Auto Annotation Tool: Best Options for Automated Workflows

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What’s an Auto Annotation Tool and Where It Helps
- Comparing Automatic Annotation Tools Side-by-Side
- Top 10 Auto Annotation Tools : Pros & Cons
- Where Automation Breaks in Annotation Workflows
- Semi-Automated Solutions (aka Humans-in-the-Loop)
- How to Choose the Best Auto Annotation Tool for Your ML Project
- About Label Your Data
- FAQ

TL;DR
- Auto annotation tools speed up dataset prep by pre-labeling or suggesting annotations, but they can’t fully replace human review.
- They work best with repeatable patterns, clear ontologies, and large volumes of image or video data.
- Failures show up with small objects, ambiguous classes, and domain shift – making QA loops and human-in-the-loop review essential.
- Tools vary: open-source options give control; enterprise SaaS focus on compliance and scale; hybrid options balance speed with ease of use.
- A pilot project is the safest way to choose: define an ontology, use a gold dataset, run automation, then measure correction rate and time-to-first-model.
What’s an Auto Annotation Tool and Where It Helps
An auto annotation tool uses AI to label data faster, but human review is still required to make the results trustworthy.
These tools fit into data annotation workflows in three main ways:
- Pre-labeling: a model creates draft labels for a dataset, humans correct them
- Smart suggestions: real-time helpers like boundary snapping or frame interpolation
- Full automation: only works for simple, repetitive tasks with little ambiguity
They work best on large machine learning datasets with clear, repeatable classes such as vehicles, people, or scans with established diagnostic criteria. In these cases, automated data annotation cuts the time of the first pass and reduces manual workload. An automatic image annotation tool can pre-label large datasets, but still requires QA for edge cases.
Human review remains essential for edge cases, ambiguous labels, and safety-critical domains like healthcare or autonomous driving. Models also break down with domain shift or small objects, making human-in-the-loop quality control non-negotiable.
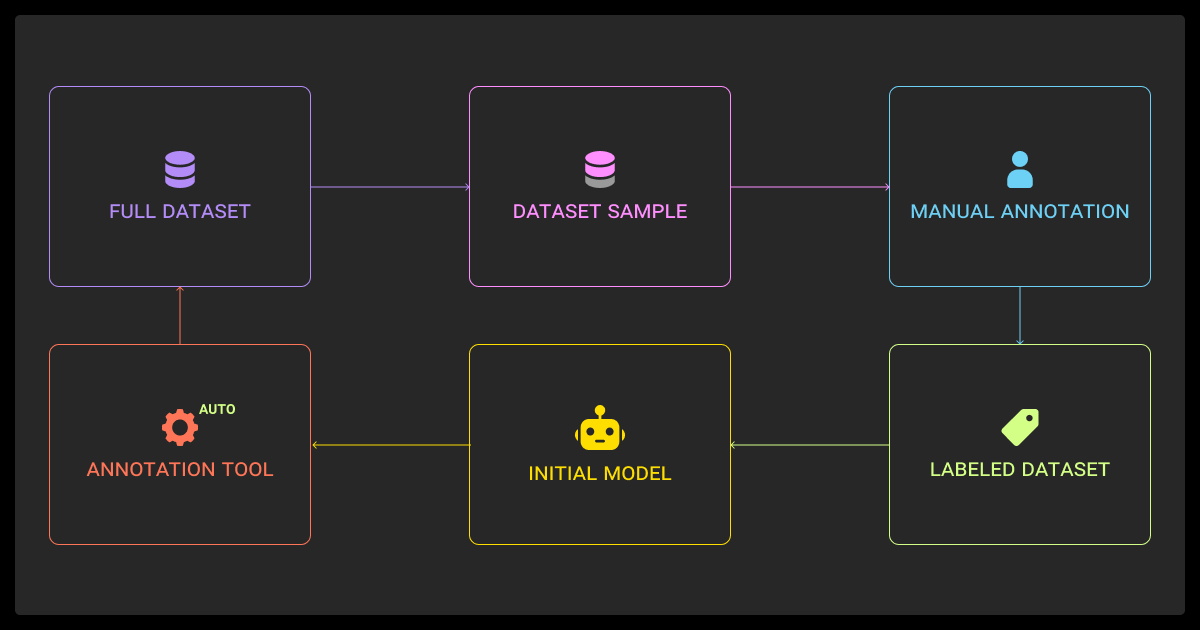
Comparing Automatic Annotation Tools Side-by-Side
Choosing the right one among the best auto annotation & labeling tools depends on the workflow you want to support. This table is a practical reference you can use to align with your team before testing tools:
| Tool | Focus | Modalities | Auto Features | Best For |
| Roboflow | Hybrid SaaS | Images, Video | Auto Label (SAM, Grounding DINO), Label Assist | Teams building end-to-end CV pipelines quickly |
| CVAT | Open-source | Images, Video, 3D | BYOM, SAM tracking, wide format support | Research and engineering-led teams needing control |
| V7 Darwin | Enterprise SaaS | Images, Video, DICOM | Auto-Annotate, video interpolation, model-in-loop | Regulated industries needing precision |
| Label Studio | Open-source | Multi-modal | Pre-labeling, active learning, ML backend API | Research and custom ML pipelines |
| Kili Technology | Enterprise SaaS | Images, Text, PDFs, Geospatial | Model-based automation, AutoML, LLM evaluation | Enterprise teams with complex verticals |
| SuperAnnotate | Enterprise SaaS | Images, Video, Text | AI-assisted editor, OCR automation, workflow orchestration | Large-scale enterprise data ops |
| Ultralytics | Open-source | Images, Video | Auto Label with YOLO + SAM (CLI) | Engineers comfortable with code and script-based workflows |
| Encord | Enterprise SaaS | Images, Video | Active learning, model-in-loop, QA metrics | Scaling teams needing compliance and governance |
| urAI | Niche SaaS | Text, PDFs | Auto entity annotation, OCR text tagging | NLP-focused teams |
| Mask R-CNN (open-source) | Open-source | Images | Script-based instance segmentation | Research and small teams with technical expertise |
Auto data annotation tools fall into three main categories: open-source for flexibility and control, enterprise SaaS for scale and compliance, and hybrid platforms for speed and convenience. The best choice depends on your data type, the maturity of your pipeline, and how much control you want over automation versus human review.
Top 10 Auto Annotation Tools : Pros & Cons
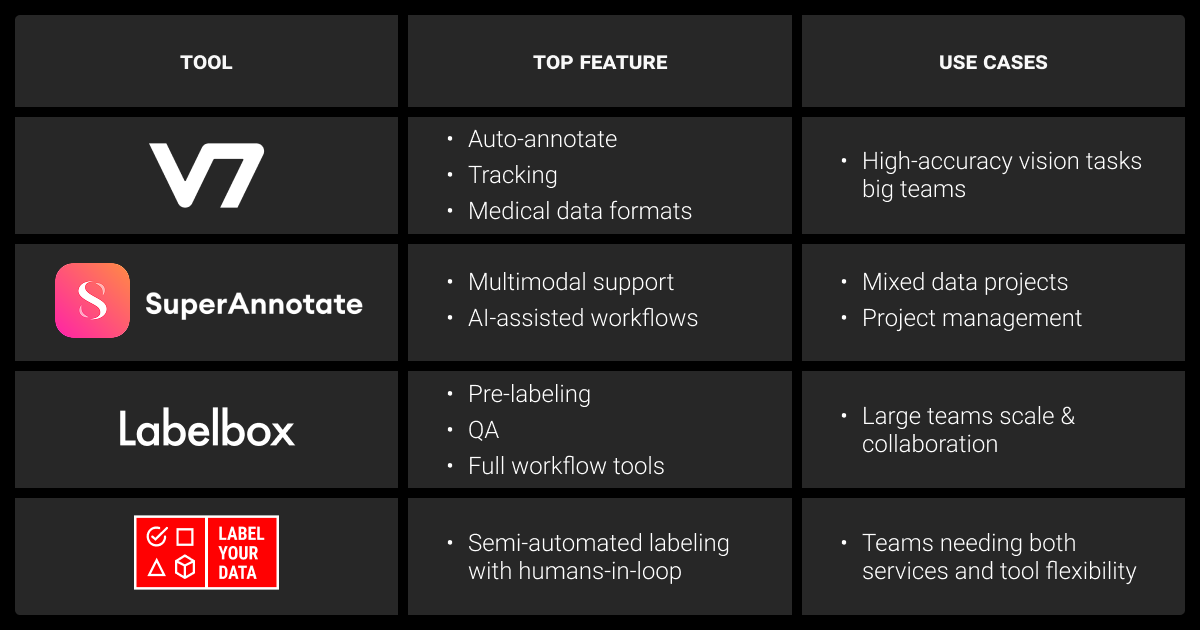
Not every project needs the same auto labeling tool. Some teams need scriptable control, others want enterprise compliance, and many just need to speed up the first pass of labeling.
We cover the best current solutions, along with their automation features, where each tool performs best, and the trade-offs that could affect your ML pipeline. Each automatic annotation tool relies on a machine learning algorithm, often pre-trained on large datasets, to generate draft labels.
Roboflow
- Features: Auto Label with SAM and Grounding DINO, Label Assist, Smart Polygon
- Best fit: Teams that need fast dataset prep and prototyping inside a unified pipeline
- Trade-offs: Paid tiers for advanced features; weaker on highly niche domains
Roboflow integrates foundation models like SAM and Grounding DINO to deliver zero-shot annotations and rapid pre-labeling. It’s often the first auto image annotation tool ML teams try when building early prototypes. You can upload, pre-label, and train baseline models inside one platform without building separate workflows. It’s most useful for vision projects where time-to-first-model is a priority, but performance may drop on unusual classes, requiring extra review.
CVAT (open-source)
- Features: Auto-annotation through built-in or custom models (BYOM), wide format support
- Best fit: Research and engineering-led teams needing on-prem or flexible pipelines
- Trade-offs: Requires setup and ongoing infra maintenance
CVAT is an open-source tool that supports images, video, and 3D, with flexibility to plug in your own models for pre-labeling. This Bring Your Own Model (BYOM) approach is valuable for teams with specialized data where vendor models fall short. Its strength lies in extensibility and control, but teams must manage deployment, scaling, and security in-house. That makes it a strong fit for research labs or enterprises that prioritize control over convenience.
V7 Darwin
- Features: Auto-Annotate for images and video, polygon masks, video interpolation, model-in-loop
- Best fit: Enterprise projects in regulated industries (e.g., healthcare, security) needing precision
- Trade-offs: Commercial pricing; advanced compliance features locked to paid plans
V7 Darwin focuses on precision with features like Auto-Annotate (pixel-perfect segmentation) and auto-tracking for video, cutting annotation time significantly. It’s designed for industries with strict compliance, supporting formats like DICOM for medical imaging. For ML engineers, the draw is quality and workflow orchestration – projects get enterprise-grade QA and regulatory assurances, but the cost model makes it less suitable for small teams.
Label Studio (open-source)
- Features: Auto-annotation, pre-labeling, active/online learning; ML integrations (e.g., OpenMMLab, custom backends)
- Best fit: Research and custom ML pipelines that need flexibility across data types
- Trade-offs: Open-source version lacks enterprise features; setup requires engineering time
Label Studio is built for experimentation and integration. It supports multiple modalities (like text, audio, video, time series) while letting you connect your own ML models for pre-labeling or active learning. For ML engineers, the strength is control: you can embed automation exactly where it fits in your pipeline. The trade-off is complexity, as the open-source edition requires engineering effort, and enterprise features like role-based access are paywalled.
Kili Technology
- Features: Model-based automation, AutoML, semi-automated labeling, vertical tutorials (e.g., geospatial, LLM evaluation)
- Best fit: Enterprise teams with regulated or industry-specific data
- Trade-offs: Higher cost; value best realized in large-scale operations
Kili Technology focuses on automation paired with strong quality assurance. Pre-labeling and AutoML features accelerate annotation, while built-in QA tools and LLM scoring add oversight. It also provides templates for verticals like geospatial or document processing. For ML engineers, the benefit is a managed workflow that keeps quality consistent in high-volume projects, but the platform’s cost and scope make it less appealing for small or highly custom datasets.
SuperAnnotate
- Features: AI-assisted editor, OCR automation, workflow orchestration, role-based QA
- Best fit: Enterprise teams scaling multi-stage annotation operations
- Trade-offs: Steeper learning curve; may be oversized for smaller teams
SuperAnnotate combines automation with structured workflows for enterprise-scale annotation. The AI-assisted editor reduces manual work on image and video tasks, while OCR tools support document-heavy projects. It stands out for integrated task routing and QA layers, making it effective for distributed teams with strict oversight needs. Smaller research groups, though, may find the platform heavier than necessary for their scope.
Ultralytics (open-source)
- Features: Auto Annotate (YOLO + SAM) for batch auto-labeling via CLI or script
- Best fit: Engineers comfortable with scripting who need fast pre-labeling
- Trade-offs: No UI or collaboration features; accuracy depends on model setup
Ultralytics provides a lightweight way to bootstrap annotations using YOLO and SAM. Engineers can run Auto Annotate to generate bounding boxes or masks across datasets with minimal setup. It’s well-suited for technical users who prefer scripts over interfaces and want rapid pre-labeling for experiments. The downside is the lack of workflow management or review features, so human QA has to be handled separately.
Encord
- Features: Automation with active learning, model-in-the-loop, QA and data quality analytics
- Best fit: Enterprises scaling annotation pipelines with compliance requirements
- Trade-offs: More setup complexity; cost structure geared to large teams
Encord emphasizes automation plus oversight. Its active learning workflows help reduce labeling load by selecting the most informative samples, while built-in analytics track data quality. For ML engineers, this combination streamlines large-scale projects where drift and governance are concerns. The trade-off is overhead — the platform is designed for enterprises with resources to integrate and maintain.
urAI
- Features: Auto entity annotation, OCR tagging for scanned documents
- Best fit: NLP teams handling large volumes of text and structured documents
- Trade-offs: Narrow focus; not applicable to multimodal tasks
urAI is specialized auto text annotation tool for natural language processing. It pre-labels entities in text and supports OCR-based document annotation, which speeds up NER and information extraction tasks. It’s valuable for ML teams working with financial, legal, or medical text, where auto-suggested entities cut annotation time. The limitation is scope, as this automatic text annotation tool won’t help if your pipeline includes images, video, or audio.
Mask R-CNN (open-source)
- Features: Script-based segmentation and detection; flexible model weights
- Best fit: Research teams or small groups needing custom automation
- Trade-offs: DIY-heavy; lacks UI, QA, and collaboration features
Using Mask R-CNN for automatic annotation remains a popular open-source approach. Teams run inference scripts to generate bounding boxes or masks, then export results in COCO or similar formats. This gives engineers full control and flexibility, but requires GPU access, coding skills, and manual QA processes. It’s most useful in research or experimental projects where teams want precision without committing to a commercial tool.
ML engineers often explore open-source options through an auto annotation tool GitHub repository, where scripts and models like Mask R-CNN are widely shared.
Focus on platforms that handle edge cases well and can learn from human corrections. Many tools stay static, but the ones that adapt to your feedback become increasingly valuable as your annotation needs evolve.

 AI Consultant, Clearlead AI Consulting
AI Consultant, Clearlead AI Consulting
Where Automation Breaks in Annotation Workflows
In safety-critical use cases, even a minor mislabel can compromise downstream performance.
Automatic tools accelerate AI data labeling, but they don’t cover every possible scenario. Models often miss small or overlapping objects, confuse classes that look alike, or degrade when data drifts into new domains.
Key weak spots to watch:
- Small or overlapping objects
- Domain shift
- Class confusion
- Model drift over time
The most effective safeguard is a structured quality-assurance loop. Confidence thresholds can flag low-certainty predictions for review, while correction rates provide a clear signal of when retraining is needed. Sampling strategies also help teams focus human effort where automation fails most often.
Semi-Automated Solutions (aka Humans-in-the-Loop)
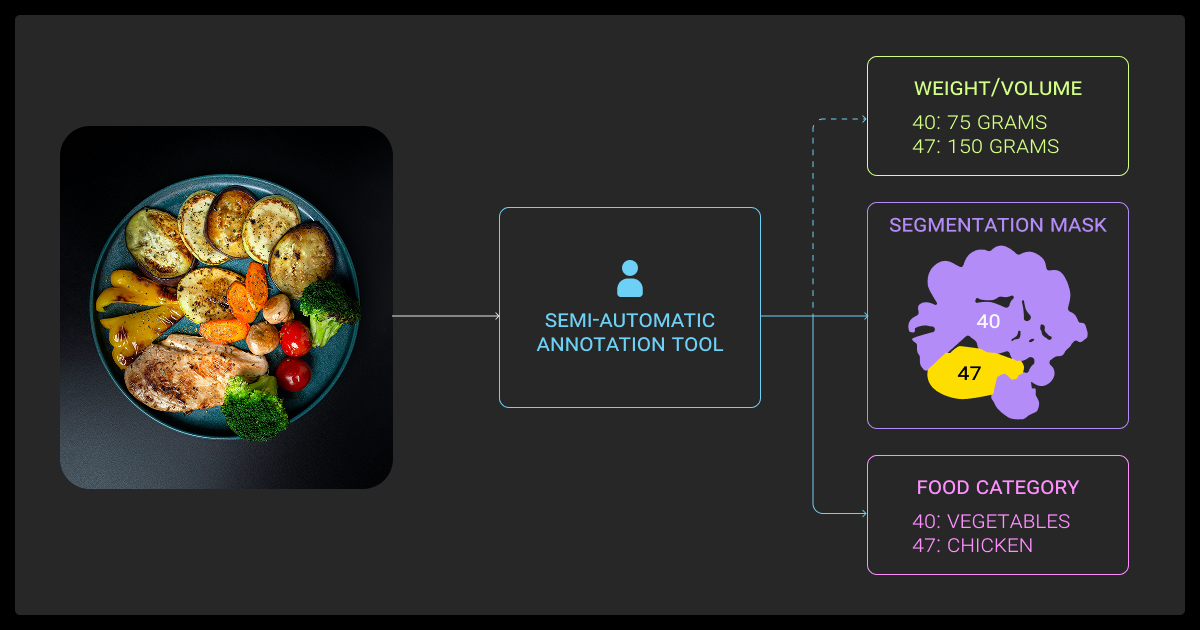
Full automation rarely holds up across complex datasets. LLM data labeling works well for entity recognition and classification, but requires careful human review to avoid hallucinations.
Semi-automated approaches bring humans back into the loop to review, correct, and handle edge cases. This balance gives teams faster throughput without losing accuracy or oversight.
Label Your Data
- Features: Human-in-the-loop with flexible, semi-automated workflows
- Best fit: Edge cases, rare classes, regulated data
- Trade-offs: Slower than full auto, but higher quality for more accurate model training
Label Your Data combines automation for repeatable patterns with expert review for complex samples. ML teams can push bulk data through auto-labeling, then rely on humans for low-confidence outputs. For enterprise clients and researchers, this option ensures compliance and reliable gold sets.
Here’s how our data annotation company compares to auto annotation tools, offering a human-in-the-loop model your ML team can consider for more reliable training data:
| User type | Automated tools | Label Your Data |
| ML teams | Fast pre-labels but higher correction load | Balanced speed with lower correction debt |
| Enterprise clients | Cheaper at scale but weak on compliance | Human oversight ensures audit trails |
| Researchers | Quick baseline datasets | Handles rare or novel classes carefully |
Managed HITL platforms
Vendors offering automation plus managed review teams are a fit for organizations without internal annotation ops. These data annotation services provide scalability and quality without requiring in-house staff, but come with higher recurring costs.
Custom pipelines
Engineering-led teams often combine an open-source auto annotation tool free like CVAT or Label Studio with internal reviewers. This setup offers flexibility and control, though it demands more coordination and infrastructure overhead.
Long-term ROI depends on whether the platform scales with your data and workflows, or becomes brittle. The biggest success signal is iteration speed — how fast you can go from ‘we need new labels’ to production-ready datasets.
 Growth, Dimension Labs
Growth, Dimension Labs
How to Choose the Best Auto Annotation Tool for Your ML Project

Picking an auto annotation tool is less about features on paper and more about fit with your workflow. The best choice depends on the type of data you work with, the level of control you need, and how much you want to rely on humans in the loop.
Start by mapping needs to tool classes:
- Tool-first (engineering-led stacks): Open-source or script-based tools give maximum control but require setup
- Hybrid (speed + oversight): Platforms that mix automation with QA reduce correction debt while maintaining checks
- Enterprise SaaS (compliance + scale): Provide audit trails, managed workflows, and integrations but come with higher cost
When evaluating options, focus on:
- Data modalities (images, video, text, 3D)
- Model-in-loop support (SAM, Grounding DINO)
- QA controls and reviewer workflows
- SDK/API integration and deployment (SaaS vs. on-prem)
- Total cost of ownership (licensing, infra, and people)
A pilot project is the most reliable way to validate a tool. It helps you not only measure correction rates but also predict long-term data annotation pricing at scale. Track time-to-first-model and correction rate to see whether the tool actually reduces annotation debt in your workflow.
Accuracy is table stakes. Look at label-to-deploy time, rework pricing, ontology versioning, and throughput under load. In one pilot, rework costs added 35–50% to the final invoice. Testing these factors upfront saves both time and money.
 Co-Founder, All-in-one-ai.co
Co-Founder, All-in-one-ai.co
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Can data annotation be automated?
Yes, but only to a point. Auto annotation tools can generate draft labels using models like SAM, YOLO, or rule-based templates. They speed up repetitive labeling tasks and help build baseline datasets. Still, human review is required to correct errors, handle ambiguous cases, and maintain dataset quality, especially in safety-critical projects.
How to annotate data automatically?
- Choose a tool with auto-labeling support (e.g., CVAT, Roboflow, V7, Ultralytics).
- Prepare a fixed ontology so the model knows what classes to predict.
- Run pre-labeling or auto-annotate on your dataset.
- Review low-confidence predictions through sampling or thresholds.
- Retrain the model with corrected data to improve the next pass.
What is auto annotation?
Auto annotation is the use of AI models to assign labels to raw data such as images, video, or text. It can take the form of full dataset pre-labeling, smart suggestions during manual work, or batch automation via scripts. The main purpose is to cut down manual effort and shorten time-to-first-model, while still keeping humans in the loop for QA.
Can I use ChatGPT for data annotation?
ChatGPT can help with certain text annotation tasks such as entity tagging, sentiment labeling, or summarization, but it doesn’t replace a structured data annotation platform. It works best as part of a pipeline: use it to generate candidate labels, then validate them with rules or human review.
While some teams test ChatGPT or compare Gemini vs ChatGPT for text-based labeling, these models are not replacements for structured annotation tools. For large-scale or multimodal data (images, video, audio), specialized annotation tools are a better fit.
Which is better, CVAT or Roboflow?
It depends on your team’s needs. CVAT is open-source, flexible, and supports BYOM (bring your own model), making it strong for research and privacy-sensitive projects. Roboflow is SaaS-based with a faster setup, built-in foundation models, and dataset management features, which helps for quick prototyping. CVAT requires more engineering overhead, while Roboflow trades some control for convenience.
How to auto annotate in CVAT?
- Launch a project in CVAT and upload your dataset.
- Enable auto-annotation and pick a pre-installed model or load your own.
- Apply the model to selected images or video frames.
- Review and correct generated labels in the UI.
- Export results in your preferred format for model training.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.