How to Build an Effective Product Classification Pipeline

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Product Data Classification Is Harder Than It Looks
- How Product Classification Works in an AI Pipeline
- Types of Product Data Used for Classification
- Building a Reliable Annotation Workflow
- Evaluating Product Classification Models
- Scaling Product Classification Across Catalogs and Regions
- Compliance and Regulatory Product Classification
- Key Challenges in Product Data Classification
- Best Practices for Building Your Product Classification Pipeline
- About Label Your Data
- FAQ

TL;DR
- Product classification impacts everything from search relevance to product analytics and inventory. Scaling it across messy catalogs and multilingual data is harder than it seems.
- You need more than a model. Success depends on clean, consistent, labeled product data – across text, images, attributes, and evolving taxonomies.
- Human-in-the-loop QA, dataset versioning, and pipeline automation are key to handling edge cases, rare classes, and compliance mappings.
Why Product Data Classification Is Harder Than It Looks
Getting product categories right is critical for search, recommendations, and analytics. But it’s harder than it sounds. Most product data is messy, unstructured, or inconsistent, especially across large catalogs.
Off-the-shelf models struggle with edge cases like duplicate SKUs, multilingual descriptions, and overlapping product classification categories. Errors cascade: mislabeled items affect downstream performance and user trust.
If you’re building a product classification pipeline, here’s what typically breaks:
- Free-text input with typos and inconsistent formats
- Class imbalance and ambiguous boundaries
- Taxonomy drift over time and across regions
Label Your Data supports classification projects by cleaning, normalizing, and labeling product data with human-in-the-loop QA, making sure your machine learning algorithms train on accurate inputs.
How Product Classification Works in an AI Pipeline
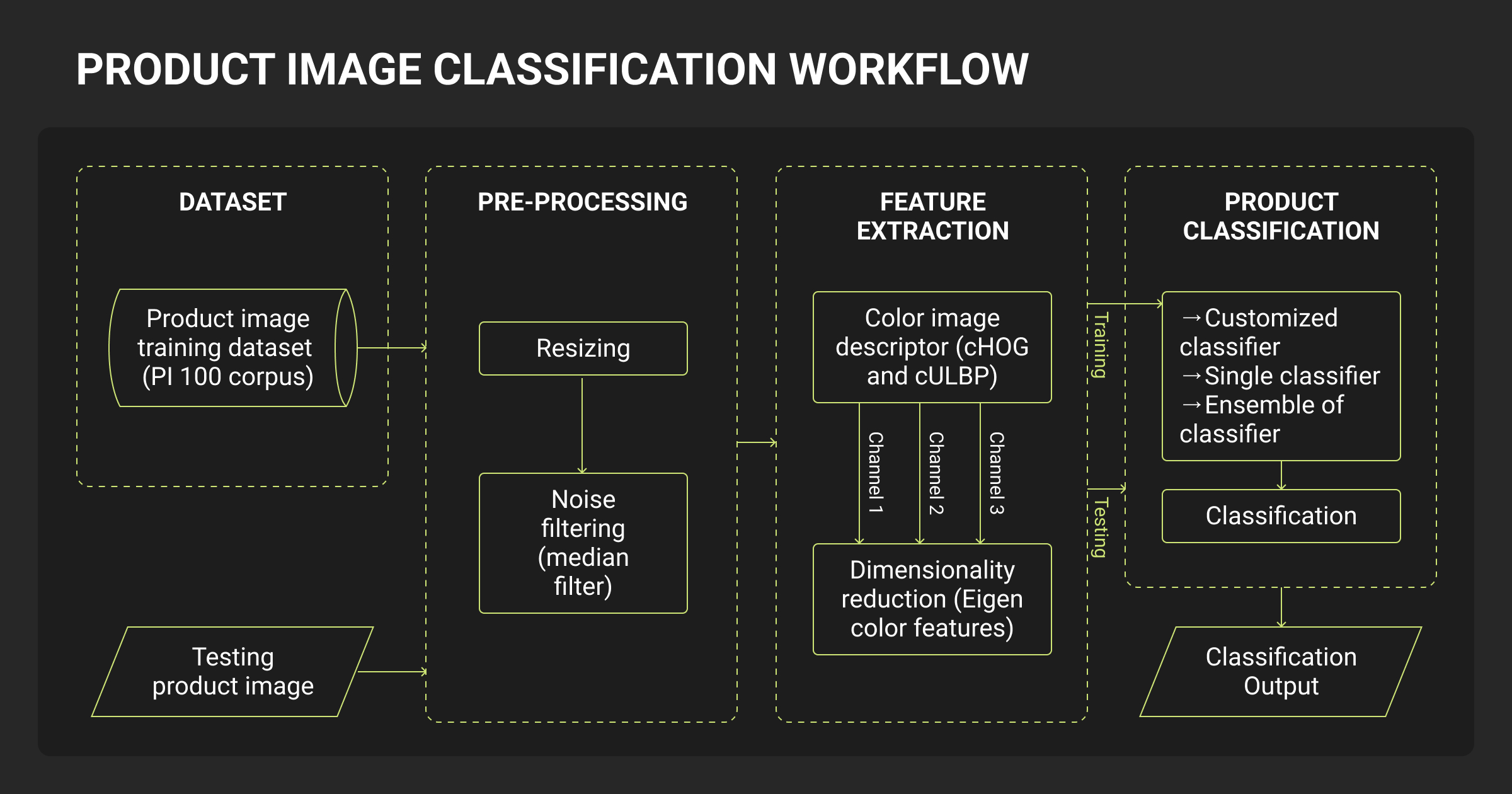
Product classification pipelines follow a structured workflow that turns messy catalog data into model-ready features and labels.
While the basic steps resemble standard ML pipelines, product data classification adds layers of complexity due to inconsistent formats, evolving taxonomies, and the need for multilingual support.
Data ingestion
This step pulls raw product data from multiple sources: ecommerce databases, ERP systems, vendor feeds, or scraped content. Most product data lives in platforms like Shopify, Magento, or WooCommerce payment gateway-based stores, each with its own catalog schema and metadata conventions.
Common ingestion formats include JSON, XML, CSV, or SQL dumps, and ingested records are often noisy, incomplete, or duplicated. For example, a product may appear twice with different SKUs but the same title, or with inconsistent attributes depending on the seller.
Preprocessing
You normalize fields like price, units, and text case; deduplicate records; and resolve conflicting metadata. For image data, you validate resolution, orientation, and file format. Preprocessing ensures consistent structure before annotations or features are created.
Tools often used: Pandas, PySpark, or custom ETL pipelines. Schema validation (e.g. with Pydantic or Cerberus) is key at this stage.
Annotation and labeling
At this step, you – or an expert data annotation company – add structured labels, either manually or through weak supervision. Label types vary:
- Category tags (e.g. Electronics > Phones > Accessories)
- Attributes (e.g. material, color, compatibility)
- Flags for duplicates, violations, or policy alignment
Data annotation may be handled in-house or outsourced to trusted data annotation services for multilingual and edge-case-heavy product catalogs.
Model training and evaluation
Once labeled, the data feeds into a classification model – typically using gradient-boosted trees or transformers depending on the modality (text/image/multimodal).
Key requirements:
- Balanced representation across categories
- Handling long-tail classes
- Versioned experiments with tools like MLflow or Weights & Biases
Evaluation goes beyond raw accuracy: F1 scores per class, confusion matrices, and error slices are critical for production reliability.
Deployment and feedback loops
Trained models are deployed for batch or real-time classification. But accuracy in production depends on feedback from downstream systems (e.g., search logs, conversion funnels, manual overrides).
Continuous evaluation pipelines flag misclassifications, taxonomy drift, or emerging product types. These issues should trigger re-annotation, model retraining, or schema updates.
Tip: Pipelines should be modular, reproducible, and observable; with DAGs for orchestration (e.g. Airflow), and built-in hooks for human review.
Types of Product Data Used for Classification
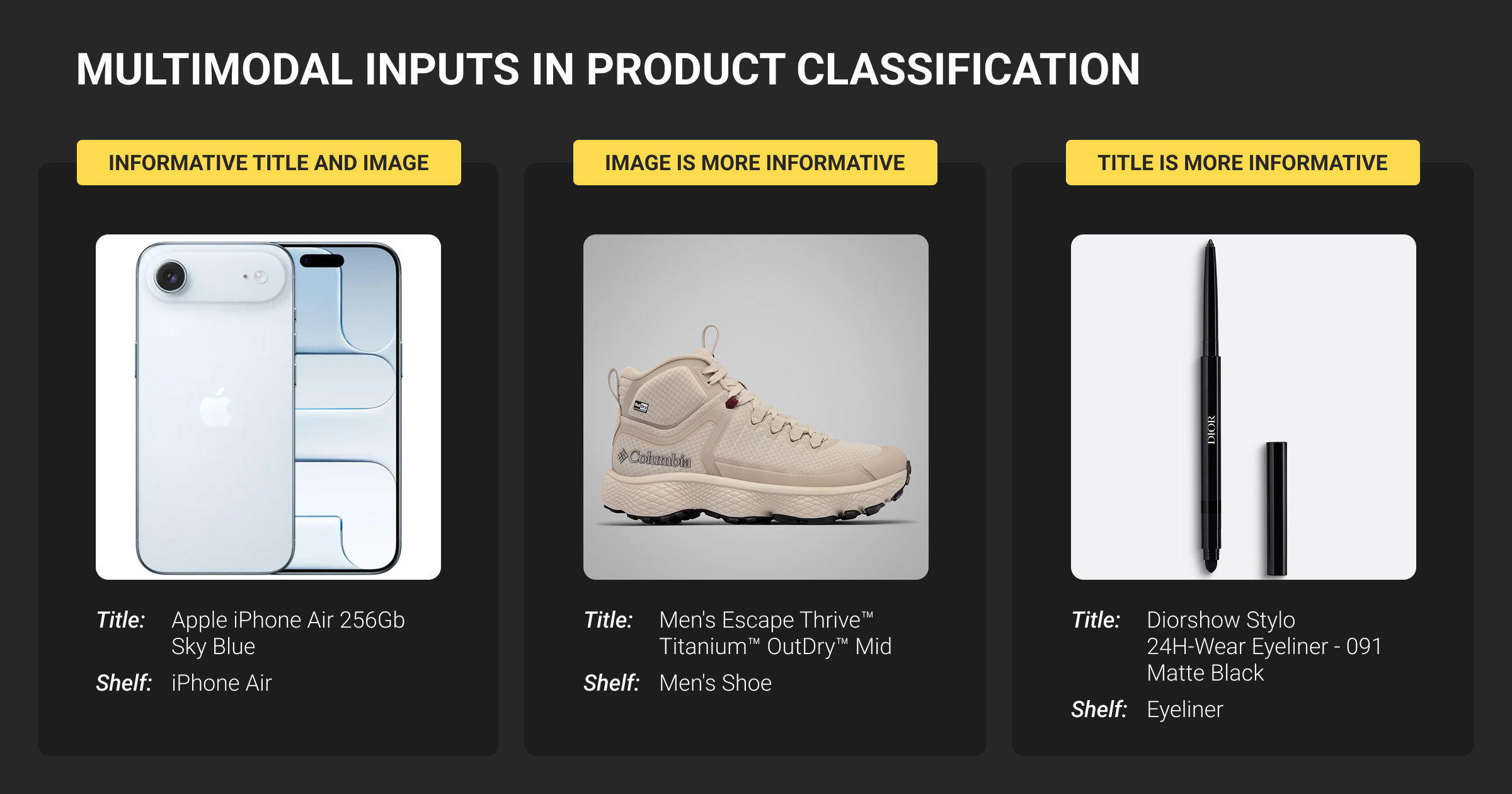
Classification performance depends heavily on the quality and format of input data. In retail and ecommerce, that often means working across multiple modalities, each with distinct preprocessing, annotation, and modeling needs.
Effective pipelines use the right combination of modalities based on product type, available metadata, and classification goals.
Text data
Product titles, descriptions, attribute fields, and product review classification categories provide the most accessible signals. But these are often messy: inconsistent phrasing, filler text, language noise, and overuse of marketing keywords can hurt model precision. Preprocessing may involve stopword filtering, lemmatization, and phrase normalization.
Use case: Classifying mobile phone accessories based on keywords like “wireless,” “MagSafe,” or “Android-compatible.”
Image data
Visuals help models distinguish products that look similar in text but differ in form (e.g., “blue shirt” vs. “navy jacket”). Image classification or similarity models require clear, high-resolution input. Bounding boxes or segmentation can add detail but require manual human annotation effort.
For visual-heavy catalogs like fashion or electronics, image recognition models are essential. They power product similarity search, detect duplicates, and assist in tagging visual features like color or texture.
Use case: Identifying packaging variations of the same product or detecting mislabeled apparel colors.
Multimodal data
Combining text and image embeddings often leads to better accuracy than either alone. Transformer-based models like CLIP or BLIP align visual and textual representations, improving generalization. Multimodal pipelines are especially valuable when titles are vague or images are ambiguous.
Use case: Disambiguating listings where a product title is generic (“Men’s jacket”) but the image or attributes offer clarity.
Tabular and metadata
Structured fields like price, dimensions, SKU codes, and vendor IDs help fine-tune classification, especially for edge cases. These features are commonly used in ensemble models or decision rules post-inference to refine output.
Use case: Filtering duplicates or mapping to regulatory codes based on vendor category codes and price thresholds.
In e-commerce and healthcare, pairing text and images leads to better classification—especially for unfamiliar or niche products. From our work, multimodal models consistently outperformed text-only baselines. Start small, measure what improves performance, and iterate instead of over-engineering.

 Co-Founder, Superpower
Co-Founder, Superpower
With our global team at Label Your Data, you can easily tackle multimodal annotation across text, images, and tabular fields and get unified training datasets that reflect real-world complexity across verticals like fashion, electronics, and healthcare.
Building a Reliable Annotation Workflow
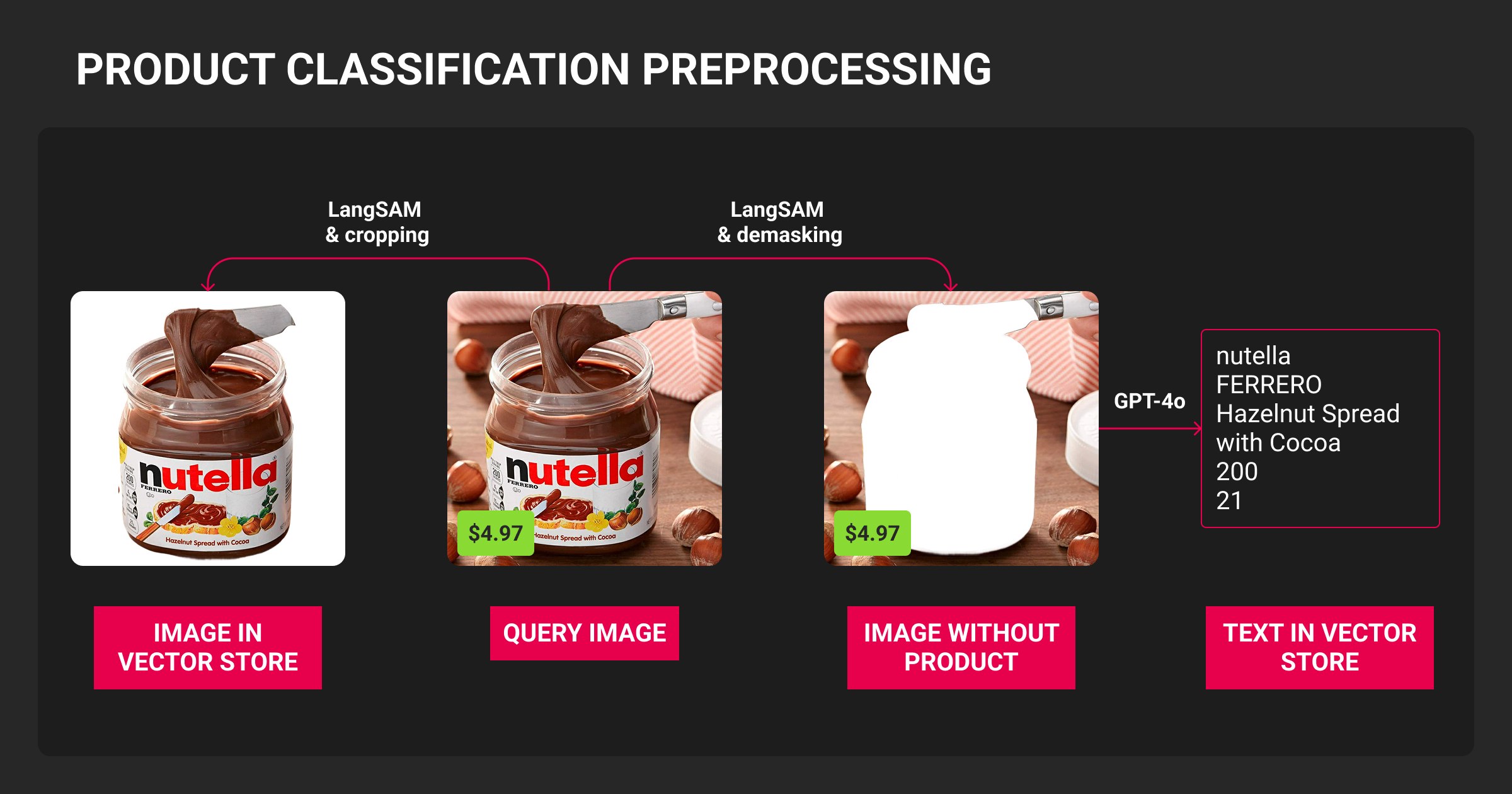
Annotation is the make-or-break point for most classification pipelines.
The effectiveness of models hinges on the quality of the labels they learn from, and when it comes to product data, we often need a mix of human insight and adaptable tools to nail those labels. Issues like inconsistent categories, duplicate SKUs, and vague descriptions all need a level of attention that goes beyond what automation can handle.
Annotation techniques
Product classification may require more than just assigning a top-level category. Our team usually works with:
- Text data: Category tags, sentiment of reviews, attribute extraction (e.g., material, style)
- Image data: Bounding boxes for product focus, segmentation for shape analysis
- Structured data: Flags for duplicates, missing attributes, or misaligned SKUs
Edge cases, like multilingual descriptions or visual lookalikes, often require expert human review.
Quality assurance
Even strong models can’t compensate for noisy or inconsistent labels. That’s why QA matters:
- Consensus workflows: Multiple annotators label the same item; disagreements trigger review
- Gold sets: Curated examples used for benchmarking accuracy
- Audit trails: Every label should be traceable: who labeled it, when, and with what confidence
In our experience, high inter-annotator agreement (IAA) is especially important for subjective labels or overlapping product classification categories.
Automation + human feedback
Pre-labeling with AI can speed things up, but humans must correct model errors and validate low-confidence predictions. A feedback loop between model outputs and annotators improves both labeled data quality and model performance over time.
This method works well for our team too. Label Your Data takes this hybrid, semi-automated approach to maintain high annotation accuracy even for domain-specific taxonomies and multilingual datasets.
At Meta and Magic Hour, pairing text with images helped solve tricky categorization problems—especially for new, creative products. Meta-learning allowed our models to adapt from just a few examples. We always start with a pilot loop to minimize manual annotation.
 CEO, Magic Hour
CEO, Magic Hour
Teams with in-house capacity often rely on a dedicated data annotation platform to manage task distribution, label versioning, and QA workflows at scale.
Evaluating Product Classification Models
Once your model is trained, don’t just look at top-line accuracy. Product classification operates in noisy, high-variance environments.
Misclassifications can hurt search, recommendations, and compliance, especially when rare or high-value categories are involved. Evaluation must go beyond aggregate metrics to reveal where and why errors occur.
Evaluation metrics for product classification models
To evaluate your model, pick metrics that reflect the real-world impact of errors:
| Metric | What It Measures | When to Use |
| Accuracy | Overall % of correct predictions | Valid only when classes are balanced |
| Precision | % of predicted class X that are correct | Useful when false positives are costly |
| Recall | % of actual class X that were found | Critical when missing a class has business impact |
| F1-Score | Trade-off between precision and recall | Best for imbalanced class distribution |
| Confusion Matrix | True vs. predicted class breakdown | Helps spot patterns of misclassification |
Many teams over-focus on accuracy alone. In practice, rare category performance, confusion patterns, and feedback from real users often reveal bigger issues. Some common product category classification methods include flat classifiers, hierarchical models, and zero-shot approaches.
Misclassifications are often tied to mislabeled or ambiguous training data. Track metric performance over time, especially after taxonomy or label changes.
Handling class imbalance
Real-world catalogs often have dominant categories (e.g., “T-shirts”) and underrepresented ones (“UV-protective hiking gear”). To address the imbalance dataset problem:
- Use stratified sampling in training and evaluation sets
- Consider weighted loss functions or over/undersampling strategies
- Evaluate per-class recall to ensure minority classes aren't ignored
Continuous evaluation and feedback
Model accuracy can degrade as new products are added or taxonomies change. Set up evaluation pipelines that include:
- Real-world test data and shadow deployments
- Annotation error audits to isolate labeling noise
- User feedback loops for correction and retraining
Our team supports full-cycle evaluation by combining labeling services with ongoing QA, making it easier to trace errors to their root cause, whether it’s in your data or your model logic.
Scaling Product Classification Across Catalogs and Regions

Product data classification gets exponentially harder at scale. As you expand across markets, product lines, and languages, your taxonomy balloons – and so does the complexity of maintaining consistent, accurate labels.
Multilingual and regional adaptation
Terms and categories vary widely across regions. For example, “trainers” in the UK are “sneakers” in the US. Misclassifying culturally specific or seasonal products leads to broken user experience and lost conversions.
To handle this:
- Train models on multilingual product data
- Maintain localized taxonomies or mapping layers
- Use annotators familiar with regional context to capture nuance
Label Your Data provides multilingual annotation teams who can disambiguate product data in over 55 languages, which is critical when globalizing your catalog.
Keeping datasets versioned and models fresh
As products get added, retired, or re-categorized, old training data becomes stale. Without proper versioning, retraining on outdated or inconsistent labels can introduce drift.
Best practices include:
- Dataset versioning tools (like DVC or LakeFS)
- Incremental retraining with updated labeled subsets
- Change logs to track taxonomy edits and relabeling needs
Adapting to seasonality and trends
Holiday editions, packaging updates, or region-specific SKUs require classification pipelines that handle flux gracefully. Models trained on past data may not generalize well to sudden category shifts.
Solutions:
- Incorporate recency-weighted data in training
- Use metadata like launch dates or regions during classification
- Set up alerting when new SKUs can’t be confidently labeled
When classifying at deeper levels of a taxonomy, product subcategory classification methods often require more training data per class and careful handling of label imbalance to avoid skewed predictions.
Compliance and Regulatory Product Classification
In regulated industries, product classification is a legal requirement. Errors here can delay shipments, violate safety laws, or block your product from entering a market.
This is especially critical in:
- Medical devices, which must align with the FDA product classification database. Your model should map products to official FDA device codes, not internal labels only.
- Industrial goods, where NAICS/NAPCS codes are required for customs declarations, procurement systems, and industry reporting.
- Cross-border ecommerce, where HS codes (Harmonized System) determine duties and compliance rules. Misclassification can lead to fines.
Standard ML models can’t learn these mappings out of the box. They require expert-verified labels aligned with real taxonomies.
We at Label Your Data work with domain experts to annotate data against official classification systems like FDA, NAICS, and HS, helping you build audit-ready datasets that regulators and procurement systems actually accept. Whether it’s medical device categories or industry codes, our workflows ensure compliance doesn’t lag behind your ML automation.
Key Challenges in Product Data Classification
Even with a solid pipeline, product data classification can fail without addressing these persistent issues.
Data quality and label noise
Ambiguous titles, inconsistent descriptions, and mismatched attributes introduce noise that weakens model accuracy. Without clear class definitions and human oversight, automated labeling compounds these errors.
Combining structured guidelines, strong QA workflows, and slice-based audits helps detect and correct low-quality annotations early.
Bias and representation gaps
Overrepresented product types or dominant languages skew the model toward majority classes. Niche or region-specific items often suffer from poor classification, especially in multilingual catalogs.
Monitoring dataset balance and evaluating across segments, like geography or brand tier, is essential to avoid blind spots in production.
Cost and scalability
Manual labeling delivers precision, but it’s resource-intensive. Pure automation fails on edge cases and low-quality inputs. The challenge is finding a sustainable blend of model pre-labeling and human review that can keep up with catalog growth and update frequency. This makes data annotation pricing a critical factor when scaling across languages or taxonomies.
Targeted human-in-the-loop validation on risky or rare classes helps scale without compromising accuracy or burning budget.
The most effective pipeline I’ve built combined transformer models with hierarchical classification. We used contrastive learning across text and image embeddings, then trained a classifier aligned to semantic distances. Active learning helped surface edge cases for human review, closing the loop on accuracy and adaptability.
 Co-Founder & CEO, AIScreen Digital Signage Software
Co-Founder & CEO, AIScreen Digital Signage Software
Best Practices for Building Your Product Classification Pipeline
A scalable classification system starts with better data planning and feedback loops. These practices help ML teams avoid common failure points and move faster toward production-grade performance.
Audit your data sources and licensing
Check for inconsistent formats, missing metadata, or licensing issues before ingestion. Use schema validators and version trackers to flag anomalies early.
Benchmark before full-scale labeling
Open (public) machine learning datasets can help test your model architecture or label schema. Start small to catch edge cases before investing in full annotation cycles.
Use hybrid data strategies
Combine in-house data, third-party sources, and synthetic data augmentation to improve representation across product classification categories and edge conditions.
Maintain versioning
Treat datasets like code and version everything with tools like DVC or LakeFS. This enables reproducibility, rollback, and parallel experimentation across teams.
Track taxonomy and metadata updates
As product lines evolve, category definitions change. Keep a changelog of class names, ontology edits, and attribute mappings so models stay aligned with business logic.
These steps help build pipelines that evolve with your catalog, rather than breaking every time taxonomy or inputs shift. But you should keep in mind that the success of any product classification system depends less on complex models and more on high-quality, consistently labeled training data.
As taxonomies grow, languages multiply, and catalog updates accelerate, annotation becomes both the foundation and bottleneck of ML performance. By investing early in structured annotation workflows, feedback loops, and reliable QA practices, ML teams can scale classification pipelines with accuracy and stability.
About Label Your Data
If you choose to delegate product data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is product classification in machine learning?
Product classification in machine learning means assigning products to predefined categories using data such as titles, descriptions, images, and structured attributes. It’s a supervised learning task where labeled examples train a model to generalize to new, unseen items.
What does product classification mean for ecommerce?
Ecommerce product data classification directly affects search relevance, recommendation quality, inventory tracking, and analytics accuracy. Misclassifications can break navigation, distort metrics, and reduce conversion, especially across large, multilingual, or poorly structured catalogs.
What kind of data is used in product classification models?
Models typically use a mix of text (titles, descriptions, and product review classification categories), images, and structured metadata (brand, size, price, dimensions). Multimodal setups, like combining image and text inputs, are common in modern classification pipelines.
What are the 4 types of classification?
In machine learning, the four main types of classification tasks are binary classification, multiclass classification, multilabel classification, and hierarchical classification.
Each serves a different product catalog need, such as detecting single vs. multiple tags or modeling nested category trees. Platforms that support image recognition alongside text labeling are especially useful when classifying SKUs with minimal metadata.
How does human-in-the-loop improve product classification?
Humans refine edge cases, correct model outputs, and validate tricky product classification categories. This feedback is especially important in long-tail or domain-specific taxonomies where labeled data is sparse.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.