Multimodal Machine Learning: Practical Fusion Methods

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Core Concepts Behind Multimodal Machine Learning
- Multimodal Learning Challenges to Consider
- Fusion Strategies in Multimodal Machine Learning
- Handling Missing or Noisy Modalities
- Evaluation Metrics and Benchmarks for Multimodal Machine Learning
- Real-World Use Cases and Modal Pairings That Work
- Deployment Risks and Production‑Ready Patterns
- Recommendations for Multimodal Machine Learning Teams
- When to Call in Experts or Use Multimodal Data Services
- About Label Your Data
- FAQ

TL;DR
- Multimodal machine learning works with different data types, like text, image, audio, sensors. Each requires dedicated preprocessing and modeling strategies.
- Fusion isn’t trivial; alignment, embedding, and co-learning present core challenges.
- Use early/intermediate/late fusion thoughtfully, matching the structure to the use case.
- Missing or noisy modalities demand graceful degradation and cross-modal knowledge transfer.
- Production means grappling with real-world concerns: latency, drift, monitoring, and interpretability.
Core Concepts Behind Multimodal Machine Learning
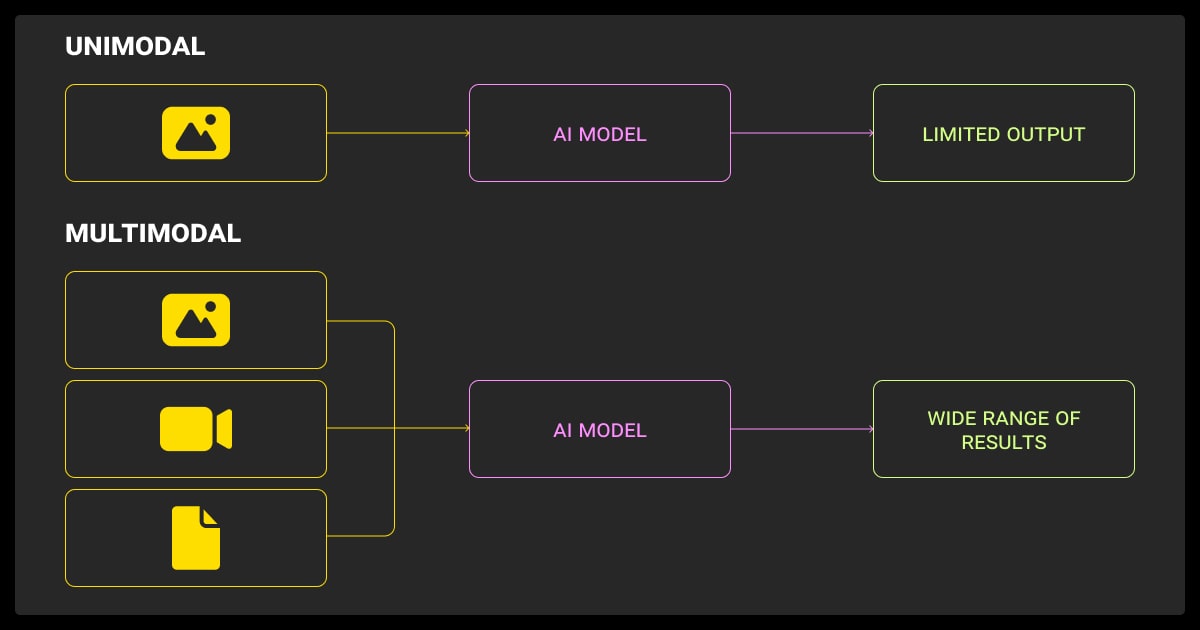
Have you ever wondered, “What is multimodal machine learning?” or, “What is a multimodal model?” In short, this is where you mix at least two of the following, text, audio, images, or video. And what is multimodal data? This refers to the actual dataset, like the text or photos that you use to train your machine learning algorithm.
Multimodal learning machine learning isn’t just slapping image and text inputs into a model and hoping for the best, it’s about jointly modeling representations, aligning semantics, and fusing insights.
Each modality carries a unique structure:
- Text is sequential and sparse
- Images are spatially structured and information-dense
- Audio is temporal and spectral
- Sensors might stream structured time-series
Simply concatenating raw feature vectors rarely produces synergy; rather, you need to solve embedding mismatches, temporal offsets, and representational disparities.
When merged correctly, modalities reinforce each other. Multimodal approaches boost performance across image captioning, VQA, retrieval, and even medical diagnosis. Just as toddlers learn “cat” by pairing meows, shapes, and touch, our models benefit from cross-modal reinforcement.
Multimodal Learning Challenges to Consider
These are the core issues to consider when it comes to multimodal machine learning:
Representation learning across diverse modalities
Finding aligned latent spaces using contrastive learning, as in CLIP, requires careful design. You need to consider contrastive losses, modality-specific encoders, and shared transformers. Professionals often pretrain encoders separately before projecting them into a joint space via projection heads and multimodal alignment objectives.
Temporal or semantic alignment between streams
Video and audio tasks demand frame-level sync. In practice, heuristic methods like Dynamic Time Warping (DTW) may help in small-scale or non-neural setups, while deep models typically use cross-modal transformer attention. For text and image (e.g., captioning), most pros leverage positional embeddings aligned with image regions.
Co‑learning when modalities are unequal or noisy
A key insight from multimodal-fusion literature is to allow strong modalities to scaffold weaker ones. With sensor dropout in self-driving cars, for instance, you can use modality dropout during training and train fusion networks to fallback gracefully.
Fusion Strategies in Multimodal Machine Learning
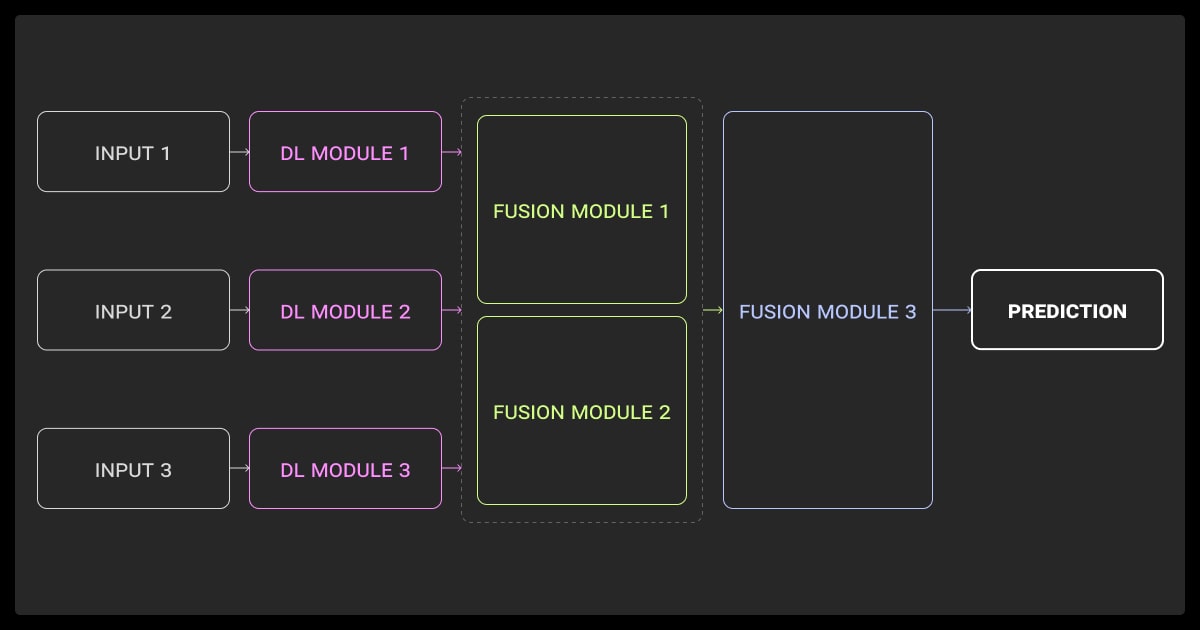
Different fusion schemes matter. Here’s what works:
Early fusion
Concatenation is simple, flatten features and combine, but be careful, as any asynchrony disrupts it. Embedding-level fusion uses pretrained encoders, then merges latent vectors, preserving the structure and reducing dimensional chaos.
Intermediate fusion
This is extremely useful. You encode each modality separately, then use cross-attention to let modalities “talk” before classification. It’s effective in VQA and image-text tasks, yielding better localized reasoning than naive early fusion.
Late fusion
When modalities arrive asynchronously or have mismatched sampling rates (e.g., audio and camera), late fusion via voting, gating, or weighted averaging works well. This is useful in multi-sensor robotics or remote monitoring systems where modality reliability fluctuates.
We replaced early fusion with a shared encoder using cross-attention, which helped the model selectively rely on the stronger modality. In one deployment with text and image inputs, the system still returned accurate results even when images failed to load, because it learned to compensate using the available product descriptions.

 Co-Founder & CEO, AIScreen
Co-Founder & CEO, AIScreen
Handling Missing or Noisy Modalities
Multimodal co-learning frameworks help robustness in a few ways.
Modality dropout and inference-time graceful degradation
During training, you can randomly zero out modality inputs, forcing the model to learn fallback behaviors. Some architectures include gating based on confidence scores to decide when to rely on backups.
Knowledge transfer from high-quality modalities
It may be useful to experiment with teacher-student setups where a complete-modal teacher teaches a missing-modal student using distillation losses. (You can reference AVID or KD-MM for audio-visual distillation cases.)
We moved away from early fusion after seeing high failure rates with incomplete or noisy inputs. Instead, we added a fusion layer that dynamically adjusts weighting based on data quality. When genomic input is unreliable, clinical data takes precedence. This design led to a 25% performance boost on sparse, real-world datasets like rare disease cohorts.
 CEO & Founder, Lifebit
CEO & Founder, Lifebit
Evaluation Metrics and Benchmarks for Multimodal Machine Learning
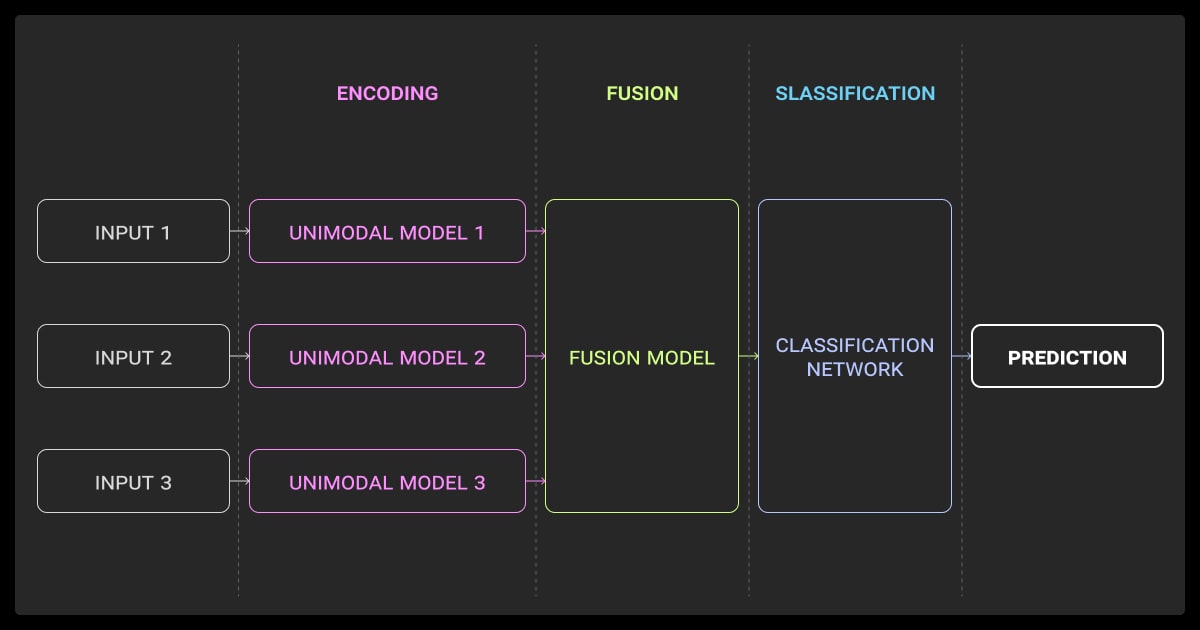
Evaluating multimodal models isn’t as straightforward as computing accuracy. You’re not just validating a prediction; you’re testing whether multiple streams of information are working together meaningfully. Depending on your task, your metrics need to reflect different things, like semantic matching, robustness to degraded input, alignment quality, and cross-modal consistency.
For retrieval and alignment tasks, say, matching an image to its caption or locating a video clip based on text, the go-to metric is Recall@K. This measures how often the ground truth appears in the top K ranked results. CLIP and similar models use Recall@1 and @5 extensively. You’ll also see median rank or mean reciprocal rank (MRR) in multimodal search.
For classification and sequence labeling (e.g., VQA, emotion detection, sentiment from audio + text), you still rely on Accuracy, Precision, Recall, F1, but you’ll often want to break this down per-modality, or test degraded cases (e.g., text-only, image-only, text+image) to evaluate fusion effectiveness.
For robustness testing, especially in real-world systems, consider:
- Modal ablation tests: evaluate performance when one or more modalities are dropped, corrupted, or noisy.
- Perturbation sensitivity: measure output stability under input variations.
- Out-of-distribution detection: key in safety-critical systems.
In healthcare, you may add:
- AUROC (Area Under Receiver Operating Characteristic) for imbalanced tasks
- Calibration metrics (Brier score, expected calibration error) to assess whether the model is confidently wrong, which is dangerous in clinical settings.
Standard benchmarks
These are the de facto testing grounds:
- MSCOCO, Flickr30k: image-caption pairs, widely used for image-to-text alignment.
- VQA v2, GQA, TDIUC: for visual question answering.
- CMU-MOSEI, CMU-MOSI: for sentiment from video, audio, and text.
- AVE (Audio-Visual Event): synchrony between sound and video.
- KITTI, nuScenes, Waymo Open: sensor fusion datasets in autonomous driving.
- MIMIC-CXR, RadImageNet: for multimodal medical analysis with image + structured data.
You can create custom validation splits that isolate modality-specific failure cases. You’ll learn more from where it fails than just how often.
Real-World Use Cases and Modal Pairings That Work
These modality pairings work well for real-world tasks like captioning, diarization, and sensor fusion.
Vision + text
Some pros built pipelines with vision encoder + transformer, followed by a text classifier to spot toxic context. These beat uni-modal baselines hands-down.
Audio + video
Aligning Mel-spectrogram embeddings with facial embeddings using cross-attention works best for speaker diarization. It’s key in broadcast transcription.
Sensor fusion
Here you merge LiDAR, radar, and GPS via gated RNN or transformer fusion layers. Temporal alignment, calibration, and noise handling dominate engineering efforts.
GPT‑4 and Google Gemini tackle text+image queries via multimodal transformers, the commercial proof’s in large-scale deployment.
Deployment Risks and Production‑Ready Patterns
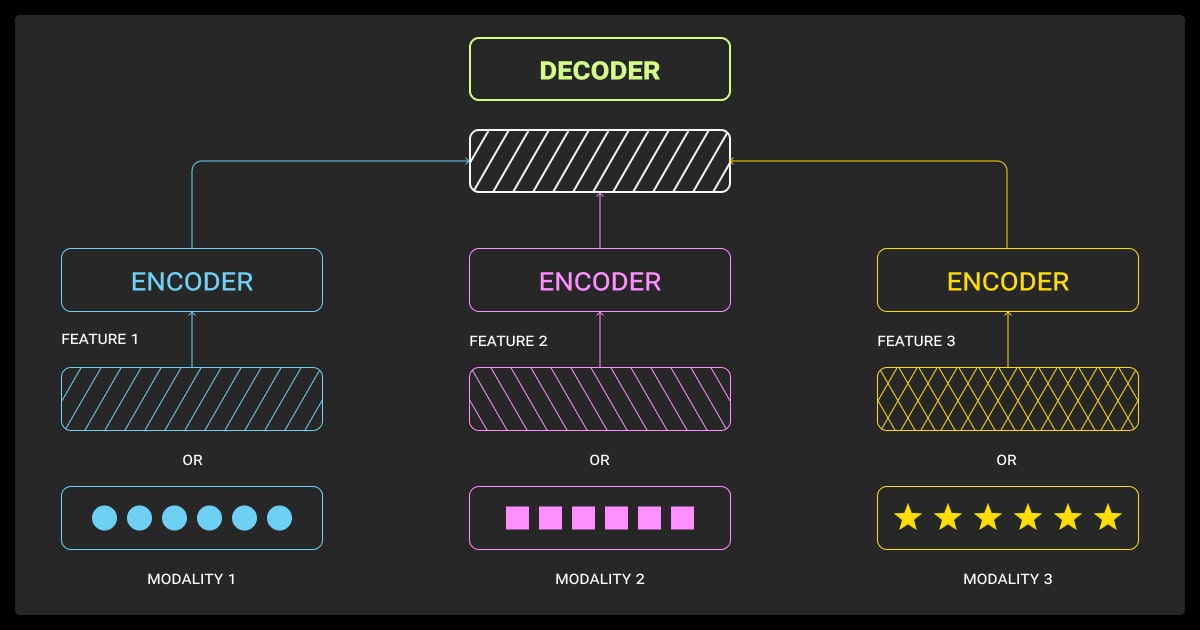
Deploying multimodal systems is tough:
- Compute and latency: Multimodal encoders are heavy. I use quantization, distillation, or offload one modality.
- Drift monitoring: Track input distribution per modality, set alerts.
- Debugging: Log per-modality errors and visualize attribution. It’s messy but necessary.
Multimodal systems might dazzle in research, but in production, they introduce new failure modes you won’t see in single-modality setups. Here’s where things usually go sideways:
Compute cost and latency
Multimodal models can balloon in size, especially with dual encoders or joint transformers. If you’re using ResNet-50 for images and a BERT variant for text, your inference cost just doubled, before fusion.
- You should quantize where possible. Knowledge distillation into smaller uni-modal heads helps. You should also consider caching static modality embeddings when possible (e.g., use image encodings precomputed offline).
- Batching strategy: You should avoid asynchronous modality inputs that trigger duplicate forward passes. Batch intelligently across shared encoders.
Monitoring and Input Drift
Each modality has its own drift characteristics. A well-lit product image dataset may quietly turn into blurry user-uploaded photos. Your audio data might degrade due to poor mics or compression. Text input can change tone (e.g., emojis or abbreviations).
- You can build modality-specific drift detectors. Monitor activation distributions or latent embedding variance. Track changes in embedding norms across time slices, if it jumps, something’s off.
- Use reconstruction errors or entropy estimates from modality-specific autoencoders to catch anomalies early.
Debugging Multimodal Models
Where did the model go wrong? Was it the visual input, the transcript, or the fusion logic? Without proper logging and attribution tools, you’re flying blind.
- Log intermediate representations. You should record latent embeddings before and after fusion layers.
- Use Grad-CAM or integrated gradients per modality to attribute predictions.
- Create fallback modes that log which modality was dropped or underweighted during prediction.
- Build tooling that lets non-engineers (like product managers or doctors) understand the system’s reasoning across modalities.
Using a shared encoder allowed us to maintain around 85% accuracy even when some input modalities were missing, like corrupted audio. This helped keep model output stable despite unreliable connections or partial input on the user side.
 Chief Product Officer, Cognito Education
Chief Product Officer, Cognito Education
Recommendations for Multimodal Machine Learning Teams
Whether you’re a startup prototyping a voice-activated assistant or an enterprise team building autonomous vehicles, your engineering architecture matters. A lot.
Choose your fusion strategy based on task and data
There’s no “best” fusion method, only the one that fits your task. For highly correlated modalities (e.g., audio+video of a speaker), intermediate fusion via cross-attention shines. For asynchronous or noisy modalities, late fusion provides resilience.
It’s worth considering:
- Early fusion only works if data is tightly synchronized and well-aligned.
- Intermediate fusion enables attention-based cross-modal interaction and is widely used in tasks like VQA.
- Late fusion is suited to asynchronous, modular systems where modalities arrive at different rates.
Use attention heatmaps or learned gating weights to validate that fusion is working as intended, not just pushing one dominant modality through.
Use modular architectures to isolate issues
Build your model in pieces. Separate encoders per modality let you:
- Reuse pretrained weights
- Swap or fine-tune specific parts
- Debug more effectively
- Train with missing modalities
This makes the entire pipeline more robust, especially under partial data or failures in one sensor stream.
Use encoder-decoder or encoder-projection-fusion-head style blueprints with clear handoff points between stages.
Use curriculum learning to stabilize training
Start by training each modality encoder individually on unimodal tasks, then progressively introduce fusion layers and joint objectives. It’s often more stable than end-to-end training from scratch.
When to Call in Experts or Use Multimodal Data Services
At some point, doing it yourself stops making sense. Multimodal learning sounds impressive, but it’s deceptively tricky in real-world applications. Here’s when it’s worth bringing in specialized support:
When data collection or annotation becomes complex
Creating well-aligned datasets across modalities is a bottleneck. Misalignment between audio and video, or image and text, creates garbage-in, garbage-out situations. Data annotation, especially when temporal or spatial alignment, like with image recognition, is required, is expensive.
- Consider Label Your Data, V7, Scale AI, or SuperAnnotate for structured multimodal labeling.
- For speech, you might need forced alignment tools (e.g., Gentle) or phoneme-level segmentation.
- Look at hiring a data annotation company and data collection services that can assist with LLM fine tuning. This is also useful when you’re dealing with limited machine learning datasets. They can help expand the set with quality examples.
You’ll know it’s time to make the switch when your costs keep climbing and your in-house team can no longer cope. That’s when it pays to shop around to find the best data annotation pricing and data annotation services. It’s worth looking for a team with a proven track record rather than just going for the cheapest option.
When interpretability is mission-critical
In healthcare, legal tech, or financial systems, you’ll need to explain predictions. If you’re working in high-stakes fields, bring in experts in explainability or use vetted APIs (like Azure’s multimodal cognitive services) that include traceable logs for machine learning model training. Don’t rely on raw logits, build post hoc explanation layers or visualizations.
When scaling across modalities
When expanding to new modalities (e.g., adding video to an existing audio pipeline), integration can get messy. Third-party providers often have prebuilt pipelines, encoders, or tools to reduce development time.
OpenAI, Google Cloud, and AWS all offer multimodal APIs and multi agent LLM are worth testing for early prototypes before building in-house.
When regulatory or safety requirements kick in
You’ll need audit trails, test-time modality fallback, fairness audits across demographic groups and sensors, and failure reports. Don’t improvise here. Bring in a firm experienced in safe AI deployment.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is multimodal learning in machine learning?
Multimodal machine learning is when models learn from two or more data types, text, image, audio, by linking them through shared latent spaces or fusion layers.
What is an example of multimodal learning?
CLIP is one example of multimodal learning that aligns image and text embeddings for zero-shot classification. GPT‑4 vision is another that processes images and instructions simultaneously. These two are the best multimodal learning examples.
Is ChatGPT a multimodal model?
GPT‑4 can be a multimodal AI, but the version matters. When you enable image input, it truly is, combining vision and text through transformer layers.
What is an example of multimodal deep learning?
Visual Question Answering (VQA) is a good example that combines CNN image features with LLM-style reasoning to generate answers about an image.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.