VLM: Complete Vision Language Models Guide for ML Teams

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- VLMs use three components to handle multiple visual tasks through natural language instead of requiring separate specialized models.
- Open-source models like Qwen2.5-VL now match GPT-4o performance while enabling fine-tuning on 5,000-50,000 examples using LoRA for $100-$5,000 in compute.
- Early fusion enables rich reasoning but consumes 4,096 tokens per image, while hybrid approaches balance efficiency with spatial understanding for production deployment.
What Are Vision Language Models?
Vision language models (VLMs) are neural networks that process images and text together. Feed them a photo and a question, get back a text response that shows visual understanding. A VLM reads an X-ray and identifies abnormalities, extracts line items from scanned invoices, or describes suspicious behavior in security footage.
Traditional computer vision needed separate models for each task. VLMs handle multiple vision tasks through natural language instructions using a single architecture: a vision encoder converts images to tokens, a projection layer aligns them with language model embeddings, and an LLM decoder generates responses.
Why production teams are deploying VLMs in 2025:
- Open-source caught up: Qwen2.5-VL and InternVL3 match GPT-4o’s performance while running on your hardware
- Efficient architectures: Mixture-of-experts models cut inference latency 40-70%
- Accessible fine-tuning: QLoRA adapts 70B parameter models on a single A100 GPU
Training on billions of image-text pairs unlocked emergent reasoning. Top models score 60-70% on MMMU-Pro, a benchmark requiring expert-level understanding of physics and engineering diagrams.
Understanding how these three components work together explains why VLMs outperform task-specific models and where their limitations come from.
How Do Vision Language Models Work: Architecture & Workflow
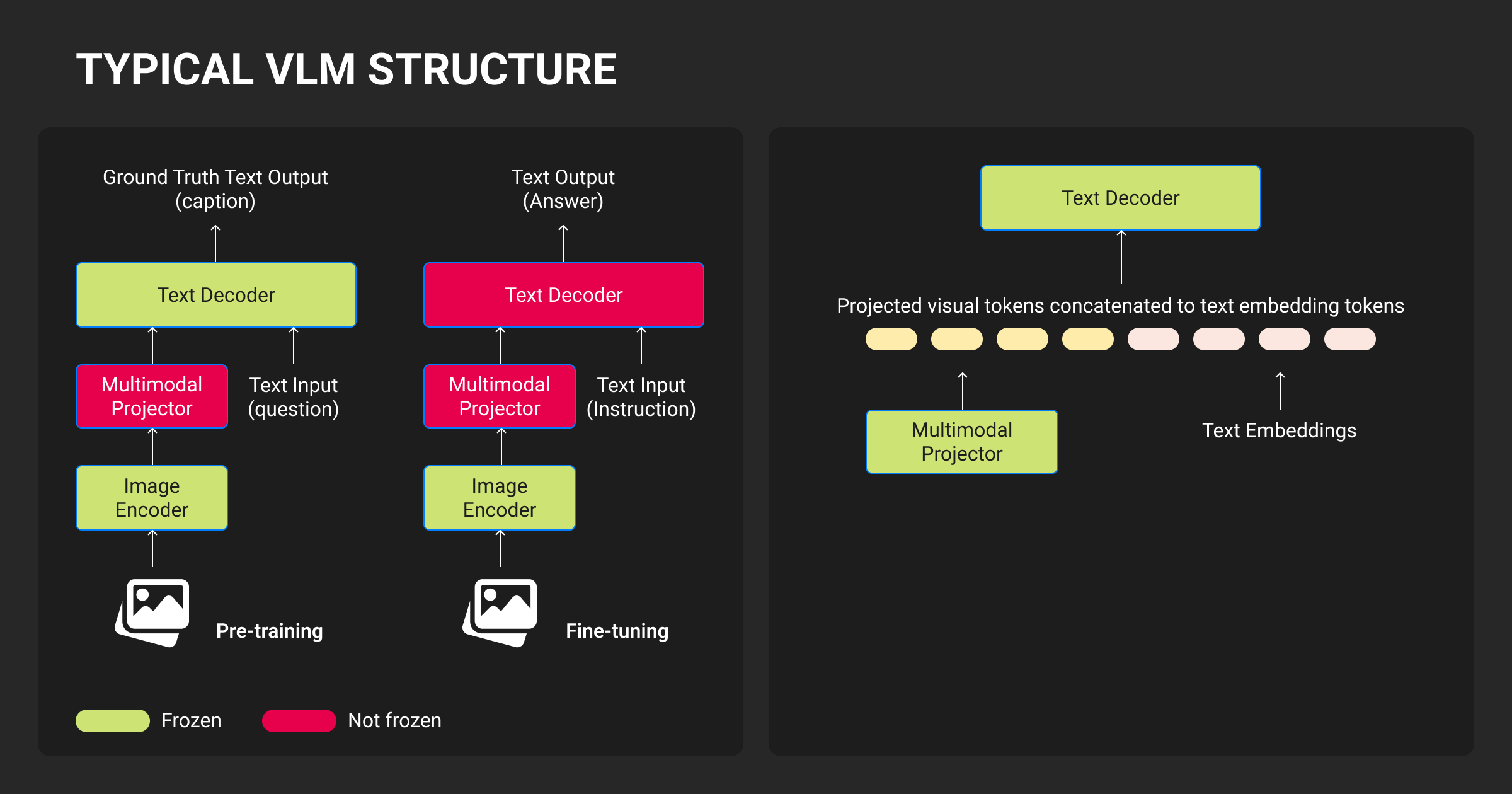
Vision LLMs use a three-stage pipeline. The vision encoder converts images into numerical representations, the projection layer maps these to the language model’s embedding space, and the LLM decoder generates text while attending to both visual and text tokens.
Stage 1: Vision encoders
Vision Transformers (ViT) split images into 16×16 pixel patches, then process each patch as a token. A 1024×1024 image becomes 4,096 visual tokens before reaching the language model. This token explosion is why context windows matter: adding a single high-resolution image to your prompt consumes the same budget as 2,000-3,000 words of text.
Common vision encoders in production:
- CLIP-ViT-L/14: Trained on 400M image-text pairs, outputs 1,408-dim embeddings (LLaVA, many open-source models)
- SigLIP: CLIP's successor with sigmoid loss, lower memory footprint (Phi-4, DeepSeek-VL2)
- Custom encoders: Proprietary optimization for specific architectures (GPT-4o, Gemini, Claude 3.5)
Proprietary models like Gemini 1.5 Pro can process 1 million tokens, handling hours of video or thousands of document pages in a single context window.
Stage 2: Projection layers
Vision encoders output 1,408-dimensional vectors. LLMs expect 4,096-dimensional inputs (for Llama-based models). The projection layer bridges this gap, typically using a 2-layer MLP that learns the alignment during training.
The projection layer uses a machine learning algorithm (typically a 2-layer MLP) that learns the alignment during training. Most teams freeze the vision encoder during fine-tuning and only train the projector plus the top 2-4 layers of the LLM. This reduces compute costs by 90% while maintaining accuracy.
Different types of LLMs serve as decoder backbones: Llama-based for open-source, proprietary for GPT-4o and Gemini. The projector learns task-specific mappings: medical VLMs emphasize tissue boundaries, document VLMs focus on text regions and layout structure.
Stage 3: Token fusion
| Fusion Approach | How It Works | Advantages | Tradeoffs |
| Early fusion | Concatenates visual + text tokens into single sequence | Rich cross-modal reasoning, best spatial understanding | 4,096 visual tokens per image, high memory cost |
| Late fusion | Processes vision/language separately, combines near output | 50-70% lower memory, faster inference | Weaker spatial reasoning, misses subtle relationships |
| Cross-attention | LLM attends to visual tokens periodically without concatenation | Balanced efficiency and reasoning quality | More complex architecture |
| Hybrid | Early fusion for grounding + sparse cross-attention for efficiency | Production sweet spot (Qwen2.5-VL, InternVL3) | Requires careful layer design |
Modern LLM vision models increasingly use hybrid approaches. Early fusion in the first few layers establishes visual grounding, then sparse cross-attention maintains efficiency through deeper layers.
Prompting strategies for multimodal understanding
Text prompts frame how the vision language model interprets images. "Describe this image" produces generic captions. "List all visible safety hazards in this construction site photo" focuses attention on specific visual elements.
Prompt ordering matters:
- Question-before-image: 5-10% better accuracy on reasoning tasks
- Image-before-question: More natural for conversational interfaces
- Multi-turn conversations: Each exchange adds previous image tokens to context (hits limits after 3-4 turns with high-res images)
DeepSeek-VL2 introduced dynamic resolution processing that tiles large images into 1024×1024 chunks, processes each independently, then fuses the results. This lets the model handle 4K images without the 16,384-token cost of naive encoding.
The architecture explains both VLM machine learning strengths and weaknesses. Rich early fusion enables complex reasoning but burns tokens fast. Efficient late fusion scales better but misses subtle visual-linguistic relationships. Understanding these tradeoffs guides model selection for your use case.
The biggest challenge is getting VLMs to work for everyone, especially with user-generated content. Models struggle with different skin tones or facial features when users are global. We added diverse training data at Magic Hour, but edge cases still emerge. Constantly test with real-world inputs and talk to users from different backgrounds.

 CEO, Magic Hour
CEO, Magic Hour
Popular VLMs and Emerging Architectures
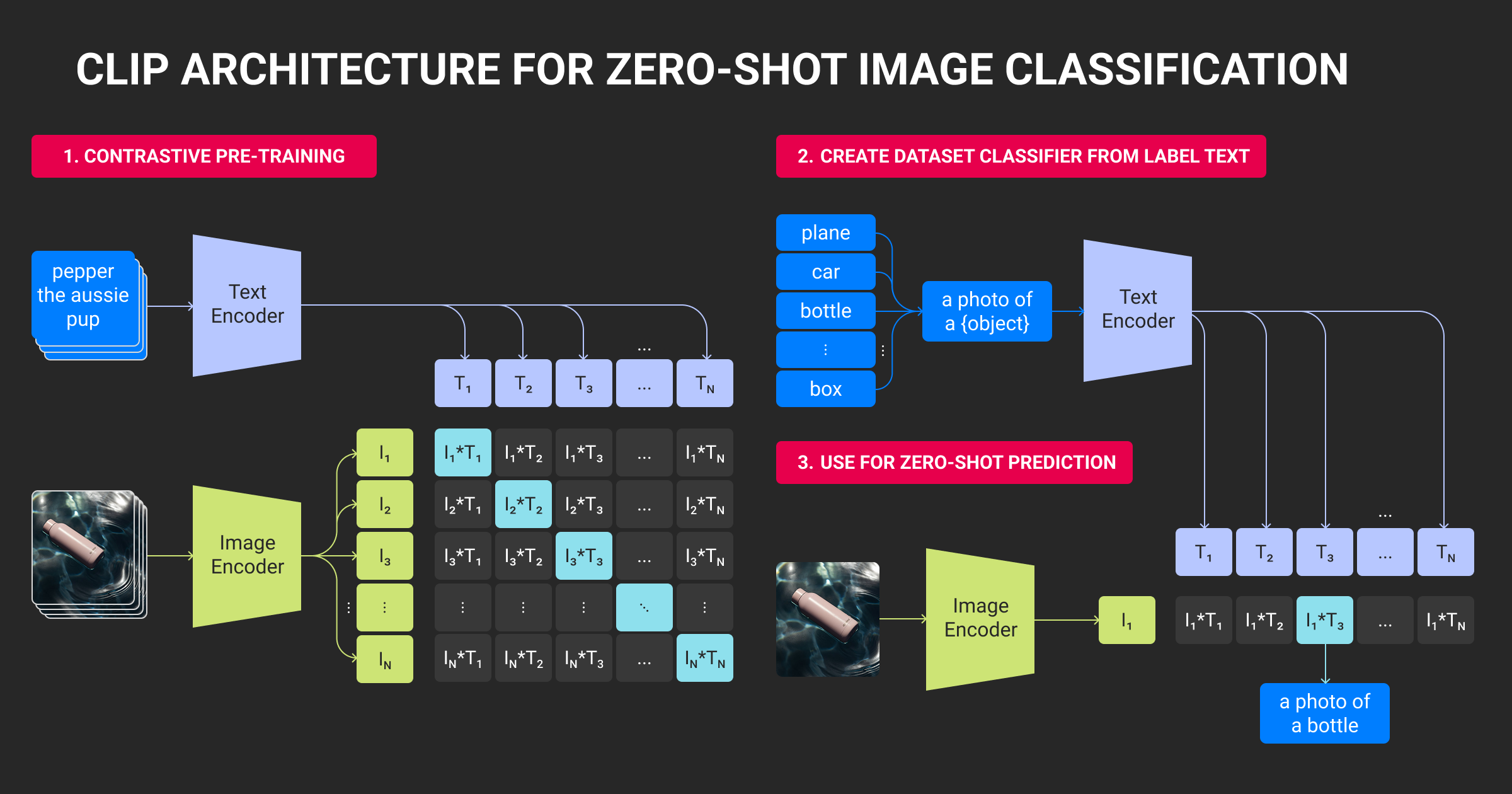
The VLM vision language model landscape splits between proprietary APIs offering state-of-the-art reasoning and open-source models approaching parity while running on your infrastructure. Model selection depends on whether you prioritize absolute performance, cost control, data privacy, or fine-tuning flexibility.
Top VLM models in 2025
| Model | Released | Params | Modalities | Context | Key Strength | License |
| GPT-4o | May 2024 | N/A | Text/Image/Video/Audio | 128k | 59.9% MMMU-Pro, best reasoning | Proprietary |
| Gemini 1.5 Pro | Dec 2024 | N/A | Text/Image/Video/Audio | 1M | Longest context (hours of video) | Proprietary |
| Claude 3.5 Sonnet | Jun 2024 | N/A | Text/Image | 200k | Superior OCR/document understanding | Proprietary |
| Qwen2.5-VL | Jan 2025 | 3B-72B | Text/Image/Video | 32k-128k | First open-source >70% MMMU | Apache 2.0 |
| InternVL3 | Apr 2025 | 4B-78B | Text/Image/Video | 128k | Production-ready stability | MIT |
| DeepSeek-VL2 | Dec 2024 | 4.5B (1-2.8B active) | Text/Image/Video | 32k | 50-70% lower latency (MoE) | MIT |
| LLaVA 1.6 | Jan 2024 | 7B-34B | Text/Image | 4k-32k | Research/prototyping baseline | Apache 2.0 |
| Phi-4-Multimodal | Feb 2025 | 5.6B | Text/Image/Audio | 16k | On-device deployment | MIT |
Proprietary models (GPT-4o, Gemini, Claude) lead in absolute performance but lock you into API pricing and prevent fine-tuning. Use them when accuracy justifies costs, and you don't need data privacy or custom adaptations.
Open-source models like Qwen2.5-VL-72B and InternVL3-78B now perform within 5-10% of proprietary models. You control deployment, fine-tune on proprietary data, and eliminate per-call costs at scale.
Three architecture trends reshaping your VLM
Mixture-of-Experts (MoE) activates only 1-2.8 billion of 4.5 billion total parameters per input. DeepSeek-VL2 cuts inference latency 50-70% compared to dense models while maintaining accuracy. The router network learns which experts handle visual reasoning versus text generation.
Smol-capable VLMs (1B-10B parameters) target edge deployment. Phi-4-Multimodal runs on NVIDIA Jetson Orin with sub-100ms inference. These sacrifice 10-15% accuracy for no cloud dependency, enabling retail point-of-sale, robotics, and mobile applications.
Vision-Language-Action (VLA) models add action decoders for robot control. NVIDIA Groot N1 and Physical Intelligence π0 see camera feeds and language instructions, then output joint positions and gripper states. Current 60-80% success rates limit deployment to supervised automation in warehouses and manufacturing.
Picking the best LLM for vision tasks
Start with LLaVA 1.6 for prototyping (extensive docs, active community). Move to Qwen2.5-VL or InternVL3 for production if you need fine-tuning or data privacy. Choose DeepSeek-VL2 when latency matters more than absolute accuracy. Use GPT-4o or Claude 3.5 when you need best-in-class performance and lack machine learning infrastructure to manage open-source deployments.
The performance gap between proprietary and open-source continues shrinking. Teams increasingly start with open-source for cost control, only escalating to APIs when specific tasks demand the extra 5-10% accuracy.
Applications of Vision Language Models
VLMs evolved beyond traditional image recognition systems that output fixed class labels. They can handle multiple visual tasks through natural language instructions instead of requiring separate specialized models. Teams deploy them when task requirements change frequently or involve complex reasoning.
Visual question answering in specialized domains
Medical VLMs examine X-rays and answer "What abnormalities appear in the lower left lung?" Manufacturing teams prompt "Identify all defects and classify severity" instead of training separate classifiers. Financial analysts query charts for trend analysis.
GPT-4o scores 59.9% on MMMU-Pro benchmarks requiring multi-hop reasoning. Open-source Qwen2.5-VL hits 70%, making expert-level visual reasoning accessible without API costs.
Document understanding and extraction
VLMs read layout and structure, not just characters. They understand that the number below "Total Amount" is what you owe, not a phone number. Insurance teams extract policy details from mixed formats. Legal analysts parse contracts and cross-reference clauses. Finance processes nested tables while maintaining footnote associations.
Claude 3.5 Sonnet handles complex layouts across 200,000-token contexts while preserving spatial relationships.
Semantic search replaces metadata tagging
E-commerce customers search "black leather jacket with asymmetric zipper" and retrieve visually matching products even if catalogs say "moto jacket." Remote sensing teams query satellite imagery: "Show flooded agricultural fields" without training classification models. The implementation encodes images and queries into shared embedding space, then uses vector databases like FAISS for similarity matching.
Teams building custom VLMs require data annotation to create the 5,000-50,000 labeled image-text pairs needed for fine-tuning.
Multimodal RAG preserves visual context
Standard RAG loses diagrams and layouts when converting PDFs to text. Multimodal RAG embeds images alongside text chunks, improving retrieval accuracy 25-40%. Engineers search "how does the cooling system connect?" and get diagram pages with VLM-generated answers referencing specific components.
Robotics applications
Vision-Language-Action models control robots through natural language. NVIDIA Groot N1 handles warehouse pick-and-place by predicting joint positions instead of text tokens. Current 60-80% success rates require human supervision.
Applications span healthcare radiology, satellite monitoring, retail catalogs, legal analysis, and manufacturing quality control. The pattern: flexible visual understanding beats rigid classification when tasks evolve.
VLM Training, Fine-Tuning, and Evaluation
Most teams fine-tune pretrained VLMs rather than training from scratch. Full pretraining requires prohibitive compute budgets. LLM fine tuning adapts existing models to your domain at a fraction of the cost.
Fine-tuning strategies for production
Dataset requirements scale with task complexity:
- Simple tasks: 500-1,000 examples
- Complex reasoning: 5,000-50,000 examples
- Production quality: 10,000-100,000 examples
Mix 70% task-specific data with 30% general machine learning datasets to prevent catastrophic forgetting. Many teams partner with a data annotation company like Label Your Data to scale dataset creation while maintaining quality control.
Using a data annotation platform streamlines the workflow of collecting, labeling, and validating the 5,000-50,000 image-text pairs required for production-quality fine-tuning.
LoRA (Low-Rank Adaptation) cuts training costs: Freezes pretrained weights, adds small trainable matrices to attention layers (rank 16 or 64), enabling 70B model fine-tuning on single A100 GPU.
QLoRA combines 4-bit quantization with LoRA: Reduces memory 75% with 1-3% accuracy loss, making 70B models trainable on consumer GPUs.
VLM evaluation benchmarks
MMMU-Pro contains 12,700 expert-level questions across physics, chemistry, and engineering. Human experts score 88.6%. Leading models in 2025:
- GPT-4o: 59.9%
- Qwen2.5-VL-72B: 70%
- InternVL3-78B: 70%
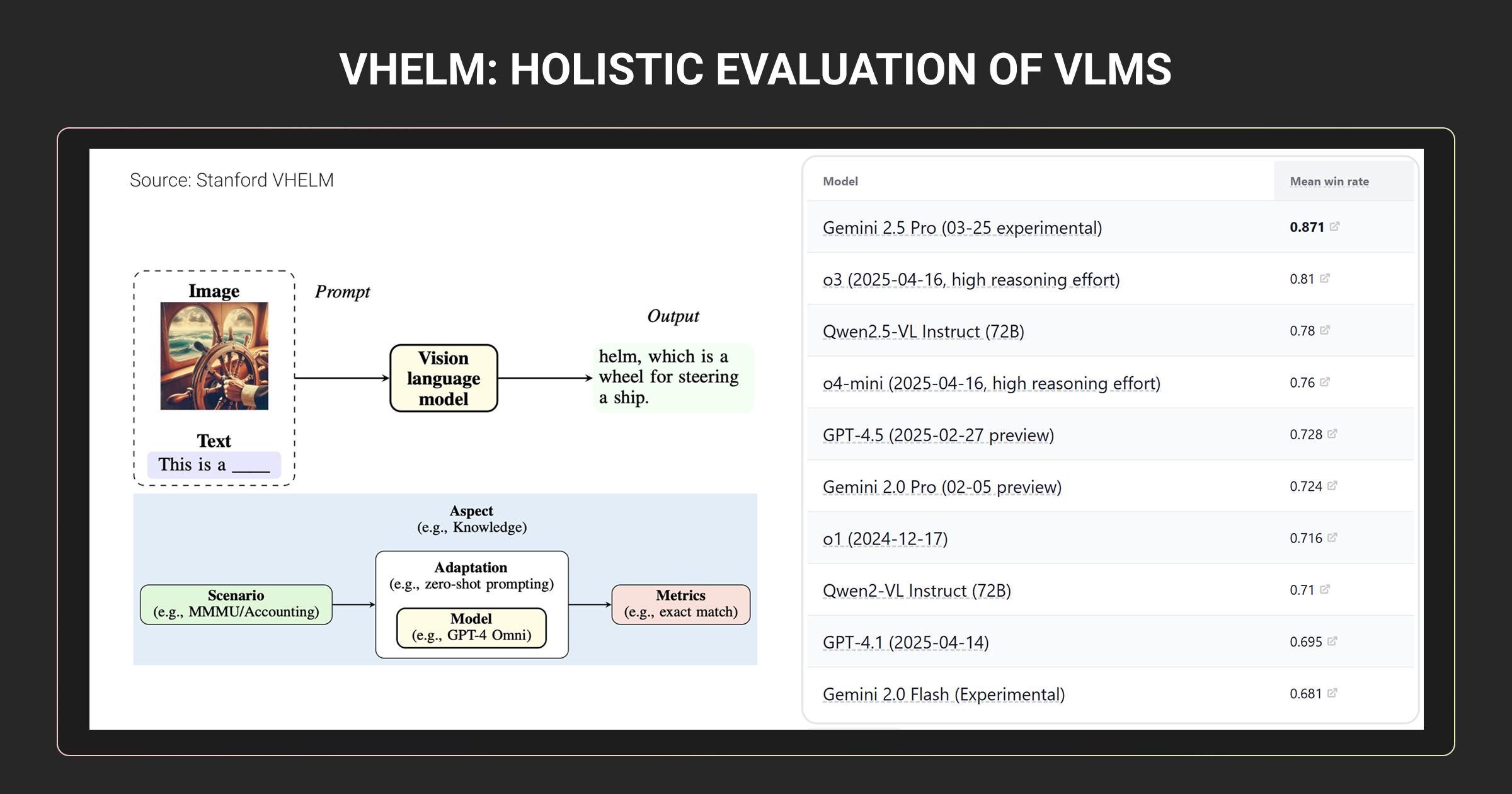
Stanford’s VHELM benchmark provides unified evaluation across nine aspects including perception, reasoning, and bias, producing standardized leaderboard comparisons.
Video understanding: Video-MME tests temporal reasoning across 900 videos and 5 difficulty levels. LongVideoBench evaluates 5-20+ minute videos for long-context tracking.
Multimodal-specific metrics
- Image-text alignment: Cosine similarity >0.8 indicates strong alignment
- Hallucination rate: 10-30% typical on complex scenes, measure by human annotation
- Spatial reasoning: Current VLMs score 50-60% accuracy
Combine benchmark scores with domain-specific LLM evaluation. Sample 100-500 outputs for human review before production. Track accuracy disparities across gender-balanced and race-balanced test sets to detect bias.
The real blocker is the mismatch between what the image encoder sees and the text encoder understands. At Skywork.ai, 12% of our image-text pairs had descriptions not present in the image. We added a cross-modal error rate (CMER) metric tracking low text similarity despite high image confidence. This cut hallucination errors by ~35%. Treat alignment debt as a first-class KPI.
 Marketing Manager, Skywork.ai
Marketing Manager, Skywork.ai
Professional data annotation services can accelerate dataset creation, though quality control remains critical for preventing cross-modal misalignment.
While compute costs $100-$5,000, data annotation pricing typically ranges from $0.10-$2.00 per image-text pair depending on task complexity. If not handled by experts, dataset preparation often becomes more expensive than GPU time itself.
Key VLM Limitations to Consider
VLMs advanced rapidly but face constraints that affect production deployment.
Hallucination in spatial understanding
Autoregressive LLMs generate plausible text regardless of image content. A VLM might confidently state "the red ball is left of the blue cube" when colors or positions are wrong. Spatial reasoning accuracy sits at 50-60% even in top models.
Mitigation approaches:
- Constrained decoding that validates claims against object detection outputs
- DPO with human preference data penalizing hallucinated details
- Prompt engineering: "Only describe what you can clearly see"
- Object detection validation (adds 100-200ms latency, reduces hallucination 30-50%)
Context window bottlenecks
1024×1024 images consume 4,096 visual tokens. Three high-resolution images plus conversation history hits 16k context limits, constraining multi-turn dialogues and document processing.
Solutions in production:
- Dynamic resolution: Qwen2.5-VL adapts encoding density to image content
- Adaptive tiling: DeepSeek-VL2 splits large images into chunks
- Key frame selection: 50-80% token reduction in video
- Vision token caching: Store encoder outputs for repeated images
Trade image resolution for context capacity. Many applications work fine with 512×512 encoding, freeing tokens for longer conversations. Bias from training data and safety degradation during vision adaptation require monitoring production outputs and pre-deployment fairness audits.
Building production VLMs requires both technical architecture decisions and high-quality training data at scale.
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the difference between VLM and LLM?
A large language model, aka LLM, processes only text. VLM vision language model adds a vision encoder and projection layer to process both images and text together, enabling tasks like visual question answering, document understanding, and image captioning through natural language instructions.
Is ChatGPT a VLM?
ChatGPT-3.5 and earlier versions are text-only LLMs. GPT-4o and GPT-4 with Vision are VLMs that process images alongside text.
What is the difference between VLM and OCR?
OCR extracts text characters from images but loses layout, structure, and spatial relationships. VLMs understand context: they know the number below "Total Amount" on an invoice is what you owe, not a phone number or date.
What is a vision language action model?
VLA models extend VLMs by adding an action decoder that outputs robot control signals instead of text. They see camera feeds and language instructions, then predict joint positions and gripper states for physical tasks like pick-and-place.
Is VLM better than LLM?
VLMs handle visual tasks LLMs cannot. For text-only work, standard LLMs are more efficient. Choose based on whether your application requires visual understanding.
What is the difference between VLM and ML?
Machine learning is the broad field of algorithms that learn from data. A vision language model, aka VLM, is a specific type of ML model that processes vision and language together. All VLMs use ML techniques, but not all ML involves vision-language tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.