Segment Anything Model: Architecture, Use Cases & Limitations

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Segment Anything Model (SAM)?
- How Segment Anything Model Works: Architecture Breakdown
- How to Use Segment Anything Model: Where SAM Earns Its Keep
- What Are Meta Segment Anything Model’s Limitations?
- When Should You Use SAM vs Human-in-the-Loop Annotation?
- How to Evaluate Segment Anything Model for Your CV Pipeline
- About Label Your Data
- FAQ

TL;DR
- SAM is Meta’s promptable segmentation foundation model (SAM 1 through SAM 3.1) that produces zero-shot masks from visual prompts, and from text or example images in newer versions.
- It performs well on natural-image pre-labeling and interactive tools, but accuracy drops on specialized domains like medical or AV data, and SAM does not assign semantic class labels.
- The production pattern that holds up is SAM plus human-in-the-loop annotation: the model handles fast pre-labeling and trained annotators with QA handle the refinement production accuracy demands.
When a machine learning team needs segmentation masks for a new dataset, Segment Anything Model (SAM) looks like the answer. The demos are stunning: click a point and get a clean mask. You can type “striped cat” and segment every striped cat in the video.
On Meta’s own SA-Co benchmark, though, Segment Anything Model 3 doubles every prior segmentation model and still trails human annotators by 25 points. This guide covers where that gap shows up on production data.
What Is Segment Anything Model (SAM)?
The Segment Anything Model (SAM) is Meta AI’s promptable foundation model for image and video segmentation.
You give it a prompt (a click, a box, a coarse mask, or with newer versions, a text phrase or example image), and it returns segmentation masks for the matching object or concept. SAM was designed to do this without task-specific fine-tuning, working zero-shot across a wide range of imagery.
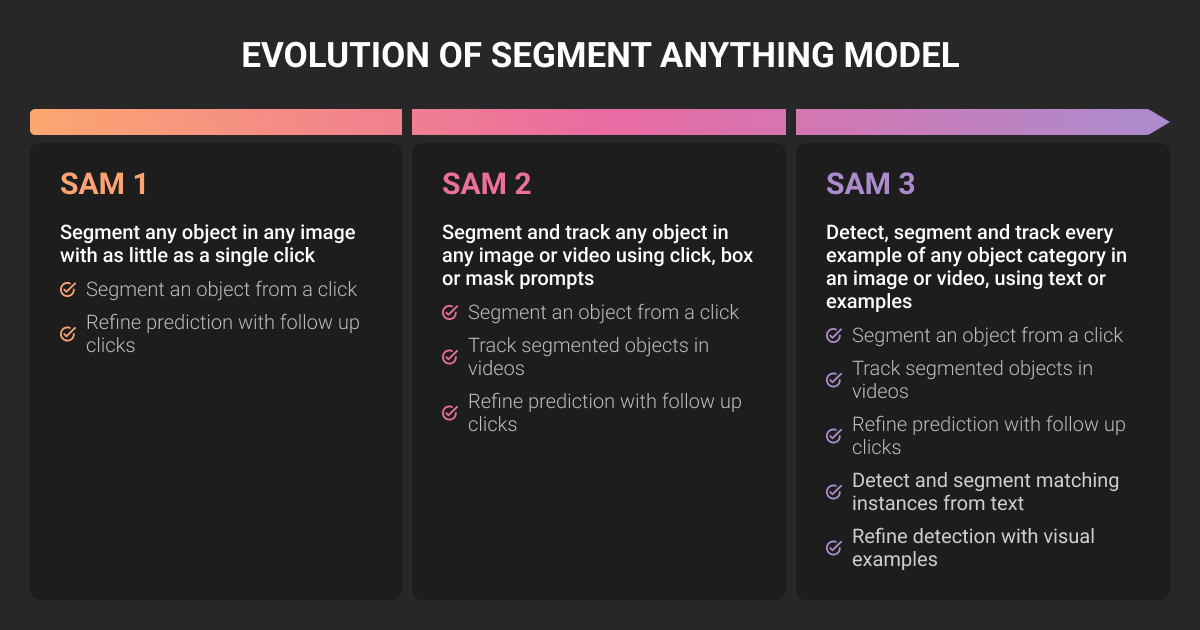
The model has shipped in several versions since the original 2023 release:
- SAM 1 (April 2023): image-only segmentation, prompted with points, boxes, or coarse masks. Trained on SA-1B, a dataset of 1.1 billion masks across 11 million images.
- SAM 2 (mid-2024): unified image and video segmentation, with a streaming memory module that tracks objects across frames.
- SAM 3 (November 2025): adds Promptable Concept Segmentation (PCS), where a short text phrase or example image tells the model to segment every instance of a concept in an image or video. Roughly 848M parameters, 3.4 GB on disk, and around 30 ms per image on an H200 GPU.
- SAM 3.1 (March 2026): a faster release with multiplexing and global reasoning, optimized for real-time video.
For computer vision (CV) teams, the appeal is obvious. One model that handles a huge range of segmentation tasks zero-shot saves you the cost of training a bespoke segmentation model for every new use case.
Whether that promise survives contact with your production data is the question this article tackles.
How Segment Anything Model Works: Architecture Breakdown
Segment Anything Model architecture has three core components in the original design: an image encoder, a prompt encoder, and a mask decoder. SAM 2 and SAM 3 extend this design with memory modules and a detector-tracker structure.
Image encoder
The image encoder is a Vision Transformer (ViT) that converts the input image into a dense latent embedding. This is the heaviest part of the network. SAM 1 offered ViT-B, ViT-L, and ViT-H variants. SAM 3 uses a shared Perception Encoder backbone across the detector and tracker components, with the full model sitting around 848M parameters.
The encoder runs once per image. After that, you can apply many prompts to the same embedding without re-encoding, which is what makes SAM feel snappy in interactive tools.
Prompt encoder
The prompt encoder converts user inputs into embeddings the mask decoder can consume. Original SAM supported four prompt types: positive or negative point clicks, bounding boxes, coarse masks, and a limited form of free-form text.
Segment Anything Model 2 (SAM2) kept these visual prompts and added per-frame memory for video. SAM 3 made open-vocabulary text prompts a first-class capability and introduced image exemplars, where you draw a box around one example and SAM finds similar objects elsewhere in the scene.
You can mix prompt types within a single inference, for example combining a text phrase with positive clicks for refinement.
Mask decoder
The mask decoder is a lightweight transformer that fuses the image embedding with the prompt embedding and outputs candidate masks plus a confidence score. SAM returns up to three masks per ambiguous prompt, letting you pick the one that matches your intent.
This is where most fine-tuning effort gets focused. The image encoder is large and expensive to retrain. The mask decoder is small and adaptable, and parameter-efficient methods like Low-Rank Adaptation (LoRA) and adapter modules let teams adjust SAM for new domains without retraining the backbone.
Variants such as SamLoRA, SAM-Adapter, BLO-SAM, and AM-SAM have all built on this approach in academic and applied work.
What changed in SAM 2 and SAM 3
Segment Anything Model 2 introduced a streaming memory module that lets the model track an object across video frames using context from previous frames. The model behaves like SAM 1 on still images, then activates the memory module on video.
Segment Anything Model 3 made a bigger architectural shift. The model now has a dual detector-tracker design that shares a single backbone. A presence head decouples recognition from localization, which Meta says improves accuracy on closely related text prompts (for example, distinguishing a player in white from a player in red).
On Meta’s PCS benchmark, SAM 3 doubles the accuracy of prior systems and reaches roughly 75 to 80 percent of human performance on SA-Co, a 270K-concept evaluation set.
How to Use Segment Anything Model: Where SAM Earns Its Keep
Segment Anything Model (SAM) is genuinely useful in the right places. Here are four use cases where CV teams are getting real value.
Pre-labeling for annotation pipelines
This is the highest-leverage use of SAM today. Instead of asking annotators to draw polygons from scratch, you generate SAM masks first and have annotators verify or refine them, rejecting the ones that miss. Roboflow, CVAT, and most modern annotation platforms now bundle SAM-based pre-labeling.
Segment Anything Model Meta AI can cut annotation time on natural-image data substantially. The economics depend almost entirely on the rejection rate, which we will come back to.
Interactive segmentation tools
For creator and editing tools, SAM is a natural fit. Meta’s Segment Anything Playground lets users isolate or modify parts of media with text or click prompts.
Facebook Marketplace’s “View in Room” feature uses SAM 3 and SAM 3D to let users visualize furniture in their own space. After Effects and ComfyUI plugins for SAM-based masking and roto work have already become standard in VFX pipelines, with Stable Diffusion ecosystems following close behind.
Open-vocabulary tasks
If you have a use case where the set of categories you care about is large or shifts often, SAM 3’s PCS task lets you avoid retraining a closed-vocabulary detector every time the taxonomy changes. This is a fit for retail product recognition with rotating SKUs, content moderation with evolving policy categories, and wildlife monitoring projects tracking rare species.
Prototyping and synthetic data
For early-stage projects without labeled data, SAM lets you generate masks fast enough to bootstrap a model. Many CV teams use SAM to produce a noisy first dataset, train a smaller production model on that, then iterate.
SAM is also useful inside synthetic data pipelines for isolating objects to composite into new scenes.
SAM is great when you need speed and flexibility, especially with tons of different images. Before SAM, we did all that correcting by hand, which was brutal. SAM just handles messy, real-world photos without as much fuss. But for precise masks or anything compliance-heavy, my teams still go with the old segmentation methods. It’s more reliable for QC.

 CEO, Magic Hour
CEO, Magic Hour
What Are Meta Segment Anything Model’s Limitations?
SAM (Segment Anything Model) is impressive on the curated demos. The gap between demo and production gets wider as your data gets weirder.
Domain shift hurts more than the demos suggest
SAM was trained predominantly on natural images. When you take it into specialized domains, the wheels start to come off. Studies on digital pathology, kidney biopsy, agriculture, manufacturing inspection, and remote sensing have all documented significant accuracy drops on out-of-distribution data.
A widely cited Segment Anything Model paper titled Segment Anything Is Not Always Perfect investigated the model across these fields and found that performance degrades sharply outside common scenes, especially when target regions blend into their surroundings.
For autonomous driving teams, this matters. A model that segments a sunny suburban street perfectly may miss a low-contrast pedestrian against a wet road at dusk. Production AV models live in the long tail of weather variation and heavy occlusion, and SAM was not built specifically for that kind of data.
SAM produces masks but no semantic labels
This is a foundational point that surprises a lot of teams. SAM 1 and SAM 2 produce masks without semantic labels. The model can isolate the shape of a thing, but it does not tell you whether the thing is a pedestrian, a shopping cart, or a curb.
SAM 3 partially closes this gap with text prompts, but you still need a separate classifier or detector if your downstream task requires consistent class labels at scale. For perception systems where the label is the entire point, SAM is a mask generator, not a labeling solution.
Boundary precision falls short for safety-critical work
SAM optimizes for coverage and generalization rather than granularity. There are no built-in refinement modules, no zoom-in functionality, and limited control over fine-grained edge accuracy.
Annotation providers evaluating SAM in production have reported that manual editing is often more time-consuming than labeling from scratch when expert annotators are aiming for production accuracy. SAM alone cannot reliably produce the pixel-level rigor the safety-critical CV tasks demand.
Tracking and edge cases break in dense scenes
SAM2 (Segment Anything Model 2) and SAM 3 made real progress on video segmentation, and they have known weak points. Ultralytics' SAM 2 documentation lists tracking instability over long sequences, object confusion in crowded scenes, efficiency drops with multiple simultaneous objects, and missed detail on fast-moving subjects.
Segment Anything Model 3 inherits some of these issues and adds prompt sensitivity: as one hands-on review notes, getting robust behavior still depends on careful prompt design and well-chosen exemplars. In production, these limitations turn into rework that erases SAM’s speed advantage.
Fine-tuning still needs labeled data and GPU budget
You can adapt SAM to your domain. A growing body of work (V-SAM, BLO-SAM, SAM-Adapter, SAM2-Adapter, SamLoRA) documents how to do this with parameter-efficient methods. None of it is free. You need a labeled target-domain dataset, plus GPU budget and ML engineering capacity.
If you were hoping SAM would let you skip the labeled dataset step, fine-tuning will pull you right back into it. And the dataset has to be high quality, or your fine-tuned SAM will inherit the same flaws.
When Should You Use SAM vs Human-in-the-Loop Annotation?
Use SAM when speed and coverage matter more than pixel-perfect accuracy, and when your domain looks roughly like natural images. Bring in human-in-the-loop annotation when accuracy directly affects safety outcomes or regulatory compliance.
SAM works well for:
- Pre-labeling that human annotators will refine
- Interactive tools where users provide prompts and accept passable masks
- Open-vocabulary tagging where the taxonomy changes often
- Synthetic data and prototyping for early-stage projects
SAM struggles when:
- You need pixel-precise boundaries (medical, defect, damage segmentation)
- Your domain is far from natural images (LiDAR projections, thermal, gigapixel WSI)
- You need consistent class labels at scale across millions of frames
- Your dataset has long-tail edge cases the foundation model never saw
SAM outperforms traditional segmentation when its outputs are captured with provenance and treated as signed, versioned artifacts. We link model overlays to model version, data slice, and human edits. That provenance makes SAM suggestions usable in tumor boards and payer reviews. Without it, stick with human-audited measurements.
 Co-founder, Medicai
Co-founder, Medicai
How to Evaluate Segment Anything Model for Your CV Pipeline
Before committing to SAM, run a structured evaluation:
- Pull a representative sample from your production data: real frames with the noise, weather, occlusions, sensor artifacts, and edge cases your model will see.
- Run SAM with your intended prompt strategy (clicks, boxes, text, exemplars, or a mix).
- Measure mask quality against ground truth using IoU. Track it per object class and per scene type so you see where the failures cluster.
- Measure annotator effort to bring SAM masks to production quality. This is the number that decides whether SAM is paying for itself.
- Identify the slices where SAM fails. Decide whether to fine-tune SAM for those slices or route them to human-only annotation.
Skip step 4 and you will not actually know whether SAM saved you anything.
If you are evaluating Segment Anything Model (SAM) Meta AI for an upcoming dataset and want to talk through where it will help and where it will hurt, our team is happy to scope it with you.
About Label Your Data
If you choose to delegate segmentation labeling, run a free data pilot with Label Your Data. Our human-in-the-loop QA has helped many CV teams scale their SAM pipelines into production. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Is Segment Anything Model a CNN?
No. SAM is a transformer-based model, not a CNN. Its image encoder is a Vision Transformer (ViT), the prompt encoder uses positional encodings, and the mask decoder is a lightweight transformer. SAM 3 keeps this transformer-first design and adds a DETR-style detector with a Perception Encoder backbone shared between the detector and tracker.
Is Segment Anything free?
Yes, with caveats. SAM 1, SAM 2, and SAM 3 model weights and code are released by Meta under the Apache 2.0 license, free for commercial use. You will still pay for the GPU compute to run inference and any fine-tuning, plus the engineering time to integrate SAM into your pipeline. The SA-1B training dataset is research-only, but it doesn't restrict using the trained models in production.
What is the difference between SAM and YOLO?
YOLO is a closed-vocabulary object detector trained to find a fixed set of classes and output bounding boxes (or masks in YOLO-Seg variants). SAM is a promptable, open-vocabulary segmentation foundation model.
YOLO knows what categories it's looking for in advance and is faster and more accurate within them. SAM segments anything you prompt it to, including categories it has never explicitly seen, but trails specialist detectors on narrow domains.
In production CV pipelines, the two are often complementary: YOLO detects and SAM segments the detection.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.