LLM Orchestration: Strategies, Frameworks, and Best Practices

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- LLM orchestration coordinates multiple language models to handle tasks efficiently.
- Frameworks manage workflows, assign tasks, and integrate models with data sources.
- It improves efficiency, scalability, and flexibility in AI workflows.
- Common challenges include resource use, compatibility issues, and managing errors.
- Best practices include matching models to tasks, monitoring performance, and focusing on secure, scalable workflows.
What Is LLM Orchestration?
LLM orchestration means coordinating large language models (LLMs) to handle tasks more effectively.
Instead of relying on a single model for everything, orchestration uses multiple models, each focused on what they do best. It’s a practical way to manage complex workflows in AI applications.
Here’s how it works:
- A smaller, faster model can handle straightforward tasks like summarization.
- A larger, more powerful model tackles nuanced operations like decision-making.
By dividing tasks, you save resources and improve results.
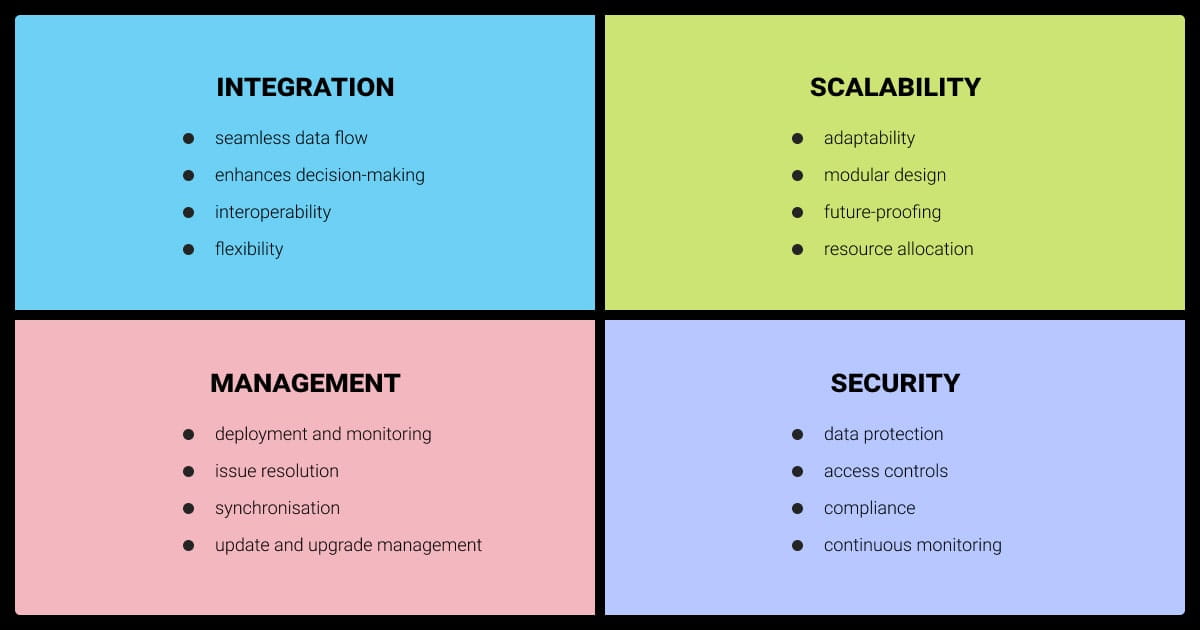
Why LLM Orchestration Matters
Using different types of LLMs is a smarter way to approach AI workflows. Here’s why:
- Efficiency: Assigning tasks to the right model reduces unnecessary strain on resources.
- Scalability: Adding more models as workloads grow becomes straightforward.
- Flexibility: You can swap models in or out without disrupting the system.
Single Model vs. Orchestration
| Feature | Single LLM | LLM Orchestration |
| Task Handling | Handles all tasks | Distributes tasks among models |
| Performance | Limited to model’s capacity | Optimized for each task |
| Scalability | Harder to scale | Easy to add/remove models |
| Resource Use | Often inefficient | Allocates resources dynamically |
This approach is about getting the best out of LLMs by working smarter, not harder.
Core Components of LLM Orchestration
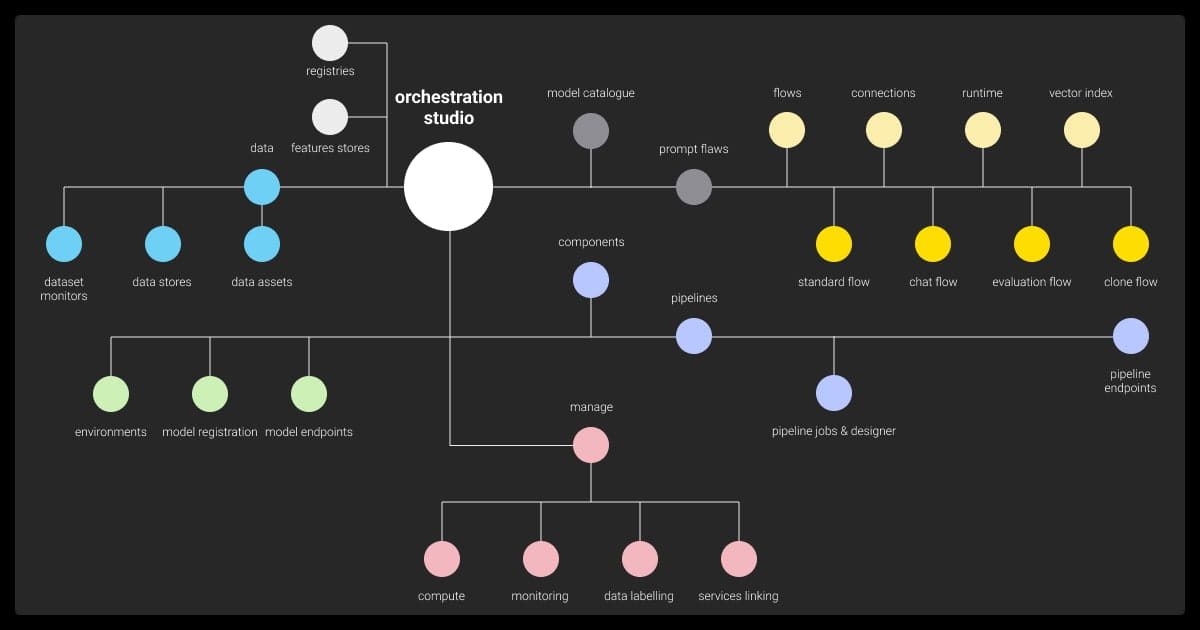
LLM orchestration involves multiple components that work together to streamline AI workflows. Each plays a specific role in ensuring tasks are handled efficiently and outputs are optimized.
Prompt Management
- Stores and organizes prompts for easy reuse.
- Enables prompt chaining, where outputs from one model become inputs for another.
- Refines prompts dynamically based on task requirements.
Example: In automatic speech recognition, prompt templates are used to guide models in transcribing audio files accurately, while chaining prompts refines outputs for better clarity.
Task Allocation
- Assigns tasks to the most suitable model based on its capabilities.
- Balances workload across models to optimize resource use.
Example: For image recognition, simpler models identify basic shapes and objects, while advanced models handle complex features like facial recognition or scene analysis.
Orchestrating multiple LLMs in complex workflows requires clear task segmentation and well-defined interdependencies. Using workflow orchestration tools like Apache Airflow or LangChain ensures smooth transitions between LLMs.

 CEO, Software House
CEO, Software House
Data Integration
- Connects models to external databases, APIs, or vector stores for retrieving contextual information.
- Handles preprocessing to ensure data is in the right format for each model.
Example: A financial analytics pipeline retrieves transaction data from an API, processes it using a preprocessing model, and then feeds it to a reasoning model for fraud detection.
Performance Monitoring
- Tracks metrics like response times, accuracy, and resource usage.
- Uses dashboards for real-time insights and debugging.
Example: Dashboards monitor response times across models in an e-commerce recommendation system. If latency increases, the orchestrator adjusts task distribution to lighten the load on slower models.
State Management
- Maintains context across interactions, ensuring seamless workflows for tasks requiring multiple steps.
Example: In a conversational AI workflow, the orchestrator maintains context from previous interactions (e.g., a user’s preferences) to provide consistent, personalized responses across sessions.
Error Handling
- Provides fallback mechanisms when models fail to produce desired outputs.
- Flags errors for manual review or reroutes tasks to alternative models.
Example: In a financial chatbot, if a smaller model misinterprets a query, the orchestrator escalates it to a larger model or flags it for human review, ensuring seamless responses.
How LLM Orchestration Works

LLM orchestration connects and manages multiple models to complete tasks more efficiently. It relies on frameworks and tools that handle everything from prompt design to data flow between models.
The Orchestration Process Step-by-Step
Task Identification
Break the overall goal into smaller tasks. For example, one task might involve extracting data, while another focuses on generating a summary.
Model Selection
Choose models based on their strengths. For instance:
- A retrieval-focused model like GPT-3.5 for fetching relevant information.
- A reasoning-capable model like GPT-4 for interpreting complex queries.
Workflow Design
Set up a sequence of steps for the models to follow. This may include:
- Prompt chaining to pass context between models.
- Integrating APIs to connect the models with external tools.
Execution
The LLM orchestration framework processes inputs, assigns tasks to the appropriate model, and collects the outputs.
Monitoring and Adjustment
Track performance in real-time using dashboards or logs. Make changes as needed, like using LLM fine tuning for prompts or replacing underperforming models.
LLM Orchestration Tools
| Framework | Key Features | Best For |
| LangChain | Modular workflows, prompt templates, vector databases | Complex applications with modular needs |
| Haystack | Semantic search, document retrieval | Information-heavy tasks |
| LlamaIndex | Data integration, retrieval-augmented generation | Working with diverse data formats |
LLM Orchestration Frameworks
| Component | Role in Orchestration |
| Prompt Templates | Standardizes input to ensure consistent outputs. |
| Vector Databases | Stores embeddings and retrieves relevant data. |
| API Integrations | Facilitates communication between models and external tools. |
| Memory Stores | Retains context to improve response continuity. |
Real-Life Example of LLM Orchestration
Imagine building a chatbot:
- A smaller model handles standard FAQs.
- A larger model processes nuanced queries requiring reasoning.
- The orchestrator ensures smooth handoffs between the two, making the interaction seamless.
By automating these steps, LLM orchestration frameworks streamline workflows while keeping the system adaptable and efficient.
Key Challenges in LLM Orchestration (and How to Solve Them)
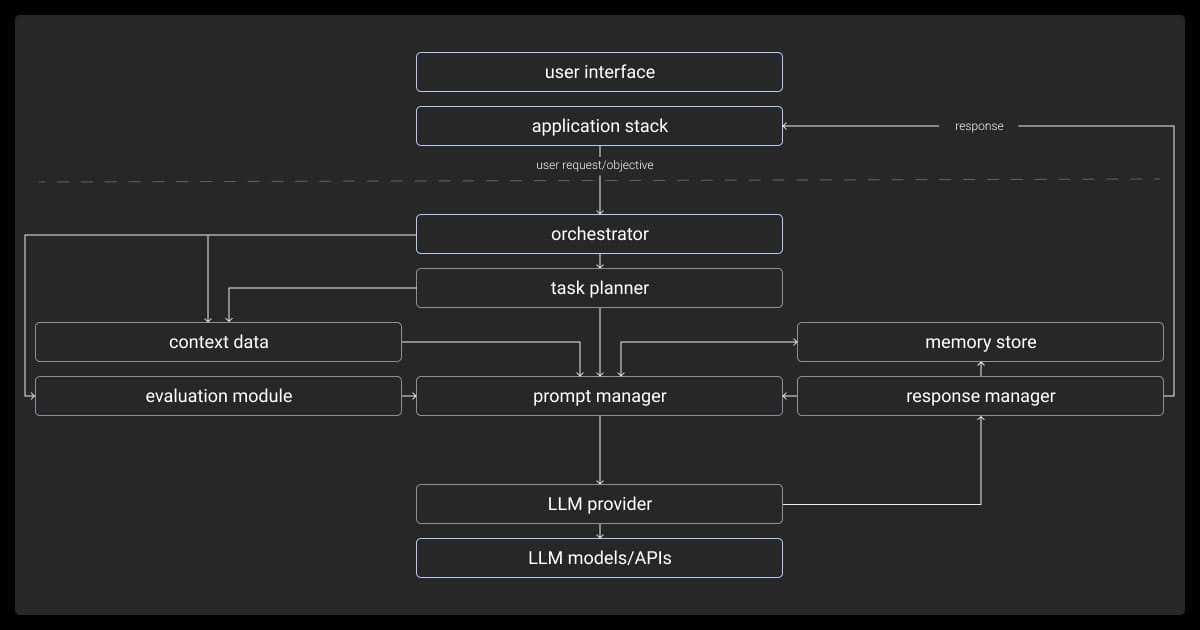
LLM agent orchestration isn’t always straightforward. If you’ve faced roadblocks like resource strain, compatibility issues, or workflow inefficiencies, you’re not alone. These challenges are common but manageable with the right strategies.
Resource Allocation
You’ve likely noticed that LLMs can drain computational resources, especially when juggling multiple models. This can lead to slower response times and inflated costs.
How to solve it:
- Use LLM orchestration frameworks that dynamically allocate resources based on the task’s complexity.
- Assign lightweight tasks, like simple text parsing, to smaller models, saving larger models for heavy lifting.
- Monitor usage regularly to identify inefficiencies and optimize workflows.
Compatibility Issues Between Models
Integrating models from different providers can feel like piecing together mismatched puzzle pieces. APIs and architectures don’t always align, and it’s frustrating to make them work together seamlessly.
How to solve it:
- Select LLM orchestration tools like LangChain or Haystack, which are designed to bridge compatibility gaps and simplify integration.
- Standardize workflows by using frameworks that support modular components, making it easier to plug and play with various models.
Data Security and Privacy Concerns
Sharing sensitive data with models, especially those hosted externally, can feel risky. Data breaches or compliance failures could be catastrophic.
How to solve it:
- Use encryption and access control to secure data at every step.
- Opt for LLM orchestration frameworks with built-in audit logs and compliance tools.
- Where possible, use on-premise deployments to keep data within your control.
Latency and Scalability Problems
As the number of tasks and users grows, response times increase, and performance takes a hit. Scaling up to handle demand often feels like playing catch-up.
How to solve it:
- Prioritize simple preprocessing tasks for smaller, faster models to reduce bottlenecks.
- Invest in scalable orchestration frameworks that allow you to add resources as demand grows.
- Optimize workflows by removing unnecessary steps that may slow down responses.
Talent Shortages
Hiring someone with the right expertise in LLM orchestration might feel like finding a needle in a haystack. Teams often struggle to keep up with the technology’s rapid evolution.
How to solve it:
- Upskill your team with targeted training on orchestration frameworks.
- Leverage LLM orchestration tools that lower technical barriers, making it easier for non-experts to contribute.
- Partner with consultants or agencies to fill immediate gaps while building internal expertise.
Error Propagation
A mistake in one model’s output can cascade through the entire workflow, creating more issues downstream. Fixing it feels like untangling a web.
How to solve it:
- Build error-handling mechanisms into your LLM agent orchestration setup.
- Use fallback systems where another model or human reviewer steps in when something goes wrong.
- Regularly test workflows with varied inputs to catch and fix vulnerabilities.
Strategies for Effective LLM Orchestration
Successfully managing multiple large language models requires more than just the right tools—it takes a clear strategy. Whether you’re optimizing workflows, scaling resources, or integrating models, these approaches will help you get the most out of your setup.
Match Models to Tasks
Each LLM has strengths and weaknesses. Assigning tasks without considering these can lead to inefficiencies or poor results.
What to do:
- Use smaller models for simple, repetitive tasks like keyword extraction.
- Reserve larger, more powerful models for complex tasks like reasoning or long-form content generation.
- Regularly evaluate model performance on specific tasks to ensure optimal usage.
Modularize tasks based on model specialization. The target is to ensure that you assign specific subtasks to the LLMs best suited for them... Monitor the execution carefully to ensure a smooth transition between tasks.
 Co-Founder, AI Tools
Co-Founder, AI Tools
Optimize Your Workflows
Efficient workflows reduce redundancy and speed up execution.
What to do:
- Break complex tasks into smaller, manageable steps.
- Use prompt chaining to pass context between models effectively.
- Streamline handoffs between models with orchestration frameworks like LangChain or Haystack.
Most people overcomplicate LLM workflows. I treat each model like a basic tool - data goes in, something comes out. When I need multiple LLMs working together, I just pipe the output from one into the next.
 Web Developer, AI Engineer & SEO Expert, Vincent Schmalbach
Web Developer, AI Engineer & SEO Expert, Vincent Schmalbach
Invest in Monitoring and Feedback Loops
Understanding how your system performs lets you catch issues early and refine operations.
What to do:
- Implement dashboards to track response times, task completion rates, and errors.
- Use logs to identify and resolve bottlenecks.
- Incorporate user feedback to fine-tune workflows and improve results.
Focus on Data Integration
LLMs perform best when they have access to the right data in the right format.
What to do:
- Connect your models to reliable data sources via APIs or vector stores.
- Preprocess data to ensure it’s clean and usable before it reaches the models.
- Store commonly used data in memory to reduce retrieval times.
Build Scalability into Your System
As your workload grows, your system should adapt without sacrificing performance.
What to do:
- Use cloud-based LLM orchestration frameworks that scale with demand.
- Test your setup under different workloads to identify weak points.
- Automate resource allocation to prevent overuse or underuse.
Prioritize Security and Compliance
Keeping data safe and meeting regulations is non-negotiable in most industries.
What to do:
- Use encryption and role-based access controls for sensitive information.
- Choose frameworks with built-in compliance features, such as audit trails and logging.
- Regularly review and update security protocols to stay ahead of risks.
By following these strategies, you’ll improve both the efficiency and reliability of your LLM orchestration, making it easier to meet your goals while avoiding common pitfalls.
Automating Data Annotation with LLM Orchestration
LLM orchestration simplifies data annotation by automating workflows that require precision and scalability. Instead of relying on manual labor of a data annotation company or a single model, orchestration combines the strengths of multiple LLMs to handle diverse labeling tasks efficiently.
How it works:
Task division
A smaller model handles basic tasks like identifying simple patterns, while a larger, more advanced model processes nuanced data, such as subjective text sentiment.
Error handling
Outputs are validated through fallback mechanisms, where low-confidence results are flagged for review or reprocessed by another model.
Scalability
LLM orchestration frameworks distribute tasks across multiple models, enabling faster processing of large datasets without compromising accuracy.
Case in point, in geospatial annotation, one model labels objects in satellite images, while another generates contextual descriptions for text-based datasets. This division streamlines workflows and minimizes errors.By orchestrating LLMs for annotation, teams can save time, reduce costs, and maintain high-quality labeled datasets for machine learning projects. Alternatively, they can opt for expert data annotation services to ensure accuracy, scalability, and customized workflows.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an LLM orchestration framework?
An LLM orchestration framework is a tool that helps manage and coordinate multiple large language models in a single workflow. It handles tasks like prompt chaining, task assignment, data integration, and error handling, making it easier to build and optimize AI-driven applications.
What is the difference between GPT and LLM?
GPT (Generative Pre-trained Transformer) is a specific type of LLM developed by OpenAI. LLMs, on the other hand, refer to any large language model trained to understand and generate human-like text. GPT is a subset of LLMs, but not all LLMs are GPT-based.
What are LLM frameworks?
LLM frameworks are software libraries or platforms designed to simplify the development and deployment of applications that use large language models. They offer tools for prompt engineering, API integration, data handling, and workflow management. Examples include LangChain, Haystack, and LlamaIndex.
What is orchestration in generative AI?
Orchestration in generative AI refers to the process of coordinating multiple AI models or components to complete complex tasks. It ensures that each part of the workflow, such as data retrieval, model interaction, and output generation, works together efficiently to produce cohesive results.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.