GIS Data Collection: Building Datasets for Spatial ML

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What ML Teams Actually Need from GIS Data Collection
- Core GIS Data Collection Methods (and How They Affect ML Outcomes)
- From Raw GIS to ML-Ready: Key Preparation Steps
- How GIS Data Collection Impacts Model Design
- Should You Outsource GIS Data Collection or Use Existing Sources?
- Common GIS Data Collection Pitfalls (and How to Avoid Them)
- Best Practices for ML-Ready GIS Datasets
- About Label Your Data
- FAQ

TL;DR
- Most GIS datasets weren’t built for machine learning; they’re often too coarse, inconsistent, or unlabeled.
- Grabbing shapefiles isn’t enough. You’ll run into projection issues, missing labels, and timelines that don’t match.
- Making GIS data ML-ready means crafting spatially-aware features that can be interpreted by models designed for geospatial inputs.
- For high-stakes projects or overlooked regions, custom collection can make a huge difference.
- Depending on your use case, combining satellite images, field surveys, and crowdsourced maps can improve accuracy and coverage.
What ML Teams Actually Need from GIS Data Collection
The answer varies from project to project. One common factor is that GIS field data collection in machine learning can be difficult because the tools are built for maps rather than the kinds of spatial models used in machine learning, like CNNs or segmentation architectures.
This makes it harder to annotate and feed into spatial ML architectures such as CNNs, U-Nets, or temporal models like ConvLSTM.
You can hire data collection services or look for a solid GIS data collection software to overcome this issue. Of course, once you have the information, you need to put it in a format that your machine learning algorithm can use, including projection alignment, spatial labeling (e.g., polygons or masks), and metadata enrichment.
That means using proper image recognition and data annotation techniques.
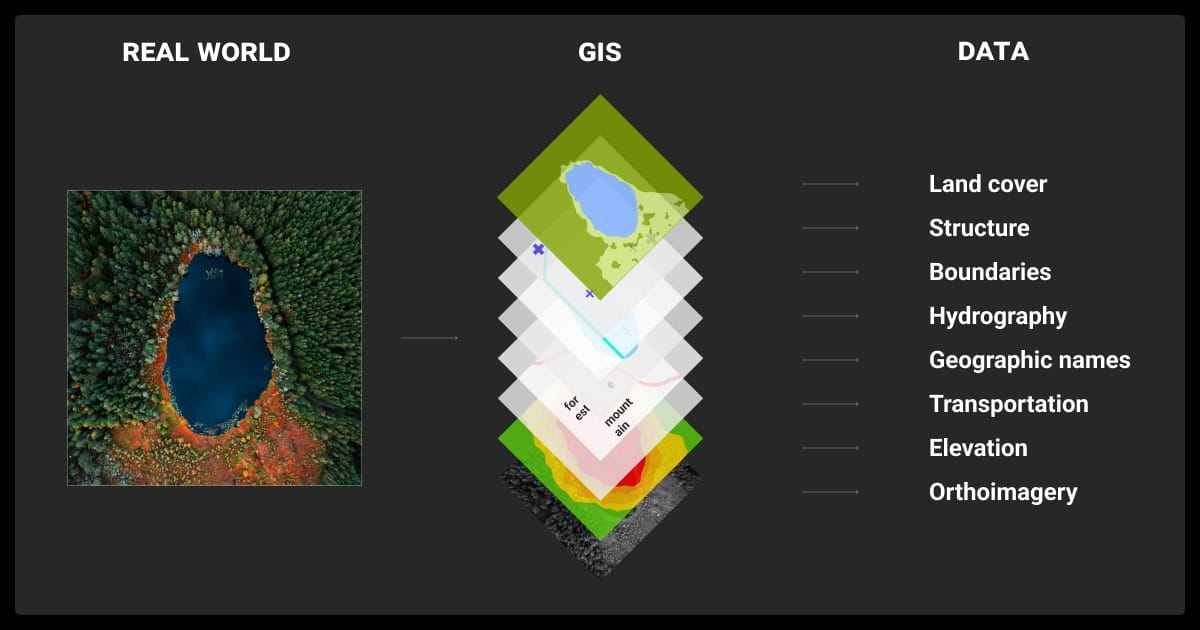
Why Off-the-Shelf Geospatial Datasets Might Fall Short
A lot of GIS data was built for maps, not models. That disconnect shows up fast when you try to plug it into a spatial ML pipeline, for example, segmentation or classification, or LLM fine tuning pipeline.
You’ll see problems like:
- Jumbled formats: Mixing rasters and vectors with mismatched projections or incompatible resolutions.
- Zoom mismatches: Labels for a city paired with imagery at 10-meter resolution.
- Coverage gaps: Detailed downtown maps but blank spots in rural areas.
- Bare-bones labels: Using “road” as a polygon isn’t helpful unless we know what kind of road, its width, or its surface.
Key Data Qualities for Spatial ML
To actually train useful models, you need more than coordinates on a map. Look for:
- Precise labels: Polygons for land cover, boxes for detection, or pixel masks for segmentation.
- Matched resolution: Imagery and labels should line up in scale and projection.
- Complete metadata: Timestamps, sources, CRS info, labeling methods.
- Clear licenses: Especially if you’re building a product.
ML Tasks That Depend on GIS Data Collection
Some tasks simply won’t work without solid spatial inputs. For example:
- Land cover classification: Figuring out what’s forest, farmland, or pavement.
- Infrastructure segmentation: Detecting roads, railways, or utility lines from imagery.
- Spatial forecasting: Predicting crop yields, traffic, or flood risks based on location.
- Address normalization and geocoding: Tying structured data to physical locations.
If the data’s outdated or misaligned, the model’s already off to a bad start.
Want to go deeper? Check out “The Guide to Geospatial Annotation” for hands-on tips, tools, and real-world examples.
Core GIS Data Collection Methods (and How They Affect ML Outcomes)

Using the right GIS data collection techniques is one of the most important factors in how your model performs. A data annotation company may use a combination of techniques to supplement their machine learning dataset. Techniques involve survey data collection, GIS mobile data collection, and others. Let’s learn more.
Remote Sensing
| Method | Cost | Resolution | Update Frequency | Weather Limits | ML Implications |
| Satellite | Med–High | 10m to 30cm | Weekly to monthly | Yes | Good for scale, but watch out for clouds and low resolution. |
| Drone | High per area | Sub-10cm | On-demand | Minimal | Great for fine-grained tasks like monitoring crops. |
| Aerial | High | 30cm–1m | Seasonal or ad-hoc | Variable | A nice middle ground for cities or infrastructure mapping. |
Field Surveys and GPS Mapping
GNSS (including GPS, GLONASS, and Galileo) tools let you collect with centimeter-level accuracy. It’s gold-standard data, especially for validation, but slow and expensive. These GIS data collection tools are best reserved for small areas or quality checks.
Volunteered Geographic Info (VGI) and Crowdsourcing
Platforms like OpenStreetMap and Mapillary (which focuses on street-level imagery) give you broad coverage and frequent updates. But the data quality can be spotty, so treat these sources as supplements—not your main source.
Public/Archived GIS Datasets
You’ll find good baselines for your GIS data collection app from sources like USGS, ESA, or government portals, especially things like elevation models or flood zones. They’re often free, but usually need cleaning and reformatting before they’re ML-ready.
Among the best [methods] are Real-Time Kinematic (RTK) GPS, Differential GPS (DGPS), and drone-based LiDAR... High-accuracy tools like RTK GPS units and LiDAR-equipped drones are expensive... Many teams are turning to hybrid approaches—using consumer-grade mobile devices with external Bluetooth GNSS receivers—to improve accuracy without the full cost.

 CEO, OutSail
CEO, OutSail
From Raw GIS to ML-Ready: Key Preparation Steps
Now let’s look at the next stage, geospatial annotation and LLM data labeling.
Data Cleaning Challenges with Spatial Inputs
No matter what data collection tools you use, spatial data brings its own set of headaches. You might run into:
- Mismatched projections: Layers look aligned on screen but fall apart in joins.
- Broken geometries: Self-intersections or gaps that crash your pipeline.
- Sparse attributes: Nulls or inconsistent values that kill batch jobs.
You’ll get cozy with tools like GDAL, ogr2ogr, and GeoPandas fast.
Even when projections match, resolution mismatches can cause issues. Pairing 10 m imagery with 30 cm labels may blur features or create aliasing. Always check visually and apply resolution-aware preprocessing.
Annotating for Supervised Models
GIS enhanced data collection is only the first step. You now need to label it, which isn’t as simple as drawing boxes. You’re dealing with polygons, polylines, overlapping classes, and time-based context. That same wetland might also be a floodplain and a conservation zone. Ontologies can get complex; many datasets involve hierarchical or multi-label structures.
Tools like QGIS, Labelbox, or Picterra help, but human judgment matters just as much here. If you’re battling to get through this stage, you can hire GIS labeling services. You can start by using AI to pre-label the data to bring down the overall data annotation pricing. You can then hire data annotation services to check the results and deal with edge cases.
Feature Engineering with Spatial Context
Spatial models thrive on context. Some of the most useful features are derived:
- Distance to roads or rivers
- NDVI averages over an area
- Elevation or slope from DEMs
- Zonal statistics or spatial joins that pull in nearby attributes
These often beat raw pixels hands down.
Temporal and Multi-Resolution Alignment
Things change fast. Roads get paved, trees are cleared, flood zones shift. To stay accurate, align everything in time:
- Sync imagery and labels by date
- Match revisit rates between sources
- Resample layers to a consistent resolution
- Harmonize multi-sensor inputs (e.g., optical and SAR imagery)
If you’re using models like ConvLSTMs or temporal CNNs, this alignment isn’t optional—it’s mission-critical.
Some teams are enhancing real-time kinematic (RTK) GNSS systems with smart failover technologies... These systems automatically switch to post-processed kinematic (PPK) or base station corrections. This ensures consistent, high-precision data collection without interruption—even in challenging terrains.
 Operations Manager, Clear View Building Services
Operations Manager, Clear View Building Services
How GIS Data Collection Impacts Model Design

We have to look at the settings on your GIS field data collection software, like resolution, memory use, and other aspects. You have to balance great resolution and computing power. The higher the former, the more of the latter you need.
You also have to make sure that your GIS data collection device can capture the level of detail your spatial ML or video analytics models require. If you’re using GIS cloud mobile data collection, does the system have enough bandwidth to store raw image or video data?
If you’re using data collection automation tools, you need to make sure they capture metadata, location precision, and the class-level detail your application demands.
How Resolution Impacts Model Architecture
The resolution you choose affects tile size, model depth, memory use, you name it. A 512x512 tile at 10m covers over 5 km². Shrink those pixels and you gain detail but pay the price in GPU and RAM. Choose wisely. Tiled inference may help when working with high-resolution inputs.
Spatial Bias and Generalization Risk
Train on highways in the U.S., and your model may choke on dirt roads in Kenya. Data often skews urban or Western. Materials, layouts, vegetation — all of it varies.
To fight bias:
- Use spatial cross-validation
- Try domain adaptation
- Augment with rotated or seasonally shifted imagery
- Explore meta-learning or fine-tuning across diverse geographies
File Format and Memory Considerations
GIS data gets big, fast. Format choices matter:
- Use GeoTIFF or Cloud Optimized GeoTIFF (COG) for imagery
- Shapefiles or GeoJSON for vector features
- MBTiles for fast delivery, but avoid them for editing
- Consider GeoParquet for large vector tables
Should You Outsource GIS Data Collection or Use Existing Sources?
That’s a good question and the answer depends on whether or not you
Public vs. Custom vs. Crowdsourced
| Source Type | Coverage | Label Quality | Cost | Best Use |
| Public | Medium–High | Medium | Free | Basemaps, elevation, general features |
| Custom | Targeted | High | Expensive | Critical ML projects, new geographies |
| Crowdsourced | Uneven | Low–Medium | Low | Bootstrapping labels, pretraining |
When Custom GIS Data Collection Is Worth It
Sometimes you’ve squeezed all the juice out of existing data. That’s when it’s worth collecting your own. Say you’re training a model to detect power lines in Sub-Saharan Africa—good luck finding public data. You’ll need drone imagery and expert labels to get anything usable.
Hybrid Strategies
Often, the best strategy is a mix. Start with free sources like Sentinel or OpenStreetMap. Hire pros to annotate high-priority areas. Use field surveys to validate. And keep updating the model as new data comes in. It’s all about trade-offs: speed, cost, and accuracy.
Teams prioritize the highest-precision tools only where they’re absolutely necessary and use lower-cost mobile mapping or satellite data to fill in broader contextual areas. That mix-and-match strategy is what’s making big projects viable without blowing out budgets.
 Founder & Principal Software Architect, Cirrus Bridge
Founder & Principal Software Architect, Cirrus Bridge
Common GIS Data Collection Pitfalls (and How to Avoid Them)
These are common pitfalls with any kind of mobile GIS data collection.
Label Noise and Boundary Errors
Blurry edges, inconsistent class rules, and overlaps all cause noisy labels. Use validation sets, quality checks, and active learning to stay ahead of it.
Class imbalance is common—urban features often dominate, while rare classes like trails or dirt roads are underrepresented. This skews results unless you apply techniques like oversampling, class-aware loss, or hard-negative mining.
Misaligned Projections and Layers
Even experienced teams get burned here. Your imagery might be in EPSG:4326 and your labels in EPSG:3857. They’ll look fine until your model starts misfiring. Standardize everything and double-check alignment visually.
Ethical and Legal Issues
High-res imagery can capture more than you planned: faces, license plates, even military sites. Licensing can also get murky fast. Always scrub sensitive info, anonymize personal data, and check export controls or data-sharing restrictions in your region.
Best Practices for ML-Ready GIS Datasets
Define a Label Schema Early
Don’t wing it. Define your classes before annotation starts. Spatial data has layers — literally. A “building” might also be a “school,” and a “road” might be paved, gravel, or just a trail. Nail down your schema early and make room for multi-class hierarchies.
Version, Validate, and Document Everything
Trust me — future you will thank you. Track:
- Sources, dates, and projections
- Tools used for annotation or cleaning
- Data versions (DVC or MLflow can help)
- Use STAC metadata when managing large raster catalogs
Good metadata saves projects.
Automate Your Preprocessing Pipeline
Manual steps don’t scale. Set up:
- GDAL for conversions and reprojection
- GeoPandas for vector wrangling
- Rasterio for raster tasks
- Airflow stitch it all together
- Tippecanoe for vector tiling
Automation keeps things consistent across datasets—and that consistency pays off.
Don’t wing it. Define your classes before annotation starts. Spatial data has layers—literally. A “building” might also be a “school,” and a “road” might be paved, gravel, or just a trail. Nail down your schema early.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is data collection in GIS?
It’s the process of gathering spatial information from various sources, like satellites, drones, field surveys, or crowdsourced platforms, to build datasets for mapping, analysis, or machine learning. The goal is to capture location-based features in a format your GIS tools and ML models can actually use.
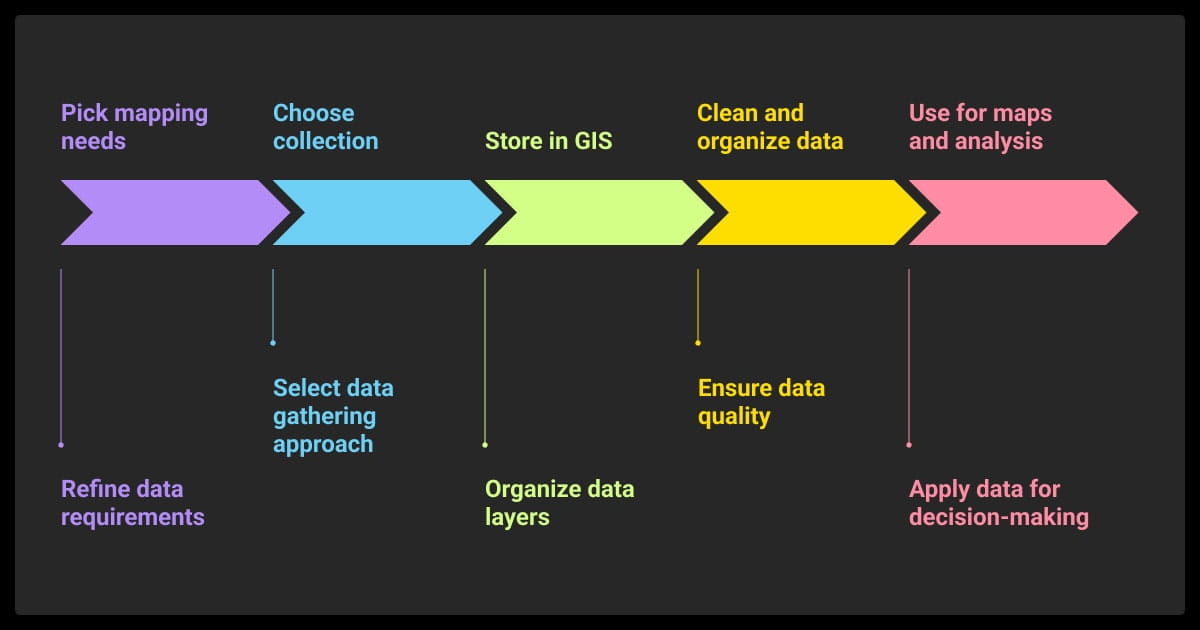
What are the stages of GIS data collection?
You start by choosing your data sources (remote sensing, field mapping, etc.), then clean and align the inputs (projections, formats, metadata). Next, you georeference and label the data using polygons, points, or masks. Finally, you prep everything for ML, ensuring it’s consistent, annotated, and compatible with your model’s input requirements.
How do you gather data in GIS?
You can capture it directly using GNSS receivers or drones, or pull it from remote sensing platforms like Sentinel or Landsat. Other options include scanning paper maps, digitizing field notes, or extracting from platforms like OpenStreetMap. The method depends on your budget, accuracy needs, and project scope.
What two kinds of data does GIS collect?
Raster and vector. Raster data includes things like satellite imagery or elevation models — basically grids of pixels. Vector data includes points, lines, and polygons that represent things like trees, roads, or land parcels. Most projects need both types to give spatial context and precision.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.