Survey Data Collection: Methods for ML Accuracy

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Survey data is valuable not just as input features, but also as ground truth for supervised learning tasks.
- Structuring surveys correctly ensures cleaner labels and more robust training data.
- There are different survey collection methods, each with their own tradeoffs in quality, cost, and scalability.
- Poorly designed survey questions introduce bias, leakage, and noise. You can fix these, but it’s better to prevent them.
- Outsourcing survey collection and labeling can improve training speed, consistency, and cross-demographic representation.
When Survey Data Collection Makes Sense in Machine Learning

Surveys are one of the most common ways to collect structured data.
In fact, 85% of researchers say they use online surveys regularly, making them the most-used quantitative method. In ML, surveys help capture what a machine learning algorithm can’t infer on its own (think user intent, sentiment, or preferences).
You might have behavioral logs or clickstream data, but that won’t tell you why someone churned or how satisfied they felt. That’s where human input comes in.
The challenge? Turning subjective responses into structured formats suitable for machine learning and training data.
Survey Data as Input vs. Ground Truth
In ML pipelines, survey data generally shows up in one of two ways:
As Ground Truth Labels
Here we use surveys for supervised labels. You’ll focus on classification or regression tasks based on human-annotated outcomes.
Say you’re training a model to predict employee burnout based on workplace metrics, and you need labeled examples. You can source these from self-reported surveys asking questions like, “How often do you feel overwhelmed at work?” scored on a Likert scale.
As Features
Your responses can also provide covariates, like demographics, opinions, and preferences, that influence behavior.
An example is recommendation systems where you rate how much you enjoy a particular recipe. This becomes more useful in tailoring a menu because you can’t deduce this purely from an order history.
Use Cases Where Survey Data Performs Best
Survey data shines when subjective judgment, intent, or emotion plays a critical role in model outcomes. For example:
Human Feedback Loops
Reinforcement learning from human feedback (RLHF) uses survey-like responses to guide LLM fine tuning. Preference labels like, “Did A or B sound more helpful?” teach LLMs to rank better responses.
Psychographic Modeling
Sentiment analysis, brand affinity modeling, and political leaning estimators all benefit from structured survey inputs that reflect beliefs or mood.
Behavioral Prediction
When paired with behavioral logs, survey responses can improve models for churn, satisfaction, or lifetime value. The more examples you can provide, the better your model can pick up on patterns.
Structuring Survey Data for ML Readiness
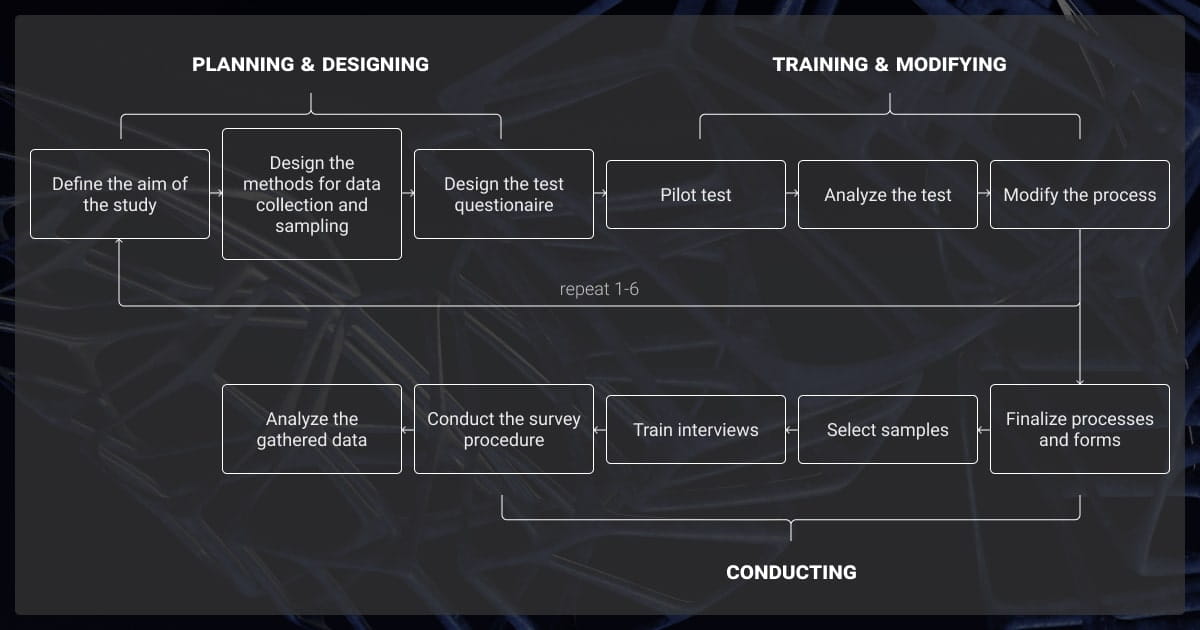
Collecting the data is just the first step. You also need to structure it properly so it’s ML-grade and not a noisy liability.
Designing for Label Consistency
One of the biggest pitfalls in survey-driven ML is inconsistency in how respondents interpret and answer questions:
Forced-choice vs. open-ended
Forced-choice formats (e.g., “Select one”) usually train better. Open-ended responses introduce NLP variability and labeling ambiguity, which can inflate noise unless manually annotated.
Use scales to normalize
Subjective answers like, “How satisfied are you?” benefit from standardization. Five- or seven-point scales can reduce interpretation variance compared to open text fields.
Avoid skip logic confusion
Dynamic survey flows can introduce nulls or inconsistencies. If question B depends on A, and you skip or misunderstand A, B’s response is meaningless.
Sampling and Response Volume for ML Training
How many responses you need depends heavily on your task complexity.
Binary classification with clear labels may only need a few thousand samples, they’re well-balanced. By contrast, multi-class models, especially those with subtle class boundaries, require more volume and diversity.
You need to:
- Balance your distribution: If 90% of your ground truth comes from one class, your model will be unbalanced.
- Capture rare classes: Real-world performance depends on long-tail data. Use oversampling or targeted surveys to fill gaps.
Preprocessing Survey Data into ML Features
Once you collect the responses, you need to turn them into model-friendly formats in their own workflow:
- Encoding: Use one-hot encoding for categorical variables; ordinal encoding works better for ranked data (e.g., Likert scales).
- Handling missing values: Common options include mean imputation, model-based imputation, or deletion (if MCAR).
For example, a typical survey-to-CSV pipeline might involve raw JSON exports from Typeform, transformation via Pandas, and column normalization before model training.
We start by intentionally biasing the first survey draft, then test it on a diverse group to refine neutrality. It leads to more human, thoughtful responses.

 CEO & Founder, Listening.com
CEO & Founder, Listening.com
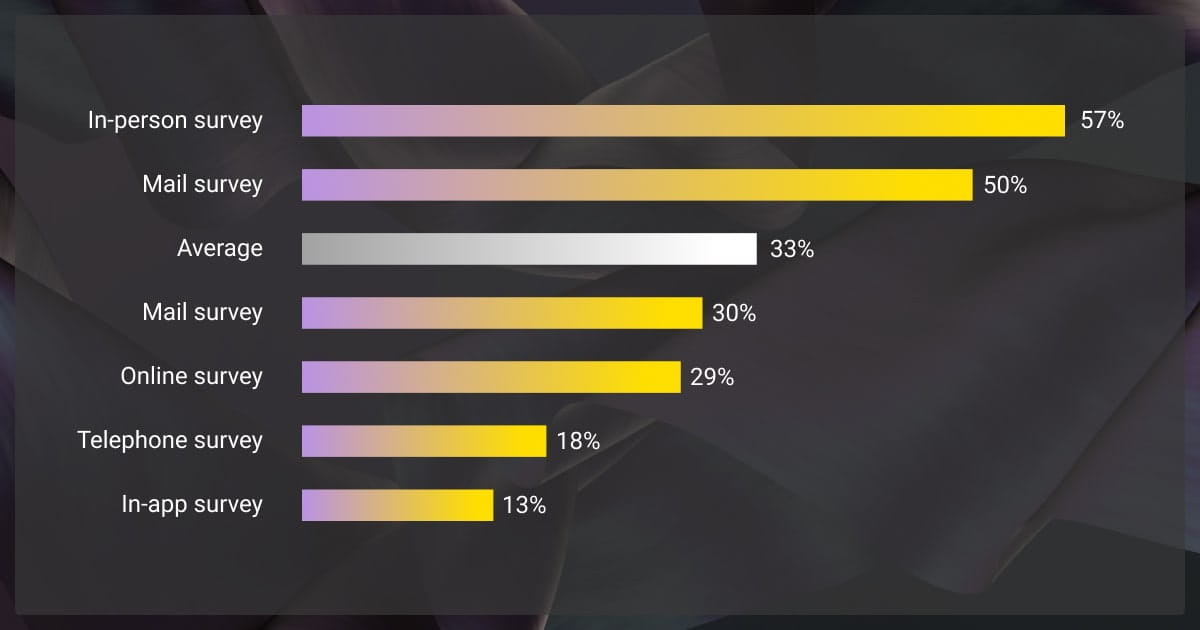
Survey Data Collection Methods Compared for ML Quality

How much time do you spend designing a survey? Most companies focus on this step, and rely on automated data collection. They don’t give much thought to other survey data collection methods, which can be a mistake.
Self-Administered Surveys (Online, In-App, Email)
Online survey data collection is easy to scale because you can use AI data collection. It’s best for low-friction feedback, and you can imbed it into digital experiences like apps, SaaS, and websites.
You have to watch out for respondents who don’t give thoughtful answers, but rather “good enough” ones, or satisfying. Another issue is where respondents click the same response across the whole survey, or straight-lining. Finally, drop-off occurs when your survey is longer than five to seven questions. Respondents lose interest.
You can fix these issues by:
- Randomizing the question order
- Inserting attention checks like “Select option 3 for this question”
- Make it possible to complete the survey in under 90 seconds.
Interview-Based Surveys (Phone or In-Person)
Does your task require specific domain knowledge, deeper judgment or complex data annotation? Then you’re better off using an interview by phone or in-person.
You’ll get high-quality, nuanced labeling, which is better for edge-case or interpretive tasks. The downside is that this type of data collection survey is time-consuming and expensive. It doesn’t work for high-volume labeling.
Pro tip: Convert qualitative responses into labels through coding guides or human annotation platforms. This hybrid approach often yields high-accuracy training sets.
Not sure if you can get this right? Speak to an expert data annotation company to handle the task for you.
Panel-Based and Crowdsourced Collection
Do you need machine learning datasets that incorporate demographic diversity or the opinion of niche audiences?
Say, for example, you’re training an image recognition application, so you need people of different ethnicities. Then you might want to use the panel-based survey method of data collection.
Panel vendors let you sample across age, geography, profession, or psychographics. Crowdsourcing platforms or sites like MTurk and Prolific give you rapid, on-demand labeling. Which is usually cheaper, but can be more prone to noise.
The key to making this technique work is annotator agreement. When multiple raters label the same item, you can calculate inter-rater reliability by using techniques like Cohen’s kappa. You can then use that signal for label confidence weighting.
Online panels are my go-to for fast, high-quality data. They offer diverse samples, built-in quality controls, and scalability from hundreds to tens of thousands of responses.
 CMO, G-BRIS
CMO, G-BRIS
Common Data Failures and How to Avoid Them
Survey-driven ML projects fail more often from data design than model architecture. Here’s what to watch out for.
Noise from Poorly Designed Questions
Poor survey design can leak labels or mislead models. For example, a churn prediction survey that asks “Do you think you’ll cancel soon?” directly injects the label into the features.
You can fix this by:
- Adding control questions to validate engagement
- Define terms clearly to reduce interpretation variance (e.g., “By ‘satisfaction,’ we mean…”)
- Run pilot test surveys with a small sample before launch
Incomplete or Imbalanced Responses
People don’t miss survey responses randomly. They might skip hard questions or fail to answer when they don’t understand your framing. The problem is that supervised models need full feature vectors. Skipped responses create unstructured nulls.
You can come to these by starting with the right survey tools for data collection and then applying these techniques:
- Imputation: Use median, KNN, or MICE (Multiple Imputation by Chained Equations)
- Oversampling: Duplicate rare classes with variation
- Synthetic augmentation: Generate new samples via SMOTE or synthetic surveys
Bias in Survey Data Collection
- Demographic skew, annotator bias, and anchoring effects
- Detection and mitigation strategies
- When rebalancing does (and doesn’t) work
Human-generated data carries human biases—sometimes subtle, sometimes systemic. The risks include:
- Demographic skew, for example, the over-representation of younger users
- Labeler bias like, “this sounds angry to me, so it must be negative”
- Anchoring where early questions influence later ones
To detect this, survey data collection runs demographic audits of the responses. They also check the label distribution across population slices.
To fix these issues, you can reweight during training or rebalance via sampling or synthetic data generation. In some cases, you need to head back to the drawing board and collect more diverse data.
Incentivizing quality over quantity improved our survey data by 40%. We offer tiered rewards based on detail and consistency to encourage thoughtful answers.
 CEO, FATJOE
CEO, FATJOE
When to Outsource Survey Data Collection
Sometimes it makes more sense to bring in outside help. While software is helpful, you may need to call in the pros when the collection stalls due to bottlenecks.
Signs You Need External Support
- You need fast, labeled responses across demographics
- You’re struggling to design unbiased, ML-ready instruments
- Your team lacks resources to QA large-scale inputs
- You’re building ML tools, not survey data collection software
What to Look for in a Vendor
Not all survey vendors are equal—especially when ML is the end goal.
You should look for:
- Experience in ML-specific use cases (e.g., annotating for NLP or CV tasks)
- Transparent workflows: who collects, who cleans, who labels
- Proven ability to deliver across formats—text, image, multi-label, scale-based
How Survey Data Collection Outsourcing Improves Training Efficiency
Outsourcing survey data collection saves your team time. You get well-designed surveys and clean, ready-to-use labels. No need to spend weeks creating surveys or fixing messy data.
An experienced vendor helps you collect better data faster. They structure questions clearly and provide balanced datasets. This means fewer training delays and higher-quality labels from the start.
If you're looking for external support, we at Label Your Data specialize in survey data collection and annotation. With our data annotation services, you can make human-labeled data fit seamlessly into your ML development lifecycle. Try our cost calculator for your personalized estimate for data annotation pricing.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the data collection method of a survey?
A survey data collection method is how you gather responses from participants, such as online forms, phone calls, or in-person interviews. The method you choose depends on your goals, budget, and audience.
What is the data collected in a survey?
You usually collect subjective data like opinions, demographic information, and self-reported behaviors. You can do this by using structured forms like scales or unstructured with open-ended answers.
What are the 5 methods of data collection?
The five methods of data collection are: online/self-administered surveys, phone interviews, in-person interviews, mail surveys, and crowdsourcing or panel services.
What are the four common collection methods of surveys?
You’re looking at: self-administered through online or on-app, interview based via phone or in-person, panel recruitment, crowdsourced platforms.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.