AI Data Labeling: What ML Teams Need to Know

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- AI Data Labeling in Modern ML Pipelines
- Operational Playbook: Cost, Throughput, and Risk
- Quality Management in AI Data Labeling
- Tools and Platforms for AI Data Labeling
- AI Data Labeling Use Cases in Machine Learning
- Checklist for ML Teams (or Individual Practitioners)
- About Label Your Data
- FAQ

TL;DR
- Labels set the ceiling: both quality and representativeness determine model performance.
- Automation speeds annotation, but human review is essential for edge cases and safety-critical tasks.
- Synthetic data is now strategic, filling gaps and stress-testing models, though it must be validated.
- Scaling is less about adding annotators and more about workflow design and active learning loops.
- The right platform accelerates pipelines, while the wrong one creates bottlenecks and vendor lock-in.
AI Data Labeling in Modern ML Pipelines
If you’ve trained a production model, you know data annotation can quickly become the bottleneck. Architectures evolve fast, but mislabeled or unrepresentative data will sink performance every time.
A decade ago, many teams leaned on crowdsourcing sites like Mechanical Turk: upload guidelines, collect labels, and hope consensus worked. That approach scaled for simple image or text tasks but struggles with today’s needs:
- multimodal machine learning datasets
- domain-specific labeling
- or the preference data used to train LLMs
Now, AI data labeling is the standard. Models generate first-pass labels at scale, and humans refine the hard cases. Labeling has also shifted from a one-off preprocessing step to a continuous feedback loop.
Every deployed model becomes a data source, where errors, user behavior, and monitoring metrics feed new training data. Teams that fail to close this loop fall behind quickly.
AI-Assisted and Agentic Labeling
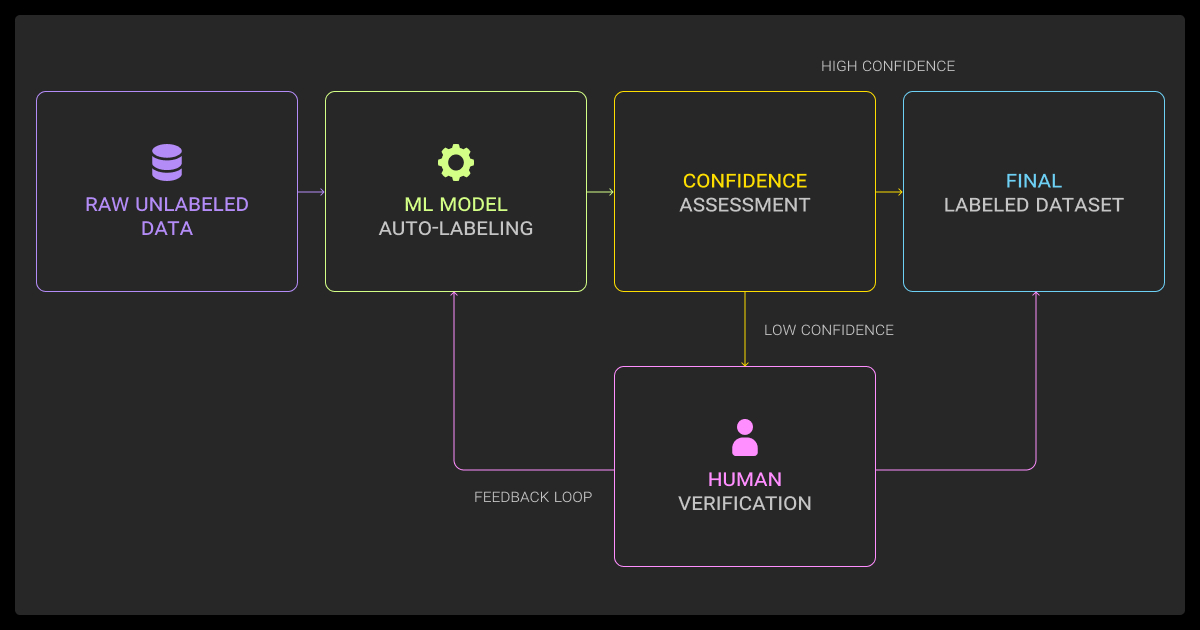
Automated data annotation speeds labeling and changes how teams structure their workflows.
For text, different types of LLMs can now generate zero- or few-shot labels for tasks like sentiment, entity recognition, or intent classification. These outputs, like with ChatGPT data annotation, reduce cold-start effort, but performance varies by domain, so human correction is still required.
For vision and image recognition tasks, models like SAM accelerate segmentation, producing masks in seconds. But SAM is a segmentation backbone, not a classifier; for classification you still need task-specific heads or downstream models. The human role shifts from drawing every bounding box or mask to reviewing and refining model suggestions.
The real question isn’t if you automate, but where you draw the boundary. Product tagging or e-commerce tasks may be fully automated with occasional audits. In safety-critical domains such as healthcare or autonomous driving, humans remain primary decision-makers, with AI serving as an assistant.
Synthetic data is also part of modern AI-assisted data labeling. Teams and data collection services use it to fill class gaps, simulate rare edge cases, and test robustness. Once models improve, they can help generate better synthetic data — a reinforcing cycle. But synthetic data must be validated: poorly designed sets can introduce bias or unrealistic distributions.
Early on we labeled everything for coverage, but that wasted time and compute. Many perfectly labeled points didn’t improve the model. The breakthrough came when we shifted to labeling only slices that reduced model confusion fastest. That single change boosted throughput and accuracy.

 CEO & Founder, Listening.com
CEO & Founder, Listening.com
Operational Playbook: Cost, Throughput, and Risk
Labeling strategy is now an engineering decision, not just a hiring plan. You’re always balancing data annotation pricing, speed, and accuracy — and you won’t get all three at once.
Adding more annotators drives up costs and doesn’t scale linearly. Many teams partner with data annotation services for complex cases but rely on automation as the backbone. The most effective setups treat domain experts and human-in-the-loop ML review as precision tools, not bulk labor.
Security and compliance run through every stage. For sensitive data (i.e., MRI scans, financial records, or personal information), you need full traceability: who labeled what, what transformations were applied, and where you stored the data before it’s used to train a machine learning algorithm. Providers should support audit logs, data lineage tracking, and regulatory readiness.
Industry requirements often make compliance as important as accuracy. In regulated domains, labeling pipelines must be designed with governance in mind before AI data labeling outsourcing or scaling up.
Quality Management in AI Data Labeling
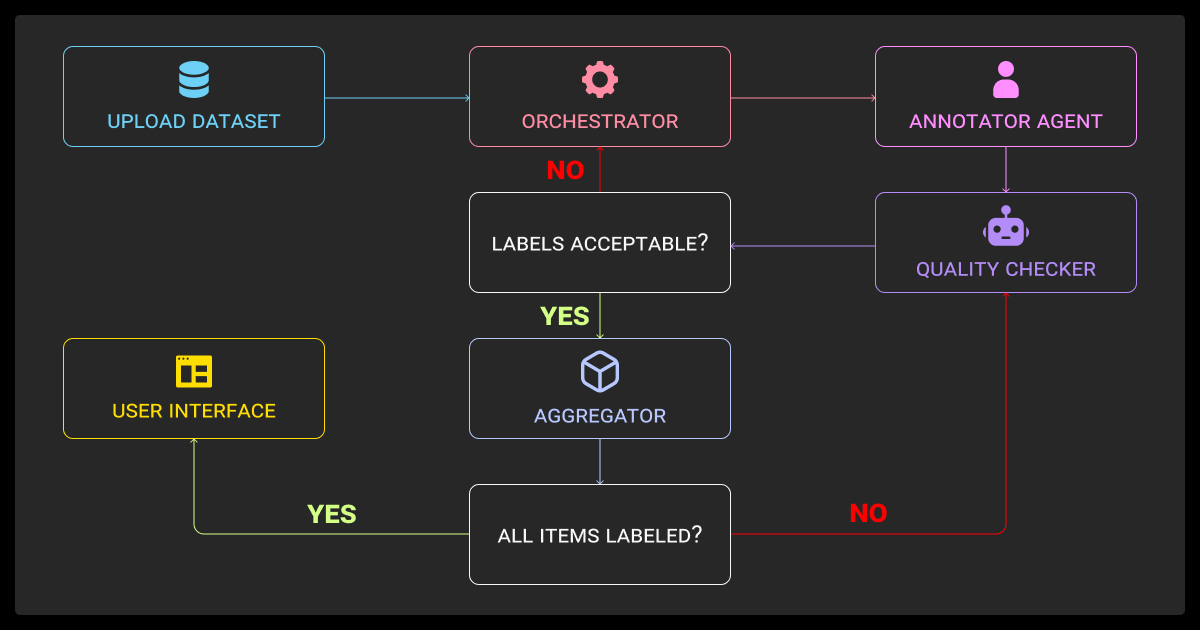
If you aren’t measuring inter-annotator agreement, you’re guessing about data quality. Metrics like Cohen’s kappa and Krippendorff’s alpha are still useful, but QA has expanded beyond them.
Modern data labeling AI systems can:
- audit datasets for consistency
- flag outliers using embedding similarity or uncertainty scores
- highlight disagreement hotspots for targeted review
Hybrid QA setups work best: AI-driven scans catch systemic issues early, while regular human audits validate edge cases. This scales more effectively than manual review alone.
Error taxonomy is another underused tool. Instead of just fixing mistakes, classify them (i.e., unclear guidelines, ambiguous samples, UI problems) so you can address root causes. Some teams and AI data labeling companies even build “stress-test” datasets designed to expose weaknesses before scaling.
It’s extra work up front, but it reduces preventable errors and improves long-term quality.
Tools and Platforms for AI Data Labeling
There’s no single best AI-driven data labelling software. The right choice depends on how much control versus convenience you need.
- Label Studio – Open source and highly customizable. Best if you want full-stack control and integration into custom ML pipelines.
- Snorkel – Focused on weak supervision. Lets you encode labeling logic as functions and combine multiple noisy sources into probabilistic labels.
- Prodigy – Lightweight, code-first, with strong active learning support. Well-suited for rapid annotation cycles with tight feedback loops.
Commercial platforms like Scale AI data labeling, Labelbox, and SuperAnnotate have evolved into orchestration systems: combining data annotation tools, workforce management, QA pipelines, and model-assisted workflows under one roof.
In short: if you want instant infrastructure, commercial platforms offer speed. If you’re building a long-term internal ecosystem, open source tools provide more flexibility, but at the cost of setup and maintenance.
When auto labeling tools aren’t enough
AI-assisted tools cover many cases, but not all. Complex multimodal datasets, compliance-heavy domains, or projects requiring domain expertise often need a data annotation company rather than just a platform.
Label Your Data provides managed services with a secure data annotation platform for these scenarios, combining expert review, iterative QA, and support for text, image, video, audio, and 3D point clouds. You can test the platform without risk with a free pilot (up to 10 frames).
We replaced generic categories with the actual decision trees adjusters use, like ‘pre-existing condition indicator.’ That specificity pushed claim accuracy to 98%. The second breakthrough was agent-driven QA — one AI agent checking another — which caught errors and cut training cycles from months to weeks.
 CEO, Agentech
CEO, Agentech
AI Data Labeling Use Cases in Machine Learning
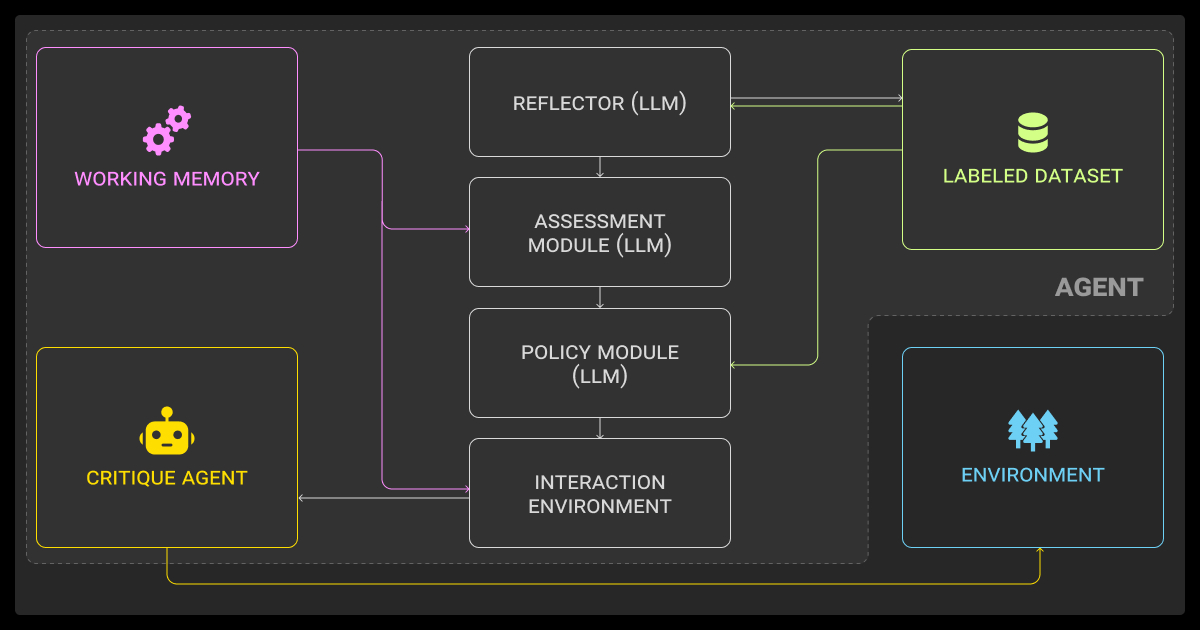
Data labeling in AI is no longer only manual; AI now assists in creating labels. LLMs generate zero-shot text labels, models like SAM pre-segment images, and active learning frameworks surface the hardest samples for human review.
| Area | AI-assisted labeling examples | Human role |
| NLP | LLMs generate zero-/few-shot labels for sentiment, topics, intent; GPT-based entity extraction from notes | Review domain-specific outputs (e.g., sarcasm, medical codes) |
| Computer Vision | SAM pre-segments radiology or driving images; auto-tagging for e-commerce products | Refine masks, correct ambiguous tags |
| Multimodal / Sensor Fusion | Pretrained 3D models label LiDAR + video; synthetic data for rare scenarios | Validate cross-modality consistency, stress-test synthetic sets |
| Active Learning | Models flag low-confidence chatbot intents or vision edge cases | Annotators focus only on uncertain/critical samples |
These approaches speed up annotation but still depend on expert oversight to refine edge cases, handle compliance-heavy data, and validate synthetic samples.
Checklist for ML Teams (or Individual Practitioners)
The following points summarize what matters most in AI-assisted data labeling for practitioners building production-ready systems:
- AI-first pipelines are now standard: Treat labeling as a core part of MLOps, not a side task.
- Labeling is continuous: It runs in parallel with training and deployment; every error or drift in production feeds back into the dataset.
- Manual-only workflows won’t scale: Use automation for volume, and reserve human effort for edge cases, compliance-heavy data, and QA.
- QA infrastructure is essential: Metrics, audits, and error taxonomies reduce preventable mistakes and improve long-term performance.
- Synthetic data is strategic: Use it to balance rare classes, simulate edge cases, and stress-test robustness, but validate to avoid bias.
- Vendor choice matters: Favor platforms and services that support open formats and portability to avoid lock-in.
Where AI data labeling fits in the MLOps cycle
Labeling is no longer a preprocessing step. It runs continuously alongside training and deployment: models surface uncertain or incorrect predictions, which feed back as relabeling tasks. Teams that build this feedback loop can adapt faster to drift and outperform static datasets.
When to use automation vs. human workforce
Automation accelerates bulk labeling, especially for well-structured or low-risk data, and is essential to scale AI data labeling services efficiently. Humans are most valuable where accuracy, context, or compliance is critical.
| Approach | Best for | Limitations |
| Automation (pre-labeling with models, active learning) | High-volume, low-stakes data; initial passes on vision/NLP tasks | Can miss nuance; needs human review for edge cases |
| Human workforce(in-house or outsourced) | Complex, domain-specific, or regulated tasks (medical, finance, autonomous driving) | Costly and slower without automation support |
| Hybrid(human-in-the-loop) | Most production pipelines; humans refine model outputs and guide iterative QA | Requires process design and monitoring |
In practice, most teams use a hybrid approach: the AI data labeling solution does the heavy lifting, humans ensure accuracy.
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is AI data labeling?
AI data labeling is the process of assigning structured, machine-readable labels to raw data such as text, images, audio, or video to train supervised models. Increasingly, AI-assisted labeling tools (e.g., LLMs, segmentation models) generate first-pass labels, which are then refined by humans to ensure accuracy and compliance.
Can data labeling be automated?
Yes, but automation depends on risk. Low-stakes datasets can often be fully automated with periodic audits, while safety-critical or regulated data always require human oversight. Most production pipelines use a hybrid setup, where AI pre-labels and humans correct.
How to categorize data using AI?
- Start with a zero-shot or few-shot model to generate initial labels.
- Fine-tune a model if task-specific accuracy is required.
- Use active learning to surface uncertain or novel samples.
- Add human review to correct edge cases and ambiguous data.
- Iterate the cycle until label quality and coverage stabilize.
What drives AI data labeling costs?
Costs are driven by data complexity, regulatory/privacy requirements, and the depth of QA. Multimodal and regulated datasets are typically the most expensive to label, and timelines also affect pricing when rapid turnaround is required.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.