Data Extraction: Core Methods for AI-Ready Pipelines

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Where Data Extraction Fits in ETL/ELT Workflows
- Core Data Extraction Methods for Modern Pipelines
- PDF Data Extraction for AI Pipelines: Template, ML, and LLM Approaches
- Automating Data Extraction with CDC and Webhooks
- Making Extracted Data AI-Ready: QA, Evaluation, and Handoff
- About Label Your Data
- FAQ
TL;DR
- Data extraction is the first step of ETL/ELT pipelines, pulling data from sources like databases, SaaS apps, PDFs, and logs.
- Core methods vary by data type: SQL queries and CDC for structured, parsers for semi-structured, and OCR or ML for unstructured.
- PDF extraction can use templates, layout-aware ML, or LLMs – each with trade-offs in cost, flexibility, and reproducibility.
- Automation strategies include batch, streaming, CDC, and orchestrators, with schema drift detection and audit logging as must-haves.
- QA makes data AI-ready: completeness checks, precision/recall for extracted fields, drift monitoring, and stable schema handoffs into pipelines.
Where Data Extraction Fits in ETL/ELT Workflows
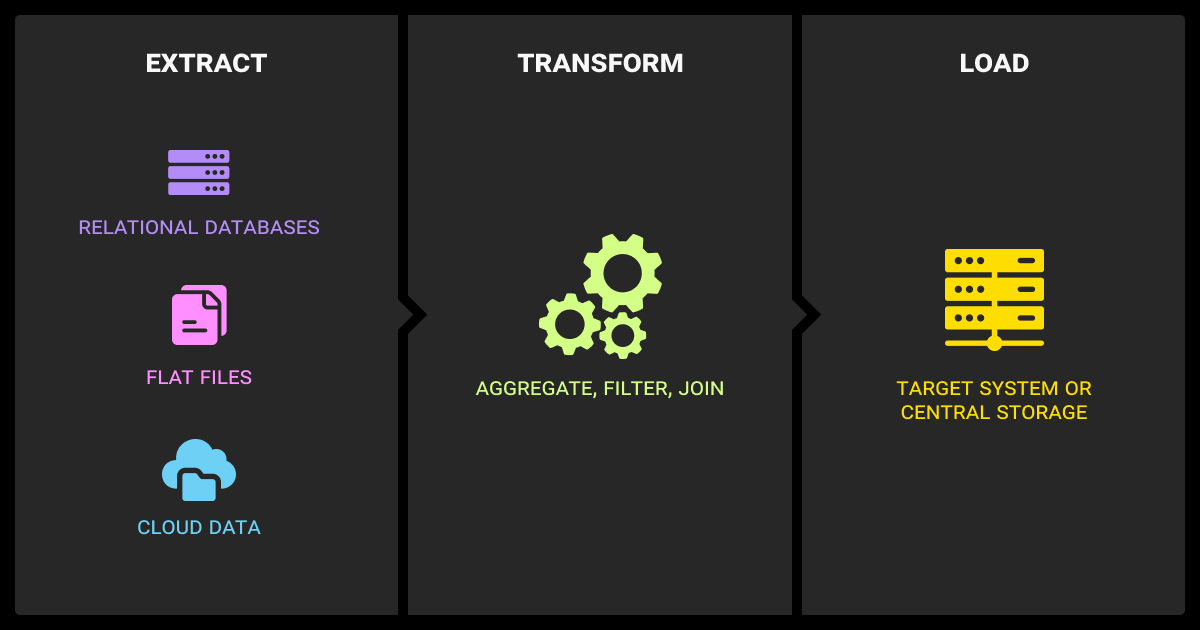
Data extraction is the process of pulling data from its original sources, like databases, SaaS applications, PDFs, APIs, web pages, or log files, so it can be consolidated and prepared for downstream use.
In ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) workflows, extraction is the first step: it delivers raw records into a staging area or data lake, where transformations and loading into warehouses or feature stores happen later.
For AI-ready pipelines, extraction determines whether downstream models and analytics receive reliable inputs. A machine learning algorithm cannot train or serve reliably if the source data is incomplete, malformed, or drifting. This is particularly critical because 80-90% of enterprise data is unstructured (think PDFs, scanned documents, and HTML pages that need cleaning before they can be analyzed or fed into ML systems).
For example, merging SQL customer records, web-scraped product reviews, and IoT sensor data only works if formats are standardized before analytics or model training.
Common Pitfalls
Extraction often fails in ways that silently undermine downstream models. The most frequent problems include:
- Schema drift in relational sources can break downstream joins
- Malformed text and encoding issues introduce silent errors
- OCR noise in scanned documents corrupts extracted fields
- API volatility can cause intermittent or missing data
A reliable extraction strategy anticipates these issues with drift detection, schema contracts, and continuous monitoring.
Types of Extraction
Enterprises rarely use a single extraction strategy. Depending on workload size, freshness requirements, and system constraints, common approaches include:
- Full extraction pulls an entire dataset at once, often used for initial loads or small tables
- Incremental extraction captures only new records since the last run
- Change Data Capture (CDC) or webhooks track updates in real time by reading database logs or listening to events
Each method is a trade-off between system load, data freshness, and operational complexity.
Core Data Extraction Methods for Modern Pipelines

Different data shapes call for different data extraction techniques. Pick methods based on schema stability, change rate, and latency needs. Plan where to catch drift: schema diffs for databases, schema checks for JSON/CSV/XML, and layout/OCR quality thresholds for PDFs and scans.
Structured Data Extraction
Structured sources, like SQL databases, data warehouses, and SaaS apps, are the most straightforward to extract from.
Common structured methods include:
- SQL exports for bulk loads or scheduled jobs
- CDC/binlogs to track inserts, updates, and deletes in near real time
- APIs and webhooks for streaming updates directly from SaaS platforms
The main risks are schema drift and query inefficiencies, which can be mitigated with schema validation and performance monitoring.
Semi-Structured Data Extraction
Semi-structured formats, like JSON, CSV, or XML, carry flexible schemas but still need parsing and validation. Parsing them often requires schema validation before the data is handed off to data annotation services.
Typical semi-structured techniques include:
- Parsing libraries to handle JSON, CSV, or XML
- Schema mapping and validation to align fields across sources
- Transformation rules to normalize field types and encodings
The challenge here is inconsistency: fields may appear, disappear, or change type between files. Drift detection and schema contracts help keep pipelines stable.
Unstructured Data Extraction
Unstructured sources, like text, PDFs, images, audio, or logs, are the hardest to process. Such pipelines often pair OCR with image recognition models to extract objects or handwriting.
Common unstructured approaches include:
- Regex or templates for high-precision but brittle parsing
- NLP and layout-aware ML models to extract entities, detect tables, and process document structures
- OCR for scanned documents or images
These data extraction methods offer flexibility but also raise challenges: accuracy varies with noise, and model outputs require evaluation (precision, recall, F1) before use in ML pipelines.
Choosing the right method depends on the type of data, the tolerance for schema drift, and the resources available to build monitoring into the pipeline.
The strongest pipelines combine OCR for documents, NLP for text, and computer vision for visuals – but the real breakthrough is large language models. LLMs like GPT-4o can process text and visual elements together with higher accuracy and less annotation. This shifts the focus from raw extraction to feature engineering, where unstructured inputs become meaningful features.

 AI Security Advocate | Chief Marketing Officer, Mindgard
AI Security Advocate | Chief Marketing Officer, Mindgard
Data extraction is often powered by dedicated data extraction software or a lightweight data extraction tool that connects to databases, SaaS applications, APIs, or logs. In many AI workflows, extraction is paired with data collection services or a data annotation company to prepare structured inputs for downstream training.
PDF Data Extraction for AI Pipelines: Template, ML, and LLM Approaches
PDFs are one of the most common but also most problematic sources in enterprise data pipelines. Unlike structured databases or JSON, PDFs weren’t designed for machine parsing.
They can mix text, images, tables, and scanned pages, often with inconsistent layouts. For AI pipelines, this means PDF data extraction must balance precision, flexibility, and reproducibility, particularly in regulated industries where results must be explainable.
Template or Rule-Based Extraction
This approach relies on fixed patterns and positions, making it effective for standardized document data extraction but fragile when layouts change.
- Pattern-based parsing (regex, XPath, positional rules)
- High precision when documents share a fixed layout (e.g., invoices, receipts)
- Low flexibility when layouts drift, requiring frequent maintenance
A typical use case is invoice data extraction in finance or contract data extraction in legal workflows, where rules and templates can capture stable fields with high precision.
Layout-Aware ML Pipelines
Machine learning datasets allow models to generalize across variable layouts by detecting underlying structure, but labeled data is still required for training.
- OCR engines + table/figure detection to digitize scanned pages
- Document parsing models that map positions, hierarchies, and labels
- More resilient to layout variation but require annotation and training data
These pipelines often rely on OCR data extraction software or domain-specific tools.
LLM-Assisted Data Extraction
Large language models allow schema-light extraction directly from text, offering flexibility at the cost of consistency and reproducibility.
- Schema-light parsing using prompts to extract fields directly from text
- Flexible for unseen formats or multilingual docs
Challenges: reproducibility (answers can vary), grounding issues (unsupported outputs), and compliance risks if citations aren’t enforced.
Outputs from LLM-assisted parsing can also serve as training material for LLM fine tuning, helping models adapt to specific document domains.
Comparing Approaches
Vendors frequently advertise their platforms as the best data extraction software, but the right choice depends on accuracy, reproducibility, and long-term cost of maintenance.
These three approaches differ widely in cost, flexibility, and reliability.
| Attribute | Template / Rules | Layout-Aware ML | LLM-Assisted |
| Accuracy/Precision | High on stable docs | Medium–High | Variable |
| Flexibility | Low | Medium | High |
| Cost/Maintenance | Low | Medium–High | High (compute + prompts) |
| Reproducibility | High | Medium | Low |
| Best Fit For | Invoices, receipts | Variable layouts, scans | Ad-hoc, multilingual docs |
Enterprises often combine these: templates for stable, high-volume documents; ML pipelines for complex layouts; and LLMs for edge cases where flexibility matters most.
Automating Data Extraction with CDC and Webhooks
Manual extractions don’t scale in enterprise settings. Large AI pipelines require automated data extraction frameworks to handle volume, minimize failures, and keep data fresh. At scale, automation implies retries, monitoring, and governance to ensure reliability and compliance.
Batch vs Streaming
Automation strategies depend on workload patterns.
- Batch extraction: scheduled jobs (daily, hourly) that move large volumes at once
- Streaming extraction: near real-time pipelines that push updates continuously
Batch is simpler to manage but less fresh. Streaming supports time-sensitive applications but needs more robust orchestration.
Handling Failures and Orchestration Needs
Automated pipelines must be fault-tolerant.
- Retries and idempotency: ensure a failed load doesn’t duplicate or corrupt data
- Orchestration frameworks: tools like Airflow or Dagster coordinate dependencies, backfills, and retries across multiple pipelines
Lightweight automation (Zapier-style connectors) may suffice for small workloads. Enterprises usually need full orchestration to handle complexity and auditability.
Monitoring and Change Management
Pipelines must adapt to evolving sources.
- Update notifications: incremental loads triggered by events or webhooks
- API monitoring: track rate limits, schema changes, and deprecations
- Schema drift detection: catch upstream changes before they break downstream models
- Data lineage and audit logging: mandatory in regulated environments
The choice of automated data extraction software depends on scale. Lightweight scripts for prototypes, event-driven automation for mid-sized systems, and orchestrators for production-grade pipelines.
Context preservation is critical—you can’t just grab text chunks and expect insights. Our “relationship-aware extraction” pulls company info, funding rounds, and tech descriptions together, cutting false positives by 67%. Domain-specific embeddings made the database three times more actionable, while real-time validation prevents bad data from polluting training sets.
 Co-Founder, Entrapeer
Co-Founder, Entrapeer
Extraction costs often scale like data annotation pricing, where volume and quality demands drive the final spend.
Making Extracted Data AI-Ready: QA, Evaluation, and Handoff
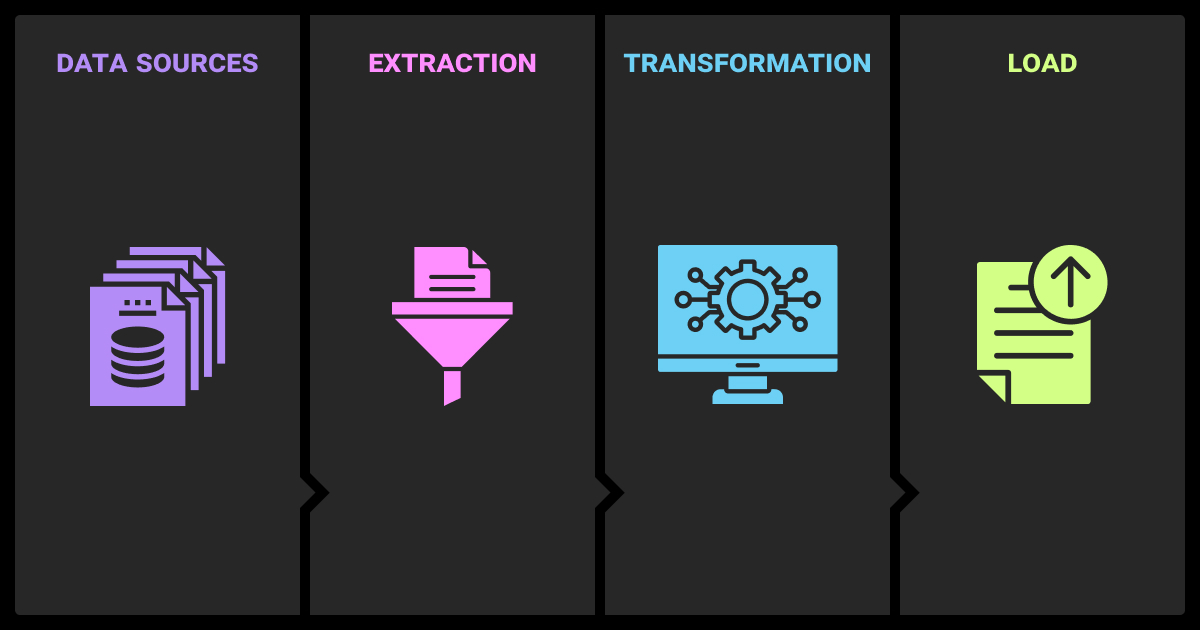
Extraction alone doesn’t guarantee usable data. Before records can fuel ML models or LLM pipelines, they must be validated, evaluated, and handed off in stable formats. Enterprises that skip this step risk feeding incomplete or noisy data into production systems.
Quality Checks
Basic validation ensures extracted data is fit for use.
- Completeness: no missing fields or truncated rows
- Consistency: uniform formats across sources (dates, encodings, units)
- Deduplication: removal of duplicate records
- Encoding checks: spot corrupted or unreadable characters
Field-Level Evaluation
Borrowing from ML evaluation, data extraction quality can be measured quantitatively.
- Precision, recall, F1 for extracted entities (e.g., names, IDs)
- Accuracy of field mappings against gold datasets
- Error rate tracking to catch systemic issues
These metrics help detect subtle errors that won’t appear in simple row counts.
Drift Monitoring and Regression Testing
Data pipelines drift as sources evolve.
- Drift monitoring: watch for shifts in formats, distributions, or layouts
- Regression tests: validate extraction scripts/models after schema or tool updates
This prevents silent degradation before retraining or analytics.
Test Set Versioning and Handoff
To ensure reproducibility, enterprises need:
- Versioned test sets: frozen datasets for repeatable evaluations
- Data contracts: formal agreements on schema and field definitions
- Stable handoffs: delivering structured outputs to feature stores, data warehouses, or LLM pipelines
Together, these practices make extracted data reliable, comparable across runs, and ready for integration into AI systems. Yet even with strong pipelines, outputs often require data annotation to ensure quality before training.
Evaluation practices also vary across types of LLMs, which may respond differently to identical extracted inputs. The ongoing debate of Gemini vs ChatGPT shows how much model performance depends on the quality of inputs prepared through extraction and annotation.
These safeguards cut down silent errors, make debugging easier, and keep handoffs into training pipelines consistent. When AI data extraction is measured and versioned like any other ML step, models get cleaner inputs and teams spend less time chasing data issues.
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is data extraction?
Data extraction refers to pulling information from its original sources, such as SQL databases, SaaS tools, APIs, web pages, PDFs, or log files, and turning it into a usable format for analytics or machine learning. It’s the first step in ETL/ELT pipelines, where raw inputs are centralized before transformation and loading.
What are the steps of data extraction?
The process typically starts with connecting to the source system, whether that’s a database, API, or file repository. Teams then decide on a method (e.g., full loads, incremental updates, or change data capture) before applying parsing, schema mapping, or OCR. The extracted data is validated for completeness and consistency, and finally delivered to a warehouse, lake, or ML pipeline.
What is the purpose of extracting data?
The main purpose is to make raw data usable for downstream systems. Extraction ensures that information scattered across databases, documents, and APIs can be cleaned, standardized, and centralized. This provides analytics platforms and AI models with stable, reliable inputs instead of fragmented or inconsistent data.
What are the best web scraping tools for data extraction?
The best data extraction tools depend on the level of control and scalability you need. Open-source frameworks like Scrapy and BeautifulSoup are widely used for flexible, code-driven scraping workflows. For non-engineers, platforms such as ParseHub or Octoparse provide point-and-click interfaces.
At a larger scale, services like Apify and Diffbot offer cloud-based orchestration and structured outputs, making them easier to integrate with pipelines. Each has trade-offs in setup effort, monitoring, and compliance handling.
What are top web scraping APIs for data extraction?
APIs are often more efficient than custom scrapers because they deliver structured data directly. Common choices include ScraperAPI and Zyte API, which manage proxy rotation and request throttling automatically. SerpAPI is a popular option for search engine results, while Bright Data provides robust APIs for multiple domains with strong compliance controls.
These APIs simplify scaling and reduce maintenance, but costs grow with volume, so teams should evaluate them against workload requirements.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.