YOLO Object Detection: Key Features and Benefits

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- YOLO is a fast, single-stage model that detects multiple objects in one pass.
- Unlike Faster R-CNN, YOLO processes images instantly, making it ideal for real-time tasks.
- Key features include grid-based detection, NMS, and parallel predictions for speed.
- New YOLO versions (v4–v9) improve accuracy, efficiency, and small object detection.
- Limitations include struggles with small objects, overlapping detections, and high computing needs.
- Faster than Faster R-CNN but less precise, YOLO is best for real-time applications.
What Is YOLO Object Detection?
YOLO object detection is a single-stage deep learning model that detects multiple objects in an image simultaneously, predicting locations and categories in parallel.
Unlike two-stage models like Faster R-CNN, which first generate region proposals and then classify them, YOLO skips the region proposal step, making it much faster.
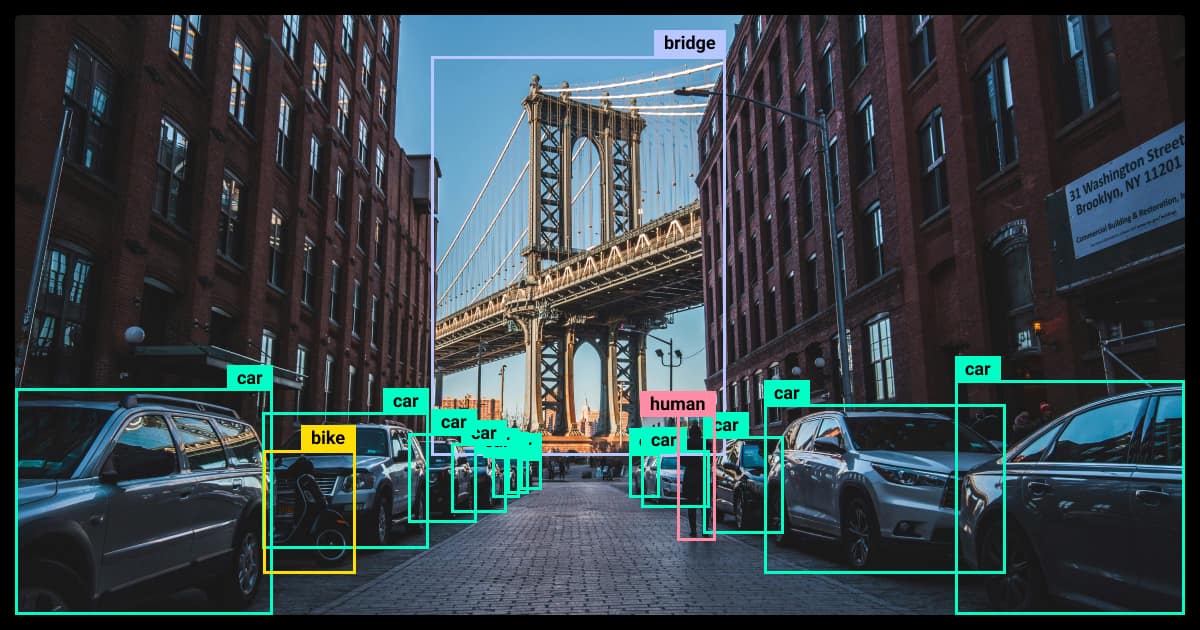
Why YOLO Object Detection Is Faster
Unlike traditional models, YOLO object detection treats object localization as a regression problem. Instead of analyzing separate image patches, it processes the entire image at once, making it much more efficient.
Key innovations that make YOLO fast:
- Single-Pass Processing: YOLO analyzes the entire image in one step, predicting objects and their locations instantly.
- Grid-Based Detection: It divides the image into a grid, assigning objects to cells for efficiency.
- Parallel Predictions: Unlike two-stage models, YOLO predicts multiple bounding boxes at once.
These advancements allow YOLO to detect objects 100 times faster than early object detection models, making it the gold standard for real-time AI applications.
YOLO’s single-pass detection is like an ultra-fast brain processing everything in one go. We used it in a security system, and it detected and classified objects in milliseconds—way faster than two-stage detectors. While it trades a bit of accuracy, the speed advantage is massive for real-world applications where instant response is critical.

 CIO and Founder, Local Data Exchange
CIO and Founder, Local Data Exchange
YOLO Object Detection Architecture
YOLO real-time object detection transformed object detection with a single-stage architecture, replacing slow multi-stage pipelines with real-time processing.
Unlike traditional object detection methods, YOLO object detection processes an entire image in a single pass, making it far more efficient than multi-stage models. This advantage makes YOLO real-time object detection a top choice for tasks requiring instant decision-making, such as autonomous vehicles, surveillance, and robotics.
How It Works
In traditional models, image classification vs. object detection represents two different tasks. Image classification gives one label to the whole image, while YOLO object detection finds multiple objects and pinpoints their locations in an image or video.
Unlike classification, YOLO identifies multiple objects in an image or video and determines their exact locations. YOLO video object detection follows a streamlined machine learning algorithm that performs detection in a single network pass.
The process consists of:
- Image Input: The model takes in an image or video frame as its input.
- Grid Division: The image is split into a grid, with each cell assigned to detect objects in its region.
- Bounding Box Predictions: Each grid cell outputs box coordinates (x, y, width, height), a confidence score, and class probabilities.
- Non-Maximum Suppression (NMS): Overlapping predictions are filtered out, keeping only the most confident bounding boxes.
- Final Output: The detected objects, along with their bounding boxes and confidence scores, are returned.
This single-pass architecture enables YOLO real-time object detection to process video frames at high speed, making it ideal for security systems, drones, and industrial automation.
YOLO Object Detection Models: v1 to v9+
The YOLO object detection algorithm has improved significantly over the years, with each version enhancing speed, accuracy, and computational efficiency.
| YOLO Version | Key Innovations | Performance Gains |
| YOLOv1 | First unified detector, 45 FPS | Fast but lower accuracy |
| YOLOv4 | CSPDarkNet, Mish activation, SPP | Improved speed-accuracy tradeoff |
| YOLOv7 | E-ELAN, model re-parameterization | 155 FPS, real-time efficiency |
| YOLOv9 | GELAN architecture, programmable gradient information | State-of-the-art accuracy |
YOLOv9 has optimized object detection by improving small object detection and real-time processing speeds. The next generation of YOLO object detection may also integrate transformer-based architectures to enhance feature extraction and tracking.
Training the Models
Training object detection YOLO models requires high-quality labeled datasets. Since manually annotating large datasets is time-consuming, researchers increasingly rely on LLM data labeling to automate parts of the data annotation process.
Different types of LLMs play a role in improving annotation accuracy by handling complex image descriptions and refining object classification. By handling unlabeled data, machine learning models can improve detection accuracy while reducing manual effort.
Key Features of YOLO Object Detection
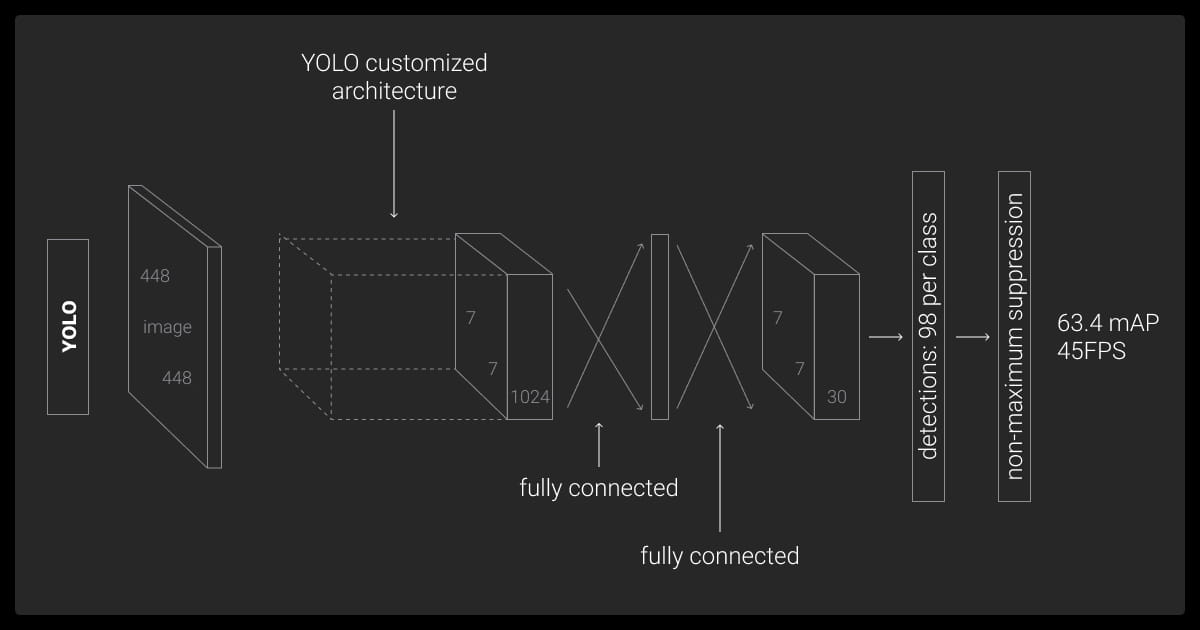
The YOLO model stands out in computer vision due to its speed, efficiency, and adaptability across multiple domains.
Speed and Computational Efficiency
One of YOLO’s biggest advantages is its high-speed inference, which enables real-time object detection on both high-end GPUs and resource-constrained edge devices.
| Feature | YOLO Model | Two-Stage Detectors (Faster R-CNN, Mask R-CNN) |
| Processing Steps | Single-pass detection | Region proposals + classification |
| Inference Speed (FPS) | 100+ FPS | 5-10 FPS |
| Hardware Requirements | Can run on edge devices | Requires high-end GPUs |
| Best Use Case | Real-time applications | High-accuracy but non-real-time tasks |
This computational efficiency allows YOLO to be used in drones, smart cameras, and real-time surveillance, making it one of the most widely adopted object detection models today.
Accuracy vs. Speed Tradeoff
While YOLO object detection is optimized for speed, its accuracy has also improved significantly in recent versions. The latest YOLO models use advanced loss functions to refine bounding box predictions and improve overall performance:
- YOLOv4-v7: Introduced CIoU, DIoU, and GIoU loss functions, improving object localization.
- YOLOv8-v9: Integrated transformer-based enhancements and better feature extraction for higher detection accuracy.
This balance between speed and accuracy makes YOLO computer vision models highly effective in autonomous navigation, industrial automation, and AI-powered video analytics.
Multi-Scale Object Detection
A common challenge in object detection is identifying objects of different sizes within the same image. Traditional models often struggle to detect small or distant objects, but YOLO object detection has addressed this through multi-scale feature extraction:
- Anchor Boxes: Predefined bounding boxes of different sizes improve small object detection.
- Feature Pyramid Networks (FPN): Allows YOLO to process objects at multiple scales.
- Spatial Pyramid Pooling (SPP): Helps detect objects at different distances from the camera.
YOLO accurately detects vehicles, pedestrians, and road signs at varying distances in self-driving applications.
YOLO Object Detection in Real-World Applications
The YOLO model is what fuels today's real-time AI system. It can rapidly analyze both images and videos. At the same time, many industries rely on it for automation, security, and decision-making, primarily due to high accuracy
From self-driving cars to industrial quality control, YOLO object detection continues to evolve, providing solutions for both consumer and enterprise-level applications.
Autonomous Vehicles & Traffic Monitoring
Self-driving cars and traffic systems use real-time object detection to identify pedestrians, vehicles, and road signs.
- Pedestrian & Cyclist Detection: Reduces collision risks by identifying people in real time.
- Traffic Sign Recognition: Helps vehicles obey speed limits, stop signs, and signals.
- License Plate Recognition: Used in traffic monitoring and toll collection systems.
The biggest advantage of using YOLO (You Only Look Once) for real-time applications is its speed and efficiency. YOLO processes an entire image in a single pass, enabling it to detect and classify multiple objects with high speed. In autonomous vehicles, YOLO helps detect pedestrians, vehicles, and road signs in real time, allowing for split-second decisions.
 Operations and Technology Manager, Pacific Plumbing Systems
Operations and Technology Manager, Pacific Plumbing Systems
Healthcare & Medical Imaging
Medical AI relies on precise image recognition to help doctors identify diseases and detect abnormalities. YOLO object detection is increasingly used in radiology, pathology, and medical robotics.
- X-Ray & MRI Analysis: Detects fractures, tumors, and organ anomalies.
- Surgical Robotics: Enhances precision in robotic-assisted surgeries.
- Medical Supply Tracking: Identifies and classifies surgical instruments in real time.
A major challenge in medical AI is the shortage of properly labeled datasets. Many hospitals turn to a data annotation company to create high-quality labeled datasets, improving model accuracy.
However, data annotation pricing can vary depending on annotation complexity, dataset size, and required precision, making it an important consideration for healthcare AI developers.
Retail & Surveillance
Retailers and security companies leverage YOLO computer vision models for real-time tracking, loss prevention, and automated checkout systems.
- Smart Checkout (Amazon Go-Style Systems): Detects products in real time, reducing the need for barcodes.
- Customer Behavior Analysis: Tracks foot traffic and engagement with store displays.
- Crowd Monitoring: Detects suspicious behavior in public places.
- Intruder Detection: Enhances home and commercial security systems.
- Automated Financial Analysis: YOLO extracts data from financial datasets, detects fraud, and streamlines documents.
While YOLO object detection enables fast and efficient monitoring, concerns about privacy and ethical use remain key challenges. Additionally, data annotation services play a crucial role in improving surveillance models by providing accurately labeled datasets. They ensure better recognition of individuals and objects in diverse environments.
Robotics & Industrial Automation
Industrial automation requires precise object detection to improve efficiency and safety. YOLO models are widely used in manufacturing, logistics, and robotics for quality control, sorting, and safety monitoring.
- Robotic Arms: Identifies and picks objects with high precision.
- Defect Detection: Automates quality control in factories.
- Warehouse Sorting: Speeds up package processing in logistics centers.
With advances in OCR deep learning, YOLO models are also used for reading barcodes, tracking shipments, and monitoring supply chains.
YOLO’s single-shot approach helps the model stay robust to sudden movements and background changes. It’s not just that the predictions come fast—they come with an awareness of the entire scene at once, lowering the chance of ‘tunnel vision’ errors that multi-stage detectors can suffer from.
 CEO & Founder, Listening.com
CEO & Founder, Listening.com
Limitations of YOLO and Model Comparisons
YOLO is fast and efficient but struggles with small objects, dense environments, and resource-limited devices.
Compared to other object detection models, YOLO makes trade-offs between speed and accuracy, which may not be ideal for all use cases.
Key Limitations of YOLO Object Detection
Despite its strengths, the YOLO model has certain drawbacks:
Struggles with Small Object Detection
- Challenge: Small objects can be misclassified due to YOLO's fixed grid structure, impacting detection of distant pedestrians or traffic lights
- Impact: Detecting distant pedestrians, traffic lights, or small medical anomalies is less reliable.
Difficulty in Handling Overlapping Objects
- Challenge: In crowded scenes, YOLO may struggle to differentiate between overlapping objects.
- Impact: This leads to misclassifications or duplicate detections in surveillance and retail analytics.
Computational Load on Edge Devices
- Challenge: Although YOLO is faster than most models, newer versions require significant processing power, limiting its use on low-power devices.
- Impact: Deployment on mobile devices, IoT systems, and embedded vision applications may require lighter versions like Tiny YOLO.
Sensitivity to Image Conditions
- Challenge: YOLO’s accuracy drops under poor lighting, motion blur, or extreme angles.
- Impact: Real-time applications like autonomous driving and security monitoring may see reduced reliability.
How YOLO Compares to Other Object Detection Models
While YOLO object detection offers unmatched speed, other models outperform it in precision and feature extraction.
| Feature | YOLO | Faster R-CNN |
| Speed (FPS) | 100+ FPS | 5-10 FPS |
| Accuracy (mAP) | Moderate | High |
| Best Use Case | Real-time detection | High-accuracy tasks |
| Limitations | Struggles with small & overlapping objects | Too slow for real-time processing |
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is YOLO in object detection?
YOLO (You Only Look Once) is a rapid, single-stage object detection model that identifies object locations and categories in just one pass through a neural network.
Is YOLO a CNN model?
Yes, YOLO is a convolutional neural network (CNN)-based model designed for real-time object detection.
Is OpenCV better than YOLO?
No, OpenCV is a computer vision library, while YOLO is an object detection model. OpenCV can use YOLO for detection but does not replace it.
Is YOLO the best object detection algorithm?
YOLO is one of the fastest and most efficient real-time object detection models, but other models like Faster R-CNN or RetinaNet offer higher accuracy for complex tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.