ADAS Data: Annotation Challenges & Best Practices

 CEO of Label Your Data
CEO of Label Your Data

TL;DR
- A 95% accurate classifier is fine for cats and dogs, but in ADAS that same accuracy is a product recall waiting to happen.
- We've watched smart annotation programs die in the same five places, every single time: sensor fusion, 3D cuboid throughput, edge cases, tracking, and taxonomy drift.
- The annotation partner who can start tomorrow at the lowest per-image rate is almost always the wrong one for ADAS, and the math on multi-year continuity is what proves it.
A perception model can pass simulation and hit every metric on nuScenes. Then it meets a rainy night and a partially-occluded cyclist, and the false-positive rate doubles. That is the moment most ADAS teams realize their problem was never the model.
In this article, you’ll learn what makes ADAS data different and where annotation programs typically break.
Importance of Data in ADAS Systems
ADAS data is the labeled multi-sensor input used to train and validate advanced driver-assistance systems before they ship in production vehicles.
The quality of ADAS data for automotive safety determines whether features like automatic emergency braking pass validation, or trigger product recalls after deployment. And so its importance comes down to one fact: a perception team can change models in a sprint, but replacing a year of badly-captured sensor data takes a year.
Get this part wrong and you spend the next year fighting label inconsistencies that started in the calibration files.
NHTSA’s FMVSS No. 127 rule requires automatic emergency braking with pedestrian detection on every new U.S. passenger car and light truck sold from September 2029, putting concrete pressure on the ADAS data programs producing the training sets these systems learn from.

ADAS data vs standard computer vision data
ADAS data is harder than standard CV data because it has to capture every long-tail edge case a vehicle might encounter at speed, across multiple sensors with frame-perfect synchronization. The quality bar is also higher, since a missed label has direct safety implications.
| Dimension | Standard CV | ADAS Data |
| Accuracy target | 90-95% acceptable | 98%+ on safety-critical classes |
| Sensors | Usually single (camera) | Multi-sensor, sub-millisecond synced |
| Objects per scene | 1-5 typical | 20-60 in dense urban frames |
| Cost of a missed label | Retrain and ship | Recall, regulatory exposure |
| Data distribution | Roughly uniform | Long-tail; rare events drive failure |
Put together, these differences mean an ADAS annotation program needs different data annotation tools and QA practices than a standard CV pipeline can supply, with team continuity becoming a much higher priority.
ADAS Data Capture and Processing by Sensor Type
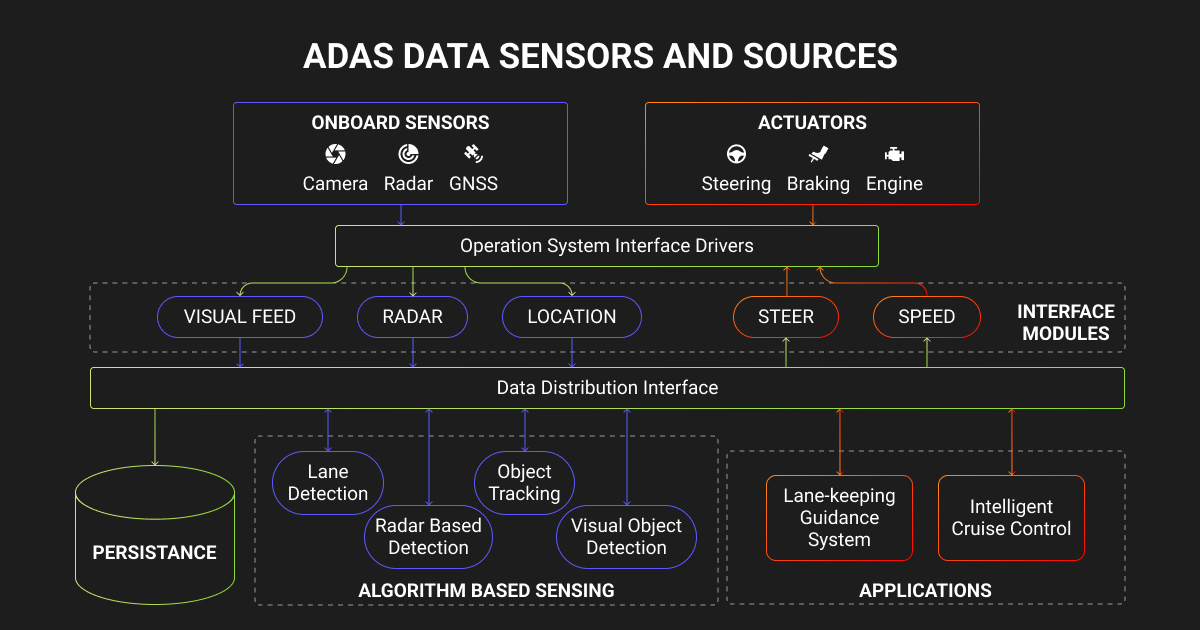
ADAS data collection and processing is the upstream half of the pipeline. It covers sensor selection, time synchronization, ingestion, and scenario filtering, with data processing in ADAS systems also covering the downstream handoff into labeling.
An ADAS dataset usually pairs camera frames and LiDAR point clouds with radar returns, labeled with 2D boxes, 3D cuboids, semantic segmentation, lane geometry, and behavior tags. If your team is building lane keep, adaptive cruise, automatic emergency braking, traffic jam assist, or any L2+/L3 feature, you are working with ADAS data.
Camera-based ADAS data integration
Camera data is the workhorse of ADAS, and the easiest sensor stream to mishandle. A six-camera surround setup at 30 FPS produces around 650,000 frames per vehicle per hour of driving. Multiply that by a fleet, multiply that by every weather and lighting condition you care about, and you understand why most ADAS teams cannot label their full corpus.
Best-practice camera ingestion looks like this:
- Synchronize timestamps to LiDAR and IMU at sub-millisecond accuracy
- Tag every frame at capture with lighting and weather metadata, plus road type
- Run automatic quality filters for blur and lens occlusion before annotation
- Sample for diversity, not volume
We saw this play out with Elefant Racing, the German Formula Student team building the FR20 Ragnarök autonomous race car. Their perception stack ran on cameras detecting traffic cones, and they needed bounding boxes and keypoint annotations to teach the model both the position of each cone and its orientation for the planning module.
Across the project, our team at Label Your Data annotated 2,244 images, adding 25,951 bounding boxes and 171,572 keypoints. Elefant Racing’s car went on to take 1st place in Design Judging at Formula Student East.
Radar and LiDAR data for ADAS
ADAS sensor data analysis lives or dies on LiDAR. A single 64-beam sweep can contain 100,000+ points, and annotating one 3D cuboid that hugs the geometry of a partially-occluded vehicle takes 30 to 90 seconds even for trained annotators. ADAS scenes commonly contain 20 to 60 objects per frame.
Safety-grade quality at this throughput comes from annotator continuity over years, not from throwing more headcount at the problem. Take Ouster, a US-based provider of digital LiDAR sensors and a Label Your Data partner since 2020.
Our annotation team scaled from 2 to 10 people with around 10% annual turnover and delivered a 20% lift in product performance and a 0.95 detection F1 score on their LiDAR scans. 3D cuboid quality is a function of annotator continuity, and that is hard to outsource to a transactional vendor.
Radar sits alongside LiDAR in most ADAS stacks, but the data annotation work is different in shape. Radar returns show up as range-Doppler heatmaps and point clusters rather than dense 3D geometry, and annotation typically focuses on object association: linking a radar return to the camera or LiDAR detection of the same physical object across time.
It is fusion-side work, and the annotators who do it well are the ones who understand sensor physics.
Ultrasonic sensor data in ADAS
Ultrasonic data sits in the background of most ADAS conversations because it does not produce visual outputs your team will look at directly.
It shows up as proximity readings, and it is mostly used for low-speed scenarios like parking assist and curb detection, where volumes are smaller and ground truth often comes from physical measurements rather than human labels.
5 Biggest ADAS Data Annotation Challenges
Most ADAS annotation programs run into the same five problems:
| Challenge | Where it shows up | How to fix it |
| Sensor fusion alignment | Inconsistent labels across LiDAR, camera, radar | Annotators trained on fused views; calibration as a first-class artifact |
| 3D cuboids at scale | LiDAR program throughput collapses | Model-assisted pre-labels + human QA |
| Long-tail edge cases | 95% of collected data is routine driving | Scenario taxonomy + active mining |
| Temporal consistency | Track IDs swap across occlusions | Multi-frame review + dedicated tracking QA |
| Class taxonomy drift | Eval sets stop being trustworthy | Versioned taxonomy + backfill on changes |
Sensor fusion alignment
Fusion of sensor data in ADAS systems is where annotation programs hit their hardest problem. Annotating a 3D cuboid in LiDAR is solvable; aligning it with the corresponding camera bounding box and radar return, all anchored to the IMU-corrected ego pose, is a different problem.
Get this wrong and you poison your fusion model long before anyone catches it in evaluation. The fix is process discipline, treating calibration files as first-class artifacts and running annotation QA pipelines that validate cross-sensor consistency frame by frame.
3D cuboids at scale
3D cuboid throughput is the hidden cost in any LiDAR program. A trained annotator produces maybe 60 to 120 high-quality cuboids per hour in dense urban scenes. AI in ADAS data processing carries some of the load, with SAM-style pre-labels and active learning cutting throughput costs meaningfully when paired with strong human QA.
Long-tail edge cases
A common rule of thumb is that 95% of fleet-captured driving is routine and 5% is interesting events, with the 5% being what matters for ADAS training. Surfacing it requires scenario tagging and near-miss mining, plus the lighting and weather metadata most teams retrofit too late.
Case in point, NODAR, a US-based 3D depth perception company building stereo vision for autonomous driving, ran into exactly this. Public machine learning datasets did not cover their sensor-specific edge cases, and their internal team lacked the bandwidth for high-volume polygon work across parallel model pipelines.
Our team handled full-cycle annotation on 1-2k images per dataset using CVAT alongside NODAR’s internal tooling, with each batch starting from a pilot task and a live training call before scaling to 10-20 annotators. Turnaround held at 3-4 weeks per dataset, with no rework.
Temporal consistency in tracking
Multi-frame object tracking is where ADAS annotation quality dies quietly. Annotators who do single-frame work well will swap track IDs across occlusions, lose pedestrians behind buses, and create phantom tracks in low-light frames. Your prediction and planning models inherit every one of those mistakes.
A data annotation company that gets this right rotates the same annotators through the same scenes over multi-frame sequences, with a QA pass dedicated to track ID stability.
Class taxonomy drift
You start with a clean taxonomy, and six months in your annotators are tagging “scooter” three different ways and the child-vs-adult split is inconsistent.
Taxonomy drift is the single most common reason ADAS evaluation sets stop being trustworthy. Lock the taxonomy, version it, and treat any change like a schema migration in a database, with backfill on the historical labels.
Best Practices for ADAS Data Annotation in 2026
You can avoid most of the pain above with a small number of disciplines:
- Define the taxonomy before you collect. Run a calibration round with 5 to 10 annotators on a 200-clip sample, resolve disagreements, then lock the spec. Only then scale.
- Treat QA as a pipeline, not a spot check. Layered QA with annotator self-checks plus dedicated reviewers is now standard for safety-grade work and adds 15 to 20% to base data annotation pricing. A bad evaluation set costs much more.
- Mine for edge cases continuously. Use embedding similarity and model uncertainty to surface where your perception stack is weak, and label there rather than uniformly.
- Stay tool-agnostic. Your perception team will change tools. Your data engineering team will change pipelines. Your annotation partner should plug into whatever you use today, not force a migration.
- Treat annotation as a continuous program. ADAS models retrain monthly and expand to new cities. Project-based annotation breaks under that load, while multi-year programs with dedicated teams hold up.
How to Evaluate an ADAS Data Partner for AV Projects
If you are actively scoping a vendor for data annotation services, here is the short list that actually matters for ADAS work.
- Genuine 3D and multi-sensor experience. Ask for a redacted sample of LiDAR cuboid work and how they handle cross-sensor consistency. Generic CV vendors will struggle here.
- Trained, dedicated annotation teams. Crowdsourced labor does not get to safety-grade accuracy on ADAS. Look for dedicated teams with NDAs and secure workspaces.
- Layered QA with measurable accuracy. Ask about their QA pipeline and disagreement resolution. Look for partners who meet your accuracy targets with audit logs to prove it.
- Compliance posture. ISO 27001 and GDPR should be table stakes, with automotive-specific standards like TISAX often required for OEM and Tier 1 work.
- Tool agnosticism. A partner who tries to lock you into their proprietary platform is solving their problem, not yours.
What you do not want is a transactional vendor who competes on per-image pricing and turnaround speed but does not understand your safety case.
ADAS programs require a specialist AI data partner, like Label Your Data, with deep delivery experience in CV and 3D for mobility and autonomous systems, from startups through to enterprise OEMs. Multi-year projects with clients like Ouster and NODAR have given our team genuine depth in LiDAR and sensor fusion, plus the operational discipline that ADAS work demands.
If that sounds like the partner your ADAS project needs, let’s talk through your sensor stack and accuracy targets.
About Label Your Data
If you choose to delegate ADAS data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Check our performance based on a free trial
Pay per labeled object or per annotation hour
Working with every annotation tool, even your custom tools
Work with a data-certified vendor: PCI DSS Level 1, ISO:2700, GDPR, CCPA
FAQ
What is ADAS data?
ADAS data is the labeled multi-sensor input used to train and validate advanced driver-assistance systems before they ship in production vehicles. It typically combines synchronized camera, LiDAR, and radar streams with annotations like 2D bounding boxes, 3D cuboids, semantic segmentation, lane geometry, and behavior tags.
The quality and diversity of this data is the single biggest determinant of whether an ADAS feature passes safety validation.
How does ADAS work?
ADAS works by combining sensor data, perception models, and decision logic to assist or automate parts of the driving task. Cameras, LiDAR, radar, and ultrasonic sensors capture the vehicle’s surroundings in real time.
Perception models trained on annotated ADAS data classify and locate objects in those sensor streams, and decision-making software uses that output to trigger features like automatic emergency braking, lane keep, or adaptive cruise.
The performance of the machine learning algorithm at the perception layer depends heavily on the quality of the training data underneath it, which is where annotated data becomes the bottleneck.
Can public datasets replace custom ADAS data annotation?
Public datasets like KITTI, nuScenes, Waymo Open Dataset, and Argoverse are useful for benchmarking and early prototyping, but they cannot replace custom annotation for a production ADAS program.
They use different sensor configurations than your vehicle, lack the edge cases specific to your operating geography, and do not reflect the failure modes your perception model needs to handle in deployment. Most production teams use public datasets for initial training and bootstrap evaluation, then transition to fully custom-annotated data for refinement and validation.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.