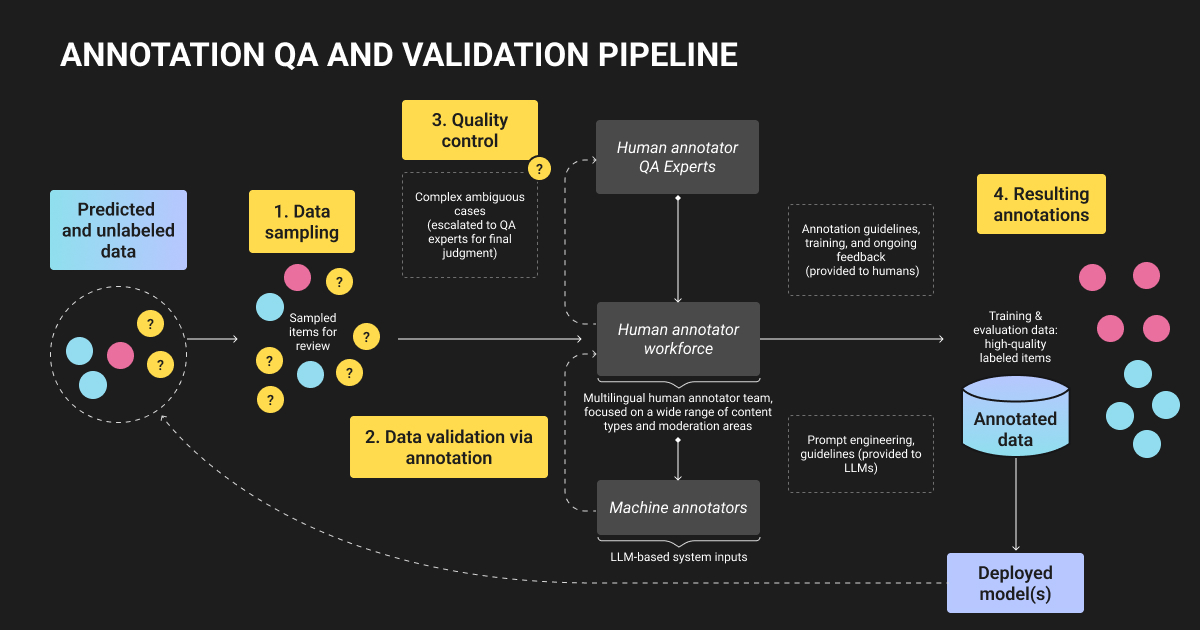
Annotation QA: Best Practices for ML Model Quality

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
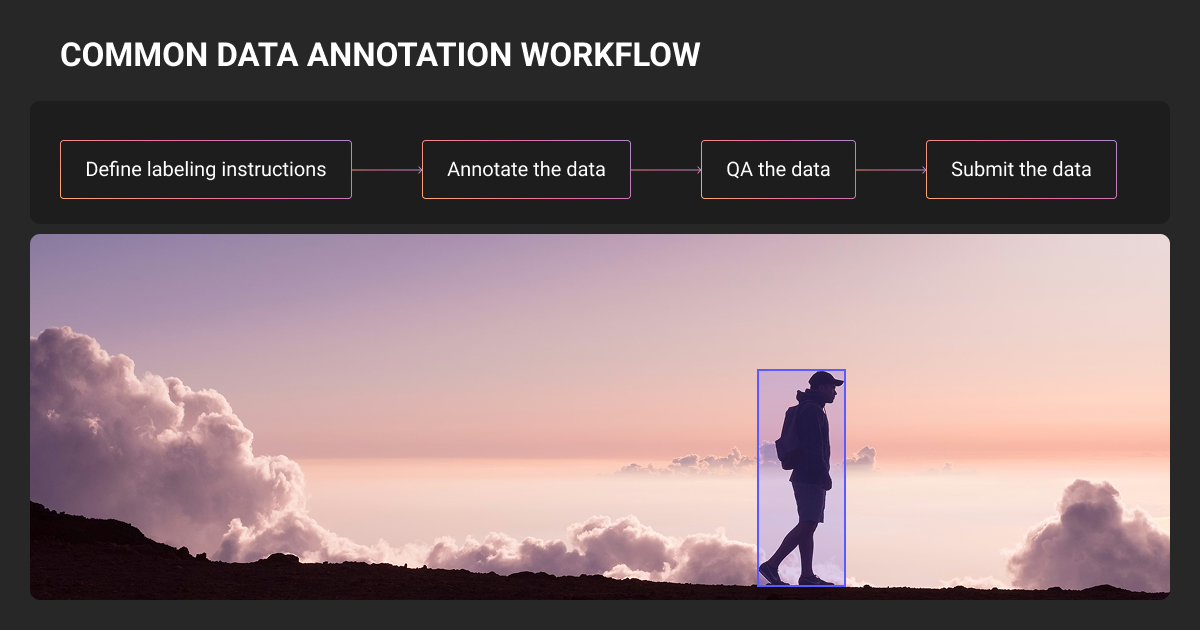
- What Is Annotation QA and Why It Matters
- Measuring Data Quality Assurance in AI Data Annotation
- The Labeling Instructions Problem: Why Annotation QA Alone Fails
- QA Process Annotation Techniques That Actually Work
- How We Implement Annotation QA at Label Your Data
- Annotation Companies vs. Crowdsourcing: The Real Quality Gap
- Automated Annotation QA: Using ML to Validate Annotations
- Allocating QA Process Annotation Budget for Maximum ROI
- Key Actions for ML Engineers Implementing Annotation QA
- About Label Your Data
-
FAQ
- How do I know if my current annotation QA process is effective?
- Should I use the same annotation QA approach for all annotation types?
- How do I check whether poor model performance is caused by annotation quality or something else?
- How long should the pilot phase last before scaling to full production?
- What’s the minimum team size needed for effective annotation QA?
TL;DR
- Detailed labeling instructions improve annotation quality more than adding QA review layers.
- Target QA strategically on challenging data characteristics using confidence-based sampling, as this cuts review time by 50-80% while maintaining accuracy.
- Managed annotation teams outperform crowdsourcing platforms on QA and cost with structured workflows and zero spam annotations.
Your vendor says they do quality assurance in data annotation. Your machine learning datasets still cause model failures in production. The problem is that most QA processes fix symptoms while missing root causes.
Research analyzing 57,648 annotations from 924 annotators found something counterintuitive: improving labeling instructions delivers better results than adding QA layers. Annotation companies’ internal QA provided marginal improvements at best, while annotators working with detailed visual guidelines outperformed those with basic instructions even when the latter received additional review.
This article examines what actually works in annotation QA to help you:
- See quality measurement approaches
- Understand when QA helps versus when it wastes money
- Learn how to allocate resources for measurable improvement
What Is Annotation QA and Why It Matters
Data quality assurance in AI data annotation verifies that labeled training data meets accuracy standards before it reaches model training. The stakes are higher than most teams realize.
Case in point, MIT researchers found that even ImageNet contains approximately 6% label errors. Production pipelines average 10% error rates, according to Apple ML Research. When 40% of labels contain mistakes, measured model performance drops to just 46.5% of potential capacity.
Missing annotations directly reduce recall because your model never learns that objects exist. Location errors affect both precision and recall. A welding defect detection study revealed that annotator habits create systematic bias: left boundary annotations were consistently less accurate than right boundaries, causing measurable performance degradation as this accumulated.
However, not all annotators deliver the same quality assurance in data annotation. Tool wear segmentation studies found expert annotators achieved an mIoU of 0.8153, while novices scored significantly lower.
Professional and GDPR-compliant data annotation services that employ and train expert annotators can close this capability gap.
Measuring Data Quality Assurance in AI Data Annotation
For spatial tasks (segmentation, detection)
Intersection over Union (IoU) remains the primary metric. Aim for inter-annotator IoU ≥ 0.75 for production segmentation. Studies show skilled annotators average 90% IoU for interactive segmentation tasks.
The Dice coefficient is less sensitive to small boundary variations, making it useful for medical imaging. For example, research on surgical instrument segmentation used both DSC and Normalized Surface Distance (NSD) as complementary metrics. DSC improvements didn’t always correlate with NSD gains, so use both.
Boundary IoU evaluates edge accuracy rather than overall mask overlap. This matters for autonomous driving, where pedestrian edges must be pixel-precise. Detection error analysis shows small objects and unusual aspect ratios cause disproportionate performance impact. Make sure to allocate extra annotation QA attention there.
For inter-annotator agreement
All kappa metrics share the same structure: κ = (observed agreement - chance agreement) / (1 - chance agreement).
- Cohen’s Kappa: Two annotators only. 0.81-1.00 is almost perfect.
- Fleiss’ Kappa: Multiple annotators, same items. Production threshold: > 0.6.
- Krippendorff’s alpha: Handles missing data and varying annotators per item; use this when workload gets distributed. Target: 0.7-0.8 for production.
Error severity hierarchy
| Error Type | Impact | Why It Matters |
| Missing annotations | Critical | Model never learns object exists |
| Location/boundary errors | High | Degrades both precision and recall |
| Incorrect class labels | Moderate | Causes category confusion |
| Spurious annotations | Moderate | Increases false positives |
For subjective tasks, disagreement often reflects valid perspectives rather than annotation errors.
We worked with a PhD researcher at Technological University Dublin on propaganda detection in news articles. Even expert annotators with linguistic backgrounds showed persistent disagreement on certain categories. We implemented a cross-reference QA process annotation with three annotators labeling identical sentences and reviewing disagreements.
“The [Label Your Data] annotators were genuinely interested in the success of my project, asked good questions, and were flexible in working in my proprietary software environment.” — Kyle Hamilton, PhD Researcher at TU Dublin
For subjective tasks, disagreement sometimes reflects valid different perspectives rather than errors requiring correction.
The Labeling Instructions Problem: Why Annotation QA Alone Fails
A 2024 study we mentioned earlier delivered a finding that should reshape how you allocate budgets: annotation companies’ internal QA provides only marginal improvements when instructions are poor.
The study tested three instruction types:
- Minimal text (168 words, 7 slides): 18-25% severe error rates
- Extended text (446 words, 10 slides): 12-20% severe error rates
- Extended text with pictures (961 words, 16 slides): 9-16% severe error rates
Annotators using picture-rich instructions outperformed those with minimal guidelines even when the latter received additional QA review. For some companies, annotation QA provided zero improvement. The remaining companies achieved less than 2% relative improvement from QA when annotators already had detailed instructions.
A Hacker News practitioner explained the root cause: “In situations where there are some ambiguities, annotators would pick one interpretation and just go with it without really making the effort to verify.” It's not that annotators are careless. It's that instructions are ambiguous.
Instruction failures that multiply QA costs:
- Ambiguous terminology (Google's search quality guidelines define even basic terms)
- Missing edge case guidance (forcing incorrect choices)
- No visual examples (causing interpretation drift)
- Missing decision trees (complex decisions need structured paths)
- Absent "why" (annotators who don't understand purpose make worse judgments)
Framework for effective instructions:
- Why: Business context and how outputs will be used
- What: Define all terms explicitly; break complex tasks into subtasks
- How: Decision trees, abundant examples, counter-examples
- Logistics: Time expectations, uncertainty handling, tool usage
I use QA to identify the most likely erroneous predictions in a real-world context, not random samples. I define slices representing the highest production risk: low confidence predictions, high disagreement between annotators, and domain-specific language that historically caused struggles. The purpose is to prevent failures before they're deployed to end users.

 Founder, Deep AI
Founder, Deep AI
QA Process Annotation Techniques That Actually Work
When consensus helps (and when it doesn’t)
Cleanlab’s CROWDLAB trains a classifier on initial consensus, then refines using predicted probabilities. This approach improves accuracy by incorporating model predictions rather than relying solely on annotation patterns.
Consensus works when:
- Clear objective ground truth exists
- Tasks are well-defined with unambiguous guidelines
- You're filtering individual annotator noise
Apply 3-5 fold consensus on 3% of data to create gold standards.
Consensus fails when:
- Tasks are subjective (affect detection, hate speech)
- Disagreement reflects valid perspectives
- Ambiguity is inherent
For example, we worked with King Abdullah University (KAUST) on a palm tree detection project that achieved 98%+ accuracy through pilot validation. The client reviewed the first 10% before we scaled. The 17-day project used a single annotator trained in QGIS, demonstrating that consistency sometimes matters more than consensus when instructions are detailed.
“The collaboration with Label Your Data was seamless, allowing us to focus on model development instead of spending valuable time on manual labeling.” — PhD student of Computer Science, KAUST
Strategic QA allocation based on data characteristics
Computer vision research analyzing 57,648 annotations investigated whether QA effectiveness depends on specific image characteristics. For image recognition tasks, the QA process annotation significantly improved quality for:
- Underexposed objects
- Intersecting objects
- Objects occluded by background
Domain-specific characteristics showed no significant benefit. This principle applies beyond images: classify your datasets by difficulty and allocate QA toward challenging subsets rather than blanket review.
Uncertainty sampling prioritizes review based on model predictions: sort by entropy, flag low-confidence samples, and focus on decision boundaries.
| Sample Category | QA Coverage | Rationale |
| High uncertainty predictions | 100% initially | Highest error risk |
| Rare/minority classes | Oversample | Often underperformed |
| Normal/easy cases | 5-10% random | Spot-check for drift |
| New annotator work | 100% initially | Quality calibration |
| Edge cases (occlusion, small objects) | 100% review | High ambiguity |
How We Implement Annotation QA at Label Your Data
We maintain 98% data annotation QA accuracy at Label Your Data by applying what the research shows actually works: instruction quality first, targeted QA second.
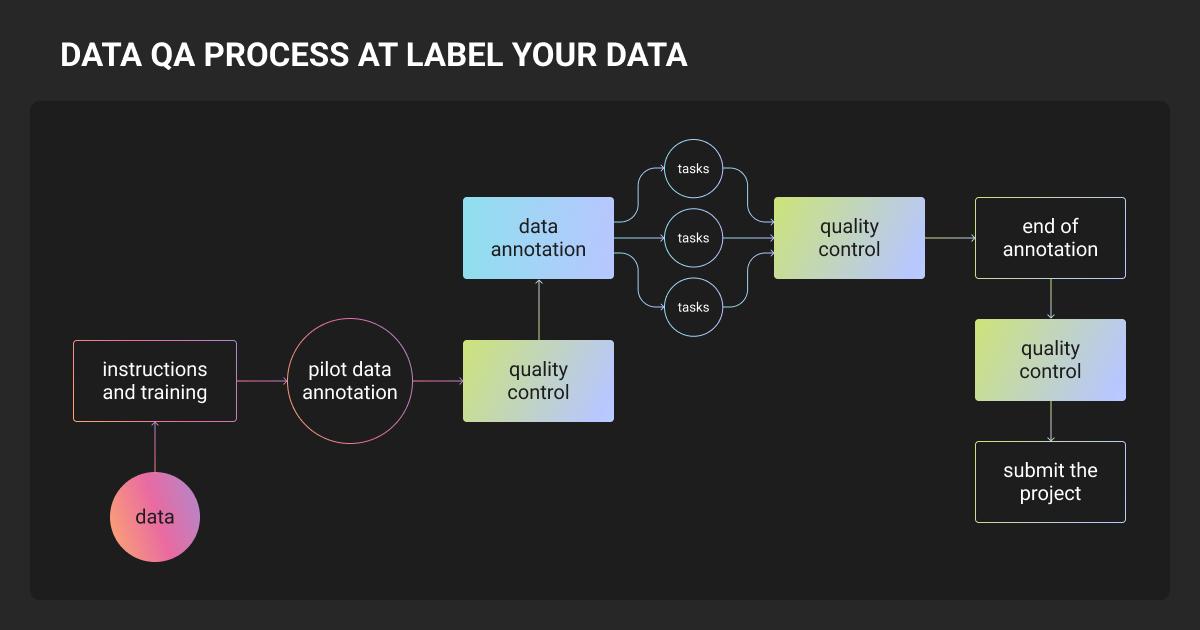
Instruction design and training
Our projects begin with comprehensive documentation of labeling criteria, edge cases, and machine learning requirements. All team members complete project-specific training before handling production data, passing benchmark tests on representative samples.
For a 3D computer vision project with Nodar building depth-mapping software, we handled up to 2,000 images per dataset with approximately 60,000 objects labeled. The workflow: pilot feedback → detailed documentation → live training calls → scaled to 10-20 annotators with 2-3 QA reviewers.
“I'm impressed with how easy communication is and how simple and effective the process has been. Everything is delivered on time and handled professionally.” — Piotr Swierczynski, VP Engineering, Nodar
Pilot validation and milestone-based gates
Small dataset portions undergo pilot tests before full production. We assess results against requirements, identify guideline gaps, and prevent systematic errors.
In the Nodar project, a pilot kicked off each batch. We refined guidelines through feedback before scaling, with edge cases tracked in shared logs. The 3-4 week turnaround per dataset stayed on schedule through a milestone-based structure, with no rework required.
For AirSeed Technologies’ drone reforestation project, we annotated 50 large geofiles over 5 months. Annotators labeled 50 test polygons each, reviewed by QA. No rework was required after the first round.
“The [Label Your Data] workflow was smooth, progress was steady, and the quality consistently met our expectations.” — Jared Reabow, VP Engineering, AirSeed Technologies
Adaptive workflows for different task types
We use multiple annotators for subjective or high-stakes tasks.
For Skylum’s photo editing software, we collected 6,000 images and labeled 70,000 detailed face and body parts, such as lips, eyes, blemishes, and scars. Data collection ran parallel to annotation to maintain pace. A team of 7 human annotators scaled through with minimal revision cycles.
“What stands out is their [Label Your Data] ability to scale any data collection and annotation process. The fast responses and iterative workflow mean we always get quality data right when we need it.” — Oleksii Tretiak, Head of R&D, Skylum
Read this in-depth Label Your Data company review to see how clients across computer vision, NLP, and other projects have experienced this approach.
Annotation Companies vs. Crowdsourcing: The Real Quality Gap
Why structured annotation teams win
- Training consistency: The same team retains context and institutional knowledge. Crowdsourcing workers start from scratch each time.
- Domain expertise: Medical imaging and autonomous vehicles require expertise that can't fit in task instructions. A data annotation company hires annotators with relevant backgrounds.
- Feedback loops: Direct communication enables real-time clarification. On platforms, delayed interaction means ambiguities get resolved incorrectly.
- Knowledge retention: Managed teams develop intuition about sensor artifacts and lighting conditions over weeks. On MTurk, each worker starts from zero.
Beyond base data annotation pricing, crowdsourcing requires significant internal resources for quality review, spam filtering, and managing inconsistencies across distributed workers.
Decision framework
Crowdsourcing works for early-stage proof-of-concept projects, simple objective tasks like basic classification, and large volumes of straightforward labeling where you can validate quality through consensus. It makes sense when data is non-sensitive and task instructions are unambiguous.
Managed teams become essential for safety-critical applications where errors have real consequences, complex annotation requiring domain expertise, sensitive or regulated data with compliance requirements, and long-term projects where knowledge retention compounds value over time.
Our AI struggled with unusual facial features or tricky lighting. We tried a new system: two people tag the same weird picture separately. If they disagree, a third person decides. After a few months, those bizarre mistakes mostly disappeared.
 Founder, Fotoria
Founder, Fotoria
Automated Annotation QA: Using ML to Validate Annotations

Model-based validation
Modern data annotation tools use confidence-based error detection to automatically flag annotations needing review. These tools analyze model prediction probabilities to prioritize samples most likely to contain mistakes, cutting manual QA time significantly.
Embedding-based analysis reveals patterns statistical metrics miss. By projecting samples into semantic space using CLIP, you can spot clusters of similar images with inconsistent annotations. Berkshire Grey, an AI robotics company, achieved 3× faster error investigations this way.
Active learning optimizes which data gets labeled first. Start by sampling typical examples at low budgets. Scale up by targeting high-uncertainty samples that provide maximum information gain.
Heuristic checks before human review
| Check Type | Rule | Reliability |
| Format validation | Label format correctness | High |
| Empty/invalid boxes | Zero area, out-of-bounds | High |
| Duplicate detection | Embedding-based similarity | High |
| Extreme aspect ratios | Flag ratios >10:1 | High |
Hybrid workflow
Automated pre-filtering → AI pre-labeling → Human refinement → Automated QA → Targeted human review → Feedback loop
This achieves a 60-80% time reduction while maintaining quality. Automation handles format validation and flagging; human annotation experts handle ambiguous cases and final validation.
Most annotation failures in production aren't caused by 'bad labels' but by unexamined assumptions baked into the pipeline. We build QA directly into the annotation workflow, rather than treating it as downstream review. Robust QA is about making the data pipeline observable and falsifiable.

Allocating QA Process Annotation Budget for Maximum ROI
QA sampling levels by project phase
| Project Phase | Sample Rate | Rationale |
| Pilot | 100% | Build gold standards |
| Ramp-up | 20-30% | Stabilization |
| Production | 5-10% | Statistical monitoring |
| Maintenance | Targeted | New patterns/edge cases |
Where to invest your annotation budget
- Instructions first (15-20%): Detailed guidelines with visual examples and edge cases deliver the biggest quality gains. This upfront investment prevents errors better than adding review layers later.
- Targeted QA second (10-15%): Focus on high-uncertainty predictions, rare classes, and challenging characteristics like underexposure, occlusion, and intersection. Skip blanket review.
- Spot-checking last (5-10%): Use for drift monitoring and validation when your team already works with strong instructions.
Track these metrics:
- Inter-annotator agreement > 0.8
- Rework rate < 15-20%
- Ground truth accuracy > 0.9
What works: Multi-annotator consensus to build gold standards, then refine instructions. Multi-layer QA with self-review and spot checks. Active learning for high-uncertainty samples.
What fails: Over-relying on automation without manual validation. Majority voting for subjective tasks. Paying per task instead of per hour.
Key Actions for ML Engineers Implementing Annotation QA
- Invest disproportionately in guideline development with visual examples, decision trees, and edge cases. This delivers larger improvements than adding QA stages.
- Implement confidence-based sampling using model uncertainty to prioritize review. Focus QA on underexposure, occlusion, and intersection.
- Track inter-annotator agreement continuously. Drops below 0.8 indicate guideline ambiguity requiring instruction clarification, not more QA.
- Use hybrid workflows combining AI pre-labeling with human refinement for a 60-80% time reduction.
- Match approach to requirements: crowdsourcing for simple classification, managed teams for safety-critical work.
The difference between good and excellent annotation QA is often the difference between models that work in production and those that fail catastrophically at edge cases.
Building this internally takes time. Or you can work with a team that already implements these research-backed approaches.
About Label Your Data
If you choose to delegate data annotation with strategic QA processes, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
How do I know if my current annotation QA process is effective?
Track three key indicators: inter-annotator agreement (should be >0.8), rework rate (should be <15-20%), and ground truth accuracy on held-out test sets (should be >0.9).
If your QA team is modifying more than 30% of annotations, that’s a red flag indicating instruction problems rather than annotator issues. Also monitor whether QA catches errors that would impact model performance versus cosmetic differences that won’t affect training outcomes.
Should I use the same annotation QA approach for all annotation types?
No. Bounding boxes benefit from automated heuristic checks (aspect ratios, size thresholds, overlap detection) that can flag obvious errors quickly. Segmentation tasks require more nuanced boundary review, where the Dice coefficient and Boundary IoU provide different insights.
Classification tasks with subjective elements (sentiment, content moderation) often need consensus approaches, while objective classification can use confidence-based sampling. Match your QA intensity to task complexity and business risk.
How do I check whether poor model performance is caused by annotation quality or something else?
Manually review 100-200 samples where your machine learning algorithm has high loss or low confidence predictions. If you find systematic annotation errors (missed objects, wrong boundaries, inconsistent labels), that's your bottleneck.
If annotations are correct but the model still struggles, look at architecture or training strategy. A quick test: have a senior annotator re-label 50 examples from your lowest-performing class with perfect accuracy. Retrain on just that corrected subset: if performance jumps significantly, annotation quality is limiting your model.
How long should the pilot phase last before scaling to full production?
For most projects, annotate 5-10% of your total dataset as a pilot or 100-200 samples minimum, whichever is larger. Run this through complete QA review, measure inter-annotator agreement, and identify instruction gaps.
If you see agreement >0.8 and severe error rates <10%, you can scale. If not, refine instructions and run another small pilot batch. Skipping this step to save time usually costs more in rework later.
What’s the minimum team size needed for effective annotation QA?
You can start with as few as 2-3 annotators plus 1 QA reviewer for projects under 5,000 annotations. The key is having enough annotators to measure inter-rater agreement and one experienced reviewer who can provide consistent feedback. For larger projects (50,000+ annotations), aim for teams of 8-12 annotators with 2-3 QA specialists.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.