Lane Detection: How It Works in Autonomous Driving Systems

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Lane Detection in Computer Vision?
- How Does Lane Detection Work?
- Traditional Lane Detection Methods
- Deep Learning Approaches to Lane Detection
- Key Datasets for Computer Vision Lane Detection
- Lane Detection Challenges in Real-World Conditions
- How Data Annotation Defines Lane Detection System Performance
- About Label Your Data
- FAQ

TL;DR
- Lane detection in autonomous vehicles still struggles with real roads despite years of progress, and deep learning is the reason it got as far as it has.
- The gap between benchmark accuracy and real-world performance almost always traces back to training data, not model architecture.
- Annotating lane markings sounds straightforward until you're doing it at scale across night driving, rain, and construction zones.
Every autonomous vehicle and ADAS-equipped car depends on one foundational capability: knowing where the lane boundaries are. Lane detection, which covers the real-time identification of road lane markings from sensor input, underpins lane keeping, lane departure warnings, and highway autopilot.
Despite the progress, lane detection in adverse real-world conditions is still a hard problem, and training data quality remains the variable most machine learning teams underestimate.
This article walks you through how lane detection systems work, from classical computer vision pipelines to modern deep learning architectures, the datasets used to train them, and where these systems still break down.
What Is Lane Detection in Computer Vision?
Lane detection is the process of identifying and localizing lane boundaries on a road surface, typically from camera imagery or sensor data. It sits at the perception layer of any autonomous driving stack, feeding downstream planning and control modules the geometric information they need.
It helps to separate the terminology here:
- Lane line detection: identifying the physical painted markings on the road (solid white, dashed yellow, etc.)
- Lane keeping: using those detections to actively steer the vehicle
- Lane departure warning: alerting a driver who drifts across a boundary without signaling
All three rely on accurate, low-latency lane detection underneath.
How Does Lane Detection Work?
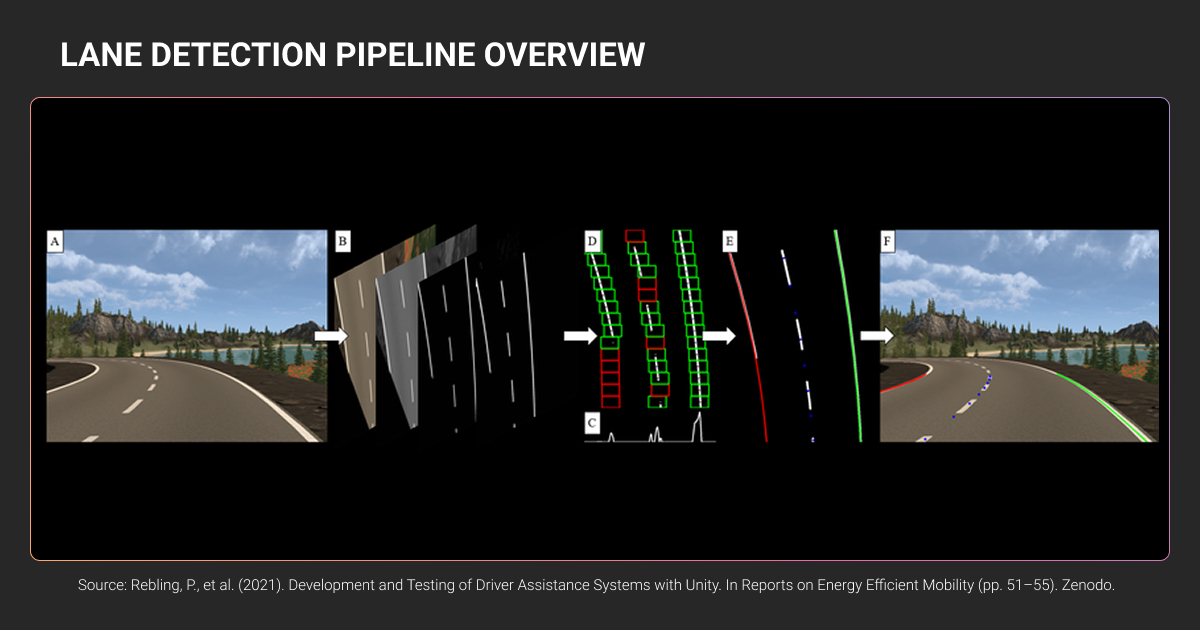
A lane detection system processes input from one or more forward-facing cameras, and sometimes a supplementary lane detection sensor like LiDAR for 3D spatial data.
The pipeline runs through three core stages:
- Preprocessing to normalize lighting and perspective
- Feature extraction to identify lane-like structures
- Post-processing to fit those features into coherent lane models
In classical systems, each stage uses hand-crafted machine learning algorithms.
In modern deep learning systems, a neural network handles feature extraction and lane modeling end-to-end, often processing hundreds of frames per second on embedded hardware. And the right data annotation platform determines how well it learns from the data.
Traditional Lane Detection Methods
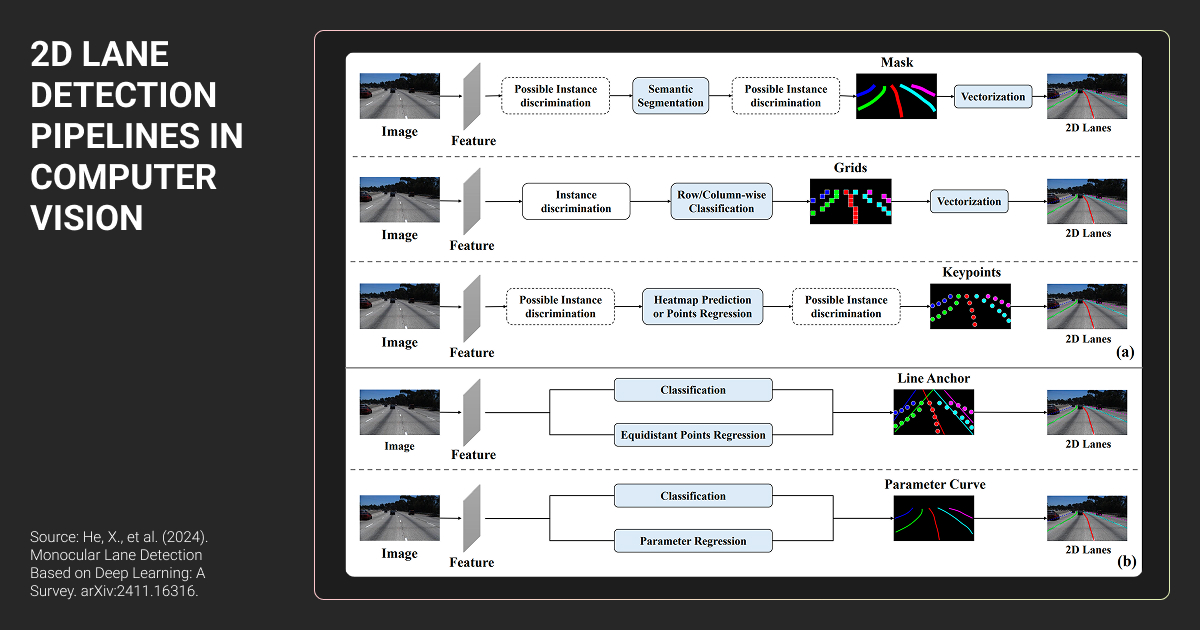
The classic computer vision pipeline
Before deep learning, road lane detection relied on a well-defined sequence of computer vision operations:
- Grayscale conversion: simplifies processing by reducing the image to a single channel
- Gaussian blur: suppresses noise before edge detection
- Canny edge detection: finds gradient boundaries in the image
- Region-of-interest mask: crops out sky and roadside clutter using a trapezoidal cutout
- Hough Line Transform: extracts line segments and groups them into left and right lane boundaries using slope-based logic
This pipeline is still the standard introductory computer vision lane detection project, and it works reliably on straight, well-marked highway segments in clear daylight. That’s also where its usefulness ends.
Why traditional lane detection falls short
The Hough Transform detects straight lines. Curved roads require polynomial fitting extensions that add complexity without solving the core generalization problem.
Every threshold in the pipeline needs manual tuning for each new environment, and what works on a sunny highway will fail on a rain-slicked urban street.
The real issue is that real roads throw multiple problems at once:
- Shadows cast false edges
- Glare from low sun angles saturates the image
- Faded markings produce weak gradients
- Vehicles occlude lane segments entirely
Traditional methods can handle one or two of these with enough engineering, but not all of them simultaneously, and not at scale across diverse driving conditions.
Lane markings are ambiguous or partially missing in poor lighting, shadows, road works, merges, or bad weather. These cases are very hard to label consistently, and they introduce noise that impacts model learning in a negative way.

 Managing Director, EIFGEOSOLUTIONS
Managing Director, EIFGEOSOLUTIONS
Deep Learning Approaches to Lane Detection
Segmentation-based methods
The first wave of deep learning lane detectors treated the task as a segmentation ML problem: classify every pixel as lane or background, then separate lane pixels into individual instances.
LaneNet pioneered this with a dual-branch architecture. One branch produces a binary lane/background mask. The other generates per-pixel embeddings that push same-lane pixels together while separating pixels from different lanes. Mean-shift clustering then groups them into distinct instances, handling a variable number of lanes without hardcoding a maximum count.
SCNN added slice-by-slice convolutions that propagate information across rows and columns within a feature map, essentially a form of message passing in four directions. This spatial structure captures the elongated, continuous geometry of lane markings in a way standard convolutions miss. It also introduced the CULane dataset, still the field's most demanding benchmark.
RESA improved on SCNN by aggregating spatial features in parallel using recurrent feature shifts at multiple strides, improving accuracy while reducing computation time.
Anchor-based methods
Rather than classifying every pixel, anchor-based lane detection algorithms define a set of predefined line proposals and learn to regress offsets that fit them to actual lane markings.
LaneATT uses over 2,700 straight-line anchors originating from image borders, pools features along each anchor, and applies self-attention across all proposals to gather global context. The result is competitive accuracy at roughly 250 frames per second, fast enough for any real-time deployment on embedded hardware.
CLRNet pushed this further with cross-layer refinement. It first localizes lanes using high-level semantic features, then refines predictions using low-level spatial detail. Its Line IoU loss treats each lane as a whole geometric unit rather than a collection of independent points, which improves accuracy on partial or occluded markings.
CLRNet achieved strong results across CULane, TuSimple, and LLAMAS simultaneously, and follow-up work like CLRerNet continues to build on it.
Parameter-based and curve-fitting methods
A cleaner alternative to pixel-level prediction is to represent lanes directly as mathematical curves.
PolyLaneNet regresses polynomial coefficients from a backbone network, representing each lane as a third-order polynomial plus a confidence score, running at over 100 frames per second with minimal post-processing.
BézierLaneNet addressed the curvature limitations of polynomial representations by fitting lanes as cubic Bézier curves defined by control points. With fewer than 10 million parameters, it showed that curve-fitting approaches can be both fast and geometrically flexible.
Ultra Fast Lane Detection took a different angle, reformulating lane detection as a row-based classification problem. For each predefined row in the image, the network selects which column grid cell the lane passes through.
This sparse output representation dramatically cuts computation, achieving over 300 frames per second with a ResNet-18 backbone while staying competitive on CULane. The v2 version extended this with hybrid row-and-column anchors and ordinal classification, improving CULane F1 by over six points.
Transformer-based approaches
Attention mechanisms address a core challenge that convolutional networks struggle with: lanes extend across the entire image and require long-range context to detect accurately, especially when portions are hidden.
LSTR was among the first transformer-based lane detection algorithms, predicting lanes as polynomial shapes with just 765K parameters at over 400 frames per second.
Laneformer tailored attention for lane geometry using separate row and column self-attention, plus object-aware attention that incorporates detected vehicles, which is particularly useful when a truck is blocking the lane marking ahead.
One survey covering over 40 monocular lane detection methods found that transformer-based architectures increasingly dominate accuracy leaderboards, while row-anchor methods continue to lead on raw inference speed.
Key Datasets for Computer Vision Lane Detection
The right lane detection dataset depends on what you’re trying to solve. Here’s how the four main benchmarks compare:
| Dataset | Size | Conditions | Annotation type | Best used for |
| TuSimple | ~6,400 frames | Clear weather, US highways | Polyline keypoints | Prototyping, quick baselines |
| CULane | 133,000+ frames | 9 categories incl. night, shadows, no-line | Polyline | Challenging real-world benchmarking |
| BDD100K | 100,000 frames | 6 weather types, day/night, urban/tunnel | Bézier curves, 9 lane categories | Generalization across environments |
| LLAMAS | 100,000+ frames | Highway, semi-auto from HD maps | Pixel-level segmentation | Large-scale pretraining |
TuSimple is nearly saturated by current models. Most teams use it for rapid prototyping rather than production benchmarking. CULane is where the real gaps show: top models still struggle on the "no line" and "night" categories.
Across all four machine learning datasets, the pattern is the same: annotation quality is the binding constraint.
No matter which data annotation tools your team uses, inconsistent polyline placement, mislabeled edge cases, or insufficient coverage of adverse conditions directly limits what the trained model can learn.
Lane Detection Challenges in Real-World Conditions

Environmental and sensor challenges
Standard benchmarks don't capture how hostile real roads can be. Rain introduces reflections that mimic lane markings. Fog degrades both raw image quality and the gradient features edge detectors rely on. Shadows from overpasses and roadside trees cast sharp boundaries that look like lane edges to a network that hasn't seen enough of them during training.
Construction zones are particularly problematic. They often combine faded original markings with temporary paint in conflicting colors, plus road surface transitions that alter how markings appear under different lighting. Most current lane detection datasets have very limited coverage of active construction scenarios.
The LanEvil benchmark tested 14 types of environmental corruption across multiple modern models and found consistent accuracy degradation across all of them, with shadow and dazzle conditions causing the worst failures.
This points to a data coverage problem as much as a model architecture problem.
Adversarial vulnerabilities
Physical-world attacks on lane detection systems are a real and documented concern.
Research presented at USENIX Security 2021 showed that printed patches resembling road grime, placed on the driving surface ahead, could fool a production lane-centering system with very high attack success rates in real driving conditions.
The attack works because models trained on clean road surfaces haven't learned to question unusual visual patterns near the bottom of the image.
Separate research showed that common roadside objects, placed deliberately, can trigger misdetections on autonomous vehicle lane tracking, which reinforces why teams rely on professional data annotation services to cover edge case diversity their training data needs.
In rain, glare, night driving, construction zones, or worn paint, even humans disagree on what the lane boundary should be. If you force annotators to guess, you end up encoding uncertainty as certainty — and the model learns inconsistent rules that show up as jitter, phantom lanes, or unstable tracking.
 Founder, Deep AI
Founder, Deep AI
How Data Annotation Defines Lane Detection System Performance

Every model covered in this article is only as reliable as its training annotations. Lane detection places specific demands that go beyond drawing rough bounding boxes:
- Polyline precision: keypoints need consistent placement across tens of thousands of frames, not approximate positioning
- Dashed marking continuity: annotators must follow the implied trajectory through gaps, not just mark visible segments
- Edge case judgment: faded markings, partial occlusion, and ambiguous intersections require trained annotators following clear protocols, not just labeled labor
Annotation inconsistency compounds at scale. For ML teams building lane detection systems targeting real-world deployment, the training data strategy is inseparable from the model strategy.
This is why getting data annotation right early matters more than most teams expect.
For such cases, a data annotation company like Label Your Data provides polyline and pixel-level lane annotation at scale, with consistent protocols across annotators and targeted edge case coverage without sacrificing throughput.
Better training data is the most direct path from benchmark accuracy to road accuracy.
See our data annotation pricing to understand what scaling edge case coverage actually costs.
About Label Your Data
If you choose to delegate data labeling for lane detection systems, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the lane detection system in a car?
It combines a forward-facing camera behind the windshield, a processing unit running a lane detection algorithm, and integration with ADAS features like lane departure warning or lane-keeping assist.
What does lane detection do?
It identifies where lane boundaries are relative to the vehicle, enabling lane departure warning, lane-keeping assist, and full lane centering in more advanced systems.
How does a lane detection algorithm work?
A lane detection algorithm takes a camera frame as input and runs it through a series of operations to identify lane boundaries. Classical algorithms use edge detection and line-fitting techniques like the Hough Transform.
Deep learning algorithms use a trained neural network that learns to recognize lane markings directly from data, outputting results as pixel masks, curve parameters, or classified row-column positions depending on the approach.
How does a car know where the lines are?
The forward camera captures the road ahead, and an onboard neural network identifies lane markings by recognizing their shape, color, and position, processing dozens of frames every second with centimeter-level geometric precision.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.