How to Automate Dataset Prep with GPT4V (And What It Misses)

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What GPT-4 Vision Actually Does for Image Annotation
- How Auto-Annotation with GPT4V Works in Practice
- Where GPT4V Breaks (And Why It Matters)
- The Hybrid GPT-4 Vision Workflow That Works
- Why Data Quality Still Beats Model Size
- When to Stop Prompting and Start Fine-Tuning
- GPT-4 Vision in Practice (Tips from Engineering Leaders)
- Should You Use GPT4V for Your Image Dataset?
- About Label Your Data
- FAQ

TL;DR
- GPT-4V accelerates image annotation by generating first-pass semantic tags, but it hallucinates objects, miscounts, and fails at precise localization.
- Hybrid workflow (GPT-4V pre-labeling + human verification) cuts annotation time by 30% while maintaining the data quality needed for model training.
- Fine-tuning smaller models on GPT-4V-seeded, human-corrected datasets delivers better accuracy, lower cost, and faster inference than using the API for production.
What GPT-4 Vision Actually Does for Image Annotation
You need 10,000 labeled images to train your computer vision model. Handle data annotation wrong, and costs spiral. Bad labels require expensive rework, and quality issues can delay production. GPT4V promises to automate the process: just feed it images and get labels back.
- But can you trust it?
- Will it hallucinate objects?
- Miss critical details?
- Generate labels accurate enough to train a production model?
In a nutshell, GPT-4 Vision works, but not the way most ML engineers expect. It’s not a replacement for human annotation experts. It’s a pre-labeling accelerator that cuts annotation time by 30-50% when used correctly. Use it wrong, and you’ll waste money on API calls while training models on corrupted data.
This guide breaks down what GPT-4 with Vision actually does for image annotation, where it fails, and how to build a workflow that combines its speed with human precision.
What GPT4V is and what it does
GPT-4V is a multimodal model that takes an image and returns text (e.g., tags, captions, object descriptions, OCR output).
For engineers, this means one thing: rapid first-pass labeling. You need 10,000 annotated images. GPT4V can generate rough labels in hours instead of weeks.
What it’s good at
- Image recognition and semantic tagging. Identifies objects, scenes, activities. A kitchen photo? It recognizes the stove, cutting board, knife, and vegetables.
- Scene reasoning. Describes relationships. "A person chopping onions on a wooden board next to a boiling pot."
- OCR. Reads text from images: street signs, product labels, handwritten notes, charts. Works across multiple languages.
- Natural descriptions. Generates human-readable captions, not just rigid label lists.
What it’s weak at
- Precise localization. Bounding box coordinates are often wrong. One study tested it on locating a telephone pole, coordinates were off.
- Counting. Can’t count dice dots correctly. Fails on "how many X are in this image" queries.
- Domain-specific attributes. Struggles with medical imaging features, satellite imagery details, rare species identification.
- Temporal reasoning. Feed it video frames, and it misses objects disappearing between shots. One experiment: it completely ignored an air conditioner vanishing from a scene.
Why engineers use it anyway
Speed and bootstrapping. You get 10,000 rough labels in hours. Human data labelers then verify and correct them, which is approximately 30% faster than annotating from scratch.
GPT-4 Vision doesn’t replace your annotation pipeline. It front-loads it. You accept ~20% error rate on first-pass labels in exchange for 10x faster throughput, then allocate human review to catch hallucinations and edge cases.
How Auto-Annotation with GPT4V Works in Practice
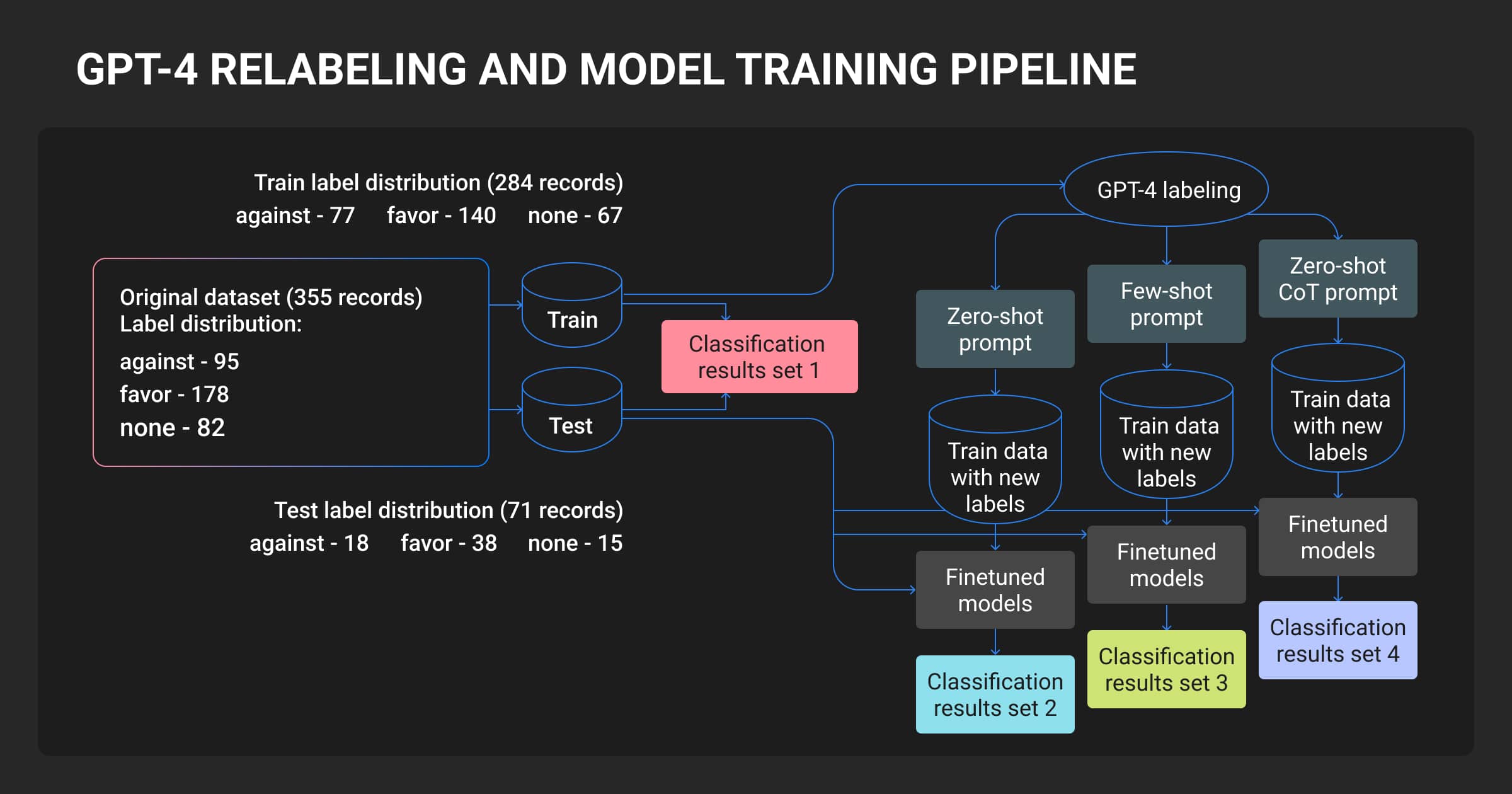
The basic workflow is straightforward: batch images to the GPT-4 Vision API, get structured output, convert to your schema, have humans review.
The five-step annotation process
- Batch images to GPT-4V via API. Maximum 4 images per request (URLs or base64 data). OpenAI GPT-4 vision API pricing is token-based, starting at ~$0.0036 per standard-resolution image.
- GPT-4V returns structured output. Use structured prompts to force consistent JSON format. Example: "Return a JSON object with keys: objects, attributes, scene_description."
- Convert outputs to your annotation schema. Write a parser script to transform GPT-4V’s JSON into COCO, Pascal VOC, or YOLO format.
- Human reviewers fix errors. Upload to a data annotation platform. Reviewers correct hallucinations, add missing details, verify relationships.
- Feed corrected data into fine-tuning (optional). Use the cleaned dataset to train a smaller, faster model. More on this later.
The OpenAI GPT-4 Vision image upload limit is 4 images per API request. Images beyond the fourth are ignored by the model, so structure your annotation pipeline to process datasets in batches of 4 or fewer.
Advanced techniques that improve results
- Set-of-Mark (SoM) prompting. Overlay numbers on image regions before sending to GPT-4V. Then ask: "Describe object #3." Forces precise grounding instead of vague scene descriptions.
- Frame-grid video analysis. Extract key frames, stitch into a grid, feed to GPT-4V with audio transcript. Cost: ~3 cents per video. Limitation: model misses objects disappearing between frames.
- Structured prompting templates. Design reusable prompts that return consistent formats across thousands of images. Reduces post-processing work.
The workflow is simple. The failure modes are not.
Where GPT4V Breaks (And Why It Matters)
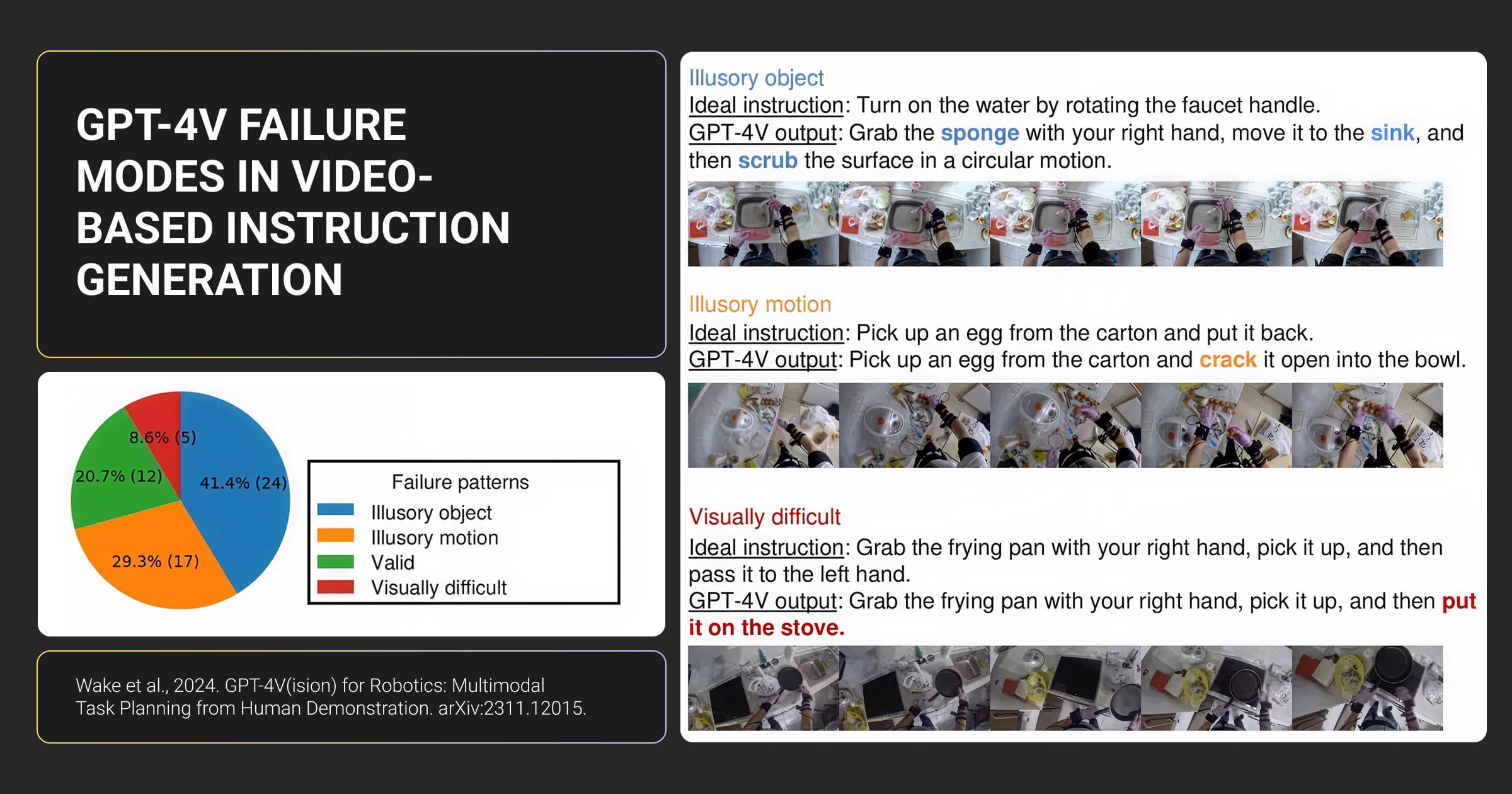
GPT4V makes confident errors. It describes objects that aren’t there, miscounts, and gives wrong spatial coordinates.
Documented failure modes
- Illusory objects. Describes things not present in the image. A robotics study tested GPT-4V on cooking videos. Accuracy: 20.7%. It hallucinated objects and invented actions that never happened.
- Wrong counts. Can't count dice dots. Fails on basic quantity questions.
- Incorrect localization. Returns wrong bounding box coordinates. Misidentifies where objects are in the frame.
- Temporal confusion. Doesn't notice objects disappearing between video frames. Creates false narratives to explain gaps it didn't detect.
- Correct answer, flawed reasoning. Medical imaging study: 81.6% diagnostic accuracy. But 35.5% of correct answers had flawed rationales. Most common error: basic image comprehension (27.2% failure rate). The model identified the right diagnosis while misunderstanding what it was looking at.
What this means for your dataset
GPT-4V is not a production annotator. You should think of it more as a pre-labeler. But you should also keep in mind that you get speed and scale, but you sacrifice precision and reliability.
A robotics team from GPT-4V(ision) for Robotics mentioned above summarized it clearly: "Human supervision is non-negotiable." They couldn't trust GPT-4V outputs without verification because hallucinations broke their task planning pipeline.
The solution is to build a workflow that catches its errors before they corrupt your training data.
Research on GPT-4 as a text annotator confirms this pattern. A study on social media stance classification found that while Few-shot and Chain-of-Thought prompting produced comparable results, none of GPT-4’s labeling approaches outperformed models trained on human-generated labels.
Human labels remain the gold standard for training production models.
The Hybrid GPT-4 Vision Workflow That Works

Use GPT4V to generate rough labels. Have humans verify and correct them. This is the only workflow validated by research across robotics, medical imaging, and remote sensing.
The proven approach
- GPT-4V generates first-pass tags. Objects, attributes, relationships, scene descriptions. Fast and cheap at scale.
- Human annotators verify and correct. Fix hallucinations. Add missing details. Validate spatial relationships. For bounding boxes, use specialized tools (GPT-4V can't handle localization).
- Sequential refinement (optional). ImageInWords methodology: each annotator builds on the previous one's work instead of starting fresh. Results: descriptions with 20% more detail in 30% less time compared to parallel annotation.
- Active learning loop (advanced). Fine-tune GPT-4V on human-corrected data periodically. Next batch of seeds becomes more accurate. Human correction burden decreases over time.
Why this works
GPT-4V processes thousands of images overnight while humans catch the errors that would break your model.
Validated by multiple studies: robotics task planning (cooking videos), medical diagnostic imaging (NEJM challenges), remote sensing machine learning datasets (RS-GPT4V). Every one concluded the same thing: autonomous GPT-4V annotation is too risky. Human-in-the-loop is mandatory.
Label Your Data runs expert-led annotation workflows end-to-end: human review by domain specialists, multi-layer quality checks, and delivery in your format. You get the accuracy your model needs without the management overhead.
Why Data Quality Still Beats Model Size

Web-scraped image captions are low quality. Human-verified, hyper-detailed descriptions dramatically outperform GPT4 Vision outputs.
The data quality problem
- Web-scraped alt-text is vague, SEO-focused, incomplete. Examples: "Canon EOS R6 Mark II" as an image description. Or just "Europe." This is what most vision-language models train on.
- GPT-4V-only captions are better but prone to hallucination and lack detail.
- Human-verified hyper-detailed descriptions outperform raw GPT-4V by 48% (ImageInWords) in side-by-side evaluations.
What “hyper-detailed” actually means
The ImageInWords study compared dataset statistics:
| Metric | Standard Dataset (DOCCI) | ImageInWords (IIW) |
| Tokens per description | 135.7 | 217.2 |
| Nouns | 34.0 | 52.5 |
| Adjectives | 16.6 | 28.0 |
| Verbs | 9.6 | 19.1 |
More nouns mean more objects identified. More adjectives mean richer attributes. More verbs mean better action and relationship descriptions.
Models trained on IIW data generate higher-quality images in text-to-image tasks and improve compositional reasoning by up to 6% on challenging benchmarks.
What this means for your project
If you’re building a custom model, invest in data quality. GPT-4V seeds the dataset fast, but humans define what good looks like.
For edge cases, domain-specific attributes, and complex scenes, expert data annotation services provide the precision foundation models can’t.
When to Stop Prompting and Start Fine-Tuning
Once you have a GPT-4V-seeded, human-corrected dataset, fine-tune a smaller model like GPT-4o or GPT-4o-mini. You'll get better results at lower cost and faster inference.
Why fine-tuning beats API calls
| Factor | GPT-4 Vision API | Fine-tuned GPT-4o |
| Cost per image | ~$0.12 | Pennies (after training) |
| Latency | Several seconds | Milliseconds |
| Accuracy | General-purpose | Domain-specialized |
| Prompt length | Long, detailed | Short, concise |
Real-world GPT4V results
- UI element detection: 272% improvement over base model after fine-tuning on task-specific data.
- Remote sensing: Fine-tuned RS-GPT4V model scored 37.86 accuracy vs 9.52 for base LLaVA-1.5 on visual grounding tasks.
- Autonomous driving: Fine-tuned models recognize road signs and lane markers with higher precision than general-purpose APIs.
The workflow
Many teams use LLM fine-tuning services to handle the technical implementation, from dataset preparation to model deployment.
- Use GPT4V API to generate 5,000-10,000 labeled images
- Human reviewers correct and enrich the labels
- Fine-tune GPT-4o-mini on the cleaned dataset
- Deploy the fine-tuned model for production inference
You've built a custom vision model that's faster, cheaper, and more accurate than calling GPT-4V every time.
The key insight for your team: GPT-4V is a tool for creating training data, not for production deployment. Use it to bootstrap your dataset, then move to a specialized model.
GPT-4 Vision in Practice (Tips from Engineering Leaders)
Engineering teams across industries are implementing GPT-4 Vision capabilities to accelerate annotation pipelines. They shared exactly where it works and where it breaks:
We used GPT-4V to automate content annotation, cutting the job down from days to hours. It still messes up on ambiguous images, so we do a human review. My advice is let the AI handle the bulk and save your experts for the tricky stuff.

 CTO, Search Party
CTO, Search Party
The hybrid workflow delivers measurable results. Machine learning teams are cutting annotation cycles by 40-60% using GPT-4V pre-labeling with human verification.
In enterprises, teams are utilizing this technology to decrease the cost of manual annotation by producing first-pass labels for humans to check, which sometimes saves 40 to 60% of cycle time for certain workflows. Its main limitation is the ability to be consistent at scale. GPT-4V is excellent with small, curated batches, but it can sometimes struggle to perform consistently in domain-specific edge cases.
 Founder/CEO, GPTZero
Founder/CEO, GPTZero
GPT-4V performs well on clean, standard data. Edge cases and specialized domains still require human expertise.
For annotation workflows, I'd only trust it on initial bounding boxes and obvious categories. Anything requiring trade-specific knowledge needs human review or your training data becomes expensive garbage.

This is the reality check every ML team needs. Use GPT-4V for first-pass work. Don’t trust it with domain-specific details that require expert knowledge. Bad pre-labels corrupt your training data and waste more time than they save.
Should You Use GPT4V for Your Image Dataset?

Quick decision framework based on your use case and constraints.
Use GPT4V if you need
- Rapid first-pass labels. Semantic tagging, object identification, scene descriptions at scale.
- Dataset bootstrapping. Generating initial annotations for thousands of images to start model training.
- Exploratory analysis. Understanding what's in your images before committing to formal annotation pipelines.
Don’t use GPT-4 Vision for
- Production inference. Latency of several seconds per image makes GPT-4V unsuitable for real-time systems. Deploy fine-tuned models for production workloads requiring speed and cost efficiency.
- Precise bounding boxes or segmentation masks. Use specialized annotation tools. GPT-4V’s localization is unreliable.
- Medical or safety-critical labels without human review. Hallucination rate makes autonomous use too risky.
- Real-time applications. CCTV monitoring, autonomous vehicles, live video analysis require millisecond latency. GPT-4V can't deliver that.
Cost comparison
GPT-4 Vision API pricing becomes prohibitive at scale: fine-tuned models eliminate per-image costs after training.
- GPT4V API: Token-based pricing starting at ~$0.0036 per image, higher for large/high-detail images
- Human-only annotation: $0.10-$1.00+ per image (varies by task complexity)
- Hybrid (GPT-4V + human review): 30-50% faster than human-only, same quality
When evaluating data annotation pricing, compare GPT-4V API costs (~$0.0036+ per image) against full-service annotation ($0.10-$1.00+ per image depending on task complexity).
Your practical path forward
- Budget under $1,000 and need 10,000+ images? Use GPT-4V for pre-labeling.
- Need precision (bounding boxes, medical labels, edge cases)? Hybrid workflow required.
- Building a production model? Fine-tune on GPT-4V-seeded, human-corrected data.
Working with a data annotation company that understands both GPT-4V capabilities and human review workflows ensures you get quality labels without managing the pipeline yourself.
Label Your Data supports your annotation workflow: our experts can label datasets from scratch or verify and correct GPT-4V pre-labels, ensuring quality before delivery in your format.
About Label Your Data
If you choose to delegate data annotation to human experts, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is GPT4V?
GPT4V (GPT-4 Vision) is OpenAI's multimodal model that processes both text and images. GPT-4 Vision capabilities include analyzing photos, generating descriptions, reading text from images (OCR), and answering questions about visual content.
What does GPT-4 vision do?
GPT 4 Vision identifies objects in images, describes scenes, reads text from documents and charts, and generates captions. ML engineers use it to accelerate dataset annotation by generating first-pass labels that humans then verify.
How much is GPT-4 vision?
OpenAI GPT-4 Vision pricing is token-based, starting at approximately $0.0036 per standard-resolution image via the OpenAI API. Costs scale with image resolution and detail mode. For large-scale annotation projects, these costs add up quickly compared to traditional annotation services.
Does GPT-4 still hallucinate?
Yes. GPT4V hallucinates objects that aren't in images, miscounts items, and provides incorrect spatial coordinates. A robotics study found only 20.7% accuracy on video transcription tasks due to hallucinations. Human review is required for reliable annotations.
How to use GPT-4-vision-preview?
The gpt-4-vision-preview model was deprecated in December 2023. Use current vision-enabled models instead: gpt-4-turbo, gpt-4o, or gpt-4o-mini. Access them via the OpenAI API, not the Playground interface. Send images as URLs or base64-encoded data.
When did GPT-4 vision come out?
GPT4 Vision was released in September 2023. The initial gpt-4-vision-preview model was later replaced by vision-native models like gpt-4-turbo and gpt-4o in December 2023.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.