Structured vs. Unstructured Data: What Your ML Workflow Needs

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Structured Data vs. Unstructured Data Really Means for ML
- How Data Format Shapes Preprocessing and Model Design
- Choosing the Right Data Type for Your ML Use Case
- The Labeling Bottleneck: Structured vs Unstructured Data
- Working with Mixed or Semi-Structured Data Sources
- Recommendations for ML Teams Working with Structured vs Unstructured Data
- About Label Your Data
-
FAQ
- What is the difference between structured vs unstructured data?
- What are examples of unstructured data?
- What are 5 examples of structured data?
- What is the difference between structured and unstructured qualitative data?
- What is the difference between structured and unstructured medical data?
- Is CSV unstructured data?

TL;DR
- Structured data is organized in tables with clearly defined fields, which is great for traditional models and often cheaper to annotate when labels already exist.
- Unstructured data includes images, audio, text, and video, which is often richer but harder to process and label.
- Your data format heavily influences your ML architecture, preprocessing steps, and annotation workload, but some architectures, like transformers, can generalize across formats (they still need format-specific tokenization).
- Don’t pick a model before understanding your input; choose tools that match your data complexity.
- Mixed formats, like JSONs, PDFs, scraped content, are common in production, so you should plan for hybrid workflows early.
What Structured Data vs. Unstructured Data Really Means for ML
So, what is structured data vs. unstructured data? These aren’t just storage categories, they dictate how you’ll build your ML system. Structure determines:
- How data flows through your pipeline
- How easy it is to annotate
- How much preprocessing work your team will face
What unstructured vs. structured data boils down to is that the former demands more custom handling because it often consists of complex tasks like image recognition. The latter often benefits from automation in QA and ETL because it’s simpler.
How Structured Data Works in ML Pipelines
Structured data looks like rows and columns: clean, labeled, and queryable. Think databases, spreadsheets, or feature vectors where each value has a clear type and meaning. In ML, this kind of data usually comes from operational systems like CRMs, ERP logs, transactions, or surveys.
ML pipelines built on structured data are predictable. You define a schema, run validation checks, and feed your model with numeric or categorical features. Though relatively straightforward, you still need to guard against issues like schema drift and data leakage, especially in production systems. Feature stores like Feast are increasingly used to manage this complexity.
Common libraries like Scikit-learn, LightGBM, CatBoost, or XGBoost work right out of the box. Feature engineering is often manual but transparent. Tools like SHAP or LIME also make it easier to interpret model outputs, especially when explainability is a key requirement.
What Counts as Unstructured in Modern ML
When it comes to unstructured vs. structured data, the former is everything that doesn’t fit neatly into rows and columns. Images, audio files, free-text customer feedback, PDFs, videos, and even code snippets fall into this category. There’s no predefined schema. Instead, you need to extract structure before modeling, or use models that can process raw inputs directly.
With the rise of deep learning, unstructured data is now central to many machine learning model training tasks. NLP models take raw text, vision models ingest image pixels, and foundation models, often text-focused, are evolving to span multiple modalities.
Multimodal foundation models like GPT-4o and Gemini can process both text and images, expanding what’s possible in unified pipelines. The payoff is higher potential insight, but at the cost of more complex data prep and infrastructure.
How Data Format Shapes Preprocessing and Model Design
The format of your input data has a huge impact on how you design your pipeline. From preprocessing steps to model architecture, unstructured data vs structured data require fundamentally different approaches.
Structured Data
With structured data, preprocessing is mostly about normalization, imputation, encoding, and aggregation. You might scale features, bucket timestamps, one-hot encode categories, or derive new columns. Most of this can be handled in Pandas or Spark.
Model-wise, you have a wide choice of interpretable and efficient options. Linear models, decision trees, and ensemble methods like Random Forest, LightGBM, or XGBoost dominate here. They handle sparse inputs well and train quickly, even on CPUs. Explainability tools like SHAP or LIME are well-suited to these models, especially in regulated industries.
Unstructured Data
Structured vs unstructured data analysis is very different. Unstructured data flips the script. You can’t just feed an image or paragraph into a model. Text needs tokenization and embedding. Images need resizing or normalization; segmentation is part of labeling, not preprocessing. Audio requires feature extraction like MFCCs or spectrograms.
Once preprocessed, unstructured data often feeds into deep learning models: CNNs for images, Transformers for text, and hybrids for multimodal tasks. RNNs are rare in text NLP, but still used in low-latency ASR and tiny-ML. Replaced by transformer-based architectures, these models require GPUs, large datasets, and longer training times. They’re more complex, but they unlock use cases that structured data can’t touch.
The deadliest pitfall with unstructured data is context preservation. Structured data needs automated constraint checks, while unstructured data benefits from probabilistic confidence scoring. Build bridges between them with human feedback loops.

 President, Kell Solutions
President, Kell Solutions
Choosing the Right Data Type for Your ML Use Case

Now that we’ve seen some structured vs unstructured data examples, it’s time to move onto real world applications.
Before launching any project, step back and ask: What type of data makes this prediction possible? For some tasks, structured data is enough. For others, unstructured data is the only path forward.
If you’re having problems, you can go over what is structured vs unstructured data again.
In some cases, you’ll have both structured and unstructured sources available. Choosing between them depends on annotation cost, infrastructure, and model complexity.
High-Value Structured Use Cases
Structured data powers many of the most profitable ML applications. Fraud detection in banking, product recommendations in ecommerce, churn prediction in SaaS, all rely heavily on transaction logs, clickstreams, and tabular behavior data.
These use cases benefit from the structure; patterns are often buried in numeric signals or categorical combinations. Labeling is cheap, models are fast to train, and explainability is usually a requirement.
When Unstructured Data is the Only Viable Input
Sometimes there’s no structured vs. unstructured data debate. Some tasks just don’t have a structured input. You can’t predict sentiment without text, detect tumors without images, or transcribe audio without waveform data. Here, unstructured data is the raw material and there’s no shortcut.
NLP, computer vision, and speech recognition rely entirely on unstructured inputs. Video annotation services, for example, use a lot of these inputs because of the complexity of the data.
These domains now fuel applications like content moderation, summarization, visual search, and accessibility tech. The complexity is higher, but so is the potential value.
Don’t build pipelines around the cleanest data—build them around the mess that reflects reality. Start with unstructured inputs, enrich them, then generate structured records with confidence scores. The output of your workflow should be structured, not the other way around.
 Owner, Weidemann.tech
Owner, Weidemann.tech
The Labeling Bottleneck: Structured vs Unstructured Data
Data labeling is often the most expensive part of an ML project. And the type of data you use determines just how painful this process will be.
Structured Data Annotation
With structured data, labels are often already present, like with churned or not, fraud or not, and clicked or not. You might just need to clean or verify them. When you need manual data annotation, like tagging order issues, you can do it quickly and cleaning with dropdowns or binary checkboxes.
The catch? Structured labels depend on consistent schemas. One misnamed column or ambiguous category can skew everything. These issues often propagate in automated pipelines unless caught early. QA is more about validating consistency than content.
Unstructured Annotation
Unstructured annotation is time-consuming. Tagging a document requires reading it. Labeling an image might take bounding boxes or segmentation. Audio needs careful listening. LLM-generated draft labels (e.g., GPT-4o) reduce human effort by 50–80 % but still need review. And when tasks are subjective, like identifying tone or emotion, you’ll need skilled annotators.
The more structured data vs unstructured data examples your annotators process, the faster they can become, but it still takes time.
A data annotation company can make the process simpler because the tools for unstructured data are also more complex. You need UIs that support playback, zooming, markup, and tagging. QA takes longer, and disagreements are more common. The accuracy of your machine learning dataset is harder to guarantee without multiple reviewers.
Self-supervised or weakly supervised learning can help reduce annotation costs in some domains, but these techniques require careful design and validation.
Working with Mixed or Semi-Structured Data Sources
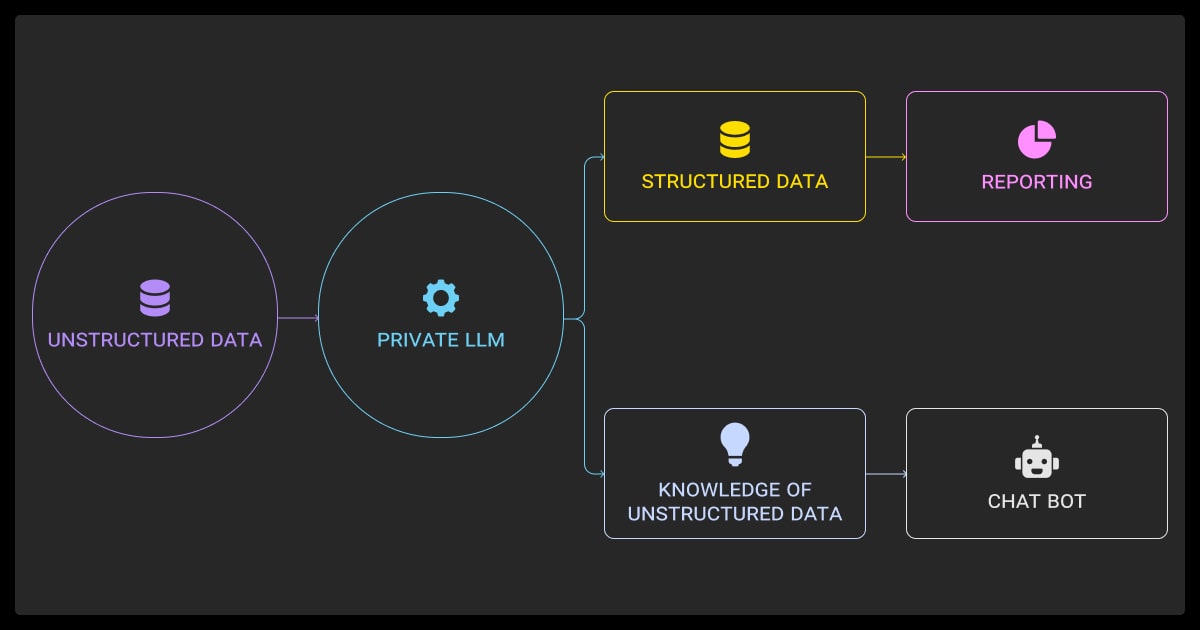
In real-world ML, data rarely comes in a clean, singular format. You’ll run into JSON blobs, scanned PDFs, scraped webpages, and datasets with both structured metadata and unstructured content.
You’ll also have to look at whether you’re running supervised vs. unsupervised learning. In the latter case, you can get away with unlabeled data. In the former, you’ll need robust data annotation tools or will need to work with LLM data labeling.
How to Normalize and Parse Hybrid Formats
Hybrid data requires early investment in preprocessing. JSONs need flattening. PDFs might require OCR. You may need to split documents into structured metadata (date, author) and unstructured body content (text, images). Parsing pipelines must handle edge cases: missing fields, corrupt files, inconsistent formats.
Semi-structured data, like JSON or XML, usually comes with a schema (JSON Schema, XSD); the real headache is schema drift across versions, which breaks downstream parsers. It needs transformation before it’s useful in ML workflows.
Tools like spaCy, Tesseract, PaddleOCR, PyMuPDF, and jq can help extract usable signals. The goal is to standardize inputs so downstream models can consume them consistently.
Here are three common hybrid-data scenarios you’ll probably meet in production:
- Electronic Health Records (EHRs): Contain structured vitals and test results alongside doctor notes or scan images. Models might combine logistic regression for structured parts and transformers for free-text notes.
- PDF Invoices: Often include tabular transaction data plus vendor logos or notes. You might extract line items into a dataframe and run OCR on visual elements.
- Web Scraped Data: Comes in all shapes: HTML structure, user-generated text, embedded images. You need to extract and clean content, remove noise, and tag intent.
Recommendations for ML Teams Working with Structured vs Unstructured Data
If you’re building ML systems in production, chances are your input data isn’t always clean or clearly defined. Here’s how to make that complexity manageable.
The successful approach treats structured data with more skepticism and unstructured data with more confidence than most teams naturally do. Both require validation, but the strategies must match the specific failure modes of each type.
 VP of Marketing & Sales, Deep Cognition
VP of Marketing & Sales, Deep Cognition
Audit Your Input Data Early
Before you send anything to data annotation services labeling, review your input structure. Is the schema consistent? Are all fields populated? Are text fields actually language, or gibberish? Identify missing values, encoding issues, or duplications now, before you pay for annotations that get thrown out later.
This can save you a lot of money when it comes to data annotation pricing and LLM fine tuning.
Use small samples to test your preprocessing logic and label guidelines. A few early reviews can save weeks of rework on your machine learning algorithm.
Also, version your label schema early. Changes in definitions mid-project can invalidate thousands of annotations.
Use the Right Annotation Tools per Data Type
Generic platforms may lack the efficiency or precision of specialized tools, especially when working at scale. Use annotation tools that match your data:
- For tabular: internal QA dashboards with CSV editing or schema validation.
- For text: platforms like Prodigy, LightTag, or Label Studio with entity/tag support.
- For vision: image annotation tools with polygon drawing, classification, or mask-based segmentation.
- For multimodal: interfaces that show text and images together for richer context.
Look for platforms that integrate easily with your training pipeline: one-click exports, API access, and clear audit trails.
When to Consider External Support
If your data is noisy, requires niche expertise, or simply exceeds your team’s bandwidth, consider outsourcing. External providers can help with:
- Large-scale annotation projects (hundreds of thousands of records).
- Multilingual support for NLP tasks.
- QA for subjective or edge-case labels.
- Hybrid datasets that require OCR, parsing, and manual review.
The right partner will reduce time-to-production without compromising label quality. Just make sure to stay hands-on during onboarding and sampling.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the difference between structured vs unstructured data?
Structured data follows a fixed schema (think tables or spreadsheets). It’s easy to query and process. Unstructured data lacks that predefined format like raw text, images, audio, or video. Each requires different ML tools and workflows.
What are examples of unstructured data?
Unstructured data shows up in many formats. Think customer emails and chats, social-media posts, scanned PDFs, handwritten forms, photos, medical images, call-center recordings, podcasts, and long-form video.
What are 5 examples of structured data?
Customer transaction logs, web analytics events, product catalogs with SKUs, sensor readings from IoT devices, and survey results in CSV files.
What is the difference between structured and unstructured qualitative data?
Structured qualitative data uses predefined codes, tags, or Likert-scale responses. Analysts can pivot it like a spreadsheet and run quick stats.
Unstructured qualitative data captures open-ended feedback: interview transcripts, focus-group recordings, free-text survey answers. You need manual coding or NLP techniques to surface themes.
What is the difference between structured and unstructured medical data?
Structured medical data lives in fields such as ICD-10 codes, lab results, medication orders, and vital signs; ready for rules-based alerts or classic predictive models.
Unstructured medical data covers clinician notes, radiology images, pathology slides, and waveform recordings (ECG, EEG). Unlocking its value requires NLP, computer vision, or signal-processing pipelines before downstream analytics.
Is CSV unstructured data?
No. A CSV file is a container for structured data. Although it’s stored as plain text, its rows and columns follow a consistent, labeled structure, making it structured if properly formatted.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.