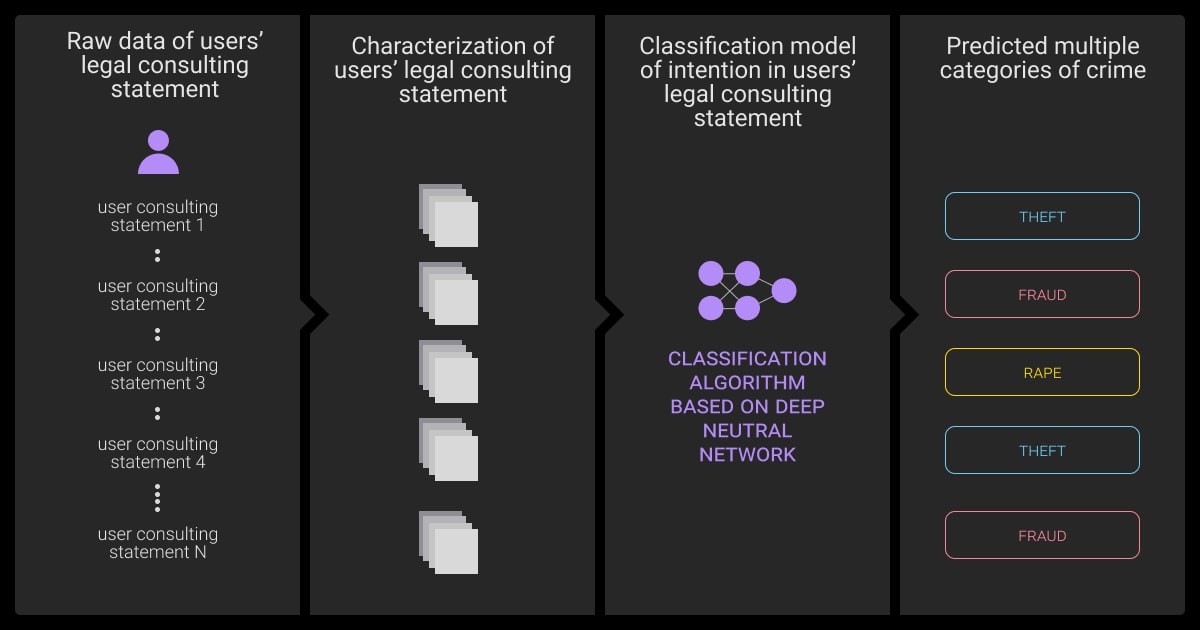
Intent Classification: Techniques for NLP Models

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Intent Classification in NLP?
- Top Intent Classification Methods
- Building an Intent Classification Pipeline
- How to Improve Intent Classification Performance
- Tools and Frameworks for Intent Classification
- Intent Classification in Production: Use Cases
- Fine-Tuning vs. LLMs for Intent Classification
- About Label Your Data
- FAQ

TL;DR
- Intent classification assigns user input to a specific intent label; core to chatbots, virtual assistants, and support automation.
- Rule-based and ML methods are fast and low-cost; transformers boost accuracy with labeled data; LLMs enable quick prototyping via prompts.
- Transformers like BERT require labeled training data and GPU resources; LLMs work zero-shot but cost more to run and control.
- A reliable pipeline covers labeling, preprocessing, model training, evaluation on real data, and ongoing monitoring.
- Boost results with data augmentation, multi-intent support, ambiguity handling, and active learning for continuous improvement.
What Is Intent Classification in NLP?
Intent classification is the task of identifying a user’s goal based on their text input by assigning it to a predefined intent label, such as `reset_password` or `track_order`.
Say someone types, “I need to reset my password.” The system needs to recognize that this isn’t a casual chat or a new order, it’s a password reset request. That’s where NLP techniques come in; intent classification uses them to process free-form text and assign it to a predefined label.
In practice, this powers:
- Chatbots and virtual assistants
- Command parsing in voice interfaces
- Triage systems for support tickets
- Routing in call centers or CRMs
The typical input is a raw user message. The output is a single intent label, but it can be more than one.
It seems simple, but real-world queries are messy. People make mistakes and typos, they use slang and sarcasm or domain-specific phrasing. This means that different types of LLMs must be able to handle nuance.
Top Intent Classification Methods
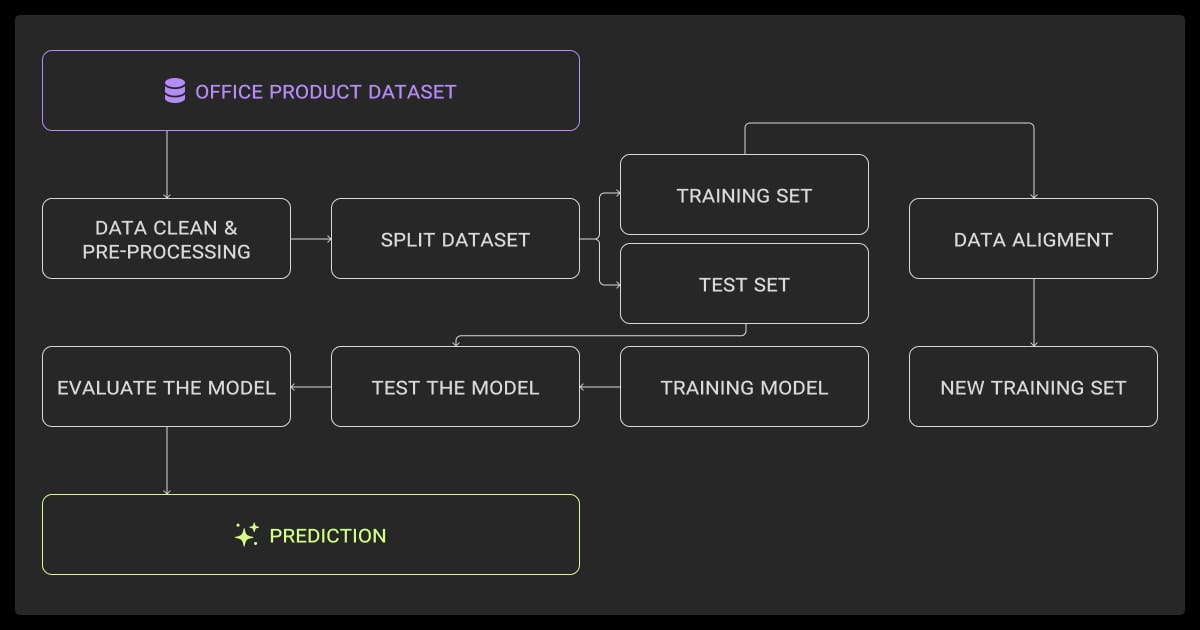
Over time, we’ve gone from hard-coded scripts to flexible, self-adapting models. Each method has its sweet spot.
Rule-Based and Pattern Matching
If you’re spinning up a quick demo or working in a tightly scoped domain, rule-based systems are still useful. You define intents with regex patterns or keyword lists. For example:
INTENT: ORDER_TRACKING
Patterns: “where is my order”, “track package”, “order status”
This is great for prototypes or legacy systems. But brittle. One slight phrasing change like, “Can you tell me if my stuff shipped?” and intent classification fails.
Classical ML Models
These were the workhorses before transformers took over. You extract features like TF-IDF, n-grams, POS tags, then feed them into a classifier like Support Vector Machines or Random Forests. Other commonly used models include logistic regression and Naive Bayes, especially when feature sets are sparse and interpretable.
Pros:
- Lightweight
- Easy to debug
- Good for smaller datasets
Cons:
- Need manual feature engineering
- Don’t generalize as well to messy text
They still have their place if you need fast inference in constrained environments like with embedded systems, edge devices.
Fine-Tuned Transformers
Using BERT for intent classification is the modern go-to for production NLP. You take a pretrained model like BERT, add a linear classification layer on top, and fine-tune it with your labeled dataset. Most models perform sentence-level classification by using the output from the [CLS] token, which captures the aggregated meaning of the entire input sequence.
LLM-Based Models
Sometimes you don’t have labeled data. Or you want to test a new intent quickly. This is where ChatGPT intent classification or GPT-style models shine.
You can prompt them like this:
“Given the user query ‘I forgot my password,’ classify the intent as one of: [reset_password, billing_question, order_tracking]”
Even better, LLMs can suggest new chatbot intent classification intent categories based on real queries, which is great for discovery. The downside is that you face cost, latency, and lower consistency issues if you don’t constrain the outputs carefully.
To improve reliability, few-shot examples and structured prompts (e.g., JSON format or strict label choices) are often used.
Why does BERT intent classification work?
It:
- Captures deep semantic structure
- Learns contextual meaning, for example “apple” the fruit vs. the brand
- Scales well with more data
You’ll need decent GPU resources and enough annotated samples, but the jump in accuracy is usually worth it. The better your intent classification dataset, the better the results.
Don’t have the time for good data annotation? It might be time to consider hiring data annotation services. They not only know how to label data for ML projects, image recognition, and document classification, they can do so far more quickly than most in-house teams.
Building an Intent Classification Pipeline
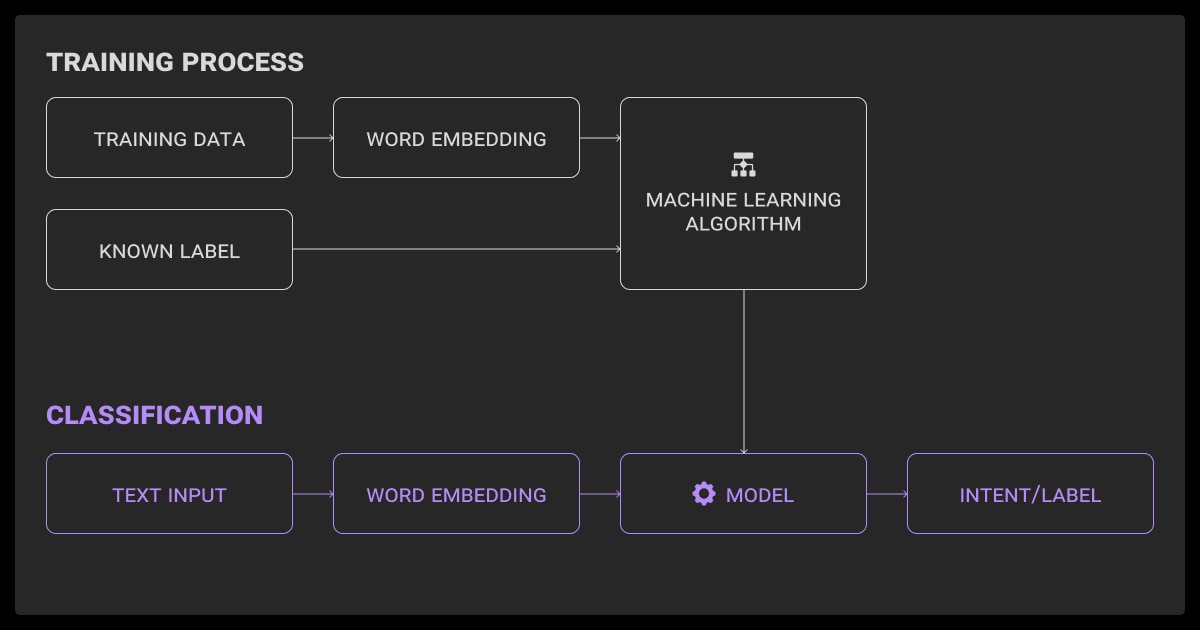
Now let’s get practical. If you’re building a full intent classification LLM pipeline, here’s a great way to do it.
Collecting and Annotating Intent Data
Start with a schema. What intents are you supporting? You need to keep them mutually exclusive when possible, or create a hierarchy. Labeling here can be tricky because users often say one thing and mean another. You’ll need to think about what people might ask the intent classification models.
Tips:
- Balance your classes and don’t let greetings dominate your dataset
- Use inter-annotator agreement to test clarity
- If labels are fuzzy, you’ll get fuzzy models
Preprocessing and Text Cleaning
Don’t skip this step. Clean text means clean signals.
You can follow these tips:
- Make everything lowercase
- Remove stopwords only if they don’t carry semantic weight for the task
- Normalize emojis, contractions, and spelling variants
- Tokenize based on model requirements, for example, subword tokens for transformers.
For LLMs, you can often skip heavy preprocessing. But for classical models, you need to clean it up.
Model Training and Evaluation
Pick a model, SVM, BERT, RoBERTa, whatever fits your stack.
Track the:
- F1 score, especially for imbalanced classes
- Accuracy, precision, and recall
- Confusion matrix, look for intent overlap
- Use cross-validation and early stopping to avoid overfitting
You shouldn’t just chase metrics. You need to test your model on real user queries. It’ll tell you more than any benchmark.
Use macro-F1 when dealing with class imbalance to avoid dominant classes skewing results.
Deployment and Serving
Now comes the fun part, making it work in production.
Things to watch:
- Keep latency low, especially for voice or chat use cases
- Set a fallback intent for uncertain queries
- Monitor performance over time, looking at intents shift, and watch as new intents emerge.
- Retrain regularly or incrementally as needed
For low-latency or offline environments, consider on-device deployment on edge or IoT devices using quantized or distilled models. This helps maintain responsiveness without relying on constant server calls.
We boosted clinical text classification from 78% to 86% accuracy just by paraphrasing labeled examples—rewriting phrases like ‘patient experienced nausea’ into variants such as ‘subject reported feeling nauseous.’ Ensembling those models with classical ML further improved performance without needing new labels.

 CEO & Founder, Lifebit
CEO & Founder, Lifebit
How to Improve Intent Classification Performance
You’ve got a baseline, but it’s missing edge cases. You need an evaluation dataset for intent classification and out-of-scope prediction. Here’s how to tighten it up.
Data Augmentation Techniques
Are you battling with small machine learning datasets? You can augment it by hiring data collection services or LLM fine-tuning services.
You can also try:
- Backtranslation, like translating from English to German and back again. You’ll naturally phrase things differently, making it easier to get examples for your machine learning algorithm.
- Paraphrasing during LLM fine tuning is a simple data augmentation technique that won’t cost a lot of money. LLMs can generate extra data with high accuracy.
- Synonym swapping for entities and verbs also lets you improve your dataset quickly and easily.
This helps balance underrepresented intents and adds linguistic variety. Just make sure that your text annotation is on point so that the system understands what it’s reading.
Handling Overlap and Ambiguity
Users aren’t robots, they’ll say things that could mean multiple things. For example, a sarcastic, “I love the new feature that adds an hour to the process.” Your model needs to be able to tell the difference.
Fixes:
- Use confidence thresholds to decide when to defer
- Use calibrated scores (e.g., temperature or Platt scaling) for more reliable thresholds
- Add multi-intent support (e.g., track_order + cancel_order)
- Create hierarchical classifiers like detect general domain → fine-grained intent
These help reduce misclassifications when the input isn’t clear-cut.
Iterative Improvement via Active Learning
Don’t guess, ask the model. Let it flag examples it’s unsure about.
In the pipeline, this might look like:
- Identify high-entropy queries
- Send them to human annotators
- Retrain the model with those new examples
It’s like giving your model a feedback loop. Over time, you’ll see its accuracy improve in the wild. Uncertainty sampling (like entropy or margin sampling) is commonly used to identify examples for labeling.
To stretch limited data, we generate paraphrases using intent-preserving prompts and filter them with embedding similarity checks. We also apply contrastive loss to pull same-intent embeddings closer—helping models distinguish overlapping intents like ‘cancel my booking’ vs. ‘reschedule my booking.
 Founder & Principal Software Architect, Cirrus Bridge
Founder & Principal Software Architect, Cirrus Bridge
Tools and Frameworks for Intent Classification
Here’s what professionals actually use in production workflows.
NLP Model Libraries
- Hugging Face Transformers: Best all-around library for state-of-the-art models
- spaCy: Great for fast, production-ready pipelines
- Rasa NLU: Purpose-built for intent classification and dialogue
- scikit-learn: Still great for classical ML approaches
- OpenAI (function calling, tools):– For LLM-based setups where you define intent categories
Annotation and Labeling Platforms
You’ll need both a model training stack and a reliable data annotation platform to supply high-quality labeled data.
- Label Your Data: Self-serve tool with free pilot, team and API access
- Label Studio: Open source, flexible UI, supports export to most formats
- Prodigy: Fast, scriptable annotation for NLP teams
- Snorkel: For weak supervision and programmatic labeling
The key is to find a reputable data annotation company with a traceable track record, rather than just making decisions solely on the lowest data annotation pricing.
Intent Classification in Production: Use Cases
It’s not just chatbots, intent classification shows up all over the place.
Retail Assistants
- Detects shopping vs. return vs. refund intent
- Suggests FAQs when users ask about product availability
- Tracks pre- and post-sale conversations
Healthcare Bots
- Pulls out symptoms from messages
- Schedules appointments via natural dialogue
- Differentiates casual health questions from serious ones that need escalation
One BERT-based medical chatbot achieved a 98% accuracy rate when researchers incorporated natural language processing into its training.
Fintech and Banking Systems
- Flags fraud-related messages
- Answers KYC questions
- Handles “Am I eligible for a loan?” intent without involving an agent
In regulated domains, being able to audit model behavior is a must.
Fine-Tuning vs. LLMs for Intent Classification
Let’s get tactical. You’re choosing between fine-tuning and prompting. Here’s what to think about.
I combine data augmentation with transfer learning—fine-tuning a pre-trained model on a small, paraphrased dataset. It improves generalization for edge cases and smaller intent classes, especially when precision and recall really matter.
 Co-Founder & CEO, AIScreen
Co-Founder & CEO, AIScreen
Performance vs. Interpretability
Fine-tuned models are easier to debug. You can trace errors back to examples, tweak the data, retrain, and try again. LLMs are more like a black box. You control the prompt, not the model weights. They’re great for speed, but not the best for reproducibility.
For teams needing a balance, quantized or distilled models like DistilBERT or TinyBERT can reduce inference cost while retaining most of the performance.
Operational Costs
| Approach | Labeling Cost | Inference Cost | Infra Load |
| Fine-tuned | High (manual labels) | Low (efficient) | Moderate |
| LLM (prompting) | Low (zero-shot) | High (per call) | Cloud-heavy |
So if you’re optimizing for cost-per-query at scale, you might want to fine-tune. But if you need to spin up a new intent tomorrow? LLMs win.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is intent classification?
It’s the task of mapping user inputs to predefined intents. For example, mapping “Where’s my order?” to order_tracking.
What is LLM intent classification?
It’s using a large language model (like GPT) to classify intent through prompting with no fine-tuning needed. Great for rapid prototyping or rare use cases.
What is intent classification in NLU?
It’s a sub-task of Natural Language Understanding (NLU), focused on interpreting the user’s goal within a broader dialogue system.
What is intent classification using embeddings?
This refers to transforming text into vector representations (embeddings), then using those for similarity comparison or feeding into classifiers.
What is RAG for intent classification?
Retrieval-Augmented Generation (RAG) combines a retriever (to fetch relevant data) and a generator (to answer). RAG is more commonly used for retrieval tasks, but it can help improve classification when intent depends on external context (e.g., past interactions).
What are the approaches to intent classification?
There are four main approaches to intent classification. Rule-based systems rely on predefined patterns or keyword matching. Classical machine learning models, such as SVMs or Random Forests, use engineered features like n-grams or TF-IDF.
Fine-tuned transformers, including BERT and RoBERTa, leverage deep contextual embeddings and perform well with labeled data. Lastly, LLM-based prompting uses models like GPT or Claude to classify intents with zero- or few-shot examples, without fine-tuning.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.