TensorFlow
The framework, PyTorch vs TensorFlow, is only one layer. A working deep learning project also needs the right scaffolding around the model. Without it, many projects stall after a strong prototype.
Plan these pieces from the start:
- Data and experiment versioning. Track which dataset version produced each model. Without versioning, regressions become hard to reproduce, and teams cannot tell whether a metric drop came from code or data.
- Evaluation strategy. Aggregate accuracy can hide the failures that matter. Slice metrics by the segments and edge cases users actually hit, and keep a held-out test set you do not tune against.
- Monitoring and drift detection. Production inputs drift away from training data. Catch that shift early before quiet degradation becomes an incident.
- Retraining triggers. Decide what starts a retrain: a drift threshold, a performance floor, or a schedule. That keeps the model from silently rotting.
None of this depends on choosing PyTorch or TensorFlow. Both integrate with common MLOps tools for tracking, serving, and monitoring. That is why the framework question is only half the decision.
The larger lever sits underneath all of it: training data quality. Framework choice shapes how you build and deploy the model, but data quality determines whether it learns the right thing.
No PyTorch training loop or TensorFlow Serving pipeline can compensate for noisy labels, biased annotations, or poorly validated datasets. Choose the framework alongside deployment target, infrastructure, team expertise, model ecosystem, and data quality so the model can perform reliably after it reaches real users.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Is PyTorch the better choice for new ML projects in 2026?
For many new ML projects, especially those involving open models, LLMs, and generative AI, PyTorch has become the practical default. Developers often choose it because more current examples, model releases, and community discussions start there. TensorFlow still matters, but PyTorch is now the safer default when the team wants fewer ecosystem workarounds.
Is TensorFlow still worth using for production ML?
Yes, especially when the production stack already depends on TensorFlow tools. TensorFlow still has strong deployment paths through TensorFlow Serving, TensorFlow.js, TFX, and LiteRT. The real question is whether TensorFlow fits where and how your team plans to deploy.
When is it worth migrating from TensorFlow to PyTorch?
Migrating from TensorFlow to PyTorch makes sense when the team needs PyTorch-first models, stronger access to LLM and generative AI tooling, or a development workflow that is easier to debug and maintain.
The switch is harder to justify if the current TensorFlow stack already works well in production. Migration can involve porting model code, validating model parity, retraining engineers, and rebuilding deployment paths, so the long-term gain should clearly outweigh the engineering cost.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.