Synthetic Data Generation: When to Use It in ML Projects

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why ML Teams Use Synthetic Data
- Techniques for Synthetic Data Generation
- When Synthetic Data Generation Helps (and When It Doesn’t)
- Is Synthetic Data Generation Right for Your ML Task?
- Evaluating Synthetic Data for ML Use
- Real and Synthetic Data Blending Strategies
- Tools for Synthetic Data Generation
- Practical Risks and Compliance Considerations
- About Label Your Data
- FAQ

TL;DR
- Synthetic data helps you get around data scarcity, privacy hurdles, and those annoying edge cases.
- Great for prototyping, rare event detection, and working in regulated industries.
- You can make it using augmentation, generative models (like GANs or VAEs), or simulations.
- Speeds up development and gives you flexibility, but you’ll still need real-world testing.
- Mixing real and synthetic usually works best, with popular use cases including fraud detection, robotics, and autonomous driving.
Why ML Teams Use Synthetic Data
Remember when synthetic data used to be a novelty? Now, it’s a practical fix for real-world bottlenecks. According to Gartner, 84% of organizations use text-based synthetic data, making it especially popular among NLP and LLM teams. 60% adopted it due to limited access to real-world data, reinforcing a common challenge in ML workflows.
Are privacy laws tripping you up? Or are you battling to find enough labeled data for your needs? Is your machine learning dataset missing rare edge cases that could improve rare class detection or domain-specific model robustness?
Synthetic data generation lets you build, iterate and take your LLM fine tuning to the next level. And it’s fast becoming the hot new kid on the block.
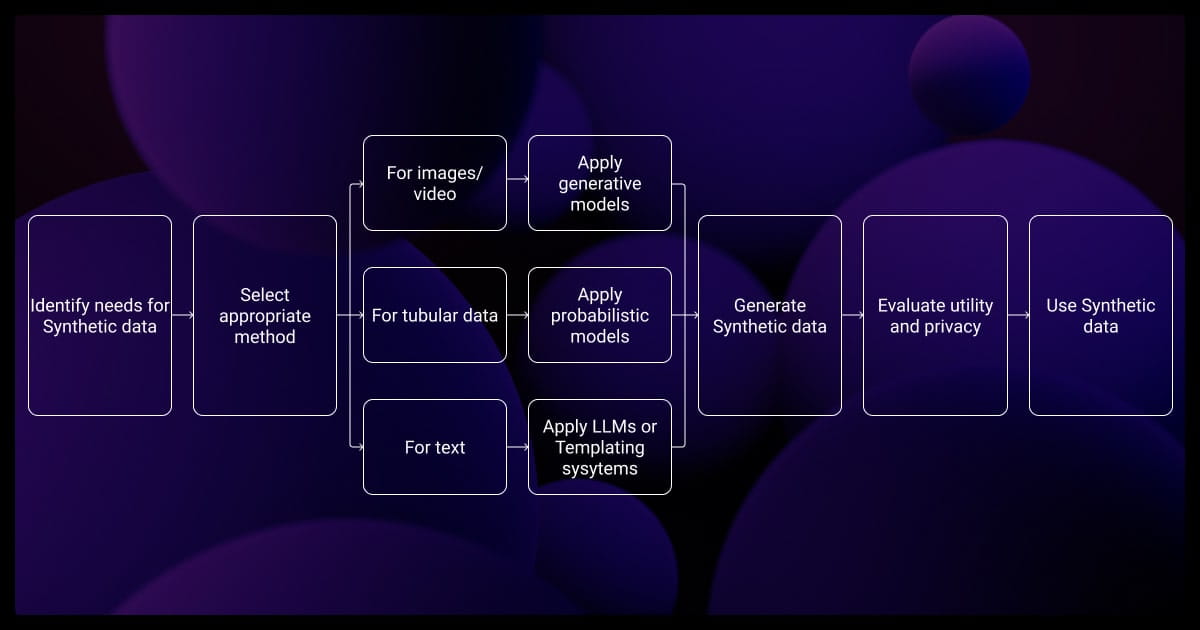
What Is Synthetic Data and How It Works
Synthetic data mimics the stats and patterns of real datasets, but it’s generated, not collected. You don’t need sensors or users, just algorithms trained on real datasets or designed to simulate domain-specific behaviors. This makes it a cost-effective way to reduce data annotation pricing.
You’re looking at:
- Tabular: Rows and columns that follow real distributions
- Image: Generated visuals for CV tasks
- Text: Machine-generated content for NLP models
- Time-series: Simulated sequences for forecasting or anomalies
It’s useful for pretraining, balancing class distribution, or skirting privacy issues. Regarding privacy issues, you’ll need to distinguish between fully and partially synthetic data. Are you using partially anonymized records from the real world? How will you scrub these?
The big win? You control the structure, size, and variability and don’t have as many compliance headaches.
Benefits of Synthetic Data for ML Projects
Synthetic data is all about control, speed, and flexibility. Some typical perks:
- Worried about privacy law bottlenecks? You can spin the data you need and still stay compliant.
- Don’t have enough training data? You can generate useful variations to flesh out your dataset.
- Worried about how your model will handle rare events? You can create more examples as you need them, instead of waiting for them to crop up.
- Looking at specific test conditions? Simulate glare, noise, or occlusion as you like.
You don’t have to wait for edge cases to happen, you can just make them happen. This allows for faster experimentation and rare class modeling.
When Synthetic Data Fits Best
Synthesizing data isn’t a one-size-fits-all solution, but it works well in the right context. That said, it can solve constraints like:
- Regulated Limits: Healthcare, finance, and places where you can’t share real data.
- High data annotation costs: Are you in a specialized industry like the medical field or autonomous vehicles where you have to label photos or videos? Video annotation services can reduce the costs, but they still add up.
- Sparse edge cases: Those once-in-a-million situations that never show up in the wild.
It’s especially helpful when you’re still in the “let’s try stuff” phase and real data is thin.
Techniques for Synthetic Data Generation
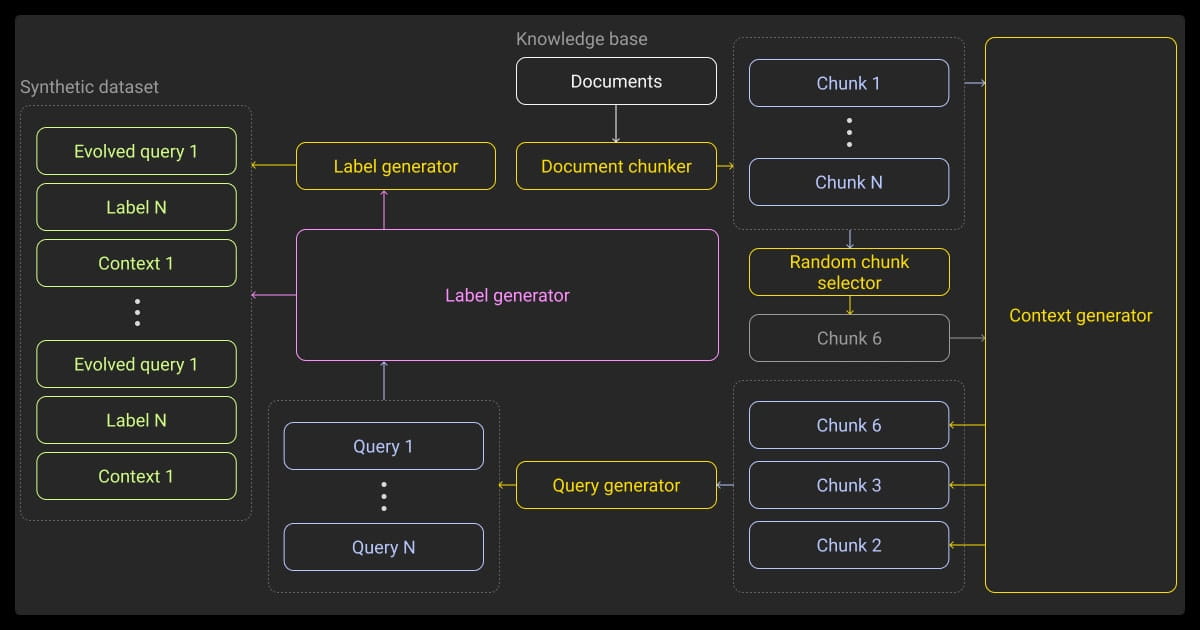
Now let’s look at some synthetic data generation techniques that a professional data annotation company might use.
Data Augmentation
This is common in image and text data processing, but it involves manipulating the data you already have instead of creating new sets. You’ll make small changes:
- Images: Rotate, crop, blur
- Text: Swap words, drop phrases, paraphrase
- Tabular: Shuffle values, inject noise, and oversample minority classes using techniques like SMOTE. (Though, technically, it is resampling, not augmentation.
It’s fast, simple, and relatively inexpensive.
Generative Models
Synthetic data generation with generative AI gives you a more creative solution, but they’re more compute-heavy. It can create realistic data samples from learned distributions. You can use:
- GANs: Widely used for images with limited but emerging use cases in tabular data, e.g. CTGAN in SDV.
- VAEs: Sample from latent space to generate variation
- Autoregressive models: Solid choice for sequence generation in NLP
Simulation-Based Methods
Here you build data from the ground up in controlled environments, like:
- Driving simulators
- Physics-based robotics environments
- Virtual financial markets
- Physics engines such as MuJoCo, CARLA
- Domains like digital twins in manufacturing or logistics
It’s perfect when you need total control, but not exactly plug-and-play.
Quick Comparison of Synthetic Data Generation Methods
| Technique | Cost | Fidelity | Best For | Labels Included |
| Data Augmentation | Low | Medium | Image, text, tabular | Yes |
| Generative Models | Medium-high | High | Image, text,tabular | Often |
| Simulation-Based | High | Very high | Time series, sensor, image | Yes |
When Synthetic Data Generation Helps (and When It Doesn’t)
Synthetic data is useful, but studies show that it’s not without issues.
Synthetic Data Generation Helps When
You’re dealing with:
Data Privacy and Compliance Issues
If real user data is off-limits, synthetic versions can keep you on track. But be sure to create anonymized datasets for public release and be careful of overfitting.
Rare Event Modelling
Do you need more fraud cases or unusual anomalies? You can generate them to address class imbalances.
Accelerating Model Development
Do you need to reduce the time and cost associated with data collection? Are you racing to market with the prototype? Synthetic data can be a lifesaver.
Synthetic Data Generation Hurts When
Synthesizing the data isn’t the answer when:
- Your models overfit to synthetic artifacts
- You skip real-world validation
- You need use cases that need exact real-world noise, chaos, or context (this is hard to fake)
You must always run real-world validation before deployment. Ask yourself:
- Do I have real data to test against?
- Is this a high-risk or low-label scenario?
- Will synthetic data actually move the needle?
Is Synthetic Data Generation Right for Your ML Task?
Synthetic data isn’t a drop-in replacement for real-world data. But in the right context, it can significantly reduce bottlenecks in machine learning workflows. The key is knowing when it’s actually the better choice.
Use the framework below to assess whether synthetic data fits your specific task.
If You Have Enough High-Quality Real Data
Use real data whenever possible. It’s more reliable for model training and evaluation. Still, synthetic data can support your project in specific ways:
- Handling rare edge cases
- Running privacy-safe experiments
- Pretraining before fine-tuning
- Transferring models across domains
If Real Data Is Limited or Unavailable
Privacy or Regulatory Constraints
When data is subject to restrictions like GDPR or HIPAA, synthetic data can provide a privacy-compliant workaround. Just make sure to validate the model with real data before deployment.
Rare or Hard-to-Label Events
If your use case involves rare outcomes, like fraud detection or equipment failures, synthetic data can be used to generate examples for underrepresented classes. Pretrain or balance the dataset, and fine-tune using real data later.
Simulation Environments
If the domain supports simulation (e.g. robotics, autonomous driving), use simulation-based synthetic data to build training sets. Always evaluate the model on real inputs to confirm generalization.
If None of These Apply
Before relying on synthetic data, consider simpler alternatives like:
- Data augmentation
- Weak supervision
- Crowdsourcing
Use synthetic data only when these approaches fall short, and always test with real-world data before production.
Evaluating Synthetic Data for ML Use
Creating it is step one. Making sure it’s actually useful? That’s step two. Tools like SDMetrics and Gretel’s reports can help automate the grunt work.
Fidelity vs. Utility Tradeoff
More realistic isn’t always better. High visual fidelity may not correlate with better downstream task performance, especially if models pick up on synthetic artifacts. Sometimes a clean, well-balanced dataset beats photorealistic noise.
Metrics That Matter
Professional data annotation services look at the following metrics:
- Class Distribution: You need balanced classes to create a balanced model
- Label Alignment: Quality data annotation ensures relevant, accurate labels.
- Diversity: Useful variation helps the model generalize beyond training data.
- Utility Scores: You want to keep track of these metrics so you can measure real-world performance gains.
Testing Generalization on Real Holdouts
It’s hard to establish how useful synthetic data generation methods are without real-world examples. It’s convenient to evaluate performance using synthetic test sets but these are often too clean to be of real value.
In the real world, use cases tend to be more messy. That’s why you need to build real holdout data into the supervised learning pipeline. This will give you a true read on generalization and let you see if your model can handle noise, ambiguity, and all the weird edge cases the synthetic set might gloss over.
In my experience, the most critical factor when generating synthetic data is ensuring its distribution aligns with real-world scenarios while introducing meaningful variability. Synthetic data should complement rather than replace real data, filling specific gaps while preserving essential statistical properties. When done right, it improves performance in low-data regions without degrading results elsewhere.

 Chief Executive Officer, Humanize AI Text
Chief Executive Officer, Humanize AI Text
Real and Synthetic Data Blending Strategies
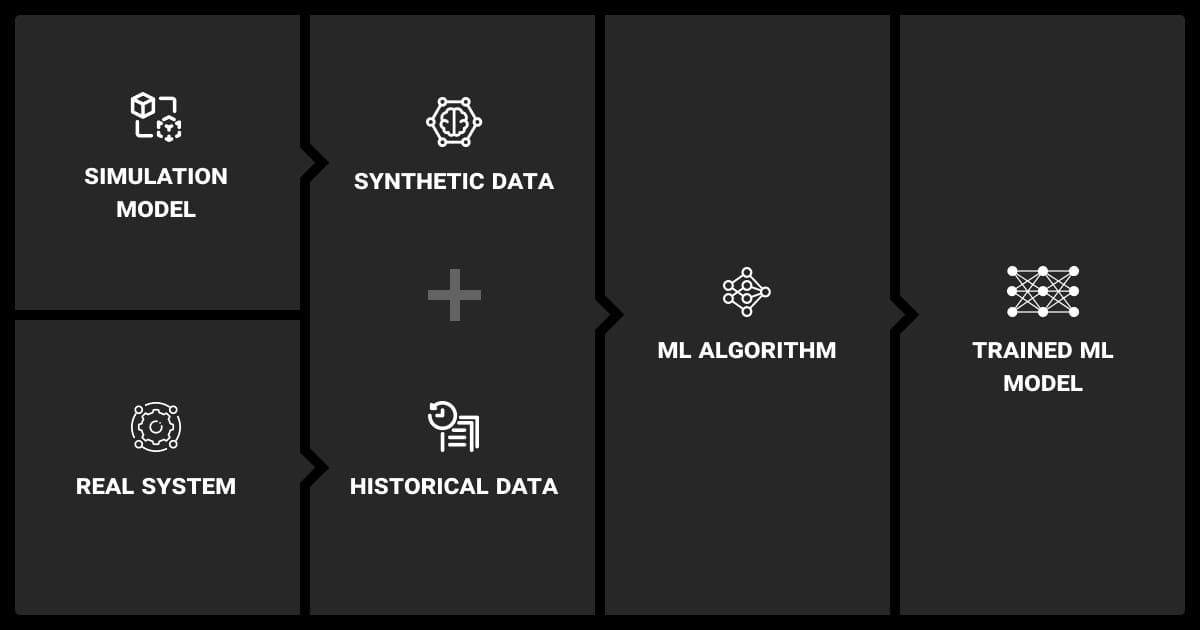
Blending your general and synthetic data generation Python datasets often works better than going all-in on synthetic.
To mix them effectively, you should:
- Use synthetic to expand tiny datasets and supplement LLM data labeling
- Pretrain on synthetic and then fine-tune your model using real data
- Deploy only after validating on real-world data
- Use domain adaptation or transfer learning techniques (adversarial training or CORAL) to bridge the domain gap when mixing different data types.
Want to make synthetic data work in practice? Common use cases include fraud detection, where you can fill in rare fraud types; privacy-sensitive applications, where real faces are replaced with synthetic ones; and rare object detection, where you simulate items like animals, gear, or vehicles to train your model more effectively.
I recommend starting small with a carefully curated synthetic dataset—maybe 10–20% of your training data—then increasing gradually. We’ve done this to mimic real user behavior and always validate on real-world data to catch emerging biases early.

Tools for Synthetic Data Generation
There are a few synthetic data generation tools. You should consider your goals before you settle on one.
Open-Source Libraries
- SDV: Strong for tabular and time-series
- Faker: Lightweight, good for quick prototypes
- Synthpop (R): Privacy-focused, statistically driven
These are perfect for early-stage or academic use.
Commercial Solutions
If you need compliance, support, or scale:
- Mostly AI: Enterprise-ready, privacy-first
- Tonic.ai: Built for secure, scalable data generation
- Gretel.ai: Developer-friendly, multi-format APIs
You’ll pay more, but you get the extras that matter in production.
Synthetic data can distort causal relationships, so validation is key. I always recommend holding out a real test set to measure generalization. It’s also important to apply regularization and compare feature distributions to spot mismatches. Tools like SHAP or LIME can help detect bias introduced during training.
 Machine Learning Expert, Vention
Machine Learning Expert, Vention
Practical Risks and Compliance Considerations
Synthetic data can reduce friction in ML workflows, but it raises important risks around privacy, bias, and compliance you can’t ignore.
Synthetic Data Is Not Legally Risk-Free
Just because it’s synthetic, doesn’t mean it’s exempt from data protection laws. If synthetic data mimics the source too closely, private info might bleed through. And this is where regulators may take exception.
For example, if you’re training image recognition types of LLMs, you have to make sure that the images you use don’t contain identifiable faces. You might need to look into techniques like semantic segmentation that pull out features on a pixel-by-pixel basis, so there aren’t recognizable faces.
Treat it like you would normal data collection in machine learning, and thoroughly scrub any personal details. You can also use differential privacy techniques to quantify and minimize the risk of sensitive information leakage from synthetic datasets.
Bias Amplification and Ethical Red Flags
If your synthetic data copies real biases, your machine learning algorithm will too. You need to make sure that your training data is free of harmful stereotypes, whether it’s real or synthetic. You should always audit synthetic datasets just as you would real ones, especially if they are trained on skewed or biased source data.
Transparency and Auditability
You should treat data generation like code. Keep track of assumptions, parameters, and tools used, and you can reproduce your results. This and synthetic test data generation becomes even more important if you have to maintain compliance.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is synthetic data generation?
It’s the process of building fake, but statistically sound, datasets using algorithms instead of real-world collection. You can use GANs, rule-based systems, or simulations, depending on your project.
What is meant by synthetic generation?
It’s a broad term for creating data from scratch with code. It covers everything from simple tabular rows to complex 3D worlds.
What is an example of a synthetic dataset?
An example of a synthetic dataset might be a fake transaction to train a model to detect fraud. You could also look at a driving simulator where every frame is labeled and artificially rendered.
What’s the main benefit of generating synthetic data?
Freedom. You’re free from privacy rules, slow labeling cycles, and rare edge cases. You build what you need, when you need it. This can speed up training and reduce the costs. It can also improve generalization, if you use it wisely.
Synthetic data generation using generative AI can add variety and help with underrepresented classes, but it should support, not replace, real data.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.