How to Build an LLM: A Step-by-Step Guide

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- LLMs are AI models trained on vast text datasets to generate and process language.
- Building an LLM involves data preparation, model training, and deployment.
- Use frameworks like PyTorch and Hugging Face for training and fine-tuning.
- Pre-trained models can save time and resources for most applications.
- Challenges include high computational costs, data privacy concerns, and debugging issues.
What Is an LLM?
Large language models (LLMs) are a type of AI trained to process and generate text in natural language. It uses patterns in data to predict, respond, and interact with language, making it useful for tasks like content generation, translation, and chatbots.
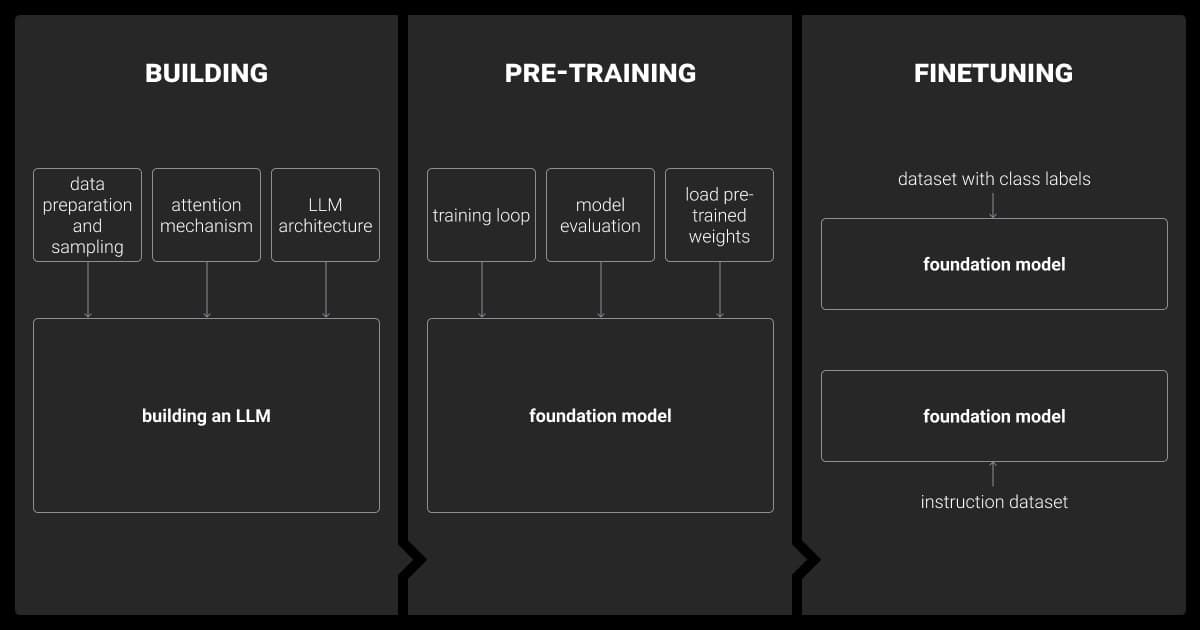
How LLMs Work
LLMs are trained on vast text datasets to understand how language flows. They don’t “think” like humans but use statistical patterns to:
- Predict the next word in a sentence.
- Recognize relationships between concepts.
- Generate coherent and contextually relevant text.
How LLMs Differ from Traditional Models
| Feature | LLMs | Traditional Models |
| Data Used | Billions of text samples | Smaller, focused datasets |
| Scale | Billions of parameters | Thousands of parameters |
| Flexibility | Handles diverse tasks | Built for specific tasks |
| Architecture | Based on transformers | Often simpler neural networks |
Language models excel at generalizing across tasks because of their scale and advanced LLM architecture.
Why Build Your Own LLM?
Using pre-trained models is often enough, but you may need to build your own LLM when:
- Custom needs: You need domain-specific capabilities (e.g., legal or financial text).
- Privacy concerns: You can’t share sensitive data with external providers.
- Cost control: Avoiding ongoing licensing fees for third-party tools.
- Adaptability: Gaining more control over how your model works and improves.
Building an LLM is resource-intensive, but it allows you to create a tool that fits your specific needs.
Key Components of an LLM

Building different types of LLMs requires understanding its core components. These include the data, architecture, and hardware that work together to train and run the model.
Datasets
The quality and diversity of your dataset directly impact your LLM’s performance. Here’s what you need to know:
Types of data needed:
- General text (e.g., books, articles, conversations).
- Domain-specific text (e.g., legal documents, scientific papers).
- Multilingual text (if targeting multiple languages).
Data preparation:
- Collection: Use open datasets, scrape public sources, or gather proprietary data.
- Cleaning: Remove duplicates, irrelevant information, and errors.
- Formatting: Standardize your text format for easier processing.
The dataset serves as the foundation of any LLM, so curating a high-quality, diverse, and representative dataset is paramount. It's essential to source data that aligns with the target use case while rigorously filtering for bias, toxicity, and irrelevant content.

 Machine Learning Engineer
Machine Learning Engineer
Model Architecture
The architecture determines how your LLM processes and generates language. Most LLMs today are based on transformers.
Transformer Models:
- Built on self-attention mechanisms.
- Handle large amounts of data efficiently.
- Excel at understanding context across long texts.
Key Variations:
- Encoder-only models: Best for understanding tasks (e.g., text classification).
- Decoder-only models: Focused on generation (e.g., writing text).
- Encoder-decoder models: Combine understanding and generation tasks.
Transformer-based architectures, like GPT or BERT, are the most common for LLMs, but the specific configuration (e.g., number of layers, attention heads) depends on your use case and compute budget.
 Founder & Principal Software Architect, Cirrus Bridge
Founder & Principal Software Architect, Cirrus Bridge
Hardware and Infrastructure
LLMs are computationally demanding. You’ll need powerful hardware to train and deploy your model.
| Requirement | Description |
| GPUs/TPUs | For parallel processing during training. |
| Memory (RAM) | To handle large datasets and model parameters. |
| Storage | For dataset storage and checkpoints. |
| Cloud or On-Premise | Cloud offers flexibility; on-premise suits privacy. |
For small teams, cloud-based services like AWS or GCP can reduce upfront costs and simplify setup.
Understanding these components will help you plan your LLM project effectively. The next step is combining these pieces to create a functional model.
How to Build an LLM: Step-by-Step Process
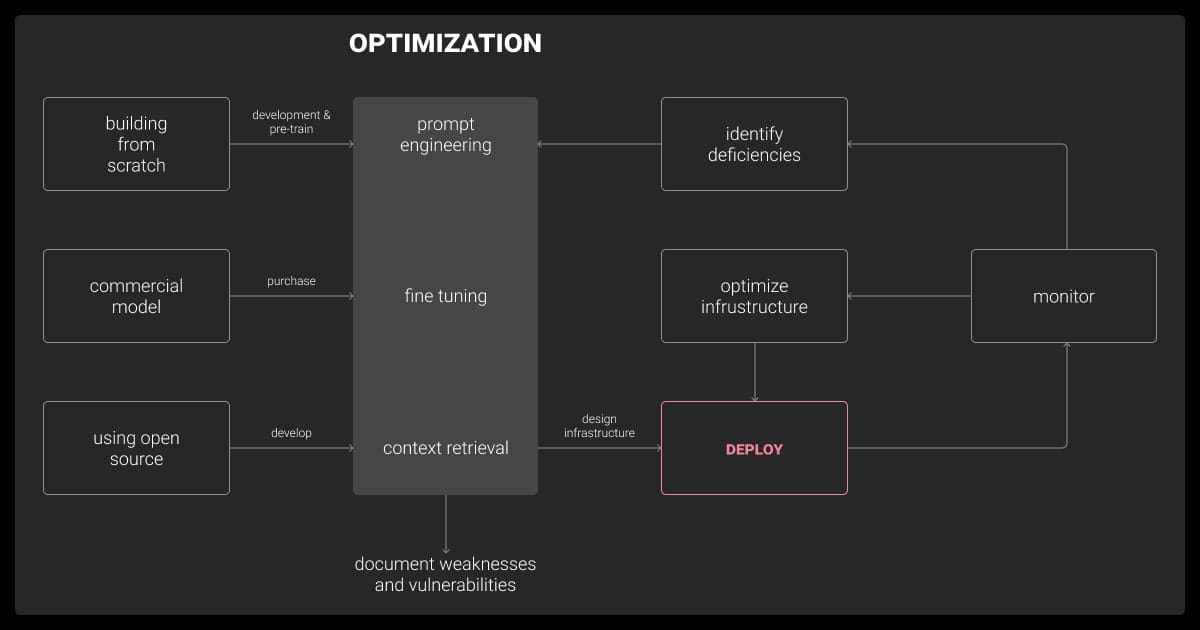
Creating a large language model is a multi-step process that involves careful planning, data preparation, model selection, and testing. Below is a step-by-step guide to help you navigate the process.
Step 1: Define Your Goals and Use Case
Start by identifying why you need an LLM and what you want it to achieve. This clarity will guide your decisions throughout the project.
Questions to answer:
- What tasks will the model perform? (e.g., summarization, customer support, specialized text generation)
- Should it handle general-purpose or niche content?
- What level of accuracy or fluency is required?
The first critical step is determining the use case. This decision shapes everything that follows, from the size of the model to the type of data required.

Step 2: Prepare Your Dataset
Your dataset is the backbone of your LLM. Invest time in collecting, cleaning, and organizing data.
Data Collection
- Use public sources (e.g., Common Crawl, Wikipedia).
- Combine domain-specific datasets for custom needs.
Data Cleaning
- Remove irrelevant or redundant data.
- Filter out biases and sensitive content.
Annotation and Labeling
- Annotate text when necessary (e.g., for specific tasks like named entity recognition).
Formatting
- Standardize text into formats like JSON, CSV, or TXT.
If your use case involves specific tasks like geospatial annotation, image recognition, or automatic speech recognition, ensure your dataset reflects these needs. High-quality datasets often require data annotation services to label information accurately and consistently.
Step 3: Select the Model Framework
Choose a framework based on your team’s expertise and project needs.
Popular frameworks:
- PyTorch: Flexible and widely used in research and development.
- TensorFlow: Robust for production environments.
- Hugging Face Transformers: Prebuilt models and tools to speed up development.
Factors to consider:
- Compatibility with your hardware.
- Community support and documentation.
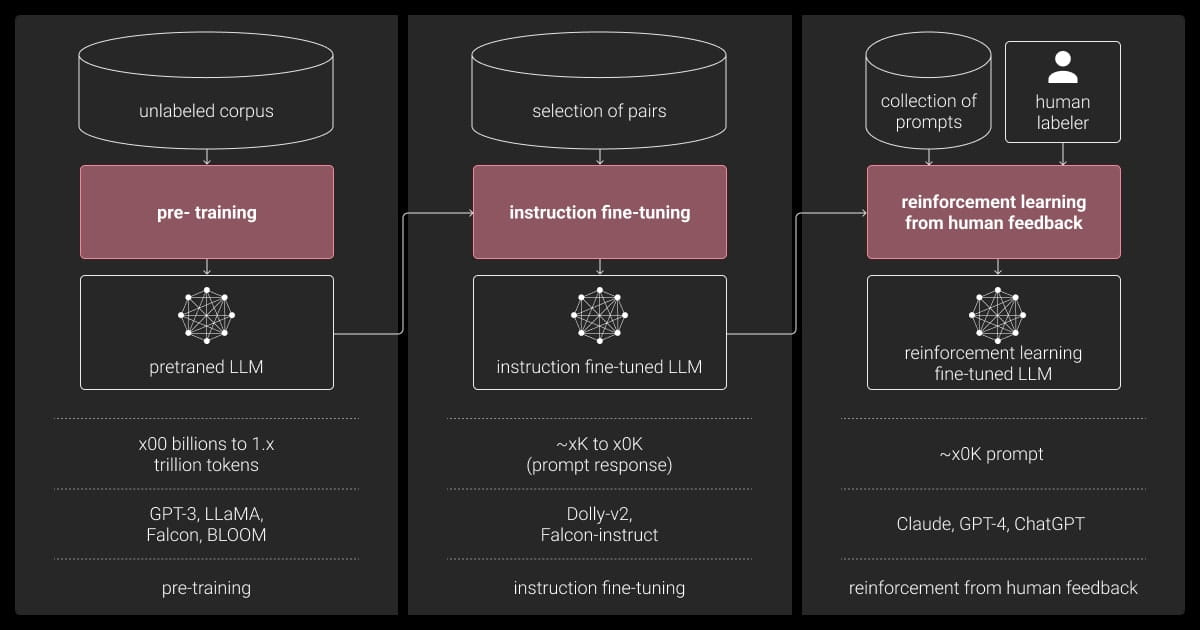
Step 4: Train the Model
Training involves feeding your dataset to the model and iteratively improving its performance.
Pretraining
- Train on large general datasets to learn language patterns.
- Requires significant computational resources.
Fine-Tuning
- Tailor the model to your specific use case or domain.
- Use smaller, task-specific datasets.
Tips for training:
- Use a learning rate scheduler to avoid overfitting.
- Regularly monitor validation loss and performance metrics.
Step 5: Evaluate and Test
Assess your LLM’s performance to ensure it meets your goals.
Key metrics:
- Perplexity: Measures how well the model predicts text.
- BLEU/ROUGE scores: For text generation tasks.
- Domain-specific metrics: Depending on the application.
Testing methods:
- Run the model on real-world tasks.
- Benchmark it against existing solutions.
Step 6: Deploy and Monitor
Once your model is trained and validated, make it accessible for use and continuously track its performance.
Deployment options:
- Host on cloud platforms like AWS or GCP.
- Use APIs for integration with applications.
Monitoring Tips:
- Track model drift to ensure consistent performance.
- Update and retrain periodically as new data becomes available.
Following these steps will help you build an LLM that aligns with your needs. Next, we’ll address common challenges you might encounter during the process.
Common Challenges in Building an LLM

Building a large language model is complex, and even with careful planning, you’ll encounter challenges. Understanding these common issues can help you prepare and address them effectively.
Data Privacy and Ethical Considerations
Using sensitive or proprietary data during training raises privacy risks, while biased datasets can lead to skewed outputs. Address this by encrypting data and anonymizing personal information. Use data annotation to identify and reduce biases, adhere to compliance standards like GDPR, and audit datasets for fairness during training.
Computational Costs and Budgeting
Training an LLM is costly and resource-heavy. To manage costs, use cloud-based services, smaller pre-trained models, and techniques like mixed precision training. Scaling large datasets may require distributed training across GPUs and optimized code for efficiency.
Debugging Training Issues
Models may overfit or fail to converge due to improper hyperparameters or low-quality datasets. Regularize using dropout, monitor metrics closely, and fine-tune with domain-specific data while validating outputs against test datasets.
Fine-Tuning for Domain-Specific Applications
Adapting general-purpose LLMs to niche tasks can be complex. Collect domain-specific data, apply LLM fine-tuning carefully, and validate results using benchmarks. Continuously iterate based on feedback and new data to improve performance.
Knowing these challenges in advance helps you mitigate risks and keep your LLM project on track. Let’s now explore the tools and resources that can make the process more manageable.
Tools and Resources to Help You Build an LLM
Building a large language model can be daunting without the right tools and resources. Fortunately, there are frameworks, datasets, and platforms designed to simplify the process.
Open-Source Models and Frameworks
Using open-source tools can save time and reduce costs. Here are some popular options:
Hugging Face Transformers:
- Pre-trained models and libraries for NLP tasks.
- Supports fine-tuning and integration with PyTorch and TensorFlow.
OpenAI GPT Models:
- APIs for access to GPT-4 and other pre-trained models.
- Ideal for those who want powerful language models without the training process.
LangChain:
- Framework for building applications powered by LLMs.
- Useful for chaining together multiple models or tasks.
Available Datasets for Training
You’ll need diverse and high-quality datasets to train or fine-tune your LLM. Below are some widely used resources:
| Dataset | Description | Use Case |
| Common Crawl | Web-scraped data for large-scale language models. | General-purpose pretraining. |
| Wikipedia | Free encyclopedia content. | Broad knowledge-based tasks. |
| PubMed | Scientific literature from medical journals. | Domain-specific applications (e.g., healthcare). |
| OpenSubtitles | Movie subtitles for conversational data. | Dialogue and chatbot training. |
For specific tasks or sensitive data, working with a data annotation company ensures accurate and efficient labeling.
Pro tip: Balance general-purpose datasets with domain-specific ones for better results.
You can also read our recent article on LLM fine-tuning tools to learn more about the tools you need for building a high-performing model.
Cloud Providers for LLM Development
Cloud platforms provide scalable resources, so you don’t need to invest in expensive infrastructure.
AWS SageMaker:
- Managed service for building, training, and deploying models.
- Offers GPU/TPU instances tailored for ML workloads.
Google Cloud AI Platform:
- Integrated tools for LLM development, including TPUs for faster training.
- Access to Google datasets for pretraining.
Azure Machine Learning:
- Simplifies model training with pre-configured environments.
- Strong integration with Microsoft tools.
Helpful Tools for Debugging and Optimization
Efficient debugging and optimization are crucial during training:
Weights & Biases:
- Tracks experiments, monitors metrics, and compares models.
- Simplifies the debugging process.
TensorBoard:
- Visualizes metrics like loss and accuracy during training.
- Useful for identifying convergence issues.
NVIDIA Nsight Systems:
- Analyzes GPU performance to optimize training.
These tools and resources can streamline your LLM development process, whether you’re starting from scratch or fine-tuning an existing model.
Thinking About Building an LLM? Read This First
Building a large language model is a complex yet rewarding process, offering flexibility, customization, and control over how the model works for your needs. However, it requires significant resources, expertise, and careful planning.
When to build your own LLM
Building an LLM makes sense if:
- You need a domain-specific model tailored to unique tasks.
- Data privacy is a priority, and external tools aren’t suitable.
- Long-term cost savings justify the upfront investment in resources.
When to use pre-trained models
Opt for pre-trained models if:
- Your tasks are general-purpose (e.g., content generation, translation).
- You lack the resources to train or fine-tune a model from scratch.
- You need results quickly without the complexity of training.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How to build LLM models?
- Define the task and goals.
- Gather, clean, and preprocess large datasets.
- Select a framework like PyTorch or TensorFlow.
- Train using GPUs/TPUs with a transformer-based architecture.
- Fine-tune on task-specific data.
- Evaluate, deploy, and monitor for improvements.
How are LLMs made?
LLMs are built using a transformer architecture trained on massive datasets to learn language patterns. The process involves data preparation, model training on high-performance hardware, and optimization using techniques like gradient descent. Fine-tuning and evaluation refine the model for specific use cases before deployment.
Can I train my own LLM?
You can train your own LLM if you have access to sufficient data and computational resources. For smaller models, a few GPUs and a domain-specific dataset might suffice. For large-scale LLMs, substantial funding and infrastructure are necessary, but fine-tuning pre-trained models is a practical alternative.
How to build an application with LLM?
- Choose a pre-trained or fine-tuned LLM.
- Set up an API for model integration.
- Design user input (e.g., chat interface, text fields).
- Process and format the model’s outputs.
- Test and monitor for performance improvements.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.