Machine Learning Model Training: A Comprehensive Guide

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What You’ll Learn in This Guide
- Preparing Your Data for Machine Learning Model Training
- Choosing the Right ML Model
- Infrastructure You Need for Machine Learning Model Training
- Training Your Model (and Not Breaking It)
- Evaluating Model Performance after Machine Learning Model Training
- Hyperparameter Tuning
- ML Model Deployment and Monitoring
- Advanced Machine Learning Model Training Techniques
- Best Practices for Training and Final Tips
- About Label Your Data
- FAQ

TL;DR
- Training a machine learning (ML) model is one of the most critical stages of building any AI system.
- It all starts with understanding your problem and data requirements; choosing the right model comes next.
- In 2025, model training means managing data, infrastructure, experimentation, and operational complexity at scale.
- The better you prepare your datasets, the better your outcomes.
What You’ll Learn in This Guide
This guide offers a clear, practitioner-focused overview of the machine learning model training process in modern production pipelines. You’ll learn how to prepare data, choose models, optimize infrastructure, and avoid common pitfalls.
We also cover how to evaluate, tune, and deploy models for long-term success, all while ensuring reproducibility and reliability.
Preparing Your Data for Machine Learning Model Training
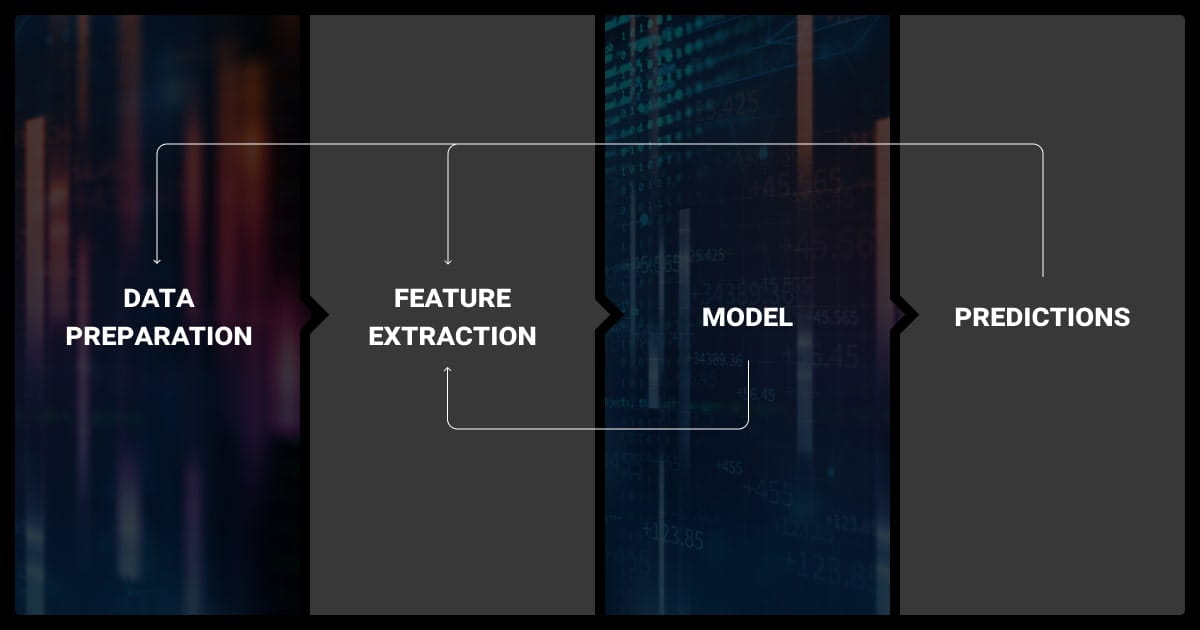
If you’re not sure how to go about this, you may want to partner with a data annotation company. While this does add to the project costs, data annotation services are usually more efficient than resource-heavy in-house efforts. They specialize in this area, and work with a pool of expert annotators.
If you’re working with different types of LLMs, choose data formats and annotations aligned with your NLP tasks. For other domains, focus on domain-specific structures.
The key to success is properly preparing your data. This includes not only data annotation but also collecting the right types of machine learning and training data.
Overall, professional data labeling in machine learning can bring down the overall data annotation pricing by improving speed and accuracy.
Data Collection and Cleaning
Training data quality is the foundation of any successful machine learning algorithm or LLM fine tuning project. Data typically comes from databases, logs, APIs, sensors, or third-party datasets. Formats include CSVs, JSON, images, audio files, and video, each with unique challenges.
Before training begins, you must clean your data. You’ll need to:
- Remove duplicates
- Handle missing values with imputation or deletion
- Watch for noisy labels in classification tasks.
You must also validate schemas and apply type consistency checks. Use anomaly detection machine learning techniques to spot outliers or inconsistencies that could skew training.
Need help with putting together a high-quality machine learning dataset? You can look into partnering with reputable data collection services.
Feature Engineering
For the next step in model training machine learning, we need to look at features. These bridge raw data and predictive power.
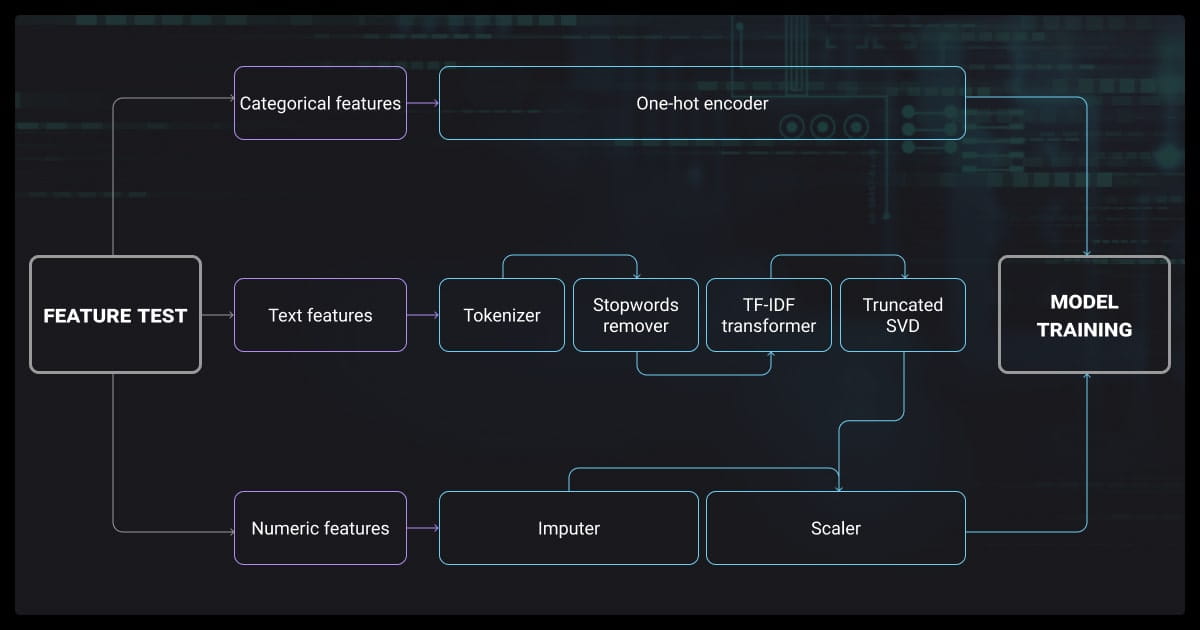
For structured data, you need to encode categorical variables (one-hot, label encoding), and you may need to scale numerical features (min-max, standardization). Time-series data often benefits from lag-based features or rolling aggregates.
For unstructured data, such as text or images, you’ll extract features using tokenization, embeddings (e.g., Word2Vec, BERT), or convolutional filters. Apply transformations like log scaling to reduce skew, and dimensionality reduction techniques like PCA to simplify input space.
Data Splitting
You should always divide your dataset into training, validation, and test sets (typically 70/15/15 or 60/20/20). You can use stratified splits for imbalanced classes and time-based splits for temporal data for model training in machine learning.
Likewise, you can use cross-validation (e.g., k-fold, stratified k-fold, time series cross-validation) for more robust performance estimation. Finally, avoid data leakage; no future information should bleed into training sets.
Everything about AI/ML model development boils down to one thing — data quality. Before training, we identify sources, audit every column, and apply aggressive quality checks. This focus alone helps tremendously downstream.

 Founder & CEO, ThirdEye Data
Founder & CEO, ThirdEye Data
Choosing the Right ML Model
Finding the right model is the next crucial step in the machine learning model training process.
Matching Model Type to Problem Type
You should choose your training model in machine learning based on your task:
- Classification: Logistic regression, random forest, gradient boosting
- Regression: Linear regression, SVR, XGBoost
- Ranking: LambdaMART for learning-to-rank scenarios; transformers for semantic relevance in search or QA systems
- Generative Tasks: GANs, VAEs, transformers
Each model class is optimized for specific objectives and input-output formats.
ML Algorithms vs. Deep Learning Models
Deep learning (DL) shines with unstructured, high-dimensional data (e.g., images, audio, and text). But don’t underestimate traditional ML. A well-tuned XGBoost model can outperform a transformer when data is tabular and features are clean.
Logistic regression, decision trees, and SVMs are interpretable and lightweight. Use DL only when it solves a problem ML can’t, or when pre-trained models provide a huge head start. Plus, use it when model performance scales meaningfully with more data and compute, especially in vision or language tasks.
Model Complexity and Interpretability Trade-offs
Deep neural networks offer high capacity but low transparency. ML models like random forests or linear models are easier to debug, audit, and explain, which is critical in regulated industries like finance or healthcare. You’ll choose the best option based on your stakeholder’s needs.
Infrastructure You Need for Machine Learning Model Training
What kind of infrastructure will you need for optimal results?
Local vs. Cloud vs. Distributed Training
You can train locally during prototyping. As your datasets and models grow, you should move to the cloud (AWS, GCP, Azure) for scalable compute and storage. For large-scale models, you can use distributed training with tools like Horovod or DeepSpeed.
Horizontal scaling increases nodes; vertical scaling uses beefier machines. You can use job schedulers like Kubernetes and Ray to manage distributed workloads and auto-scale based on demand.
Hardware Considerations
What computing power will you need for the average machine learning model training example?
- CPU: Best for small models, preprocessing
- GPU: Crucial for DL workloads (NVIDIA A100, H100)
- TPU: Google’s chips optimized for TensorFlow and JAX
The batch size affects training speed and memory, so you should think about this when planning machine learning optimization. Larger batches need more GPU RAM but converge faster.
Frameworks and Tooling
Choose based on your needs:
- ML Models: scikit-learn, XGBoost, LightGBM
- Deep Learning: PyTorch, TensorFlow, JAX
- NLP/LLMs: Hugging Face Transformers
- Tracking: MLflow, Weights & Biases (W&B), ClearML
You can use version control (Git), reproducible environments (Docker, Conda), and pipelines (Dagster, Airflow) to streamline training and overcome issues like bias in machine learning. That way, you can roll back to earlier checkpoints or configurations if training diverges.
Training Your Model (and Not Breaking It)
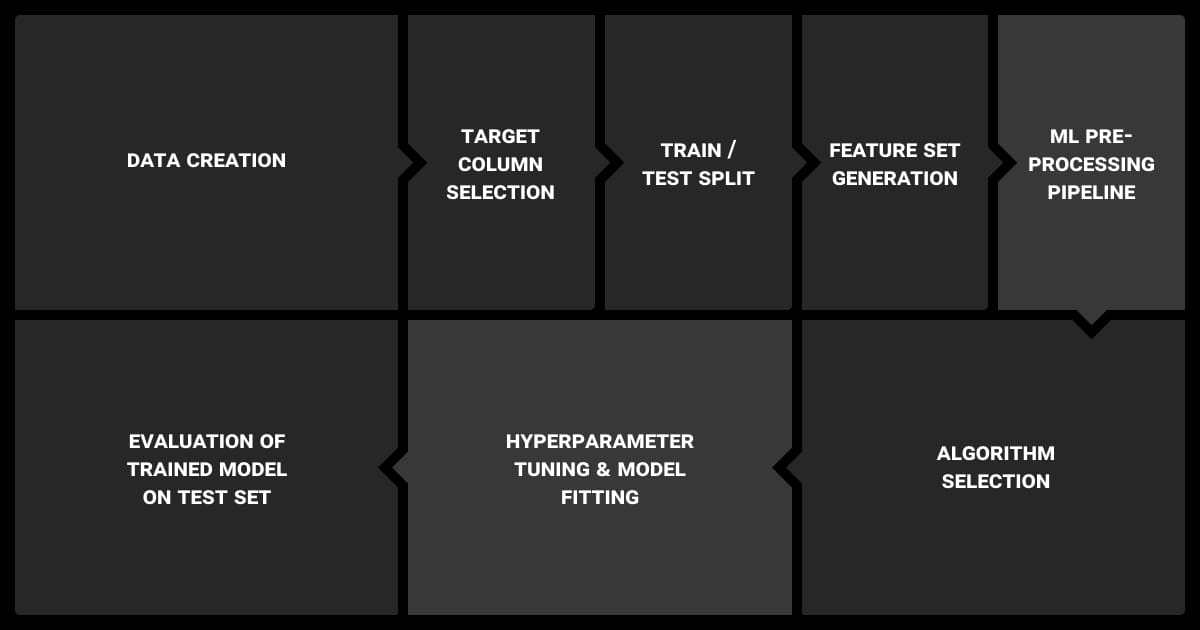
You’ll need to make decisions about whether to include unlabeled data in machine learning and also consider the supervised vs. unsupervised learning debate. The method you choose depends on what you want your model to do.
For example, image recognition tasks often require a large number of labeled data points to capture spatial features and object variations, unlike LLMs that rely on vast text corpora but don’t require spatial annotations.
If you want to learn more about these issues, check out our article on how to label data for ML projects. Now let’s look at technical stuff.
Selecting Optimizers and Loss Functions
You must choose loss functions that align with your objective:
- Classification: Cross-entropy
- Regression: MSE, MAE
- Ranking: Pairwise or listwise loss
- Generation: Loss functions like negative log-likelihood
Optimizers like Adam, RMSProp, and SGD are standard. You can use learning rate schedules like cosine annealing or step decay to improve convergence.
Training Loops and Batching
You should design training loops that iterate over mini-batches. Then monitor training and validation loss across epochs. Use dynamic learning rate adjustments to avoid plateaus. Doing this makes it easier to catch errors and fix them before they become ingrained.
Batch sizes (32–1024) depend on hardware and model type. Use framework-native data loaders (e.g., DataLoader in PyTorch, tf.data in TensorFlow) for shuffling, batching, and augmentation.
Regularization Techniques
You can prevent overfitting with:
- Dropout: Randomly disables neurons during training
- Weight decay (L2): Penalizes large weights
- Early stopping: Halts training when validation loss stops improving
- Gradient clipping: Avoids exploding gradients
Diagnosing and Fixing Training Failures
Here are some common issues you may need to deal with:
- Vanishing gradients: Use ReLU or batch normalization
- Exploding gradients: Apply clipping or smaller learning rates
- Overfitting: Try dropout, simpler models, or more data
- Label leakage: Audit feature-label relationships
- Diverging loss: Check for bugs, scale mismatches, or bad learning rates
Evaluating Model Performance after Machine Learning Model Training
You should check your model’s performance periodically.
Performance Metrics by Task
- Classification: Accuracy, precision/recall, F1 score, AUC
- Regression: MAE, RMSE, R²
- NLP: BLEU, ROUGE, perplexity
- Ranking: MAP, NDCG
BLEU and ROUGE are common for summarization and MT, though newer metrics like BERTScore may better capture semantic fidelity.
You should choose metrics that reflect the business impact; especially in imbalanced or high-risk domains.
Confusion Matrices, Calibration, and Error Analysis
Confusion matrices provide class-level breakdowns. You can calibrate classifiers with Platt scaling or isotonic regression to improve probabilistic outputs. You should manually inspect false positives/negatives for hidden failure modes.
Cross-Validation and Robustness Checks
You should always validate on multiple folds to ensure stability. Test model robustness with adversarial examples, perturbed data (e.g., adding noise, masking inputs), or shifted distributions.
Hyperparameter Tuning
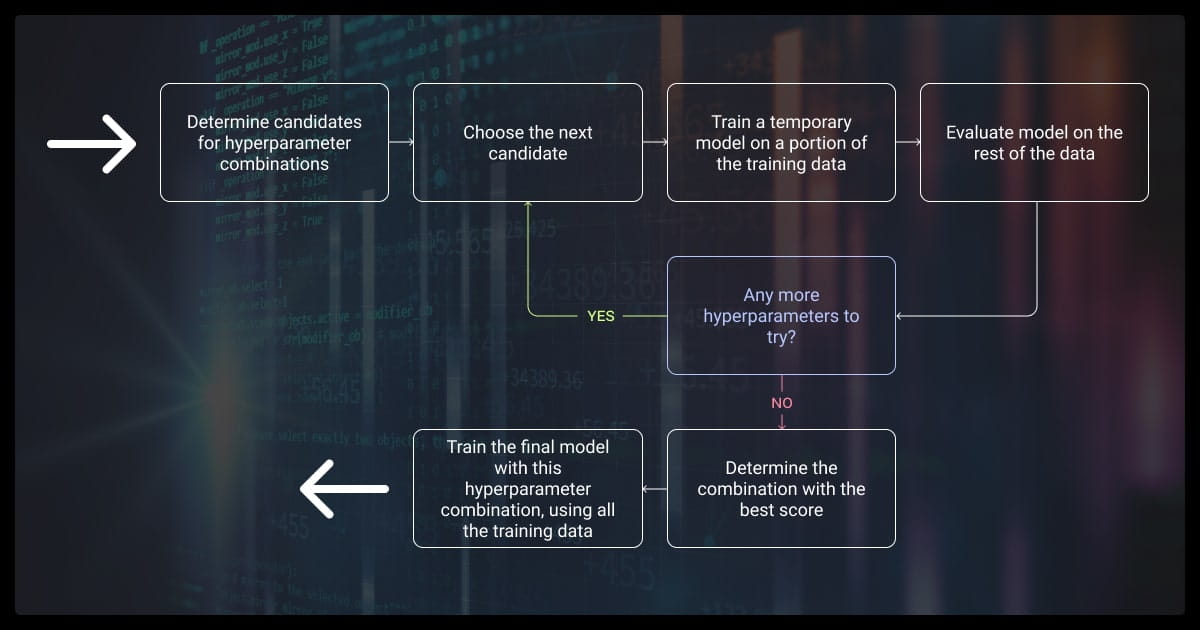
Now let’s look at fine-tuning your hyperparameters.
Grid Search, Random Search, and Bayesian Optimization
You can use:
- Grid search for small spaces
- Random search for better coverage in high dimensions
- Bayesian optimization (Optuna, Hyperopt) for efficiency
You should consider the tune depth, learning rate, regularization, and architecture parameters.
When to Use Early Stopping and Learning Rate Scheduling
Use early stopping to halt training when further validation no longer improves the results. You can combine this with learning rate warm-ups and decay for smoother convergence.
Tuning at Scale: AutoML and Parallel Runs
Tools like Google Vertex AI, H2O.ai, and SageMaker Autopilot automate tuning. These are useful when expert tuning isn’t feasible or when exploring large hyperparameter spaces rapidly. You can run parallel experiments using Ray Tune, Dask, or W&B sweeps to find the best fit.
Hyperparameter optimization consistently improves performance. It’s a high-leverage activity with one of the biggest bang-for-buck payoffs — if you're willing to put in the trial and error.
 CMO, G-BRIS
CMO, G-BRIS
ML Model Deployment and Monitoring
How do you make sure the model deploys successfully?
Model Versioning and Reproducibility
You must track everything: code, data, environment, model artifacts. You can use:
- DVC for data versioning
- MLflow or W&B for experiments and models
- Docker/Conda to freeze environments
Reproducibility ensures consistent results across teams and time.
Deployment Options
Choose based on latency and frequency:
- Batch inference: Best for non-time-sensitive use cases
- Real-time APIs: Low-latency use cases (fraud detection, chatbots)
- Serverless: Scalable endpoints via AWS Lambda or GCP Cloud Functions
- Hosted: SageMaker, Vertex AI, or custom Kubernetes services
Continuous Monitoring
Once you deploy your model, monitor:
- Concept drift: When relationships between features and labels change
- Data distribution shifts
- Latency and error rates
You can set up alerting and retraining triggers via MLOps stacks, like Seldon (model serving and monitoring) and Evidently AI (data drift and performance tracking).
Advanced Machine Learning Model Training Techniques
Do you have time or budgetary constraints? Improve performance without compromising on quality with these techniques.
Transfer Learning and Fine-Tuning
You can use pre-trained models as feature extractors or fine-tune them on your data. This is great for tasks like NLP (BERT, T5) or computer vision (ResNet, ViT) with limited labeled data.
Active Learning
You should only label the most informative samples. You can use uncertainty sampling or committee-based methods to reduce labeling costs and boost performance efficiently.
Federated Learning and Privacy-Aware Training
You should train across decentralized devices without moving data. You can combine with differential privacy or secure aggregation to maintain compliance in healthcare, fintech, or IoT.
Counterfactual Data Augmentation is a highly effective ML training technique. For example, changing 'I love this product' to 'I hate this product' in sentiment analysis helps models generalize better, reduce bias, and improve robustness.
 Founder, Deep AI
Founder, Deep AI
Best Practices for Training and Final Tips

Ready to get the best results? Go through these tips first.
Build Reproducible Workflows from Day One
You should automate pipelines, version everything, and log parameters and metrics. Reproducibility makes collaboration and debugging much easier.
Monitor Everything, Not Just Accuracy
Track training loss, validation scores, gradients, weight histograms, memory usage, and time per epoch. Early anomaly detection saves time and resources.
Always Validate on Unseen Data
Never trust a model until you evaluate it on unseen, realistic test data. Holdout sets simulate deployment conditions and prevent false confidence.
Machine Learning Model Training Resources to Go Deeper
- Books: Deep Learning (Goodfellow), Hands-On Machine Learning (Géron)
- Docs: scikit-learn, PyTorch, TensorFlow, Hugging Face
- Communities: r/MachineLearning, Papers with Code, arXiv-sanity
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is model training in machine learning?
Model training is the process of teaching an algorithm to learn from data by adjusting its internal parameters to minimize error. It relies on optimization algorithms like gradient descent and loss functions that quantify mistakes.
The goal is to help the model generalize to unseen data, not just memorize the training set. This requires careful tuning, regular evaluation, and techniques to prevent overfitting.
How to train my machine learning model?
- Prepare your data by cleaning, preprocessing, and formatting it for input.
- Split the dataset into training, validation, and test sets
- Choose a model that fits your task and data type.
- Define a loss function and optimizer to guide the training process.
- Train the model by feeding in batches and updating weights over epochs.
- Evaluate performance on validation and test data to ensure generalization.
- Tune hyperparameters to improve accuracy and prevent overfitting.
What are the 4 types of machine learning models?
Supervised learning uses labeled data to train models for tasks like classification or regression. Unsupervised learning finds hidden patterns in unlabeled data.
Semi-supervised learning combines small labeled datasets with large unlabeled ones. Reinforcement learning trains agents to act in environments by maximizing rewards.
How to make a machine learning model in 7 steps?
- Collect relevant data.
- Clean and preprocess it.
- Split into training, validation, and test sets.
- Choose the right model.
- Train using optimization algorithms.
- Evaluate performance on unseen data.
- Deploy and monitor the model in production.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.