Computer Vision in Retail: Model Deployment & Data Requirements

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How AI Powered Computer Vision Can Transform Retail
- Frictionless Checkout Runs on Multi-Camera Interaction Tracking
- Shelf Intelligence Carries the Heaviest Computer Vision in Retail Data Debt
- Loss Prevention Is the Hardest Retail Computer Vision Data Problem
- Virtual Try-On and Returns Inspection Expose Paired Data Scarcity
- Annotation Requirements by Computer Vision in Retail Use Case
- How to Move a Retail Computer Vision System From Pilot to Production
- Why Label Your Data Is a Trusted Data Partner for Computer Vision Teams in Retail
- About Label Your Data
- FAQ

TL;DR
- Retail computer vision deployment is scaling, but the data layer is now what limits production performance.
- Data quality beats model scale, since cleaner training data and periodic relabeling move production metrics more than a bigger model does.
- Every computer vision in retail use case needs its own label schema, and human review stays mandatory wherever automation cannot resolve ambiguity.
Coresight Research’s 2026 survey of US retail decision-makers found 60% scaling store-intelligence technology, up 18 percentage points year over year. In-store inefficiencies still rose to 6.4% of gross sales, and only 33% had invested in the shelf-level data those systems run on.
The gap between deployment and scale is where most retail computer vision projects stall, and the bottleneck keeps moving back to data.
This guide maps how computer vision in retail works, covering the models behind each use case and the annotation work that keeps them working in a real store environment. It draws on our 6+ years experience of working with CV teams across industries, retail included, with real client stories to back it up.
How AI Powered Computer Vision Can Transform Retail
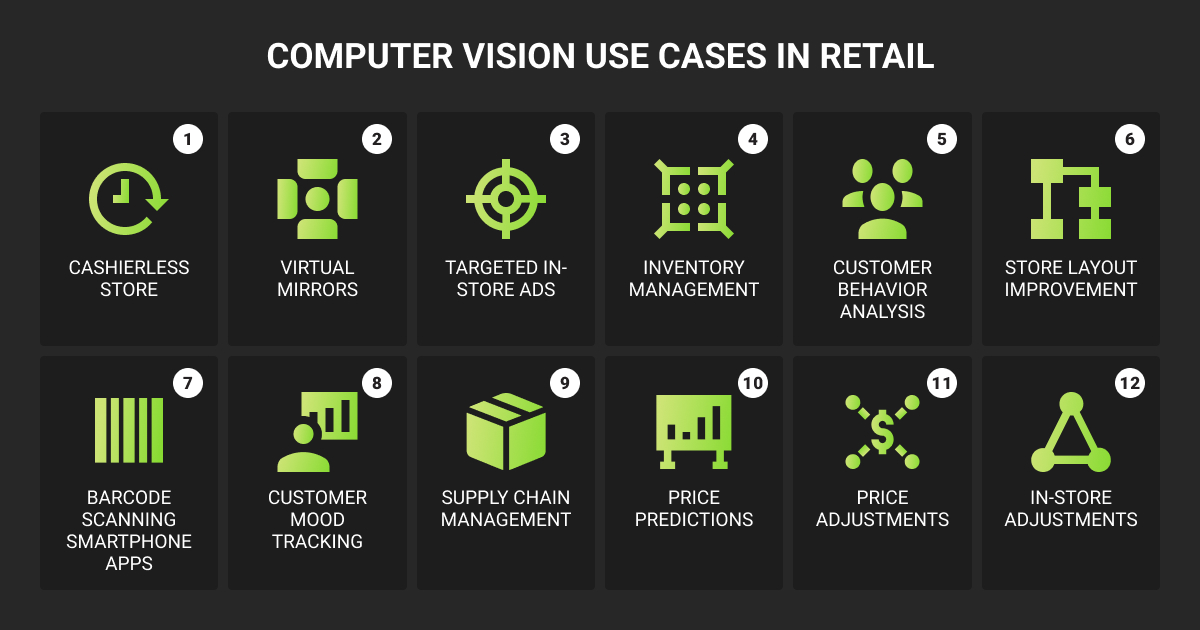
Computer vision in retail covers any AI system that reads store imagery or video data to make an operational decision: which shopper picked up which product, whether a shelf matches its planogram, or whether a returned garment is still sellable.
Cameras and sensors are the most mature layer of the store-intelligence stack. Coresight’s data puts the spend gap downstream: only 33% of retailers invested in shelf digitization, even though pricing and supply systems depend on that shelf-level data to work.
Two patterns define where budgets land:
- Retailers opt for computer vision where it removes transaction friction or closes a known leakage point such as shrink.
- Vendors with the largest installed bases compete on edge footprint and annotation scale instead of new model families.
Here’s the 2025 real-world data to back this up. Everseen reported that its platform runs on 120,000 edge AI endpoints and processes nearly 6 PB of video per day. Simbe said it had analyzed more than 60 billion shelf images against a catalog of over 18 million SKUs.
Those vendor-reported figures matter mainly as proxies for where specialized data annotation infrastructure has already industrialized.
Frictionless Checkout Runs on Multi-Camera Interaction Tracking
Checkout systems answer a harder question than object identity. They have to resolve which shopper interacted with which item and when, then confirm the cart state changed correctly.
Format dictates what works for smart checkout
Sam’s Club offers the clearest large-scale case. By October 2024 it had completed rollout of its AI-powered exit verification to all clubs, reporting that more than 64% of members used the friction-free exit and left 21% faster.
Amazon’s trajectory is more instructive. It kept expanding Just Walk Out across 170-plus third-party venues while pulling it from its own Amazon Fresh grocery stores. For CV engineers, the lesson is that this class of sensor-fusion checkout works in small, constrained baskets before it works in large-format grocery stores.
Interaction localization rules checkout models
The most useful recent academic work models the real task as interaction localization. RetailAction, released by Standard AI at the ICCV 2025 RetailVision workshop, contains 21,000 annotated samples from 10 operational convenience stores and synchronized multiview top-view video covering more than 10,000 unique shoppers.
Annotation includes 2D interaction points in both camera views, temporal ranges, and action categories such as take, put, and touch. Its DETR-based baseline with MViT-b reached 41.7 mAP overall, which shows feasibility while leaving clear headroom.
The paper bakes in a semi-automated labeling pipeline using 3D pose tracking and kinematic interaction detection. Even so, marking the exact start and end of each action still takes human judgment, and that boundary work is what decides the accuracy of machine learning datasets.
Low product retrieval precision breeds smart cart bias
For barcodeless checkout and smart carts, retrieval precision breaks first. A study from the University of the Philippines evaluated 190 open-source vision language models on grocery retrieval and found that filtered pretraining data outperformed raw scale, with up to 16.6% higher accuracy from cleaner data.
Even strong models showed a 17.5-point gap between Recall@5 and Recall@1. They place the right SKU near the top of the list but fail the final rank among near-duplicate packages. That failure mode is exactly where checkout UX breaks.
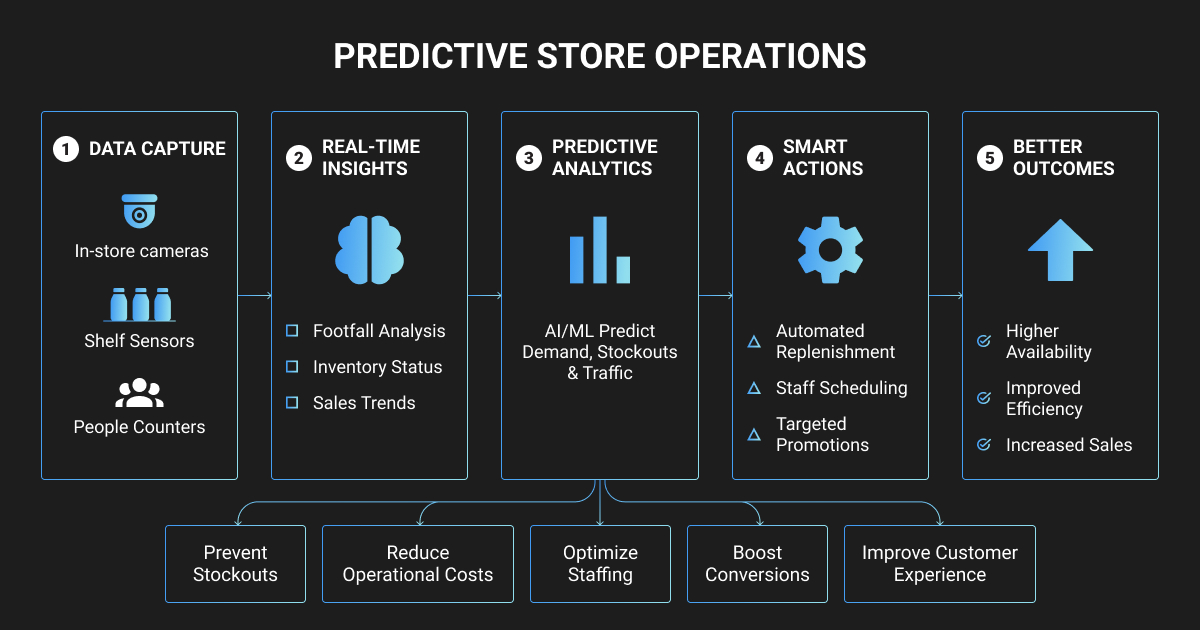
Shelf Intelligence Carries the Heaviest Computer Vision in Retail Data Debt
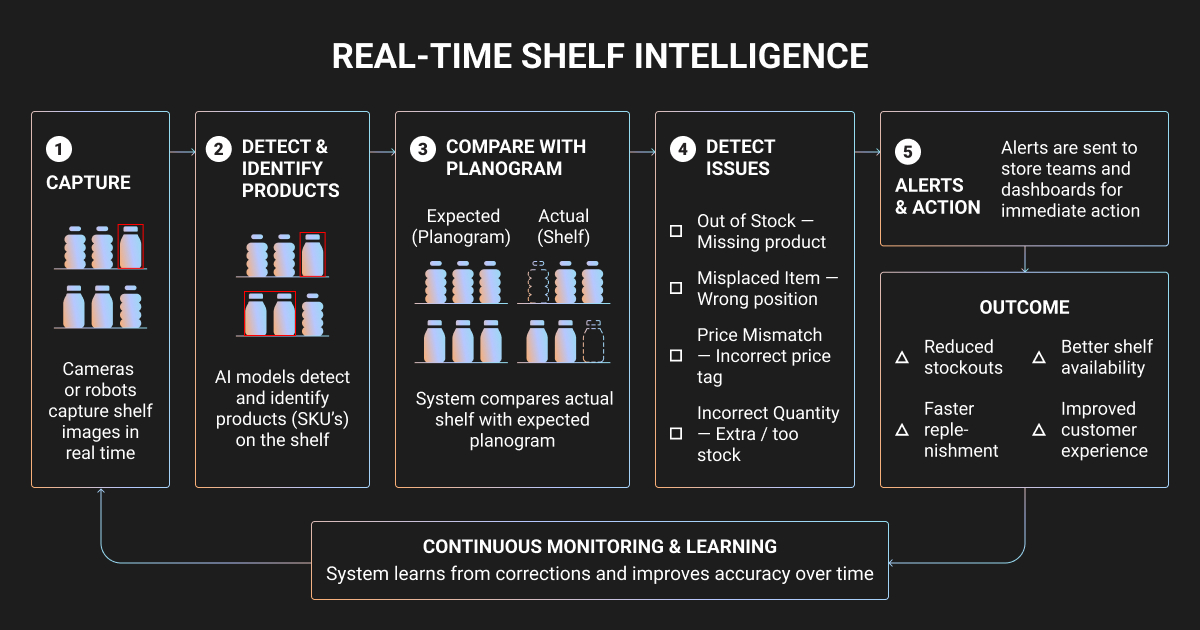
Planogram compliance and inventory systems need a wider mix of labels than most teams budget for. Production shelf CV combines several label types at once, and image annotation pricing shifts with each one:
- Shelf-level and product-level bounding boxes
- Facings counts and planogram slot graphs
- OCR for shelf tags, plus price-tag-to-product linkage
Clean vision benchmarks hide real-world mismatch
One Scientific Reports paper describes a planogram-compliance system deployed across more than 7,000 7-Eleven stores in Taiwan.
It pairs YOLOv8 detection with few-shot classification and a customized Needleman-Wunsch alignment machine learning algorithm, reaching 99.41 mAP@50 for shelf detection and 98.39% Top-1 accuracy on unseen products with only five samples per class.
Those numbers look clean until you compare them against messier data. Another paper on the Grocer-Help dataset, built from more than 13,000 images across 349 categories in eight stores, deliberately captured dense shelves, motion blur, occlusion, and long-range CCTV-style shots. Its lightweight model landed at just 58.3 [email protected].
Store heterogeneity and capture protocol dominate benchmark transfer. Strong metrics on a clean test set say little about unattended performance in a real aisle.
The hardest store edge cases live in the data
The edge cases that degrade shelf models are data problems before they are architecture problems: visually identical variants, private-label near-duplicates, localized packaging refreshes, reflective packaging, partial facings, and phantom inventory states where the shelf looks full but the ERP is wrong.
The 7-Eleven paper introduced automated labeling and clustering to cut manual annotation time, then listed the unsolved problems anyway: occlusion, backward-facing products, partial shelf capture, and confined aisles.
Auto-labeling reduces cost without removing the need for curated exception sets.
Loss Prevention Is the Hardest Retail Computer Vision Data Problem

Shoplifting detection breaks the assumptions most annotation pipelines rely on.
The target class is rare and the base rate is unstable. The same pose can read as honest hesitation, concealment, assisted shopping, or staff restocking depending entirely on temporal context.
AI training data for retail computer vision models has to span person tracking, pose keypoints, zone semantics, object interaction points, and temporal windows. Privacy constraints often strip out the richest visual features on top of that.
Some interesting insights from recent ML research papers:
- PoseLift frames shoplifting detection as unsupervised anomaly detection on anonymized pose data, showing pose-only pipelines cut privacy burden while still producing usable signals.
- A 2026 follow-up introduced the large-scale RetailS dataset under multi-day, multi-camera conditions and showed periodic adaptation on streaming unlabeled data beat offline baselines in 91.6% of evaluations, with each edge-side update finishing in under 30 minutes.
For CV teams, this means a dataset labeled once stops working fast. Each store reset or new product lineup changes what the cameras see, so the labeling has to keep going.
Virtual Try-On and Returns Inspection Expose Paired Data Scarcity
Product classification and image recognition, visual search, virtual try-on, and returns inspection form the most data-heterogeneous bucket in retail, and the one with the weakest public KPI disclosure.
For example, Zalando announced beauty virtual try-on in 2025 without releasing any conversion or return-rate impact, a sign the evaluation stack may not yet support public performance claims.
Amazon’s 2025 Trustworthy Shopping report confirms it uses computer vision and multimodal LLMs in fulfillment centers to inspect images for damage, expiration, and compliance, but discloses no precision or recall figures.
Recent work keeps hitting the same constraint. Paired data is scarce while unpaired data is abundant but noisy, and benchmark metrics have been too forgiving.
- VTBench argues that standard metrics such as SSIM, LPIPS, FID, and KID do not reflect human judgment on real-world try-on, and that controlled indoor test sets understate failure rates in the wild.
- OmniTry extends try-on to 12 classes of wearable objects and leans on large-scale unpaired images because paired samples are so hard to collect.
This means a dataset labeled once stops working fast. Each store reset or new product lineup changes what the cameras see, so the labeling has to keep going.
Annotation Requirements by Computer Vision in Retail Use Case
Each computer vision use case in retail demands a distinct label schema, and the high-value work concentrates where automation cannot resolve ambiguity.
| Use case | Core label types | Where human review is non-negotiable |
| Shelf intelligence | Bounding boxes, facings counts, OCR-linked shelf edges, slot graphs, image-stitch correspondences | Packaging refreshes, planogram-change windows, long-tail SKU onboarding |
| Checkout and shopper tracking | Multiview tracking IDs, interaction points, event timelines, transaction joins | Exception review, new store-format calibration, false-positive audits |
| Loss prevention | Pose keypoints, anomaly windows, zone semantics | Hard-negative review, drift triage, relabeling after store resets |
| Visual search and product recognition | Retrieval pairs, hard negatives, attribute normalization, packaging-version lineage | Hard-negative curation, attribute verification |
| Virtual try-on | Fit-ranked preference labels, hand-occlusion tags, cross-category size and drape labels | Fit-preference ranking, wild-scene QA |
| Returns and damage inspection | Region anomaly masks, severity scores, sellability labels | Anomaly adjudication on borderline conditions |
How to Move a Retail Computer Vision System From Pilot to Production
Treat the data layer as the core of the CV project. The two strongest recent findings point the same direction:
- Filtered data beat raw model scale on grocery retrieval
- Periodic adaptation beat static training in loss prevention
Well-designed annotation strategy and label quality now move production metrics more than another round of architecture experiments. But before you plan to scale any retail CV system:
- Decide where human review is non-negotiable, using the table above as a starting map.
- Build calibration sets for each new store format rather than assuming one model transfers.
- Plan for relabeling after assortment and planogram changes, so the first dataset never becomes a frozen liability.
If your computer vision in retail roadmap is moving from pilot to scale, talk to our data annotation company about the annotation program behind it. Our human-first, AI-enabled delivery model at Label Your Data is built for the high-volume, exception-heavy work that decides whether a model holds up in a complex environment.
Why Label Your Data Is a Trusted Data Partner for Computer Vision Teams in Retail
Label Your Data has been delivering tailored data annotation for various computer vision applications in retail. Three client stories below highlight how effectively this work performs even when faced with production challenges.
Contactless tracking for enterprise retailers
An Israeli company built contactless shopping software for global retail enterprises. Its CV model had to detect which products a shopper picked up and added to their cart, then map their movement through the store.
The footage was live CCTV carrying personal data. Our data annotators did the labeling under core security certifications, so the client’s model learned from real store video without the privacy exposure.
High-volume attribute labeling for fashion ML
A US fashion brand running an AI product had a catalog of 10,000 clothing items that needed labeling and categorizing cleanly enough to feed straight into its ML pipeline. Label Your Data assembled a dedicated team of expert annotators and labeled the full set for clean model integration.
In-infrastructure tagging for custom 3D assets
A personalized shopping platform needed custom 3D assets, and the data had to stay in its own environment. Throughout collaboration with the Label Your Data team, the whole annotation program ran inside the client’s infrastructure: data collection, tagging, image processing, and 3D model creation, none of it leaving their proprietary systems.
About Label Your Data
If you choose to delegate computer vision annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects in retail. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are the main use cases for computer vision in retail?
The four highest-value buckets are frictionless checkout and shopper tracking, shelf intelligence and planogram compliance, loss prevention, and product recognition spanning visual search, virtual try-on, and returns inspection.
Why do retail computer vision models fail in production after strong benchmark results?
Store heterogeneity and capture protocol dominate benchmark transfer. Besides, lighting, occlusion, narrow aisles, and packaging variation degrade models trained on tidy examples, which is why calibration sets and exception review outrank another architecture change.
What kind of data annotation does retail computer vision require?
It depends on the use case. Shelf work needs bounding boxes, facings counts, OCR-linked shelf edges, and slot graphs. Checkout needs multiview tracking IDs, interaction points, and transaction joins. Loss prevention needs pose keypoints, anomaly windows, and rigorous hard-negative review.
Across all of them, label quality and ongoing relabeling drive production accuracy more than model size.
Does data filtering actually beat scaling the model or dataset in retail CV?
In at least one core retail task, yes. On grocery product retrieval, filtered pretraining data produced up to 16.6 points of gain, while larger parameter counts alone did not close the Recall@5 to Recall@1 gap on near-duplicate SKUs.
For SKU-critical tasks like checkout and visual search, hard-negative mining, duplicate consolidation, and catalog cleaning tend to move the metric more than another scaling run. The practical implication is to budget annotation effort for ranking precision.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.