The Beauty of Automation in Data Labeling

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- Manual vs. Automated Data Annotation: What’s the Difference?
- Machine Learning Techniques & Other Approaches to Auto Labeling
- Auto Annotation Tools: How Does AI Handle the Data?
- Semi-Automated Data Labeling: The Best of Both Worlds
- Summary: Is AI the Go-To Solution for Delivering High-Quality Datasets?

It seems like the global AI community has reached the point when a dream of fully automated solutions becomes a reality. By integrating hyper-automation technology with modified operational procedures, Gartner predicts that enterprises will reduce operational expenses by 30% by 2024. But there’s a new goal today, that is making these automated systems reliable and safe for humans.
While complete automation of data science has been the ultimate objective of AI research, striving for this has proven to be computationally costly, mostly owing to the search space required. Additionally, certain choices might call for domain expertise, or there might be no ground truth to draw upon. Despite the fact that these technologies are not yet able to automate the entire data pipeline, they can be a valuable starting point for future innovations.
If you look at the traditional data labeling process, it’s entirely manual and time-consuming. However, despite the high accuracy rate of their annotations, humans are prone to errors and have limited productivity time. For this reason, many of the business processes today have been successfully automated thanks to AI. In data annotation, automation has resulted in a semi-automated or fully automated approach to labeling tasks.
As little human input as possible is required thanks to a semi-automatic workflow. An algorithm could, for instance, suggest whether to accept or reject a certain label. Comparatively, a fully automated approach to data annotation completely eliminates human intervention. This can be achieved by synthetic data creation and labeling, in which data are created and annotated by an algorithm based on a simulation.
Is automated data labeling worth your attention? Given that this method is flexible and helps to alleviate some of the challenges associated with data production, the answer is a resounding yes. If you want to learn more, keep reading!
But if you already know what type of annotation you need, go ahead and send your data to us!
Manual vs. Automated Data Annotation: What’s the Difference?

Today, there is a rising demand for high-quality and accurate data labeling for computer vision (CV) and natural language processing (NLP) tasks. Moreover, larger training datasets are of major importance for AI developers to ensure the safety and reliability of smart systems and technologies.
Relying solely on the manual work of annotators is no longer sufficient. It’s a time- and money-consuming process that might not even pay off. If you have a large-scale project to work on and need labeled data to train your model, you may not want to spend a lot of resources and time on a single process within a complex project development. This is when automation kicks in and offers fast, scalable, and resource-efficient solutions for those who annotate data and those who require it for their AI initiative.
But before we dive into auto data annotation, let’s first understand the difference between the manual approach to data labeling and the automatic alternative.
Manual Data Labeling
Data labeling as we know it is manual: a team of human annotators works hard to identify objects and put relevant labels in the images, video frames, text images, or even audio data. It’s the most popular and commonly used method of labeling. However, manual data annotation requires a lot of time and effort, which simply wouldn’t yield any positive results in today’s fast-paced digital environment.
In addition, data labelers go through hundreds and thousands of images (and other data types) in an effort to compile thorough, high-quality training data for machine learning. Having mass volumes of data might have the multiplicative effect of building up a backlog and delaying a project. This is the rationale behind the widespread adoption of expert data annotation services by AI engineers.
Yet, considering the accuracy and quality of training datasets, skilled human annotators continue to be the best option. Manual labeling can successfully identify the edge cases that automated techniques continue to overlook. Plus, quality control over enormous amounts of data is possible with skilled human annotators.
Automatic Data Labeling
Any data annotation carried out by machines rather than people is referred to as automatic labeling. Heuristic methods, machine learning models, or a mix of the two may be used for labeling. A heuristic technique entails processing a single piece of data in accordance with a set of rules that have been established in advance. These guidelines are set by human specialists who are aware of the underlying elements that affect how a data piece is annotated. Automated techniques offer the benefit of being cost-effective, and the labeling process itself is also rather efficient.
These criteria might, however, become obsolete or even flawed over time if the structure of the relevant data changes, which would reduce the labeling accuracy. Also, it can make the algorithm useless until the changes are taken into account. Human labelers can easily distinguish between a dog and a cat in a picture, for instance, but they are unsure of the particular processes the brain takes to do so.
The bulk of labels that are simple to identify may be handled via automatic data annotation. This approach can significantly expedite the labeling phase. However, there are still many inaccuracies in automated data labeling. When fed through to an ML model, that might end up being pricey.
Machine Learning Techniques & Other Approaches to Auto Labeling
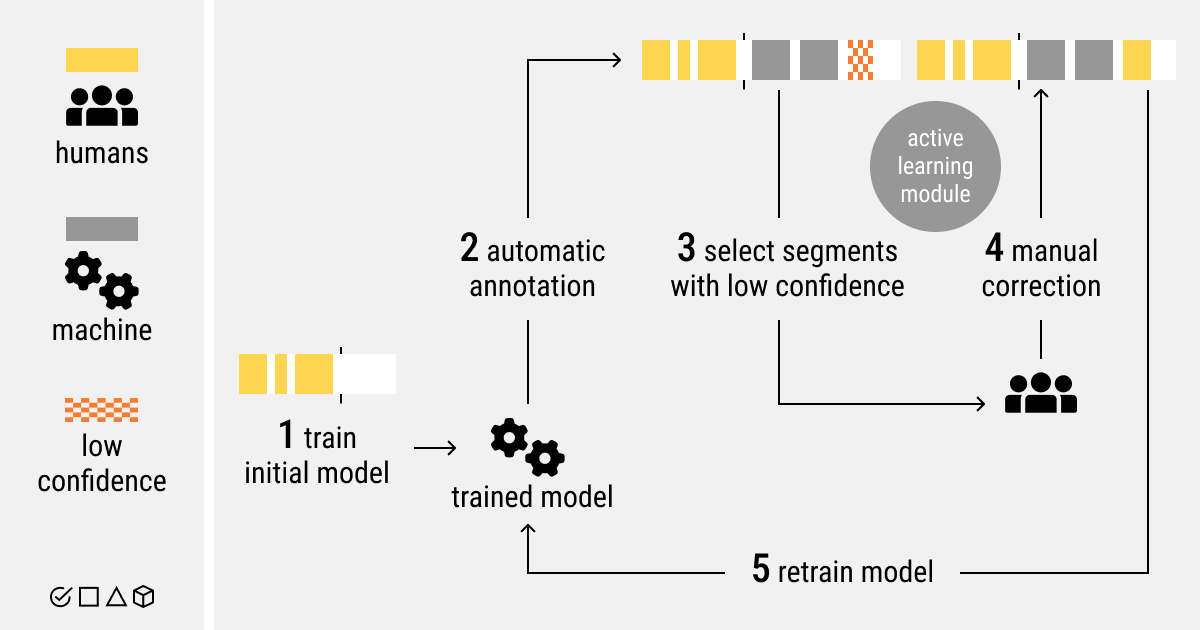
Machine learning has performed well in classification, object detection, image segmentation, and NLP. Data annotation, however, is one of the most crucial ML tasks. But the cost of machine learning goes up when there are lots of data points to categorize and label. As a result, researchers began to concentrate on lowering the cost of data labeling and enhancing its effectiveness with the use of automated and semi-automatic methods.
So, what does advanced auto labeling look like, and how to leverage AI systems to make the process of data annotation much more efficient?
Programmatic Labeling
The use of labeling functions and scripts, which are inherently more effective and reusable than manual labeling, allows programmatic labeling to unlock a much more scalable method for process automation. Teams can classify considerably more data thanks to this, adapt to changing requirements, and more efficiently detect or rectify bias in the labeling process.
Transfer Learning
This method implies using a model that has already been trained to solve a new challenge (aka retraining it on a new set of data). A machine improves generalization about one task by using the information it has gathered from previous tasks. As a result, it takes much less time and data to get a trained model that can be used to automate your workflow for data labeling.
Few-Shot Learning
The practice of providing a machine learning model with an absolutely small amount of training data is referred to as few-shot learning. As such, instead of annotating tens, hundreds, or even thousands of pieces of data, you can label just a few hundred images, for example. After that, you can use a platform to build a custom model tailored to your dataset and use it for automatic data labeling.
Active Learning
These ML algorithms, that fall under the category of supervised learning, help human labelers choose the best datasets. Active learning approaches to automatic annotation include membership query synthesis, pool-based sampling, and stream-based selective sampling.
AutoML
Automated machine learning is the process of automating the application of ML to real-world issues. More specifically, it automates the processes of training and testing ML models instead of hiring and managing a team of ML engineers. As such, no human intervention or custom engineering work is required with AutoML. There is essentially only one step to train a fully customized model on the available data.
Uncertainty Estimation
This is a method of model estimation of its own predictions and their uncertainty. The approach simply gives a model the ability to generate predictions and to express how confident or not it is in those predictions. Therefore, this is a highly important part of the frequently locked-up automatic data labeling. Uncertainty estimation is also a valuable tool that allows you to narrow down the data you might want to review for errors by human annotators.
Auto Annotation Tools: How Does AI Handle the Data?
Data labeling tools that use artificial intelligence to enhance and annotate a dataset include automatic labeling as a feature. To reduce the time and expenses of classifying data for machine learning, tools with this functionality supplement the labor of people in the loop. These auto annotation tools include functions that can significantly change the data annotation workflow.
Some of the most popular tools used for automated annotation (often mixed with the manual option as well) are:
- Amazon SageMaker Ground Truth. With features like automated 3D cuboid snapping, 2D picture distortion reduction, and auto-segment tools, this labeling tool from Amazon makes the process simple and efficient.
- Label Studio. To automatically generate reliable datasets, the machine learning backend incorporates well-known and effective ML frameworks. This automated tool is simple to use.
- Labelbox. Active learning combined with an analytical and automated iterative approach for labeling and training data, as well as making predictions.
- Tagtog. An NLP text annotation tool that offers automatic or manual data labeling. It enables you to automatically extract meaningful insights from text, find trends, pinpoint problems, and come up with solutions.
Overall, most of these tools are favored for two main reasons: they can help annotators with pre-annotation of the datasets or significantly lower the amount of work for them. Other assets that may help you auto annotate your datasets for a specific AI project include Playment, Superannotate, and CVAT. The latter is arguably the most commonly used auto annotation tool that we have tried and discussed in this article.
Semi-Automated Data Labeling: The Best of Both Worlds
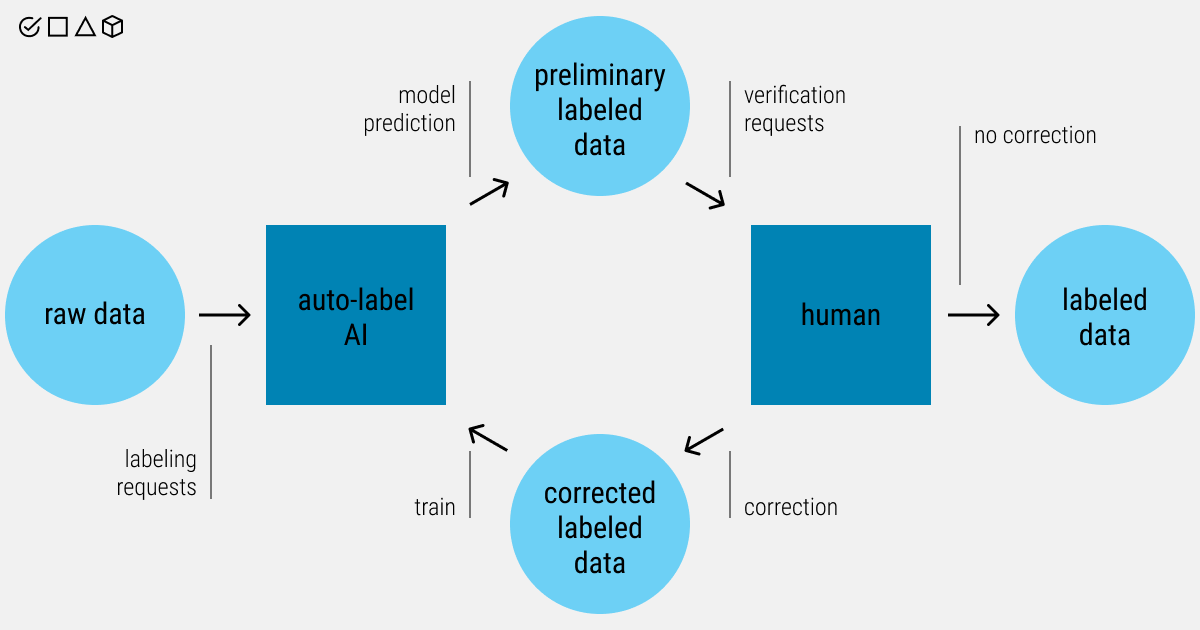
While automation bodes well for data annotation and machine learning in general, it’s important to understand if an automated process is the right option for your AI project. Automation has shown to accelerate the labeling process and aid ML experts in accomplishing their tasks. Applications that require regular updates are simpler to manage when a manual annotation is not involved.
In some cases, such as healthcare, manual labeling is often time-consuming for physicians and practitioners who are the only ones equipped to recognize and appropriately name aberrant growths or disorders. Engaging experts in the field should only be required when creating your ground truth dataset and throughout the QA procedure.
The same logic applies to other circumstances as well: it makes no sense to use expensive resources like engineers to supervise the manual labeling process. So what’s the solution here? The answer is a semi-automated data labeling.
Most people assume that working with training data is a purely manual procedure. Predictions challenge this idea by incorporating a machine into this arduous process. The output of a model may be used to quickly annotate raw data in real-time because training data and predictions have the same format. After that, this data can be fed into the training data pipeline and reviewed by the annotation experts that refine the data and feed it back again to the model. As a result, they get better results and accurate predictions. This is how a semi-automated data labeling looks like.
What Is Our Choice at Label Your Data?
Today, many AI-assisted technologies are available for use, including a lot of business applications. However, data for ML requires a nuanced approach in preparing it for the training and testing phases, and ultimately building an effective model.
This means that it’s almost impossible to eliminate the need for human manpower in this process. In reality, mistakes in quality control and data exceptions are less likely to occur with manually labeled data. However, in the times of the big data phenomenon, the requirements for annotation and the amount of effort are only increasing. Because of this, our team chose to combine both the skilled human annotators and the automation might of AI, which turned into a semi-automated workflow.
Organizing the labeling process as human-machine cooperation offers the potential to enhance the quality of annotations and minimize human effort. For us, a semi-automated data labeling workflow turned out to be the best bet. We use labeling tools and predictive models to direct and aid our team of human labelers. The model suggests labels and automates simple tasks in the labeling pipeline. It learns by monitoring previous annotation decisions. After that, our skilled annotators provide the option to give the model the rest of the labeling tasks at each checkpoint.
Summary: Is AI the Go-To Solution for Delivering High-Quality Datasets?

Due to the manual and process-heavy nature of data labeling, data engineers have traditionally delegated it to data scientists, concentrating instead on creating automated and repeatable solutions. Yet, automation has made its way to the field of machine learning and data annotation.
Well-trained human annotators still hold the top spot when it comes to precision and accuracy in training datasets. It’s crucial to involve human experts in the automated labeling process for the best decisions. However, a potent mix for today’s AI development is the appropriate auto labeling tools and a professionally managed and trained annotation staff.
If you want to experience the benefits of a semi-automated approach to data labeling, contact our Label Your Data team! We provide secure, customized, and high-quality annotations for your specific project.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.