Anomaly Detection Machine Learning: How It Works

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Anomaly Detection in Machine Learning?
- How Does Anomaly Detection Machine Learning Work?
- Choosing the Right Anomaly Detection Algorithm
- Real-World Applications of Anomaly Detection Machine Learning
- Challenges and How to Overcome Them
- Best Tools and Libraries for Anomaly Detection Machine Learning
- About Label Your Data
- FAQ

TL;DR
- Detects fraud, security threats, and system failures by spotting unusual patterns.
- Supervised learning uses labels, unsupervised finds unknown anomalies, deep learning handles complex cases.
- False alarms and scalability issues can be improved with better tuning and explainability.
- Top tools include Scikit-learn, PyOD, TensorFlow, AWS Lookout, and Google Cloud AI.
- Real-time detection, AutoML, and self-learning models are advancing machine learning anomaly detection.
What Is Anomaly Detection in Machine Learning?
Anomaly detection in machine learning finds data points that don’t fit normal patterns. These outliers can signal fraud, cyber threats, system failures, or mistakes in data.
Unlike basic rule-based methods, machine learning for anomaly detection learns and improves over time. This makes it more effective at handling large datasets and spotting new risks. It can also analyze unlabeled data, making them effective for detecting anomalies without predefined labels.
What Qualifies as an Anomaly?
Anomalies, or outliers, are data points that don’t follow the usual pattern. They can be errors, rare events, or early signs of a problem. Finding them early helps prevent fraud, security breaches, and system breakdowns.
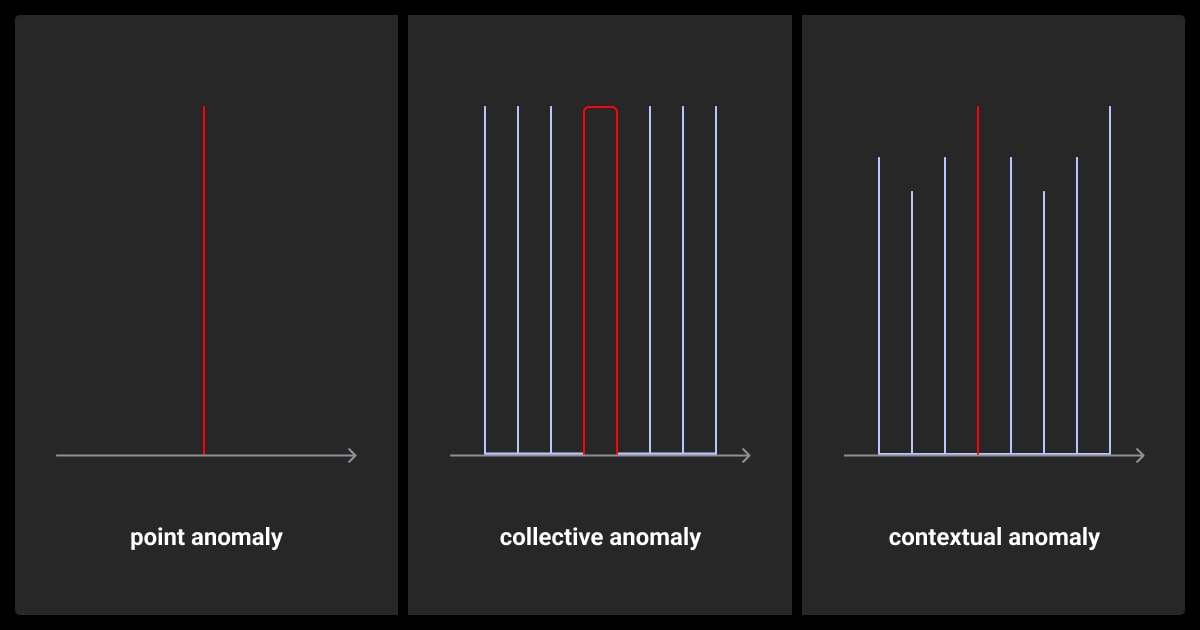
There are three main types of anomalies:
- Point Anomalies: A single data point that is very different from the rest.
- Contextual Anomalies: A data point that seems normal in general but is odd in a specific situation.
- Collective Anomalies: A group of data points showing a strange pattern.
Why Detecting Anomalies Matters
Finding anomalies helps businesses avoid big problems. Anomaly detection using machine learning is useful for:
- Fraud detection: AI anomaly detection can catch unusual bank transactions.
- Cybersecurity: Machine learning can spot strange network activity before an attack happens.
- Equipment maintenance: Detecting sensor changes early can prevent machine failures.
How Does Anomaly Detection Machine Learning Work?
Machine learning detects anomalies by learning patterns in data through pattern recognition. Instead of using fixed rules, it looks for unusual behavior and improves over time. This helps catch fraud, errors, and system failures more accurately.
Step 1: Collect and Prepare Data
Before finding anomalies, the system needs clean data. This involves:
- Gathering data – From bank transactions, network logs, sensors, or other sources.
- Cleaning data – Fixing missing values, removing duplicates, and formatting data correctly.
- Choosing key features – Picking the most important data points for detection.
If the data is messy or incomplete, the model might not detect key patterns.
Step 2: Learn What’s Normal
The system studies past data to understand normal behavior. It:
- Finds common patterns in past transactions, sensor readings, or other activities.
- Creates a baseline of what looks normal.
- Defines key metrics, like average spending, usual website traffic, or machine temperatures.
Once trained, the model can compare new data to this baseline and flag anything unusual.
Step 3: Detect Anomalies
When new data arrives, the model:
- Checks for differences – It flags anything that doesn’t match past patterns.
- Scores the anomaly – It rates how unusual the data is.
- Classifies the outlier – It decides if the anomaly is harmless or a real problem.
Different anomaly detection machine learning algorithms work better for different situations.
| Algorithm | Best for | Example |
| Isolation Forest | Rare events | Fraud detection |
| K-Means Clustering | Group behavior | Detecting website attacks |
| Autoencoders (Deep Learning) | Complex patterns | Predicting machine failures |
Step 4: Take Action
Once an anomaly is found, businesses must decide what to do:
- Send an alert – Notify security teams or engineers.
- Investigate or block – Stop suspicious actions or review flagged cases.
- Improve the model – Add new data to make the system smarter.
Looking at data through multiple lenses reveals patterns that single-perspective analysis often misses. Successful anomaly detection isn’t about finding individual outliers – it’s about understanding how metrics move together across time.

 Sr. VP of Marketing, Next Net Media
Sr. VP of Marketing, Next Net Media
Choosing the Right Anomaly Detection Algorithm

Different ML methods work better for different types of anomalies. The best choice of a machine learning algorithm depends on the dataset, the type of anomalies, and the need for real-time detection.
Supervised Learning: Best When Labeled Data Is Available
Supervised learning models need labeled examples of normal and abnormal behavior. They learn from past data and classify new data points based on what they have seen before.
Best for:
- Fraud detection with past fraudulent transactions
- Manufacturing defect detection
- Medical diagnosis with labeled patient data
Common models:
- Decision Trees – Sorts data based on rules learned from labeled examples.
- Support Vector Machines (SVM) – Draws a boundary between normal and abnormal data.
- Neural Networks – Identifies complex patterns in structured datasets.
Limitations:
- Requires a large dataset with labeled anomalies.
- Cannot detect new types of anomalies outside the training data.
Unsupervised Learning: Works Without Labeled Data
Unsupervised learning models analyze raw data and detect unusual patterns without needing labeled examples.
Best for:
- Cybersecurity and network intrusion detection
- Detecting anomalies in industrial sensors
- Identifying rare patterns in financial transactions
Common models:
- Isolation Forest – Randomly splits data and isolates outliers.
- K-Means Clustering – Sorts data into groups and identifies points that don’t belong.
- DBSCAN (Density-Based Clustering) – Finds clusters in data and detects outliers.
Limitations:
- May misclassify normal variations as anomalies.
- Results can be inconsistent if the dataset changes over time.
Semi-Supervised Learning: Uses Only Normal Data
These models train on normal data and flag anything that deviates. They are useful when anomalies are too rare to label, but normal data is available.
Best for:
- Predictive maintenance in factories
- Credit card fraud detection with normal spending patterns
- Healthcare applications where anomalies are unpredictable
Common models:
- Autoencoders – Learn to recreate normal data and flag anything unusual.
- One-Class SVM – Defines a boundary around normal data and detects anything outside.
Limitations:
- Performance depends on how well the model learns the normal patterns.
- May struggle with slight variations in normal data.
Deep Learning for Complex Anomaly Detection
Deep learning models can detect anomalies in large and high-dimensional datasets.
Best for:
- Image and video anomaly detection
- Speech and audio-based anomaly detection
- High-frequency stock market fraud detection
Common models:
- Autoencoders – Compress and reconstruct normal data, highlighting differences.
- Generative Adversarial Networks (GANs) – Generate realistic fake data to help detect anomalies.
Limitations:
- Require large amounts of training data and computing power.
- Difficult to explain, making it unclear why an anomaly was detected.
Choosing the right anomaly detection machine learning algorithm depends on data availability, the complexity of the anomalies, and the need for real-time processing.
While advanced statistical techniques can be powerful, one of the most practical ways to detect anomalies is to ground your approach in business context.
 VP Data & Analytics, NOW Insurance
VP Data & Analytics, NOW Insurance
Real-World Applications of Anomaly Detection Machine Learning
Anomaly detection helps industries prevent fraud, system failures, and security threats. It’s widely used in finance, cybersecurity, healthcare, manufacturing, and retail.
Fraud Detection in Finance
For industries dealing with financial datasets, anomaly detection helps identify fraudulent transactions in banking and trading activities. Models flag sudden large withdrawals, purchases from unusual locations, and irregular transaction frequencies.
Cybersecurity Threat Detection
Machine learning anomaly detection helps security teams spot cyber threats like unauthorized logins, unusual network activity, and suspicious data access. Unlike static security rules, machine learning adapts to evolving threats.
Preventing Equipment Failures
Factories use sensor data to spot early signs of equipment failure. Predictive maintenance reduces downtime and improves efficiency. Object detection models assist in spotting defects on production lines, improving quality control.
Medical Anomaly Detection
Healthcare providers use image recognition to identify rare diseases, monitor irregular heart rates, and analyze medical images for signs of tumors. Faster and more accurate detection improves patient outcomes.
Retail Fraud and Inventory Management
Retailers use anomaly detection to flag unusual purchases, prevent fraud, and track inventory changes. It also helps detect bot traffic spikes that could indicate security risks. Businesses also rely on image classification vs. object detection models to detect counterfeit products.
Supply Chain and Logistics Monitoring
Logistics companies track shipments using machine learning to identify unexpected delays, route changes, or equipment failures, helping businesses respond faster and prevent disruptions.
With its ability to adapt and learn, anomaly detection machine learning examples continue to show how AI improves efficiency, security, and decision-making across industries.
Challenges and How to Overcome Them

Anomaly detection with machine learning is powerful but comes with challenges. False alarms, large datasets, and unclear results can make it harder to use. Here’s how to solve these problems.
Reducing False Alarms and Missed Anomalies
Some models mistake normal data for anomalies (false positives) or miss real issues (false negatives). This happens when models aren’t trained well, the wrong method is used, or anomalies look too much like normal patterns. To fix this, models need better tuning, more real-world data, and a mix of detection methods to improve accuracy.
Handling Large and Fast-Moving Data
Traditional models can be too slow for large datasets. Organizations handling large datasets, such as those for automatic speech recognition, need optimized models capable of processing real-time data efficiently. Using cloud-based services, optimizing machine learning models, and leveraging data annotation help process data faster and more efficiently.
Making Models Easier to Understand
Some AI models detect anomalies but don’t explain why, making them hard to trust. Deep learning models, in particular, work like “black boxes.” Tools like SHAP and LIME help show why a model flagged something. Choosing simpler models or adding confidence scores also makes results easier to interpret.
Keeping Up with Changing Data
Anomalies change over time, so a model trained on old data may miss new fraud or system failures. Regular retraining, adaptive learning, and performance monitoring help the model stay accurate as patterns shift.
Picking the Right Anomaly Detection Model
No single model works best for every dataset. Some methods handle specific anomaly types well but fail in others. Testing different models, choosing the right one for the task, and balancing accuracy with simplicity lead to better results.
Optimizing Data Annotation
One of the biggest challenges is data annotation pricing, as acquiring high-quality labeled data can be costly. This is where data annotation services help by providing scalable solutions to improve model accuracy.
Our current models can identify statistically significant anomalies with 94.7% accuracy across complex, multi-dimensional datasets, representing a significant leap in data intelligence capabilities.
 Senior Software Engineer, StudioLabs
Senior Software Engineer, StudioLabs
Best Tools and Libraries for Anomaly Detection Machine Learning
Choosing the right tools makes anomaly detection with machine learning faster and more accurate. Some are best for simple tasks, while others handle large-scale data.
Top Python Libraries
- Scikit-learn – Basic anomaly detection with easy-to-use models.
- PyOD – Wide range of outlier detection methods.
- TensorFlow/Keras – Deep learning for complex patterns (e.g., OCR deep learning).
Cloud-Based Solutions
- AWS Lookout for Metrics – Real-time anomaly detection.
- Google Cloud AI – Detects anomalies in streaming data.
- Azure Anomaly Detector – Best for IoT and business data.
Best for Large Datasets
- Apache Spark MLlib – Scales anomaly detection for big data.
- Dask-ML – Faster parallel computing for machine learning.
Next Steps
- Select the right anomaly detection approach based on your data.
- Experiment with different models to see which works best for your use case.
- Use scalable tools like PyOD, TensorFlow, or cloud-based AI for large datasets.
With the right approach, anomaly detection using machine learning helps businesses prevent fraud, secure systems, and improve efficiency. Many rely on a data annotation company for high-quality labels, ensuring accurate detection in complex datasets.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is anomaly detection in machine learning?
Anomaly detection in machine learning finds unusual data points that don’t match normal patterns. It helps detect fraud, system failures, and security threats by learning from past data and flagging outliers.
Which ML algorithm is best for anomaly detection?
The best algorithm for anomaly detection machine learning depends on the data. Isolation Forest is good for rare anomalies, Autoencoders handle complex patterns, One-Class SVM works with only normal data, and DBSCAN detects outliers in clusters. The right choice depends on data size and speed needs.
What are the three 3 basic approaches to anomaly detection?
Supervised learning uses labeled data to train models. Unsupervised learning finds anomalies without labels. Semi-supervised learning trains on normal data and flags anything unusual. The method depends on whether labeled data is available.
Which AI method is used for anomaly detection?
Machine learning models like Isolation Forest and SVM detect unusual patterns, while deep learning methods like Autoencoders and GANs handle complex data. Some systems use reinforcement learning to improve over time. The best method depends on data type and accuracy needs.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.