Human Annotation: 3 Edge Cases Automation Misses

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Fully Automated Labeling Still Fails in Production
- How Human Annotation Fits the Modern ML Pipeline
- Edge Case 1: Contextual or Ambiguous Annotations that Models Misread
- Edge Case 2: Rare or Out-of-Distribution Data Automation Can’t Handle
- Edge Case 3: Domain-Specific or Fine-Grained Labels that Require Expertise
- How to Combine Automation with Human Annotation in QA Workflows
- About Label Your Data
- FAQ

TL;DR
- Automation speeds up annotation but still collapses under real-world complexity: missing subtle context, domain nuance, and rare data distributions.
- Human annotation closes that gap, validating ambiguous outputs, refining datasets, and preventing model drift.
- In tasks like image recognition or LLM fine-tuning, domain experts correct edge cases that automation can’t interpret or even detect.
- The most reliable data annotation platforms now use hybrid pipelines: pre-labeling with automation, then human verification based on confidence thresholds.
- Human-in-the-loop systems don’t slow ML teams down; they make model deployment auditable, reproducible, and resilient in production.
Why Fully Automated Labeling Still Fails in Production
Fully automated labeling remains unreliable in real-world ML pipelines because it amplifies mistakes, lacks interpretability, and struggles with ambiguous data.
Despite advances in foundation models and auto-annotation tools, AI-driven labeling continues to break under real-world conditions. Models trained without human oversight tend to misread context, propagate early labeling errors, and lose auditability across iterations. In production, these gaps surface as performance drift, unseen edge cases, and costly debugging cycles.
Recent events, such as xAI’s decision to lay off 500 generalist annotators while hiring PhDs and domain experts, show that automation can’t replace specialized human insight.
The “annotation is dead” debate misses the point: human annotation hasn’t disappeared – it has evolved. Human input now focuses on the parts automation can’t see, such as:
- Contextual nuance
- Domain-specific accuracy
- Continuous feedback within model evaluation loops
Even the best human-powered data annotation companies continue to outperform automated systems on ambiguous or safety-critical data. While purely automated labeling pipelines scale fast, human-powered data annotation service providers ensure that edge cases are caught before they break production pipelines.
Without humans validating context, catching rare cases, and guiding model retraining, errors multiply silently – until production fails.
How Human Annotation Fits the Modern ML Pipeline
Even the most advanced machine learning algorithm struggles to interpret context, ambiguity, or unseen cases without human oversight. That’s why it’s a common practice for a data annotation company to integrate human QA layers into their pipelines. Automation scales speed, but human powered data annotation services ensure reliability where precision and context matter most.
Yet, human data annotation has shifted from bulk labeling toward strategic intervention in MLOps workflows. Rather than labeling millions of samples manually, humans now verify outputs, resolve ambiguity, and maintain model reliability as part of a continuous feedback system. This evolution reflects the rise of hybrid pipelines where automation handles scale, and human experts safeguard accuracy.
Modern roles in human annotation workflows
Human now plays a focused, high-impact role in modern ML pipelines:
- Model QA: Humans audit automated labels, catching subtle misclassifications before they affect training or deployment.
- Edge-Case Triage: Annotators review low-confidence or out-of-distribution samples that automation can’t classify reliably.
- Feedback Loop Integration: Human reviews feed directly into retraining cycles, improving model alignment over time.
- RLHF-Style Evaluation: In LLMs and multimodal systems, human ratings refine response quality and reduce drift.
Together, these roles create a human-in-the-loop architecture that strengthens reliability without slowing automation. Annotation has become a form of continuous quality assurance, not a bottleneck.
Edge cases often slip through when data looks normal but hides subtle patterns — like mislabeled traffic mimicking a threat. The most dangerous failures come from systems that err with confidence. Automate what’s safe, but flag low-confidence or high-risk outputs for expert review. Combining model disagreement metrics with human spot-checks keeps accuracy high and builds stakeholder trust.

 CEO | IT & Cybersecurity Expert, Terminal B
CEO | IT & Cybersecurity Expert, Terminal B
In today’s MLOps setups, human-in-the-loop annotation for LLM training ensures context-aware feedback and prevents model drift. These hybrid workflows bridge automation and expert oversight, core to the best human annotation services for AI, where quality control is embedded throughout the data lifecycle.
ML teams can also use a hybrid data annotation platform that blends automation with human verification. Instead of mass labeling, annotators verify edge cases and refine model outputs. Understanding data annotation pricing helps teams plan scalable, cost-efficient labeling workflows without sacrificing accuracy.
Edge Case 1: Contextual or Ambiguous Annotations that Models Misread
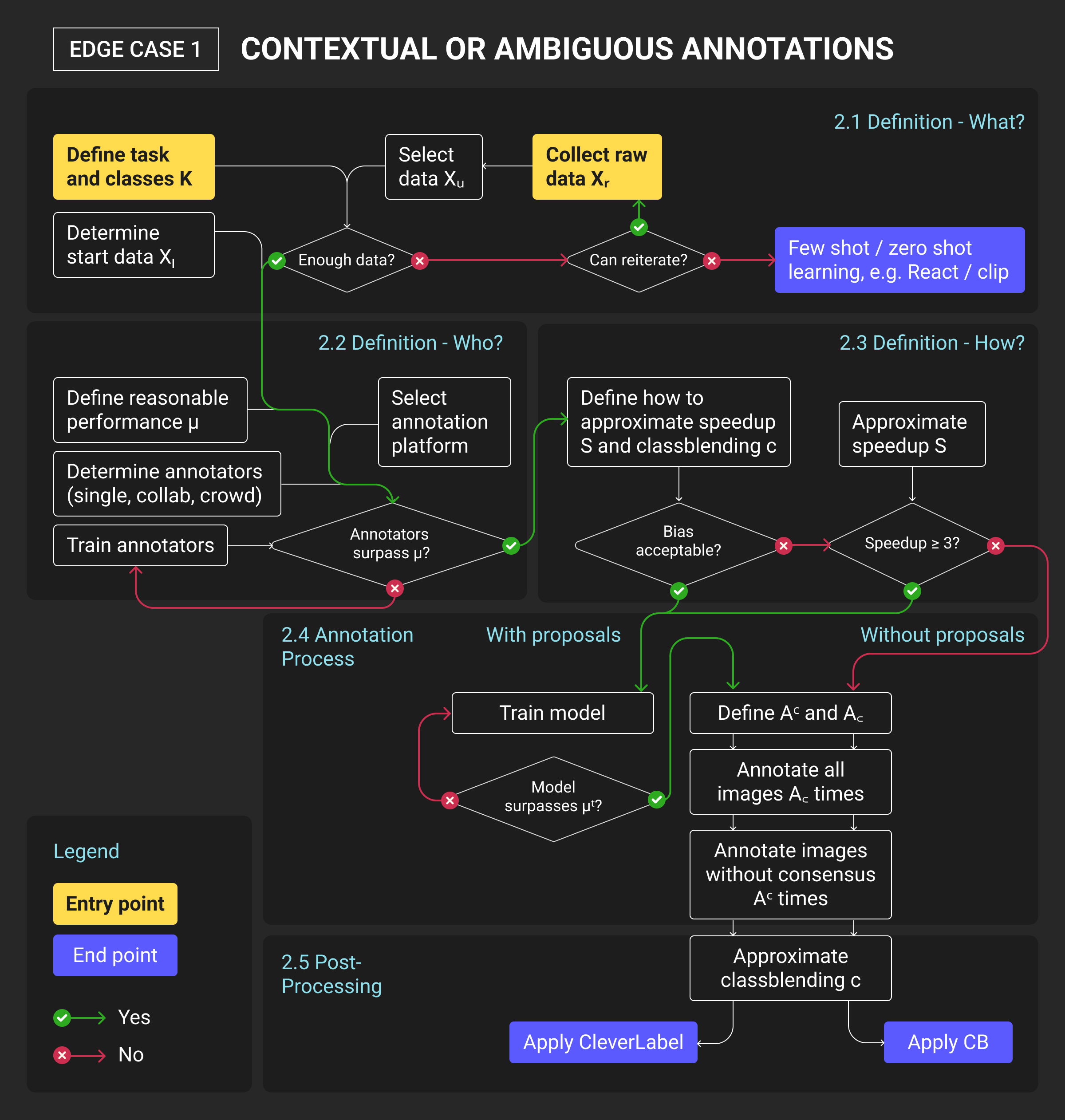
Automated systems often struggle when meaning depends on context.
Even advanced models can misinterpret sarcasm, irony, or ambiguous cues because they rely on statistical patterns rather than understanding intent. In computer vision tasks, this problem appears in scenes with overlapping objects, reflections, or gestures that require human interpretation with human-in-the-loop data annotation.
Why automation misses context
Automated labeling relies on pattern recognition. A sentiment model might flag “great, just what I needed” as positive, missing the sarcasm. An image recognition model could label a plastic toy gun as a weapon. These context failures come from the same issue: machines interpret form, not intent. Human annotators, however, bring cultural grounding and pragmatic understanding that keeps datasets semantically aligned with real-world meaning.
Where human annotation add value
Human annotators step in where automation fails – interpreting tone, intent, and contextual meaning. They catch subtle distinctions that determine whether a label is correct or misleading, ensuring that training data reflects real-world usage rather than surface-level signals. This process prevents small semantic errors from snowballing into major model biases and maintains reliability in production pipelines.
Models can’t detect contextual contradictions, double meanings, or culturally specific expressions. Idioms, humor, or domain-specific terminology still require human reasoning to resolve. Left unchecked, these errors propagate into model weights, leading to systemic bias or misclassification that’s hard to detect later in production.
This is where human feedback annotation for LLMs becomes essential. Humans interpret tone, semantics, and cultural nuance that models can’t fully capture. Such human in the loop annotation remains the safeguard that grounds data in human context.
Edge Case 2: Rare or Out-of-Distribution Data Automation Can’t Handle

Automated labeling systems fail most noticeably when they encounter rare events or out-of-distribution samples. These are the corner cases that don’t appear often enough in training data for a model to generalize.
In production, they surface as unpredictable behaviors, false positives, or total model collapse when facing unfamiliar inputs.
Why rare data breaks automated annotation
Pre-labeling models and foundation-based annotators depend on learned patterns. When they meet an example outside that learned distribution, an unusual object, a new language variant, a rare medical anomaly, they have no frame of reference. The result is a high-confidence wrong label, which is far more dangerous for downstream systems. These low-frequency errors slip through automated QA because the model doesn’t recognize its own uncertainty.
How human QA restores reliability
Human experts excel at identifying and reasoning about anomalies. In edge cases such as detecting cracks in novel materials, interpreting low-quality sensor data, or labeling unique satellite imagery, human reviewers catch what automation misses. Their judgment helps maintain dataset integrity and supports model retraining under distribution shift conditions – a frequent cause of degraded performance in live environments.
Out-of-distribution data is inevitable in real-world ML pipelines. Automation can handle the predictable, but only human review can recognize when “unknown unknowns” appear – preventing silent model failures long before they reach production.
Edge Case 3: Domain-Specific or Fine-Grained Labels that Require Expertise
Automated annotation systems struggle when tasks demand expert domain knowledge rather than ML pattern recognition. Models can identify shapes, objects, or tone, but they can’t interpret meaning that depends on specialized context, such as diagnosing a rare medical scan, labeling contractual clauses, or identifying micro-defects in manufacturing imagery.
Why domain knowledge still beats automation
Foundation models perform well on general data but lack the precision needed for expert tasks. For example, a model trained on medical imaging may detect a tumor but miss subtle indicators that only a radiologist would catch. The same issue appears in legal NLP, where an AI might tag “termination” clauses inconsistently across contract types. These mistakes accumulate and skew the dataset; small errors that have significant real-world consequences.
Where humans close the precision gap
Subject-matter annotators ensure that data reflects expert reasoning, not just pattern matching. In specialized domains, they validate edge interpretations, maintain labeling consistency, and provide feedback loops that guide model retraining. This process keeps machine learning datasets both accurate and explainable, allowing downstream ML models to operate under regulatory or safety-critical conditions.
Automation scales annotation; human experts safeguard its precision. In highly regulated or safety-dependent industries, like healthcare or MilTech, the cost of missing nuance is higher than the cost of human oversight.
We found AI tools miss context-dependent behavior that looks identical frame by frame. Our system once mistook a food-truck crowd for an aggressive mob — both had the same motion patterns. Human reviewers caught these by correlating multiple camera feeds over time. What’s 'normal' in one feed becomes suspicious across zones. Edge cases hide in context, not pixels.
 Founder, DuckView Systems
Founder, DuckView Systems
Even in advanced LLM fine tuning workflows, automation can’t fully replace human domain experts. Different types of LLMs require distinct annotation strategies depending on their training scope and downstream task.
LLM data annotation often includes human validation to maintain consistency and precision across specialized datasets, preventing model hallucinations and semantic drift.
How to Combine Automation with Human Annotation in QA Workflows
Modern ML pipelines rarely rely entirely on automation or human annotation; they combine both. The most effective teams build hybrid workflows that use automation for scale and humans for context, judgment, and verification. The goal is to ensure each label reflects both model efficiency and human reasoning.
How hybrid annotation pipelines work
A common setup looks like this:
- Pre-labeling with automation: Models generate initial annotations using confidence scores.
- Confidence-based routing: Samples below a defined threshold go to human reviewers.
- Human QA and correction: Annotators verify or adjust labels, resolving ambiguity.
- Feedback loop: Corrections feed back into model retraining to improve next-round accuracy.
This approach keeps annotation fast without sacrificing quality. By quantifying confidence thresholds and routing intelligently, teams can reduce human review volume while preserving dataset integrity.
Measuring ROI and QA impact
To evaluate the success of hybrid workflows, ML teams measure metrics like annotation agreement rate, review turnaround time, and model improvement per human-hour. These metrics help decide when automation is “good enough” and where human oversight adds the most value.
Building a reliable hybrid loop
Effective pipelines treat human feedback as continuous, not one-time. In practice, this means running ongoing QA cycles that mirror MLOps principles: retrain, validate, and redeploy models with human-reviewed data as the foundation. The outcome is a labeling process that scales efficiently while maintaining interpretability and trust.
Hybrid workflows represent the next stage of human-in-the-loop annotation, where automation accelerates throughput, and human QA ensures models learn the right lessons, not just the fast ones.
About Label Your Data
If you choose to delegate data annotation to human experts, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is a human annotation?
Human annotation is when trained individuals manually review, label, or verify data used to train machine learning models. Unlike automated systems, humans bring contextual understanding and ensure accuracy in complex or ambiguous datasets.
What is an example of annotation?
An example is labeling objects in images, like identifying pedestrians, vehicles, or traffic signs for autonomous driving systems. Another is tagging emotions or topics in text data to train sentiment analysis models.
What is an annotation person?
An annotation person, or data annotator, labels or verifies datasets for AI training. Depending on the project, they may specialize in areas like medical imagery, legal text, or geospatial data.
Why is human annotation still important in AI?
Human annotation ensures context-aware labeling and reduces model bias. While automation handles scale, human insight corrects errors that algorithms miss, improving reliability in real-world applications.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.