Multimodal AI: Combining Data Types for Smarter Models

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What’s Multimodal AI?
- How Multimodal AI Works to Integrate Diverse Data Sources
- Data Requirements: Building High-Quality Multimodal AI Models
- Practical Applications of Multimodal AI for AI Engineers and ML Teams
- How to Use Multimodal AI in Your Projects
- Labeling Multimodal AI Data: Key Challenges
- How Label Your Data Can Help
- About Label Your Data
- FAQ

TL;DR
- Multimodal AI combines multiple data types for better understanding.
- Data alignment and precise annotation are key to building multimodal datasets.
- Multimodal AI enhances real-world applications like healthcare and customer support.
- Choose the right data and tools, and fine-tune models for better performance.
- Multimodal AI improves model accuracy and context understanding.
- High-quality annotation ensures accurate data integration across modalities
What’s Multimodal AI?
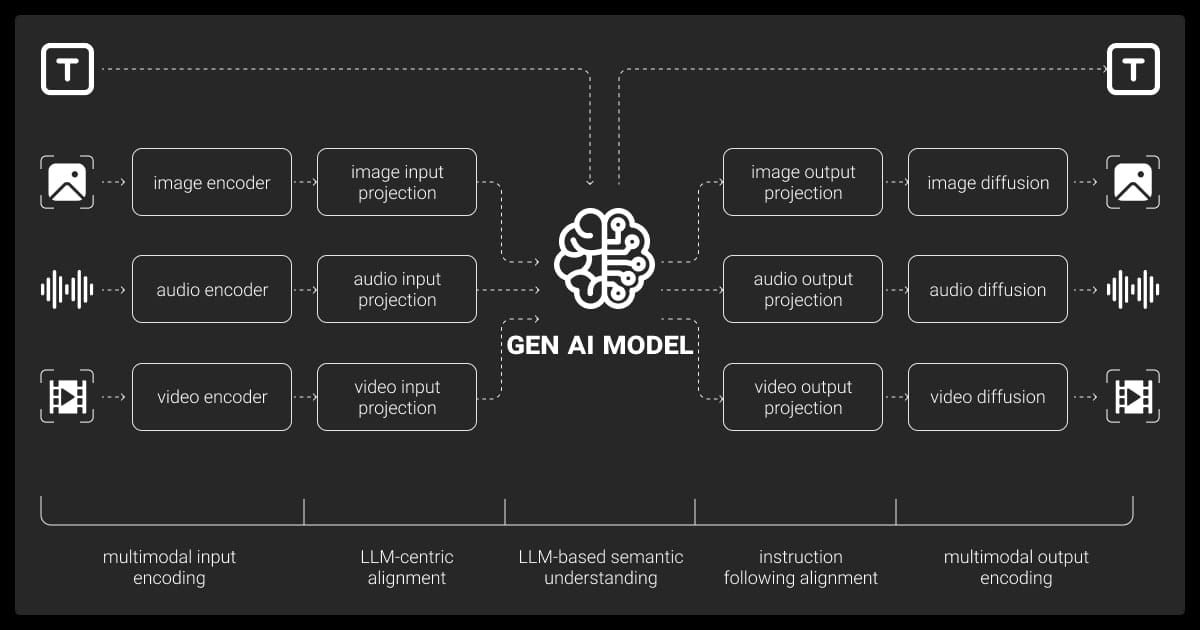
Multimodal AI is changing how machines process data. Instead of focusing on one type of input, like text or images, it combines multiple data sources. This ability makes AI systems smarter and more capable of understanding real-world situations, content, and meaning.
For AI engineers or ML teams, multimodal AI means more accurate models and better problem-solving. Whether it’s blending text with images or adding video to the mix, this approach opens up new possibilities. In this article, we’ll explore what is multimodal AI, how it works, the data it needs, and why it’s crucial for advanced AI projects.
Examples of Multimodal AI Models
Such models integrate various data types to enhance performance across diverse tasks. Below are some well-known multimodal AI examples:
| Model | Description | Modalities | Use Cases |
| CLIP (OpenAI) | Learns visual concepts from natural language supervision | Text + Image | Image classification, object recognition |
| DALL-E (OpenAI) | Generates images from textual descriptions | Text + Image | Text-to-image generation, creative design |
| Gemini (Google DeepMind) | Combines advanced vision and language capabilities to handle complex multimodal tasks | Text + Image + Audio | Interactive AI, multimodal content creation |
| VisualBERT | Combines vision and language for understanding visual-linguistic tasks | Text + Image | Visual question answering, image captioning |
| VideoBERT | Learns from unlabeled videos and speech transcripts | Video + Audio + Text | Video understanding, action recognition |
| Speech2Text (Google) | Converts spoken language to text using multimodal inputs | Audio + Text | Speech recognition, real-time transcription |
| Flamingo (DeepMind) | Handles various image and text combinations for interactive tasks | Text + Image | Interactive AI, visual reasoning |
| LXMERT (Facebook AI) | Focuses on learning vision and language simultaneously | Text + Image | Visual question answering, cross-modal reasoning |
How Multimodal AI Works to Integrate Diverse Data Sources
Let’s start with what does multimodal mean in AI:
Multimodal AI combines data from different sources to create a richer, more complete understanding.
For example, instead of just analyzing text or images separately, a multimodal AI model can process both at once. This allows the system to recognize patterns that it might miss if it only looked at one type of data.
The core of multimodal AI is data fusion. This process brings together different data types, such as text, images, audio, or even video. The AI system then analyzes these combined inputs to make more accurate predictions. For instance, an AI in healthcare system might use both medical images and patient reports to improve diagnosis.
By integrating multiple data streams, multimodal AI models can better understand context. This makes them especially useful for tasks like image recognition, video recognition, and even customer support, where both text and visual data are essential.
The Role of Different Data Types in Multimodal AI Development
Different data types are crucial in developing both traditional and multimodal generative AI systems. Text data provides context and meaning, images convey visual information, and audio can capture nuances in communication. By combining these modalities, AI systems can become more robust and effective.
Moreover, the interplay between various data types allows for richer feature extraction and more accurate predictions. For example, enhancing a text-based model with image data can improve sentiment analysis by providing visual context that supports or contradicts the textual information.
One hurdle is aligning the timing and context across modalities, particularly when dealing with dynamic data like video or speech. Without precise annotation to synchronize different modalities, the model can struggle to understand the relationship between them. Detailed temporal annotations improve the model’s ability to process complex, multimodal information cohesively.

Data Requirements: Building High-Quality Multimodal AI Models
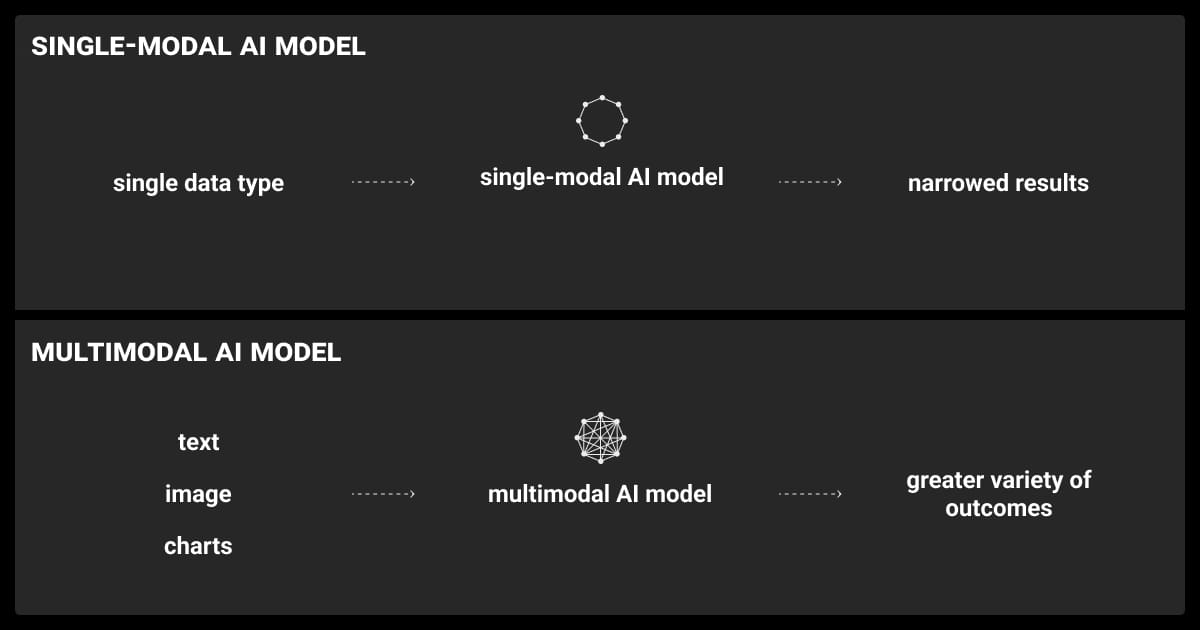
Data Alignment for Synchronized Multiple Modalities
Each modality—text, images, or audio—must be accurately paired. For instance, in a video-based dataset, every frame should be linked to the correct audio or text annotation. This synchronization allows the model to learn meaningful relationships between different input types. Without proper alignment, the model can’t connect patterns across data, leading to lower performance.
Data Consistency for Coherent Multimodal Inputs
If you’re working with text and images, each image must have a precise, contextually accurate text description. Any mismatch in the data can confuse the multimodal AI model, resulting in poor generalization. Maintaining high-quality, consistent data ensures the AI can correctly associate and process multiple inputs.
Dataset Size and Diversity
Multimodal models require large and diverse datasets to capture real-world scenarios. Datasets like COCO and Visual Genome are commonly used because they provide detailed image-text pairings. However, creating such datasets involves substantial effort in terms of annotation and verification. A diverse dataset helps the model generalize better across different contexts and applications.
Preprocessing Multimodal Data
Each data type has unique preprocessing requirements. Text data often needs tokenization and normalization, while images might require resizing or contrast adjustment. These preprocessing steps ensure that the different data inputs can be fed into the model in a compatible format. Each modality should be carefully prepared to maximize the model’s ability to understand and integrate them.
Standardizing the representation of data from different modalities into a common feature space can help the model learn from integrated data more effectively. Embedding layers, for example, can facilitate better interaction among modalities.

 CEO, Software House
CEO, Software House
Practical Applications of Multimodal AI for AI Engineers and ML Teams
By combining data from different sources, multimodal AI enables more accurate and context-rich predictions.
NLP and Computer Vision Integration
One common use case is combining natural language processing (NLP) with computer vision. For example, a multimodal AI system can analyze product descriptions and images to provide better recommendations in e-commerce. By understanding both text and visual cues, the model can offer more relevant results to users, improving overall experience and accuracy.
Multimodal Sentiment Analysis
In customer service, multimodal AI analyzes text, voice tone, and facial expressions. A multimodal AI model that can process chat messages, customer voice recordings, and video data can detect subtle emotions or dissatisfaction more effectively. This combined analysis gives businesses deeper insights into customer sentiment and allows faster, more accurate responses.
Autonomous Systems and Robotics
For autonomous vehicles, multimodal AI integrates data from multiple sensors like cameras, radar, and LiDAR. This ensures the vehicle can understand its surroundings and make safe driving decisions. By merging visual, spatial, and environmental data, autonomous systems can react more intelligently in complex real-world situations.
Healthcare Diagnostics
In healthcare, multimodal AI can combine data from medical images (like MRIs or X-rays) with patient records. This helps doctors make more informed decisions by considering visual and textual information. It’s particularly useful for diagnosing complex conditions where multiple data sources are critical for accurate treatment plans.
How to Use Multimodal AI in Your Projects
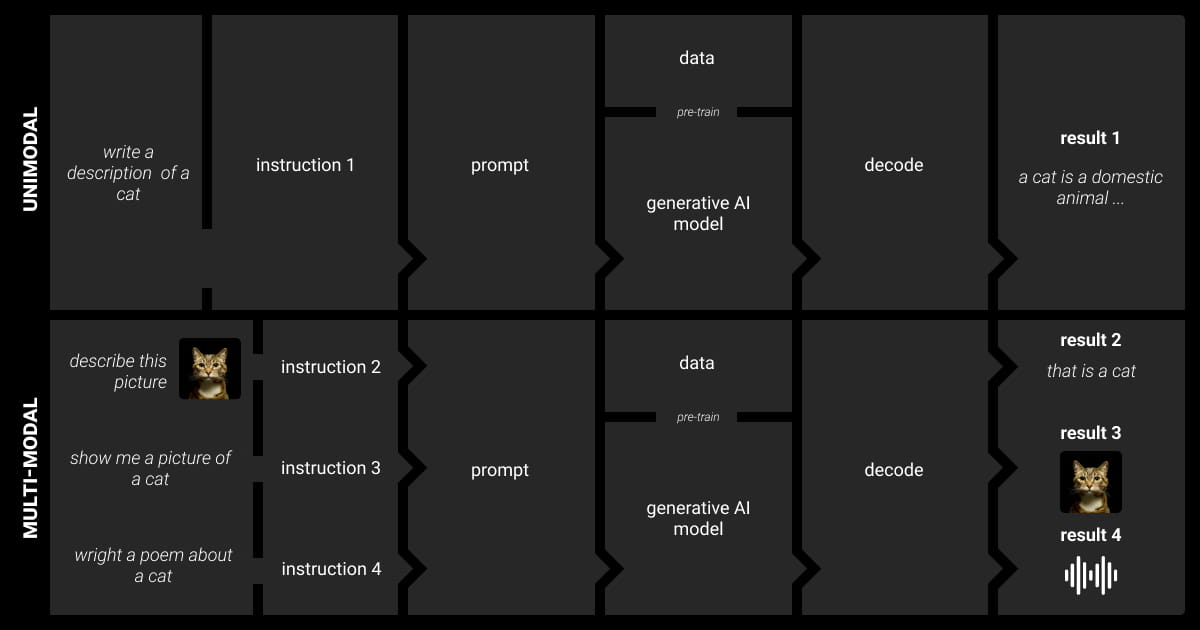
Implementing multimodal AI requires a strategic approach. This implies gathering diverse data and learning how to effectively combine and use it.
Here are key steps for AI engineers and ML teams to get started:
Step #1: Select the Right Data and Tools
Consider which modalities will offer the most value for your specific use case. For example, text and image data work well for applications like image captioning, while video and audio are crucial for tasks like speech recognition or content moderation. Use pre-trained models like CLIP or VisualBERT designed to handle multimodal inputs, reducing the effort needed to train from scratch.
Step #2: Train and Fine-Tune Your Model
Multimodal AI models require careful training to fuse data from different sources effectively. Start with a pre-trained multimodal AI model to save time and resources. Then, apply LLM fine-tuning to feed the model with domain-specific data to ensure it performs well on your specific tasks. Tools like Hugging Face’s Transformers or OpenAI’s GPT can streamline this process. Alternatively, you can opt for external help from an expert LLM fine-tuning service provider like Label Your Data.
Step #3: Manage Data Noise and Complexity
Working with multiple data types can introduce noise and inconsistencies. It’s important to clean and preprocess each type of data to minimize errors. For instance, images may need normalization, while text requires tokenization. Ensure that the features from each modality are compatible and aligned to avoid confusion during model training.
Step #4: Monitor and Optimize Model Performance
Multimodal AI models can be computationally expensive and complex to manage. Regularly monitor performance metrics such as accuracy and recall for each modality. Use optimization techniques like knowledge distillation or model pruning to reduce the size of your models and improve efficiency without sacrificing performance.
The best way to overcome integration challenges when combining multiple modalities is to convert each modality into a comparable feature space. This helps the model learn more effectively and ensures smoother interactions between data types.
 Co-Founder, AI Tools
Co-Founder, AI Tools
Labeling Multimodal AI Data: Key Challenges
Labeling multimodal data is one of the most critical steps in building effective AI models. However, it’s also one of the most challenging tasks due to the complexity of aligning multiple data types.
Labeling Multiple Data Types
In multimodal AI, each data type requires specific labeling techniques. Text annotations, image bounding boxes, and audio transcriptions demand different skill sets. Aligning these labels across different data sources can be tricky. For example, when labeling video data with audio, you need to ensure the timing and context of each label are perfectly aligned. Any misalignment could lead to reduced model performance.
Ensuring High-Quality Annotations
Poorly labeled data can confuse the model, leading to suboptimal predictions. That’s why it’s essential to engage expert annotators who understand how to handle multiple data formats. High-quality labeling ensures the model correctly learns the relationships between different data types.
Managing Large Volumes of Data
Multimodal AI often involves large datasets, which means scaling up annotation efforts can be resource-intensive. Labeling vast amounts of video, image, and text data manually is time-consuming. At Label Your Data, we use a semi-automated approach with human-in-the-loop oversight for high-quality results. This combination allows us to handle large datasets efficiently.
Data annotation is critical because it helps the model understand the connections between different data types, like linking words to objects in an image. Accurate labeling ensures the model captures relationships across modalities effectively.
 Head of Marketing & People Ops, WeblineIndia
Head of Marketing & People Ops, WeblineIndia
How Label Your Data Can Help
Whether you need labeled text, images, audio, or a combination of all three, we have the tools and expertise to deliver accurate, aligned datasets.
Our annotators are trained to work with complex multimodal datasets, ensuring that your model receives the best possible data for training. By partnering with us, you can overcome the challenges of multimodal data labeling, ensuring your AI models are trained on clean, well-annotated datasets.
Submit your data and see how we deliver high-quality annotations before you commit.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is multimodal in artificial intelligence?
Multimodal AI implies AI systems that can work with different types of data—like text, images, audio, and video—all at once. Instead of focusing on just one input type, multimodal AI combines various data sources to deliver more accurate predictions.
What is the difference between generative AI and multimodal AI?
Generative AI is all about creating new content, such as text, images, or even music, based on patterns it has learned. Multimodal AI, on the other hand, focuses on combining different data types to improve understanding. While generative AI can be part of a multimodal system, they serve different purposes: generative AI creates content, while multimodal AI processes multiple inputs for better accuracy.
Is ChatGPT a multimodal?
ChatGPT mainly works with text, which makes it a unimodal model. However, OpenAI has released GPT-4 with Vision (GPT-4V), a modern multimodal LLM. This technology allows users to analyze both images and texts together.
What is multimodal conversational AI?
Multimodal conversational AI takes things a step further by combining different forms of communication, like voice, text, and images. For instance, a multimodal chatbot can respond to spoken commands while showing relevant images or text on a screen, making conversations more interactive and informative.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.