Knowledge Distillation: Teacher-Student Loss Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Knowledge Distillation Solves and Why It’s Used
- How Knowledge Distillation Works
- Types of Knowledge Distillation Techniques
- Training a Student Model with Knowledge Distillation
- When to Use Knowledge Distillation (and When Not To)
- Tools and Libraries for Knowledge Distillation
- About Label Your Data
- FAQ

TL;DR
- Knowledge distillation compresses large, high-performing models (teachers) into smaller, faster ones (students) while maintaining accuracy.
- Instead of just learning from labels, student models learn from the teacher’s output distributions, called soft targets.
- You can distill logits, intermediate features, or attention patterns, depending on your architecture and goals.
- It’s ideal for edge deployment and low-latency applications where compute is tight but you still need solid performance.
- Libraries like PyTorch, HuggingFace Transformers, and models like DistilBERT make distillation practical and production-ready.
What Knowledge Distillation Solves and Why It’s Used
High-performing models aren’t always usable in production. They’re too big, too slow, and too expensive. Knowledge distillation (KD) offers a way to keep the accuracy without the overhead.
At its core, knowledge distillation is about teaching a compact model to behave like a larger one. Instead of training the small model directly on ground-truth labels, we guide it using the outputs of a large, well-trained model, the teacher.
The student learns from the teacher’s “knowledge,” often in the form of softened probability distributions over classes derived from the teacher’s logits. This approach gives you the best of both worlds in the performance of heavyweight types of LLMs, without the resource cost of running one.
Whether you’re optimizing for mobile, embedded systems, or reducing inference time in batch processing, knowledge distillation of large language models helps preserve model accuracy while shrinking size, latency, and power consumption.
How Knowledge Distillation Works
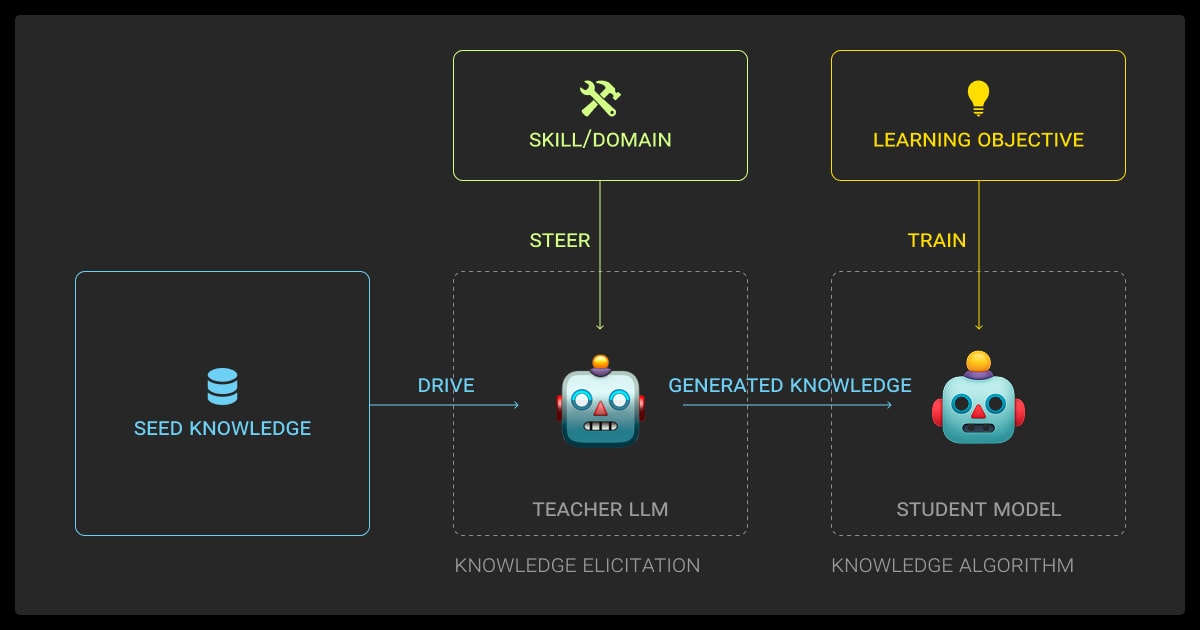
Now let’s look at how LLM knowledge distillation works in practice.
Teacher-Student Setup
You start with a large teacher model like BERT, a ResNet-152, or a custom LLM, one that someone’s trained on your task and is doing well.
The student is a smaller network, often with fewer layers or reduced width. The student learns from how the teacher distributes confidence across all classes, capturing nuanced relationships even when predictions are incorrect.
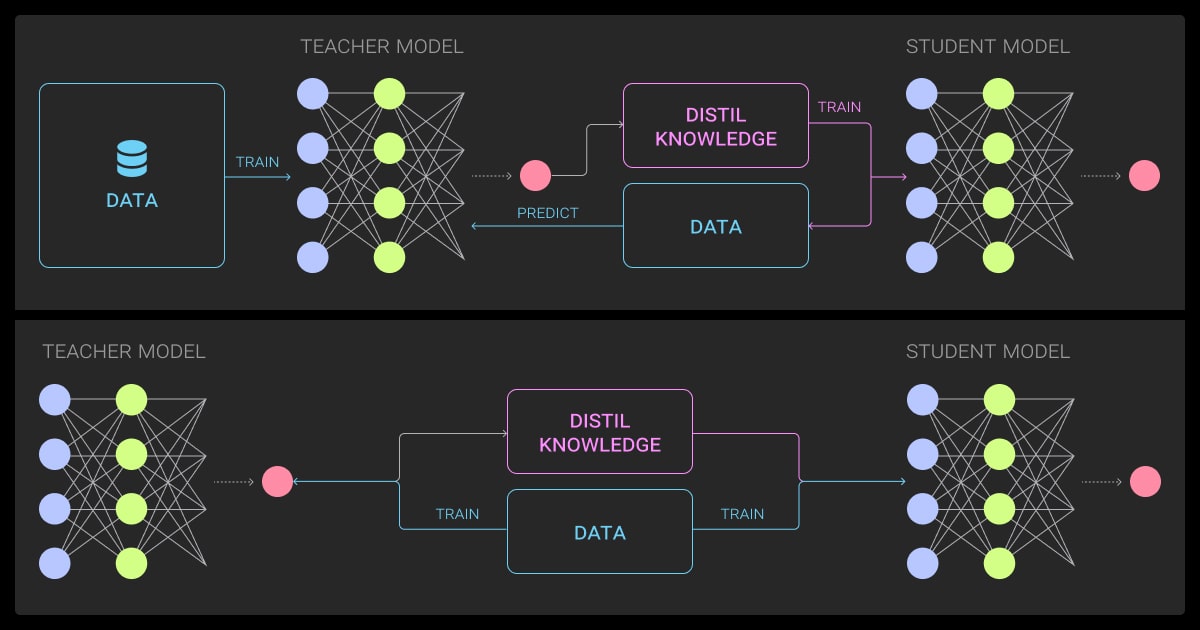
You’ll then start training the student model and distilling the knowledge in a neural network.
Soft Targets and Temperature Scaling
Raw logits (pre-softmax outputs) from the teacher are passed through a softmax function, often with a temperature parameter T > 1.
A higher temperature softens the output, spreading probability mass across more classes, which is crucial. Instead of just telling the student “class A is right,” we’re saying, “class A is 70% likely, B is 20%, and C is 10%.” That extra information helps the student understand class relationships and generalize better.
The formula looks like this:
softmax(z_i / T) = exp(z_i / T) / ∑_j exp(z_j / T)Distillation Loss Function
Distillation loss typically combines two components:
- Hard loss: Cross-entropy between student predictions and the actual ground-truth labels
- Soft loss: KL divergence between the student’s softened outputs and the teacher’s softened outputs
The total loss looks like:
L_total = α * CE(y_true, y_student) + β * KL(p_teacher^T || p_student^T)Where α and β balance the contribution of each loss term.
Note: KL divergence should be computed between the teacher and student soft targets, both obtained by applying the same temperature T to their logits.
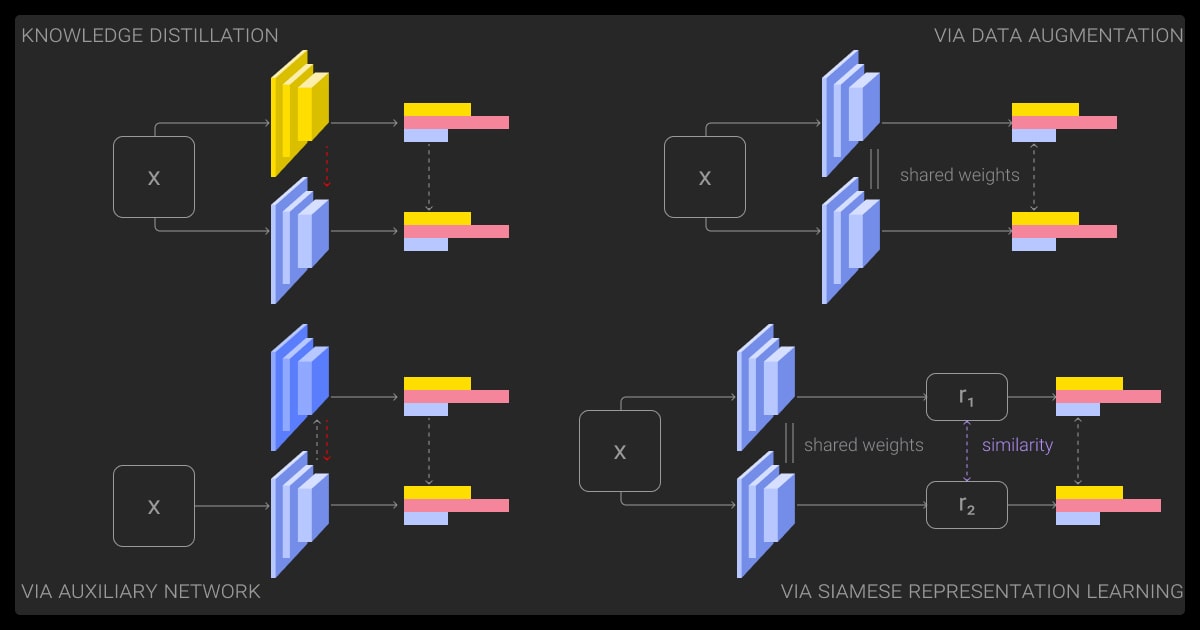
Types of Knowledge Distillation Techniques
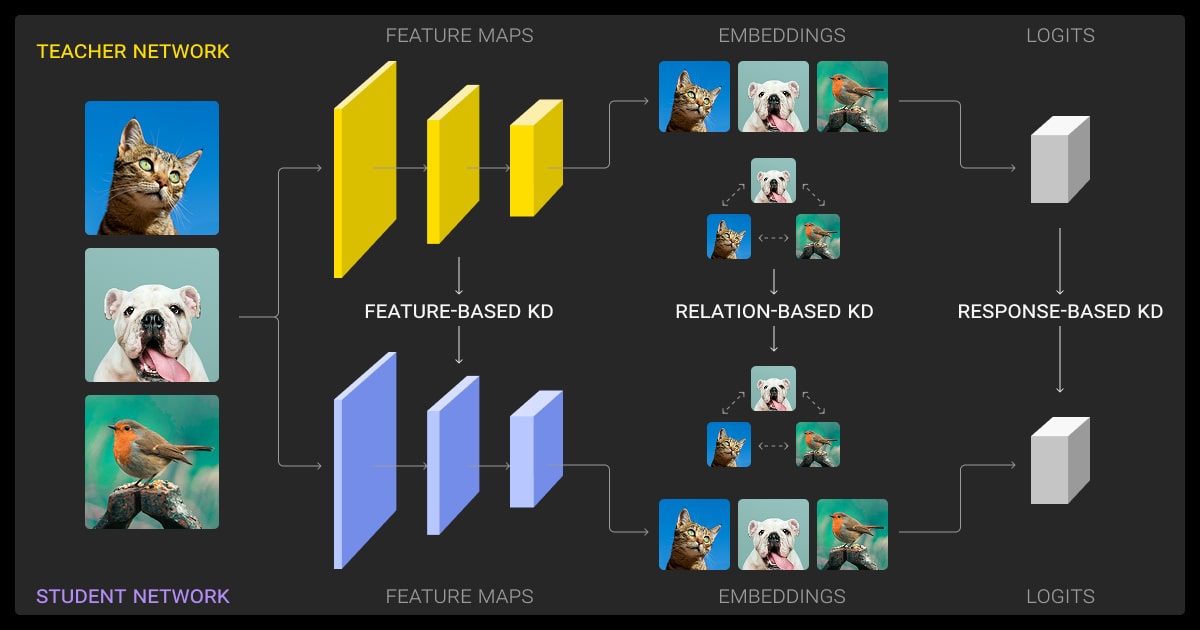
There are a few methods you can use for dynamic temperature knowledge distillation.
Response-Based Distillation
This is the classic knowledge distillation approach, where the student model mimics the teacher’s output distribution. It’s simple, often effective, and works especially well in classification problems.
Professional teams often use this method when they deploy models in production, especially in image recognition or NLP classification tasks.
Feature-Based Distillation
Here, you go deeper with your knowledge distillation LLM. Instead of just copying outputs, the student mimics intermediate representations, activations from specific layers.
You may add loss terms to align feature maps, project them to the same size, or use hint layers, often supervised with L2 or cosine similarity losses. It’s particularly useful in CNNs and transformer encoders where spatial or temporal features carry rich information.
Attention-Based or Relational Knowledge Distillation
Transformer models, like BERT or GPT, use attention heads to distribute focus across input tokens. Attention-based KD encourages the student to replicate these attention maps.
In more advanced setups, you might even train the student to capture the relationships between layers or between tokens (relational KD). DistilBERT used this approach effectively to achieve strong performance with fewer parameters.
Other emerging techniques include:
- Multi-teacher distillation (where a student learns from multiple teachers)
- Self-distillation (where a model distills knowledge into itself during training)
- Online distillation (where teacher and student are trained simultaneously)
These are especially useful in continual learning or distributed training setups.
One of the most effective tweaks we've made is matching hidden representations between teacher and student, not just logits. Mid-layer features gave the best results, since early layers are too generic and final ones too task-specific. We used cosine similarity loss and aligned dimensionality with linear layers. Starting this loss after a few epochs helped avoid early instability. This improved student accuracy by ~5% in image classification.

 Marketing Content Manager, Techstack
Marketing Content Manager, Techstack
Training a Student Model with Knowledge Distillation
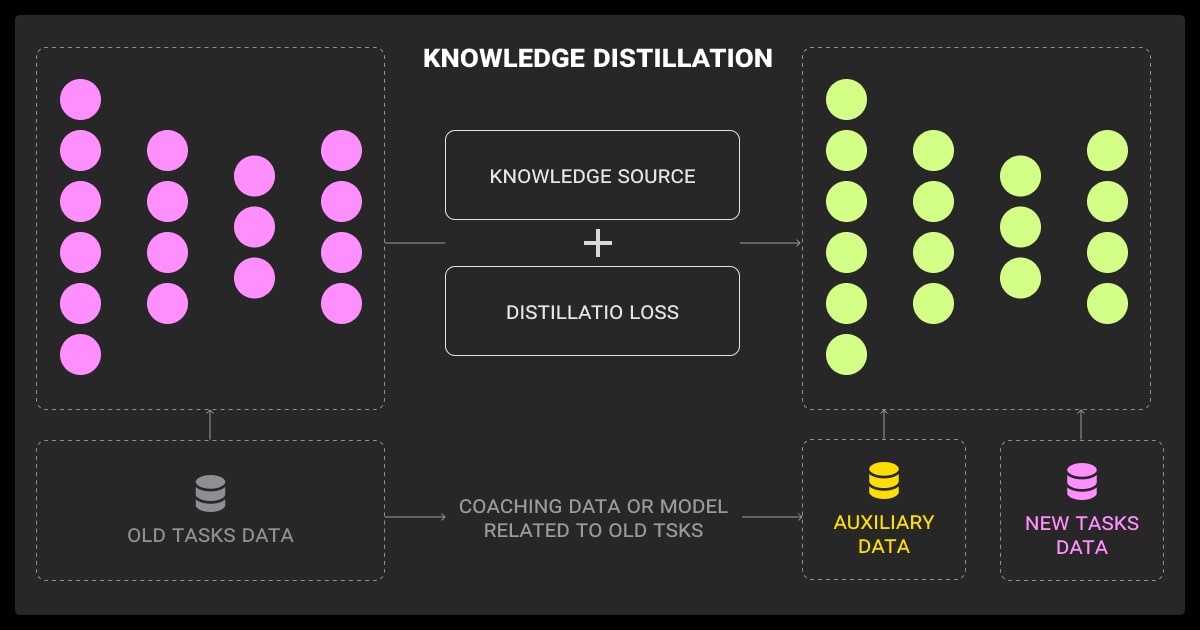
Now let’s look at how this will work in the real world.
Step-by-Step Workflow
Let’s say you’re working on a text classification problem. Here’s how you might structure it:
- Train the teacher: Fine-tune a BERT model or ResNet on your task
- Log teacher outputs: Capture logits or intermediate activations
- Design the student: Build a smaller model, e.g., a distilled version with fewer layers
- Train with KD loss: Combine soft and hard losses to guide the student
- Evaluate: Compare accuracy, size, and latency against the original
If you need help in this area, you can hire reliable and secure LLM fine-tuning services.
Choosing Loss Weights and Temperature
There’s no golden rule here, but some common heuristics help:
- Set the temperature T between 2 and 5 for best gradient flow
- Start with α = 0.5 and β = 0.5 and tune based on validation performance
- If the dataset is noisy, weigh the soft loss more heavily
You’ll need to experiment a bit depending on your domain. In high-noise settings, soft targets tend to help smooth out the training process.
Evaluation
You’re usually balancing three axes:
- Accuracy: F1 score, BLEU, ROC-AUC, etc.
- Size: Model size in MBs or parameter count
- Latency: Inference time on CPU/GPU/edge device, or total FLOPs
It’s not uncommon to lose 1-2% absolute accuracy while cutting inference time in half. That’s often a trade-off worth making in production environments.
Data augmentation can further improve KD performance by exposing both teacher and student models to a wider range of inputs, enhancing generalization.
We saw strong results by combining two techniques: (1) annealing temperature from T=5 to T=1 across epochs, and (2) adjusting loss weights based on the teacher’s confidence. If softmax confidence < 0.5, we upweighted the ground-truth loss. If high, we leaned more on soft targets. This made the student more robust and cut convergence time by 25% while boosting accuracy by 1.6%.
 Founder & Principal Software Architect, Cirrus Bridge
Founder & Principal Software Architect, Cirrus Bridge
When to Use Knowledge Distillation (and When Not To)
There’s no one-size-fits-all solution in machine learning, so you need to know when to employ knowledge distillation.
Ideal Scenarios
Use knowledge distillation when:
- You need to deploy on mobile or IoT devices
- Latency is critical, for example, real-time systems, chatbots)
- You want to save energy or reduce infrastructure costs
- You need faster experimentation cycles with lighter models
It’s also useful when you’ve got a killer teacher model but don’t want to pay its deployment tax.
Limitations
Knowledge distillation doesn’t always work out of the box:
- If the student is too small or underparameterized, it may not absorb meaningful structure from the teacher
- If the teacher is overly confident or overfits, its soft targets might hurt rather than help
- In very low-data scenarios, the student might not generalize well (although KD can sometimes help mitigate overfitting by providing richer supervision than hard labels)
Be aware that students may also inherit biases or mistakes from the teacher, especially if it’s overfit or miscalibrated. This is a common risk when using distillation without critically evaluating the teacher’s performance across domains.
Always validate performance, and don’t assume a smaller model trained via knowledge distillation will automatically outperform a baseline trained on hard labels.
As with all projects of this nature, the quality of your machine learning datasets matter. You may need to hire data collection services to gather more high-quality data or augment what you’ve got for proper LLM fine tuning of your machine learning algorithm.
You also have to stay on top of data annotation or risk a poorly performing model. If you don’t have the team to devote to this, you can hire data annotation services. This might increase data annotation pricing a little, but you save time and gain accuracy, making it a worthwhile investment.
Just be sure to find a data annotation company with experience in model distillation, and, if possible, multimodal machine learning.
We replaced final-layer-only distillation with layerwise distillation and temperature annealing. Aligning intermediate features preserved both low-level signals and task intent, which improved QA benchmark accuracy by 2.6% and reduced training time by 13%. Early layers hold rich signals — don’t lose them by distilling only from logits.
 Co-Founder, BotGauge
Co-Founder, BotGauge
Tools and Libraries for Knowledge Distillation
Let’s go over some useful resources.
HuggingFace Tools
HuggingFace’s transformers library offers distillation recipes and prebuilt student models like DistilBERT and TinyBERT. Their Trainer API supports custom loss functions, and you can plug in your own teacher-student framework.
Check out their distillation post for examples with translation, classification, and summarization tasks.
Custom Loss in PyTorch
If you want to roll your own setup, PyTorch gives you full control. Just compute the logits from teacher and student, apply temperature scaling, and plug in your own combined loss function. The official PyTorch tutorial walks through the basics.
Distilled Models
These are all distilled versions of transformer models optimized for speed:
- DistilBERT: 40% smaller, 60% faster than BERT-base, 97% accuracy
- TinyBERT: Adds feature-level distillation for even smaller footprint
- MobileBERT: Optimized for mobile CPUs with architecture tweaks
- DistilWhisper: A lightweight version of OpenAI’s Whisper for speech tasks
All are production-ready, with pretrained checkpoints available on HuggingFace Hub.For real-world deployment, you can use ONNX to export distilled models for edge devices or TensorRT to optimize inference speed on NVIDIA hardware. These tools help bring compact models into production with minimal overhead.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is knowledge distillation?
It’s a model compression method, where a smaller student model learns to replicate the behavior of a larger, pretrained teacher. The goal is to reduce size and latency while maintaining as much accuracy as possible.
What is the basic knowledge of distillation?
At its simplest, it involves softening the output of the teacher using temperature scaling and training the student to match those outputs, often combined with ground-truth supervision.
What is LLM knowledge distillation?
In large language models (LLMs), knowledge distillation helps reduce model size for applications like chatbots or summarizers. You can distill tasks like QA, classification, or summarization into smaller transformer-based models.
What is distilling knowledge?
Distilling knowledge means extracting the essential behavior of a model, how it makes decisions, and transferring that to a smaller, more efficient model.
How to apply knowledge distillation?
- Train a strong teacher model (like BERT or ResNet) on your dataset until it performs well.
- Log the teacher’s outputs, typically logits or soft probabilities, for each input.
- Build a smaller student model with fewer layers or hidden units.
- Train the student using two losses: KL divergence on soft targets and cross-entropy on true labels.
- Set a temperature (usually 2-5) to soften logits and tune loss weights (e.g., α = 0.5, β = 0.5) for best results.
What is the difference between knowledge transfer and distillation?
Knowledge transfer is broader; it might involve transfer learning or fine-tuning a pretrained model. Distillation is a specific form of transfer where a small model learns directly from the output distributions of a larger one.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.