Document Classification: End-to-End ML Workflow Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Document Classification in ML Workflows?
- Document Classification Approaches
- Building a Document Classification Pipeline
- Handling Imbalanced Labels and Multi-Label Classes
- OCR and Document Classification: What to Watch Out For
- Scaling Classification Pipelines in Production
- Tooling for Document Classification (With Examples)
- When to Outsource Document Classification Services
- About Label Your Data
- FAQ

TL;DR
- Most document classification pipelines fail before production—OCR noise, layout shifts, and messy formats are common blockers.
- Manual, ML, or semi-supervised? Your method depends on how much labeled data you have and how complex the documents are.
- Use BERT for plain text. Use LayoutLM when structure matters.
- Multi-label docs and class imbalance need smart sampling and loss tuning.
- A working pipeline isn’t just a model. You need drift checks, fallback logic, and human QA built in.
What Is Document Classification in ML Workflows?
Document classification is the task of assigning a category or label to a document based on its content. In a supervised learning setting, a data annotation company will train a model on a dataset of labeled documents and then use that model to predict labels for unseen data.
The primary goal is to enable automated sorting, routing, or prioritization of documents at scale. This means transforming unstructured, unlabeled data, which is often a mix of text, layout, and metadata, into structured, actionable outputs.
As an example, you’ll classify unstructured text in data mining into a usable machine learning dataset.
Common Uses for Document Classification
Legal Document Sorting
Contracts, case files, and regulatory documents can be classified by topic, jurisdiction, or case type.
Email Triage
Incoming emails are routed to appropriate teams using classification models trained on message text and metadata.
Claims Processing
Insurance firms classify forms and statements, for example, medical records, receipts, police reports, to streamline claims workflows.
Healthcare Records
Patient reports are classified for diagnostics, billing, or compliance. You may also need Named Entity Recognition for this use case.
Document classification is foundational for AI document classification systems that need to extract, organize, and interpret large-scale document corpora in real-time. You’ll need to find the right application for the job at hand.
For example, AI handwriting recognition for written doctor’s notes or an image recognition system that can convert photographed text into a document your model can read.
Document Classification Approaches
How we classify documents varies depending on data availability, scale, and domain constraints.
Manual vs. Rule-Based vs. ML-Powered

Manual
This is very labor-intensive and hard to scale. The upside is that it’s highly accurate, which can be critical in niche domains.
Rule-Based
This relies on heuristics like regex, keyword spotting, or conditional logic. It’s good for simple use cases, but can break down as you scale up.
ML-Powered
This automated document classification uses statistical or deep learning models trained on labeled data. It offers adaptability, generalization, and improved performance over time.
For example, assigning multiple classification probabilities instead of forcing single categories improved accuracy by ~40% in one production pipeline. Vector embeddings also reduced misclassifications by 65% by grouping similar documents into “neighborhood clusters.

 Founder & CEO at Scale Lite
Founder & CEO at Scale Lite
Supervised, Unsupervised, and Semi-Supervised Classification
You don’t have to run document classification software on its own, there are several document classification levels:
Supervised
Here you need to provide labeled data. Supervised learning is ideal when class boundaries are known and delivers high accuracy. The trade-off is that it’s data-hungry.
Unsupervised
Clustering-based, for example, K-means on embeddings. It’s useful for exploratory analysis or when labels don’t exist.
Semi-Supervised
Here we combine small labeled sets with large unlabeled corpora. The model uses techniques like self-training and consistency regularization. Recent work in semi-supervised document classification also leverages pseudo-labeling and contrastive learning.
This paper goes into each of these in greater detail.
Text-Based vs Visual (Layout) Classification
Traditional classification relies on raw or processed text. But in many enterprise settings, layout matters:
Text-Based
Uses document classification NLP techniques: TF-IDF, BERT embeddings, etc.
Visual/Layout-Based
Models like LayoutLM or DocFormer consider spatial layout alongside text for forms, invoices, and other structured documents.
When NLP and OCR document classification isn’t enough (for instance, when key signals are embedded in layout or font styling), layout-aware models become crucial. These models are particularly effective on forms, tables, and scanned documents where semantic structure is visually encoded and provide a viable alternative to document digitization with OCR.
Building a Document Classification Pipeline
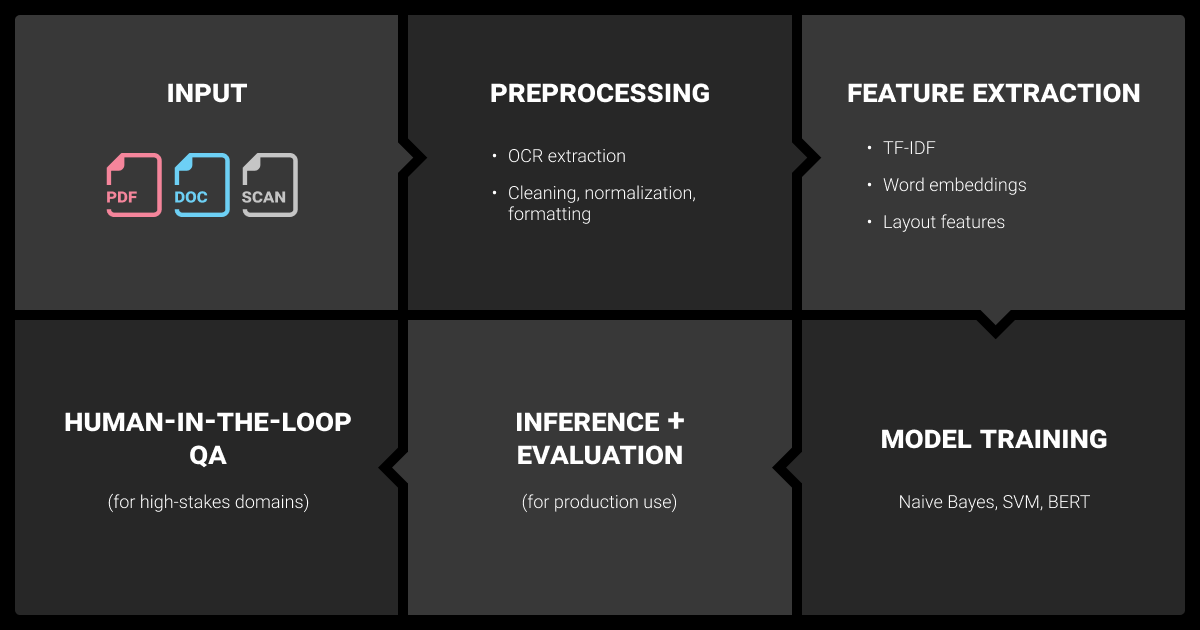
A robust document classification machine learning pipeline handles everything from raw file ingestion to monitoring models in production.
Step 1: Document Ingestion and Preprocessing
The first step towards automatic document classification machine learning is to feed in the data and clean it up. You need to pay particular attention to low-quality data with OCR deep learning and similar types of LLMs.
OCR Data Extraction
OCR data extraction is a form of scanned document classification. You extract text from scanned images, for example, using Tesseract, AWS Textract, or Google Vision OCR data entry.
Format Normalization
Convert PDFs, DOCX, HTML, and images into unified formats. Pay attention to encoding mismatches and corrupted files.
Noise Filtering
Remove headers, footers, boilerplate text, and junk characters.
Text annotation services put a fair amount of effort in at this stage so that the machine learning algorithm performs better in the end.
Step 2: Feature Extraction
Effective features are critical. Common natural language processing techniques include:
- TF-IDF: Still useful for smaller datasets or interpretable baselines.
- Word embeddings: Uses pre-trained AI in document classification like GloVe, FastText, or fine-tuned BERT to convert text into dense vectors.
- Layout embeddings: Tools like LayoutLM capture spatial relations between tokens.
- Metadata: Source, date, sender, or file type can improve performance when used as features.
When fine-tuning transformer-based models, it’s crucial to handle domain adaptation carefully, especially for domain-specific jargon or abbreviations.
Like with image classification, feature engineering often makes or breaks performance in small-data environments. Luckily, here we don’t have to worry about image classification vs. object detection or zero-shot image classification.
Step 3: Model Training
Choosing the right machine learning for document classification model depends on the complexity of the task and data availability:
- Naive Bayes: Fast and simple. Performs well on clean, bag-of-words inputs.
- SVM: Effective in high-dimensional spaces. Great for linear boundaries and small-to-medium datasets.
- Hierarchical classifiers: Useful when classes are nested (e.g., document → form → tax form).
- Transformers (BERT, RoBERTa): Deliver state-of-the-art results on most document NLP tasks. Pretrained models can be fine-tuned with labeled data.
While traditional NLP models like SVMs or Naive Bayes work well for simple tasks, transformer-based LLMs (like BERT or RoBERTa) often perform better for complex document classification. If you're comparing LLM vs NLP, the right choice depends on your data, compute limits, and task complexity.
Training pipelines should include cross-validation, early stopping, and hyperparameter tuning, for example, using Optuna or Ray Tune). Also consider class weighting or focal loss to mitigate class imbalance during training.
Step 4: Inference, Evaluation, and Monitoring
Move beyond just accuracy:
- F1 score: Balances precision and recall. Crucial for imbalanced datasets.
- Rejection rate: Measures how often low-confidence predictions are deferred to human review.
- Entropy/Confidence scores: Help assess uncertainty and trigger fallback workflows.
- Latency: Important for real-time classification use cases like chat or live document intake.
Calibration metrics, like Expected Calibration Error, can be useful for production monitoring and human-in-the-loop workflows.
Handling Imbalanced Labels and Multi-Label Classes
Real-world datasets rarely come neatly packaged, which complicates document classification using machine learning.
How Multi-Class and Multi-Label Differ
In a multi-class document classification solution, each document belongs to exactly one class. In multi-label settings, documents may belong to multiple categories, for example, “Legal + Financial”. Don’t confuse the two, multi-label requires binary classifiers per label or custom loss functions like Binary Cross-Entropy.
Alternatively, models like BERT can be adapted for multi-label by applying a sigmoid activation on the output layer instead of softmax.
Label Sparsity and Confusion in Real-World Datasets
Some classes may have only a handful of training examples. This leads to confusion and poor generalization.
- Confusion Matrix: Helps identify frequently mistaken class pairs.
- Few-Shot Learning: Prompt-based transformers or adapters can help in low-label regimes.
Other strategies include data augmentation, synthetic document generation, and leveraging external corpora for weak supervision.
Sampling Strategies to Balance Train/Test Splits
- Stratified Sampling: Maintains label proportions across train/test.
- SMOTE/ADASYN: Augment minority class examples by synthesizing samples.
- Under/Over Sampling: Adjusts the number of examples per class to rebalance data distribution.
Be cautious: synthetic sampling techniques may not generalize well to document-level semantics or hierarchical class structures.
Documents are usually more than one category at a time. Multi-label systems assign probability scores across categories, better reflecting the natural complexity of information.
 Co-Founder & CEO at Thunderbit
Co-Founder & CEO at Thunderbit
OCR and Document Classification: What to Watch Out For
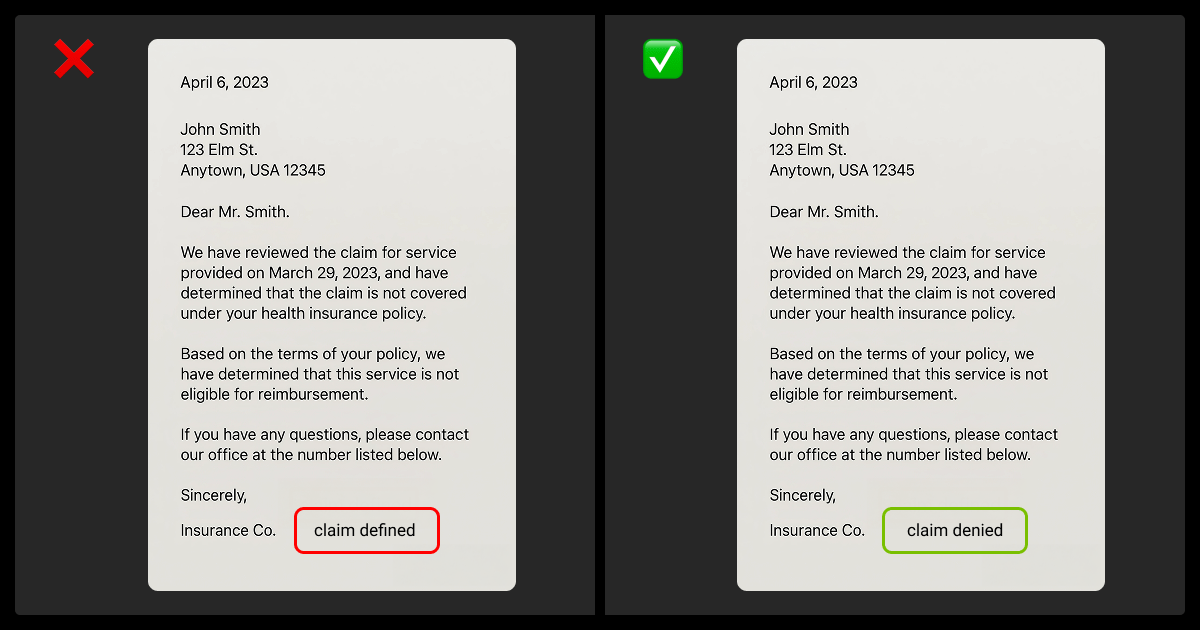
Text from OCR is noisy, especially on low-res scans, handwritten forms, or multi-column layouts.
Post-OCR Text Cleanup Essentials
You should normalize whitespace, fix character encoding, remove artifacts (e.g., ~, ¬, |) and use spelling correction or regex-based cleanup to improve token quality. You should also align OCR output with bounding boxes if you’re using layout models.
When OCR Errors Break Classification
OCR errors can shift meaning completely, for example, “claim denied” misread as “claim defined.” Tokenization and feature extraction steps can magnify this error.
How to Fix It
- Preprocessing: This is faster, cheaper, but less effective on systematic errors.
- OCR Retraining: This is necessary if errors stem from font styles, handwriting, or non-English characters. Use labeled image-text pairs to fine-tune OCR models.
You may also consider ensemble OCR outputs or confidence-weighted token filtering as alternatives.
Scaling Classification Pipelines in Production
Accuracy is only half the battle. Production systems must scale, adapt, and stay trustworthy.
Throughput and Annotation Velocity Benchmarks
Measure:
- Docs/sec: End-to-end inference speed.
- Latency per doc: Key for real-time systems.
- Annotation velocity: How many documents per hour a human annotator can handle, which impacts data ops planning.
Monitoring Drift and Model Decay Over Time
Monitor for:
- Input drift: Changes in OCR quality, document templates, or language.
- Prediction drift: Shifts in label distribution or confidence.
- Performance decay: Gradual drop in metrics over time. Use dashboards and alerts.
Human-in-the-loop QA
Deploy fallback workflows when confidence is low, when input is out-of-distribution, or when class balance shifts over time.
Tools like Prodigy, Label Studio, and Snorkel Flow support real-time human validation and retraining cycles. For service-based QA, teams often work with providers like Label Your Data to handle domain-specific reviews at scale.
Garbage in, garbage out applies to AI classification too—we found that having domain experts review just 5% of classifications weekly prevented model drift and maintained 93% accuracy over 18 months.
 Founder at Perfect Afternoon
Founder at Perfect Afternoon
Tooling for Document Classification (With Examples)
The ecosystem is rich and growing.
Open-Source Libraries
Start with these great resources:
- scikit-learn: Great for baselines (SVM, Naive Bayes) and pipeline chaining.
- spaCy: NLP pipeline with support for custom components and classification.
- flair: Easy-to-use framework with support for embeddings and document-level tasks.
ML Platforms and Pipelines
- Hugging Face Transformers: Pretrained transformer models and tokenizers.
- Label Studio: Data annotation tool with support for multi-label classification, OCR overlays, and custom QA workflows.
Custom Document Annotation Workflows
Services like Label Your Data provide annotation for complex document types with nested structures and multiple label hierarchies. They often combine human QA with ML-assisted labeling.
When to Outsource Document Classification Services
In some cases, building in-house just isn’t practical, and it makes more sense to hire data annotation services.
Internal Bottlenecks
You might look into text labeling services if you lack labeled data, or have no internal annotation capacity. You can also consider it for complex edge cases or long-tail classes.
Outsourcing can give you a high-quality dataset faster, as data collection services have highly effective collection and data annotation. Worried about data annotation pricing? The cost of internal processing can add up quickly, sometimes it’s better to recognize this early.
Evaluation Criteria for Picking a Vendor
Look for:
- Label audit capabilities: Can they measure inter-annotator agreement?
- Compliance: GDPR, HIPAA, SOC 2, etc., depending on data sensitivity.
- Domain familiarity: Legal, medical, or financial experience is a must for nuanced classification.
Why Manual Labeling Wins
Automated tools break down when context matters. They miss edge cases, struggle with ambiguous language, and often misclassify overlapping categories.
Human annotators can handle nuance, especially when trained on your domain. They recognize patterns that models ignore, like legal phrasing, handwritten notes, or multi-intent documents.
Manual labeling also allows for real-time feedback loops. Annotators can flag unclear cases, suggest new label classes, and adjust to evolving guidelines — something no off-the-shelf model can do reliably.
For high-stakes use cases, from healthcare to legal to finance, manual review is the baseline for building accurate, trusted systems
About Label Your Data
If you need help with LLM fine-tuning task, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are the four classifications of documents?
Legal documents, like contracts and agreements, often require streamlined handling and organization — especially in firms that rely on remote legal assistant support to manage intake, drafting, and review tasks efficiently.
What are examples of classified documents?
Examples of classified documents include NDAs, lease agreements, tax forms, purchase orders, prescriptions, patient summaries, immigration forms, or IDs
What is the document classification chart?
It’s a visual taxonomy or decision tree that outlines how documents are categorized, often including metadata like source, class probability, or downstream tasks.
What is the document classification method?
A document classification method refers to the specific approach used; manual rules, traditional ML, for example, Naive Bayes, or deep learning, for example, BERT, combined with preprocessing, feature extraction, and evaluation strategies.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.